
- 1Gson 、FastJson、Jackson 使用对比_jackson gson
- 2DataSophon组件之Doris升级_datasophon 可以部署doris 2.0吗
- 3Elasticsearch 集群
- 4delete.topic.enable=true,然后通过kafka manager能删除干净吗?_deletedelete.topic
- 5spring boot 接收第三方mq消息
- 6mysql 日志爆满,删除日志文件,定时清理日志_mysql 二进制日志过快 过大
- 75G网络为什么要优化?5G网络优化工程师会不会被替代?
- 8开发者评测|操作系统智能助手OS Copilot【阿里产品系测评】_操作系统智能助手copolit
- 9Plugin configuration unchanged.
- 10Latex: 引用中的 citep (将作者和年份一起放到一个括号里面)_latex怎么citep命令
7.神经网络反向传播_反向传播作用
赞
踩
1、神经网络反向传播的作用
在上一节中学到的输入通过隐藏层汇总计算最后到输出层的流程是神经网络的正向传播。这个流程用于一个完整的模型通过输入预测输出时使用。但对于一个不完美的模型,正向传播是难以更新参数完善模型的,因此就需要神经网络反向传播。
神经网络优化过程与前面学习到的梯度下降算法思想是一致的,他通过使代价函数不断向着代价值减少的方向前进来优化模型。与梯度下降不同的地方主要在于代价函数与参数的关系。
2、神经网络反向传播的流程
神经网络的代价函数如下图:
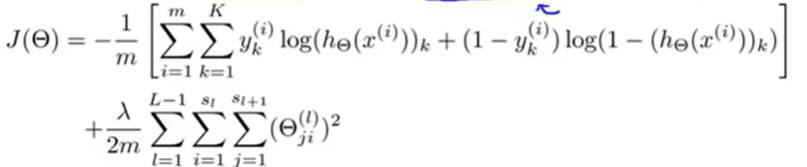
这个函数的含义就是输出层与测试集的差的对数和,总的来说就是输出与样本的差别。
神经网络有多层,每个层又有多个参数,想要合理更新每个参数,就需要知道每个参数对代价函数影响,这个影响程度通过正向传播难以求出,因此要通过反向传播过程求出。
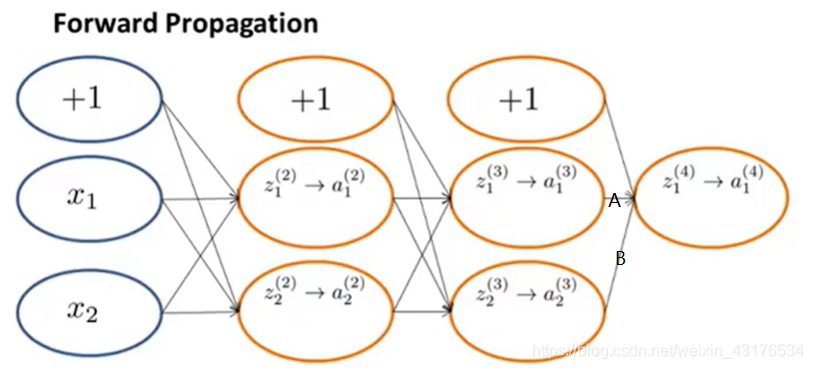
反向传播的第一步是正向传播,这个操作是为了求出输出值与训练样本的误差。有了误差值后,就可以按顺序逆向更新参数了。
我们知道,导数可以反映出函数的变化快慢程度,因此可以由偏导数来反映参数对于代价函数的影响大小。
如图所示,对于第三层和第四层,假如忽略偏置神经元,有:
a
1
(
4
)
=
g
(
z
1
(
4
)
)
=
g
(
a
1
(
3
)
×
A
+
a
2
(
3
)
×
B
)
a^{(4)}_{1}=g(z^{(4)}_{1})=g(a^{(3)}_{1}\times A+a^{(3)}_{2}\times B)
a1(4)=g(z1(4))=g(a1(3)×A+a2(3)×B)
(
1
)
(1)
(1)
若要求参数A对代价函数的影响,则要求代价函数对A求偏导,通过链式求导法则,有:
∂
f
∂
A
=
∂
f
∂
a
1
(
4
)
×
∂
a
1
(
4
)
∂
z
1
(
4
)
×
∂
z
1
(
4
)
∂
A
\frac{\partial f}{\partial A}=\frac{\partial f}{\partial a^{(4)}_{1}}\times\frac{\partial a^{(4)}_{1}}{\partial z^{(4)}_{1}}\times\frac{\partial z^{(4)}_{1}}{\partial A}
∂A∂f=∂a1(4)∂f×∂z1(4)∂a1(4)×∂A∂z1(4)
然后根据代价函数表达式和(1)式分别计算三个偏导数,相乘得
∂
f
∂
A
\frac{\partial f}{\partial A}
∂A∂f值,然后更新参数:
A
+
=
A
−
η
×
∂
f
∂
A
A^+=A-\eta\times\frac{\partial f}{\partial A}
A+=A−η×∂A∂f
其中
η
\eta
η是学习率,与梯度下降法中的学习率发挥相同的作用。
接下来的步骤与前面所述步骤相仿,从后往前计算偏导数值更新参数提高模型的性能。这就是神经网络反向传播的流程。
3、梯度检测
反向传播的计算流程十分复杂,有很多的求导计算,这会使我们的程序中出现不易察觉的bug,导致得到的模型不是最优解。
为了解决这个问题,我们可以使用梯度检测的方法。这个方法的实质是将用多项式描述的导数定义方法得到的结果与直接调用函数得到的结果相比较,若结果接近,则算法没有问题。注意在实际运行的时候要屏蔽梯度检测部分代码,否则运行速度会很慢。
4、随机初始化
如果初始将所有参数定为0或是某些有联系的数字,会导致正向传播时神经元同质化,进而影响模型的性能。为了避免这个后果,建议将所有参数初始化处理。
总结
本章学习了神经网络的反向传播过程,神经网络反向传播是一种相对复杂的算法,为了理解这个算法用了不少的时间。

