
- 1伺服系统的动态校正与控制:位置、转速、电流三环控制系统_伺服系统三环pid
- 2一文带你速通RAG、知识库和LLM!_知识库 rag
- 3sql update 特殊用法
- 4CosyVoice 实测,阿里开源语音合成模型,3s极速语音克隆,5分钟带你部署实战_cosyvoice 合成语音 速度慢
- 5LSSVM-ABKDE基于最小二乘支持向量机结合自适应带宽核函数密度估计的多变量回归预测(点预测+概率预测+核密度估计)_ls-svm 回归曲线
- 6百度api语音_function vol
- 7python中plot实现实时显示数据_python 一边显示图另一边显示数据
- 8Redis项目实战_redis 实战
- 9could not find implicit value for evidence parameter of type org.apache.flink.api.common.typeinfo.Ty
- 10树和二叉树
2024年Go最新NLP 实战 (7) 热榜算法更新(1),2024年最新整理了3家面试问题:美团+字节+腾讯_用go实现一个热门贴算法,影响因素发帖时间、点赞量、评论数和搜索频次
赞
踩
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
- 热榜总榜更新
- 标签权重体系整体优化,重点提升 “关键技术/前沿技术” 的权重,以及标签权重进一步细化与区分;
- 修复 bug:行为数据中会员身份未去重,导致重复计算;
2022/05/13 更新:
- 热榜总榜更新
- 修复bug:文章上榜后又掉榜的问题;
- 修复bug:原力值过滤逻辑、B榜逻辑未生效问题;
- 属于原力计划的文章提升权重,在原有得分的基础上乘以1.2,非原力计划文章权重不变。可增加原力计划文章的曝光;
- 考虑 “评论/点赞/收藏/分享/关注” 用户的原力等级和会员身份,在原始值(例如:点赞数)的基础上乘以用户的原力等级,会员用户再乘以3。可在一定程度上降低低等级用户刷榜的问题。
- 制定标签权重体系,给每个统一标签赋予 0-1 的权重,并根据文章最相关的标签以及标签权重,对文章得分进行调整(在原有得分的基础上乘以标签权重)。可通过标签体系来降低老技术文章的权重。(注:使用的是机器识别的标签)
- 热榜领域榜更新
- 基于文章标签以及标签权重得分体系,计算一篇文章的标签得分,并对文章得分进行调整(在原有得分的基础上乘以标签得分)。可在一定程度上过滤掉一个领域中不相关的文章。
贡献者:@Alexxinlu @行走的人偶 @幻灰龙 @softwareteacher
2022/04/24 更新:
综合热榜使用上了质量分(100分制),参考 【博文质量分计算】
- 质量分低于80分的不入围
- new_score = old_score * ( 质量分/100)
2022/03/30 更新:
改进领域榜,增加榜单说明:
- 增加“云原生”,“软件工程”,“后端” 三个领域榜,本周App/PC都会完成上线
- 对于用户反馈的“点赞,收藏”数据和榜单排名的关系,有些用户提到数据很多,但是名次不靠前,这里给一个更透明的说明:
- 目前只用App的交互数据
- 交互数据只算24小时内
2022/02/24 更新:
改进领域榜,调整规则
- 增加最低阅读数要求:50
- 增加最低原力值要求:30
- 增加最低博文长度要求:700-1500
- 增加标题党过滤
- 增加软文过滤
- 扩充领域标签池
贡献者:@幻灰龙 @佳昊 @PeasantWorker @行走的人偶
2021/12/27 更新:
综合热榜增加对用户投诉多的广告软文的识别和过滤。
2021/12/02 更新:
新增根据原力值计算N条命,插入到top11-top100的规则,具体计算方式如下:
- 综合热榜A榜
- A榜=直接根据热榜计算公式计算出来的热榜
- 综合热榜隐藏B榜
- 所有用户都有原力, 专家我们会给他较高的原力;
- 每天更新一次,针对原力值Top300用户,计算N条命:N = 2 + math.ceil(原力值 / 最低原力值)
- 每小时计算这些用户的剩余生命值: R = N -(最近7天,上热榜top100里面的B榜文章个数)
- 每小时,上述用户R>0 并且文章在A榜top100-top500区间内的文章构成了B榜
- 混合热榜
- B榜的top50的文章,在A榜里的原始排名/5+10,插入到A榜11-100
2021/11/09更新:
- 上线了10/28号提到的时间衰减因子TTL归一化的调整。TTL从1开始随着时间平滑下降。
- 上线了同作者连续上榜次数衰减因子CH的调整:同一个作者过去72小时内上过top10的文章才会对后续文章的得分造成影响。
经过这两个调整,热榜博文的时间衰减粒度不再以小时迅速衰减。这里有一个和HackNews的不同需求是,博文上榜后需要在热榜上停留足够的时间,因此衰减不能过于剧烈。
衰减的问题解决后,下一步会再回归来改进上榜博文内容稀缺度问题。
2021/10/28更新:
前后对比,有效抑制了正文里提到的标题党和过于低质长博文的问题。

2021/10/27更新:
时间衰减因子(TTL) 归一化下,从1开始随着博文创建时间衰减,可以从 TTL 的曲线变化看到0-72个小时内因子的衰减,新公式需要跑下数据验证后再上线:
https://www.wolframalpha.com/input/?i=1.52%2F%28log%28x%2B4%29%29%5E1.3%2Cx%3E%3D0%2Cx%3C%3D12
- 公式是:1.52/(log(x+4))^1.3,x>=0,x<=12
- 其中x表示博文创建后经过了多少个6小时,72小时一共有12个衰减点,这个衰减频次可以根据同样的原理调整,通过这个方式也可以同时解决夜晚大家睡觉时博文热度被衰减的问题
- 其中1.52是因子归一化到1-0的调整常量,1.52 = 1/(1/(log(0+4))^1.3),如果公式的其他系数做了调整,重算一下这个常量即可。
2021/10/27 更新:
新热榜每周NPS曲线,定期跟踪:

2021/10/27 更新:
增加了最低阅读量过滤,阅读量太低的直接不参与计算,刚创建的文章应该在其他渠道有一些冷启动的过程。但是阅读量是一个容易被刷的数据,该数据并不参与后续计算。
热榜问题分析
CSDN 的榜单有很多个,包含这些:
- 周排名
- 历史贡献排名
- 总排名
- 新晋博主
- 企业博客排名
- 领域排名
- 热榜排名
其中热榜总是存在一些问题,典型的现象有:
- 存在博文霸榜时间过长的问题。
- 收藏/点赞/评论刷量数据对榜单的影响过大的问题。
- 博文过于追求博文长度的问题。
- 标题党的风气问题
- 太多同质化的入门文章。
- 领域过于集中在少数几个语言上的问题。
- …
我们再分析下这些问题反映的问题是什么:
- 博文应该能上榜,但是应该有半衰期。
- 博文的评论区应该有正常的交流和讨论,为了上榜而做的水评实际上降低了文章的内容质量(评论区)和社区整体的评论质量。
- 收藏说明这个文章对有些用户有用,但收藏不应该是一个「热」的体现,至少权重不应过大。
- 如果博文的长度是一个KPI,写作者可以通过复制粘贴低水平的入门材料,迅速包装出「重复的低水平的长文章」,那对作者和读者来说,都是一个低质量的内容。太长的博文也并不适合读者阅读。
- 标题里充斥广告和博眼球的低质量文本,正常的技术博文反而得不到上榜单机会。
- 内容的同质化和“过热”,那么其他的稀缺内容就总是会没有机会获得上榜机会。
综合来说,让高质量的博客获得更多相关的读者,提高生态质量,打击标题党, 平衡各种领域,适度考虑阅读量和热度。是热榜算法的改进目标。
热榜算法考虑哪些方面?
设计热榜算法,考虑几个不同的维度。
首先,交互数据的平衡
- 单一交互数据的归一化
- 不同交互数据映射到可以比较互相比较的数量级
- 避免单一交互数据对结果的绝对影响
其次,在数据的时间序列上,引入半衰期
- 同一个内容的数据的得分,随着时间衰减
- 同一个作者的得分,在时间窗口期内不应该重复上榜
第三,考虑内容的质量
- 标题的质量(例如标题党降权)
- 内容的质量(例如内容长度过长降权)
第四,考虑内容的领域
- 内容不应分布在少数几个过热的领域,例如都是 Python/Java
- 衡量稀缺度
参考成熟的算法
参考 Hacker News (ycombinator.com) 的热度算法。
S
=
V
∗
(
P
−
1
)
0.8
(
T
2
)
G
S = V*\frac{(P-1){0.8}}{(T+2)G}
S=V∗(T+2)G(P−1)0.8
其中:
- V 是领域权重
- P 是基于用户投票的交互数据点数
- T 是从创建开始到现在的时间,单位是小时
- G 是重力(Gravity)因子,用来衰减,默认是1.8
这个基本的公式,重要的地方在于考虑了时间衰减和领域权重,理解这个思想后,可以根据自己的数据做调整。
热榜算法规则
综合上述分析,引入的热榜算法的机制如下:
S
=
C
∗
V
∗
C
H
∗
P
(
T
2
)
1.1
=
热榜得分
S = C * V * CH*\frac{P}{(T+2)^{1.1}} = 热榜得分
S=C∗V∗CH∗(T+2)1.1P=热榜得分
C
=
w
1
∗
t
i
t
l
e
s
c
o
r
e
w
2
∗
c
o
n
t
e
n
t
s
c
o
r
e
w
1
w
2
=
内容得分
C = \frac{w1*titlescore + w2*contentscore}{w1+w2} = 内容得分
C=w1+w2w1∗titlescore+w2∗contentscore=内容得分
V
=
a
r
e
a
s
c
o
r
e
=
领域得分
V = areascore = 领域得分
V=areascore=领域得分
P
=
∑
i
=
1
n
w
i
∗
f
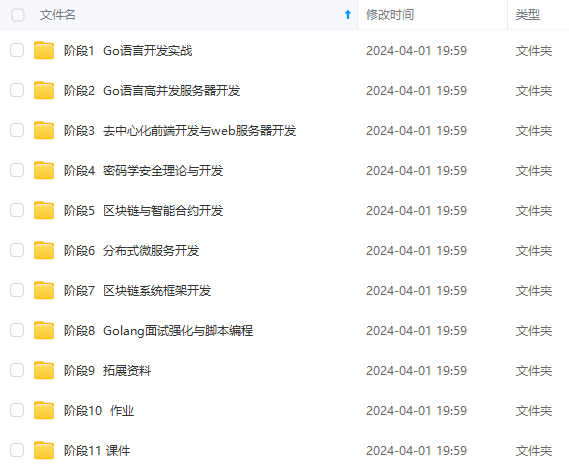
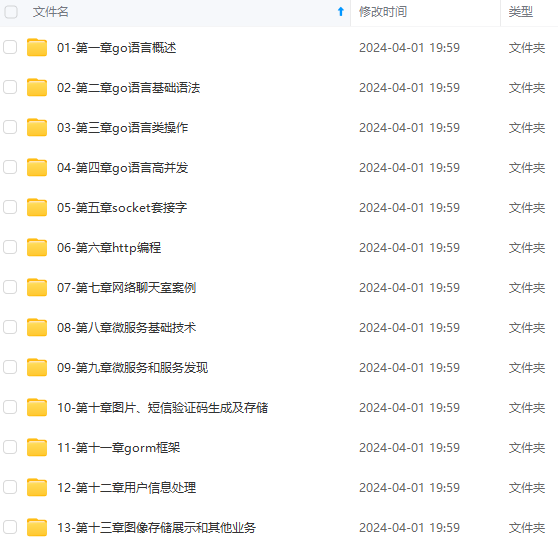
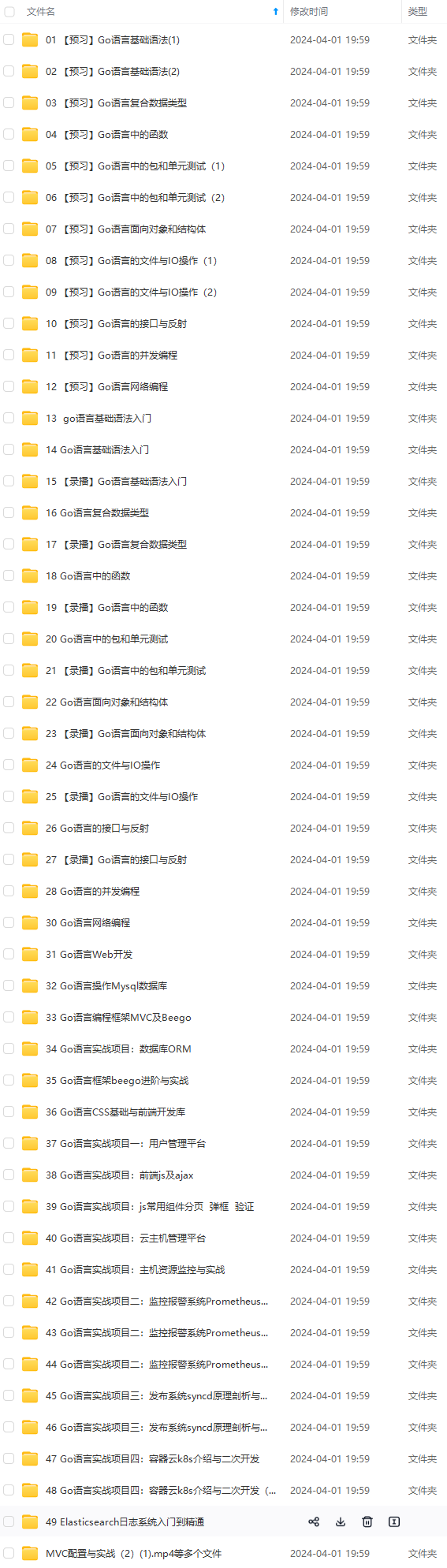
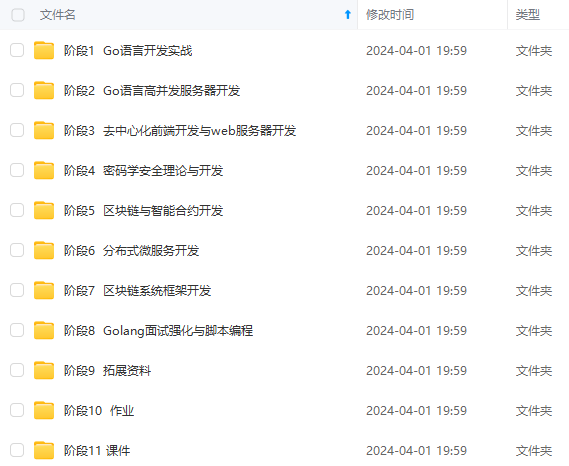
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
o
r
e
=
领域得分
V = areascore = 领域得分
V=areascore=领域得分
P
=
∑
i
=
1
n
w
i
∗
f
[外链图片转存中…(img-9oPGTW3v-1715636854272)]
[外链图片转存中…(img-8n3zFwHj-1715636854272)]
[外链图片转存中…(img-EjRnVi3N-1715636854272)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新

