
- 1Ubuntu服务器更改远程端口号的方法_ubuntu网络port怎么设置
- 2CloudFlare域名管理系统_cloudflare批量管理
- 3php论坛源代码,php论坛源代码下载
- 4AutoCompress: An Automatic DNN Structured Pruning Framework for Ultra-High Compression Rates
- 5Strongswan与Andriod野蛮模式L2TPoverIPsec对接有时候不成功。_strongswan ipsec不生效
- 6算法32:环形链表(有双指针)_求环形链表的节点数java
- 7idea2018项目导入2020.1idea依赖包失败的解决方法_getloadedimportedassetsandartifactids called with
- 8Python爬虫:代理ip电商数据实战
- 9聚类分析之 K均值_k均值聚类适用于什么样的数据
- 10python uiautomator2 安装及使用_python uiautomatic2 使用方法
深入解析Elasticsearch 8.4.1:Mapping与字段类型实战指南_elasticsearch8 mapping
赞
踩
标题Elasticsearch8.4.1常见字段类型介绍
Mapping概述
在Elasticsearch中,Mapping定义了索引中每个字段的类型、属性以及设置。Mapping的作用是告诉Elasticsearch如何索引文档中的字段,包括如何分析字段值以及如何存储它们。
常见字段类型
字符串类型
-
text:文本类型,存储的内容会被分词器处理,生成多个词根并存储在倒排索引中,支持全文搜索。
-
keyword:关键字类型,存储的内容不会被分词器处理,整个内容被当作一个词根存储在倒排索引中,支持精确值搜索。
-
数字类型
- long:64位长整型,取值范围为-263~263-1。
- integer:32位整型,取值范围为-231~231-1。
- short:16位短整型,取值范围为-32,768~32,767。
- byte:8位字节型,取值范围为-128~127。
- double:64位双精度浮点型。
- float:32位单精度浮点型。
- half_float:16位半精度浮点型。
- scaled_float:缩放类型的浮点数,底层基于long存储,支持一个固定的精度因子。
日期类型(date)
存储日期格式的字符串或自1970-01-01以来的毫秒数。
布尔类型(boolean)
取值为true、false或"true"、"false"。
- 1
范围类型(range)
支持integer_range、float_range、double_range、date_range、ip_range等范围类型。
- 1
复合类型
- 数组类型(array):支持任意字段类型的数组。
- 对象类型(object):存储类似JSON具有层级的数据。
- 嵌套类型(nested):支持数组类型的对象(Array[Object]),可层层嵌套。
地理类型
地理坐标类型(geo_point):用于存储地理坐标点。
地理地图(geo_shape):用于存储复杂地理形状,如多边形、线等。
- 1
- 2
特殊类型
- IP类型(ip):用于存储IP地址。
- completion类型:使用fst有限状态机来提供suggest前缀查询功能。
- token_count类型:提供token级别的计数功能。
- mapper-murmur3类型:安装插件后,可支持_size统计_source数据的大小。
- attachment类型:用于索引文件附件的内容。
- percolator类型:用于预定义的查询条件与文档进行匹配。
- 1
- 2
- 3
- 4
- 5
- 6
二进制类型(binary)
用于存储二进制数据,存储前需要先用Base64进行编码。
- 1
指定索引库字段类型mapping
PUT /mall-shop_1 { "mappings": { "properties": { "id":{ "type":"keyword" }, "title":{ "type":"text" }, "price":{ "type":"float" } } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
最高频使用的数据类型
-
text字段类型
-
text类型主要用于全文本搜索,适合存储需要进行全文本分词的文本内容,如文章、新闻等。
-
text字段会对文本内容进行分词处理,将文本拆分成独立的词项(tokens)进行索引
-
分词的结果会建立倒排索引,使搜索更加灵活和高效。
-
text字段在搜索时会根据分词结果进行匹配,并计算相关性得分,以便返回最佳匹配的结果。
-
-
keyword字段类型
-
keyword类型主要用于精确匹配和聚合操作,适合存储不需要分词的精确值,如ID、标签、关键字等。
-
keyword字段不会进行分词处理,而是将整个字段作为一个整体进行索引和搜索
-
这使得搜索只能从精确的值进行匹配,而不能根据词项对内容进行模糊检索。
-
keyword字段适合用于过滤和精确匹配,同时可以进行快速的基于精确值的聚合操作。
-
-
总结
-
在选择text字段类型和keyword字段类型时,需要根据具体的需求进行权衡和选择:
-
如果需要进行全文本检索,并且希望根据分词结果计算相关性得分,以获得最佳的匹配结果,则选择text字段类型。
-
如果需要进行精确匹配、排序或聚合操作,并且不需要对内容进行分词,则选择keyword字段类型。
-
创建索引并插入文档
创建索引
PUT /mall-shop_2 { "mappings": { "properties": { "title":{ "type": "text" }, "tags":{ "type": "keyword" }, "publish_date":{ "type": "date" }, "rating":{ "type": "float" }, "is_published":{ "type": "boolean" }, "author":{ "properties": { "name":{ "type":"text" }, "age":{ "type":"integer" } } }, "comments":{ "type": "nested", "properties": { "user":{ "type":"keyword" }, "message":{ "type":"text" } } } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
插入文档
PUT /mall-shop_2/_doc/1 { "title":"study elasticsearch 8.4.1", "tags":["study","elasticsearch","kibana"], "publish_date":"2024-06-24", "rating":4.5, "is_published":true, "author":{ "name":"lifly", "age":18 }, "comments":[ { "user":"jack", "message":"hi my name is jack" }, { "user":"tom", "message":"hello everyone ,I am tom" } ] }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
查询文档
GET /mall-shop_2/_mapping
- 1
查询结果
{ "took": 1, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 1, "relation": "eq" }, "max_score": 1, "hits": [ { "_index": "mall-shop_2", "_id": "1", "_score": 1, "_source": { "title": "study elasticsearch 8.4.1", "tags": [ "study", "elasticsearch", "kibana" ], "publish_date": "2024-06-24", "rating": 4.5, "is_published": true, "author": { "name": "lifly", "age": 18 }, "comments": [ { "user": "jack", "message": "hi my name is jack" }, { "user": "tom", "message": "hello everyone ,I am tom" } ] } } ] } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
根据关键词查询
GET /mall-shop_2/_search { "query": { "match": { "title": "elasticsearch" } } } ``` **查询结果** ```shell { "took": 1, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 1, "relation": "eq" }, "max_score": 0.2876821, "hits": [ { "_index": "mall-shop_2", "_id": "1", "_score": 0.2876821, "_source": { "title": "study elasticsearch 8.4.1", "tags": [ "study", "elasticsearch", "kibana" ], "publish_date": "2024-06-24", "rating": 4.5, "is_published": true, "author": { "name": "lifly", "age": 18 }, "comments": [ { "user": "jack", "message": "hi my name is jack" }, { "user": "tom", "message": "hello everyone ,I am tom" } ] } } ] } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
elasticsearch搜索引擎分词和默认分词器
什么是搜索引擎的分词
-
分词即使将文本拆分成单独的单次或词项的过程
-
分词是搜索引擎在建立索引和执行查询时的关键步骤,将文本拆分成单词,并构建倒排索引,可以实现更好的搜索和检索效果。
-
分词规则是指如何将文本进行拆分的规则和算法。
-
elasticsearch使用一些列的分词器(analyzer)和标记器(tokenizer)来处理文本内容。
分词过程
-
标记化(Tokenization):
-
分词的第一步是将文本内容拆分成单个标记(tokens),标记可以是单词、数字、特殊字符等。
-
标记化过程由标记器(tokenizer)执行,标记器根据一组规则将文本切分为标记。
-
-
过滤(Filtering):
-
标记化后,标记会进一步被过滤器(filters)处理。
-
过滤器执行各种转换和操作,如转换为小写、去除停用词(stop words),词干提取(stemming),同义词扩展等。
-
-
倒排索引(Inverted Indexing):
-
分词处理完成后,Elasticsearch使用倒排索引(inverted index)来存储分词结果。
-
倒排索引是一种数据结构,通过将标记与其所属文档进行映射,快速确定包含特定标记的文档。
-
-
查询匹配:
-
当执行查询时,查询的文本也会进行分词处理。
-
Elasticsearch会利用倒排索引来快速查找包含查询标记的文档,并计算相关性得分。
-
常见的分词介绍
- Standard分词器:
- 特点:Standard分词器是许多文本处理工具(如Elasticsearch和HanLP)中的默认分词器。它基于词典和规则进行分词,将输入的句子切分成一个个独立的词语。
- 支持:中英文混合分词,支持去除空格和标点符号,以及用户自定义词典。
- 应用:适用于一般性的文本处理任务,如全文搜索、文本分析等。
- Simple分词器:
- 特点:Simple分词器主要根据非字母字符将文本拆分为词项,并将词项转换为小写。
- 支持:不进行标点符号和停用词的过滤。
- 应用:在需要简单、快速分词的场景下使用,如日志分析、简单文本处理等。
- Whitespace分词器:
- 特点:Whitespace分词器根据空格字符将文本拆分为词项,不进行任何大小写转换、标点符号过滤或停用词过滤。
- 支持:保持原始文本中的空格和标点符号,适用于对空格敏感的文本处理任务。
- 应用:在处理结构化文本(如CSV文件)或需要保留原始格式信息的场景下使用。
- IK分词器:
- 特点:IK分词器是一个专门为中文设计的分词器,支持细粒度和智能化的中文分词。
- 功能:支持多种分词模式(如最大化分词模式、最小化分词模式、智能分词模式等),并允许用户自定义词典以适应特定场景和行业需求。
- 应用:在需要精确处理中文文本的搜索引擎、推荐系统、自然语言处理等领域广泛应用。
- 自定义分词器:
- 特点:自定义分词器允许用户根据自己的需求定义分词规则和处理逻辑。
- 支持:用户可以根据特定场景或任务的需要,定制分词器的行为,如添加自定义词典、定义特定的切词规则等。
- 应用:在需要处理特殊文本(如行业术语、专业词汇等)或实现特殊功能的场景下使用。通过自定义分词器,可以更好地满足特定任务的需求,提高分词效果和搜索结果的相关性。
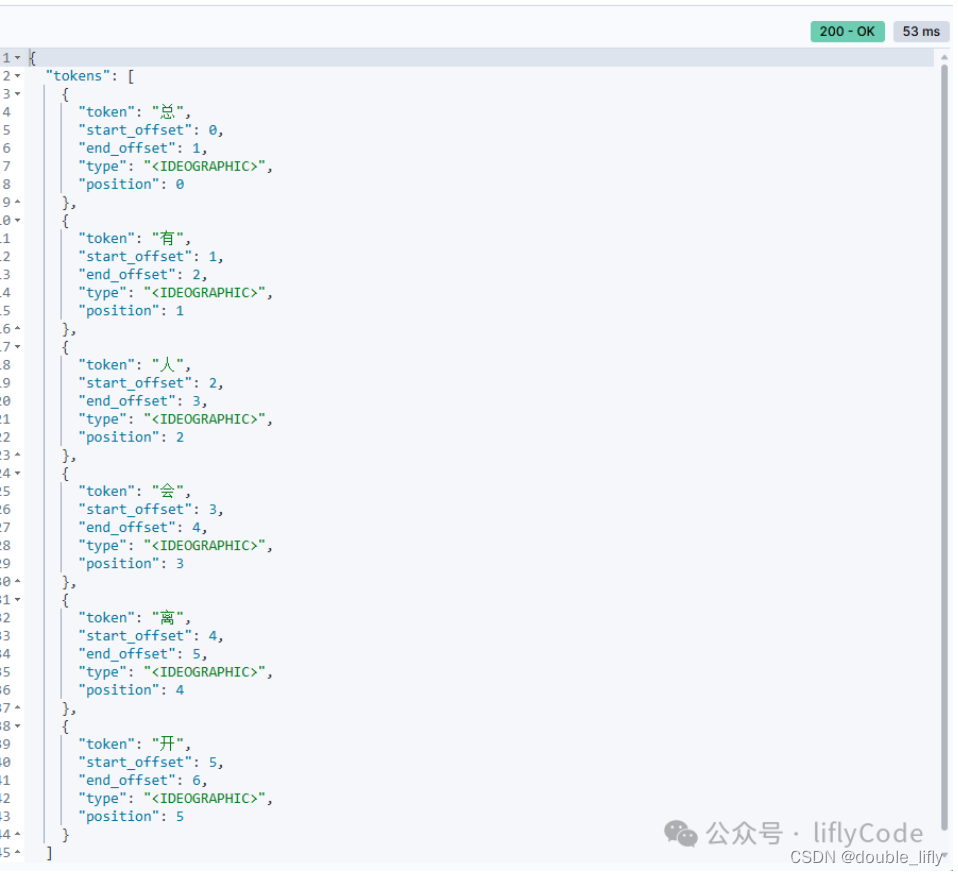
Strandard分词
POST /mall-shop_2/_analyze
{
"field": "title",
"text": "总有人会离开"
}
- 1
- 2
- 3
- 4
- 5
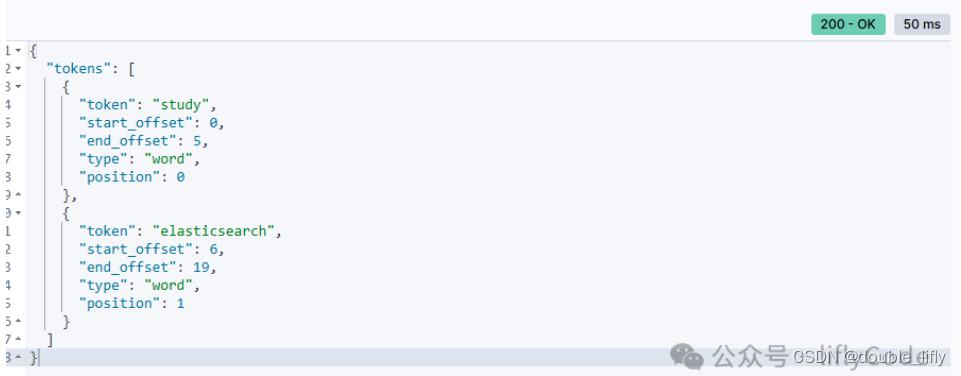
Simple分词
POST /mall-shop_2/_analyze
{
"analyzer": "simple",
"text": "study elasticsearch 8.4.1"
}
- 1
- 2
- 3
- 4
- 5
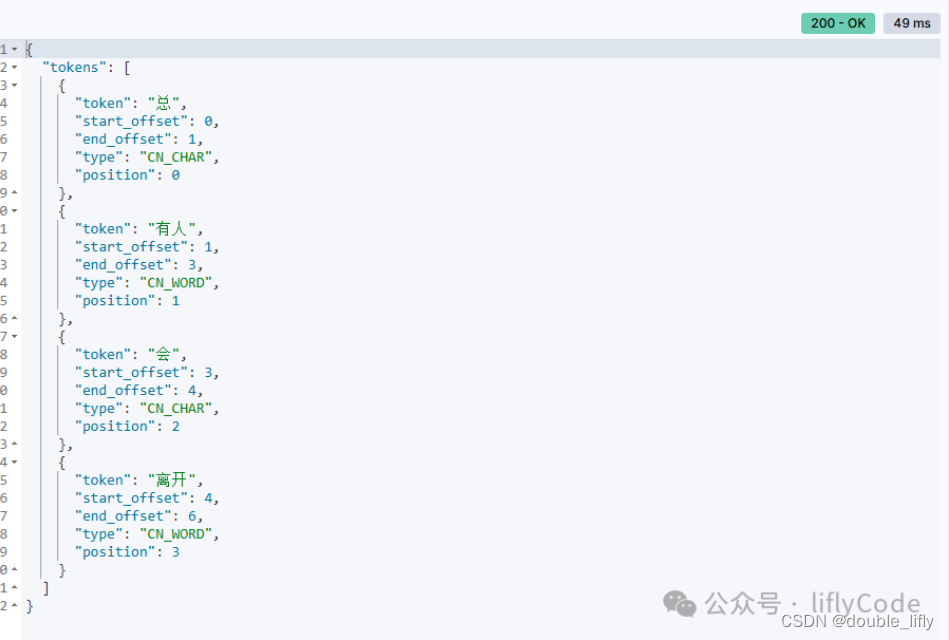
ik分词器
- ik_smart:会做最粗粒度的拆分
- ik_max_word(常用):会将文本做最细力度的拆分
POST /mall-shop_2/_analyze
{
"analyzer": "ik_smart",
"text": "总有人会离开"
}
- 1
- 2
- 3
- 4
- 5
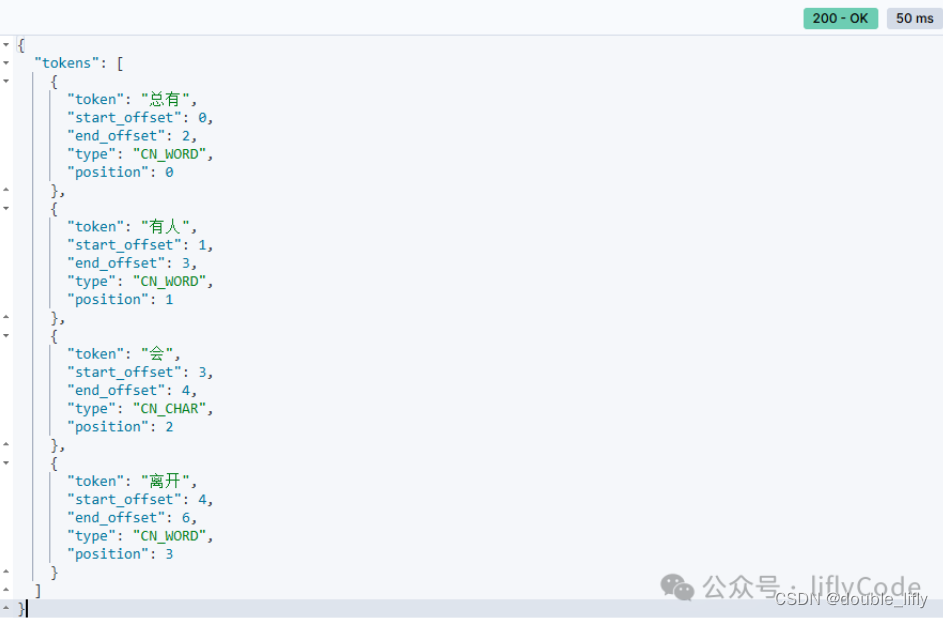
POST /mall-shop_2/_analyze
{
"analyzer": "ik_max_word",
"text": "总有人会离开"
}
- 1
- 2
- 3
- 4
- 5
本文全方位探讨了Elasticsearch 8.4.1中Mapping的定义及其关键作用,详尽介绍了各类常见字段类型的应用场景与特性,从基础的字符串、数字类型到复杂的地理空间类型,再到特殊用途的如Completion与Percolator类型,为开发者构建高效索引提供了坚实的基础。通过实践案例,展示了如何定义索引的Mapping、插入文档以及执行查询的具体过程,深刻阐述了text与keyword字段类型的选择原则,以及它们在全文搜索与精确匹配中的不同应用场景。
此外,我们还深入分析了Elasticsearch的分词机制,探讨了标准分词器、简易分词器、空白分词器以及强大的IK分词器等,揭示了它们各自的特点与适用场景,并通过实例演示了如何使用不同的分词器对文本进行分析,这对于优化搜索性能和提升查询准确性至关重要。
总之,理解并熟练运用Elasticsearch的Mapping配置与字段类型,以及掌握其强大的分词功能,是提升搜索质量和用户体验的关键。希望本文能成为你深入探索Elasticsearch之旅的有力指南,助你在构建高性能搜索引擎的道路上更进一步。
更多精彩请关注以下公众号



