
热门标签
热门文章
- 1Python使用win32gui.SetWindowPos置顶窗口
- 2https改造-python https 改造
- 3Python学习—Python虚拟环境(pyvenv、virtualenv)_pyvvfv
- 4入职百度-念念不忘,必有回响_百度 面试入职
- 5postgresql导出表结构以及数据到mysql_pg 导出表结构
- 6基于springboot的大学生租房平台的设计与实现论文_基于spring boot的房屋租赁服务平台的毕业论文
- 7时间序列新范式!多尺度+时间序列,刷爆多项SOTA_多尺度的时序信息
- 8灯光秀制作讲解_舞动光线MA2娱乐灯光舞美设计培训毕业展示第五期
- 9IC秋招RTL代码合集
- 10鸿蒙南向开发实战:标准系统-运行(基于RK3568开发板)_开发鸿蒙系统app安装到rk3568平台
当前位置: article > 正文
停用词究竟有何妙用:优化分词、精进LDA模型_lda模型 停词表
作者:码创造者 | 2024-07-10 04:00:53
赞
踩
lda模型 停词表
引言:
在自然语言处理领域,文本数据的处理是一项至关重要的任务。而在处理文本数据时,分词是一个必不可少的步骤,它将文本拆分成有意义的词语或短语,为后续的文本分析和挖掘奠定了基础。然而,传统的分词方法往往会将一些并不具备实质信息的词语也一并纳入考量,而这些词语往往被称为停用词。
停用词是指在文本处理过程中被忽略的词语,因为它们通常是高频出现且缺乏实际含义的词汇,如“的”、“了”、“和”等。在构建文本分析模型时,停用词的存在可能会干扰模型的准确性和效率,影响到对文本数据的深入理解和挖掘。
因此,建立一个有效的停用词库并将其应用于文本分析过程中变得至关重要。本文将探讨如何通过建立停用词库来优化分词,从而提升主题模型中的LDA(Latent Dirichlet Allocation)模型的性能。
剔除停用词的好处
除停用词在自然语言处理中是一个重要的步骤,它有以下几个好处
- 提高处理效率:停用词通常是频繁出现的功能词或无实际意义的词语,例如介词、连词、冠词、代词等。这些词汇对于文本的含义分析没有太大贡献,且会占据大量的存储空间和计算资源。因此,剔除停用词可以简化文本数据并提高处理效率。
- 减少噪声:剔除停用词可以减少文本中的噪声,使得后续的文本分析更加准确和有效。
- 突出关键信息:通过剔除停用词,可以使得文本中的关键词更加突出,有助于提取和理解文本的主题和关键信息。
需要注意的地方
- 避免过度剔除:过度剔除停用词可能会导致一些重要的语境信息丢失。例如,在情感分析中,一些常见的停用词如 “not”、“no” 等可能被保留,因为它们可以改变句子的情感倾向。
- 灵活处理:在某些特定的任务中,可能需要保留一些特定的停用词。例如,在问答系统中,一些常见的停用词如 “what”、“when”、“where” 等可能被保留,因为它们可以提供关于问题的重要上下文。
- 根据任务需求选择停用词表:不同的任务可能需要不同的停用词表。在选择停用词表时,需要综合考虑语言的特点、任务的领域和目标等因素。
实例
深入Spark与LDA:大规模文本主题分析实战 - 掘金 (juejin.cn)
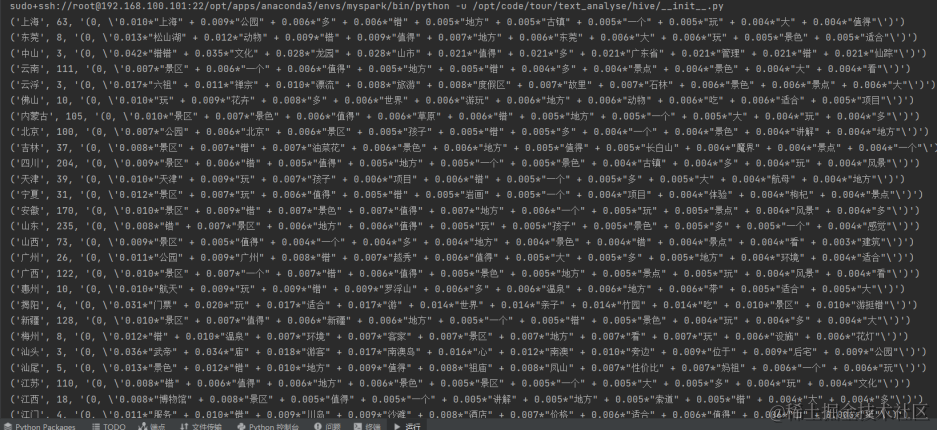
上述博客对景区游客评价文本进行了初步分析和LDA建模,但是因为建模效果并不好,下面我们将从建立停用词词库来优化分词以达到优化模型的角度来展示。
在此之前停用表选择的是nltk的中文停用词表,但主题提取后的效果并不好,还是出现了停用词“一个”,于网上搜索资料在GitHub中找到以下开源库:
https://github.com/goto456/stopwords
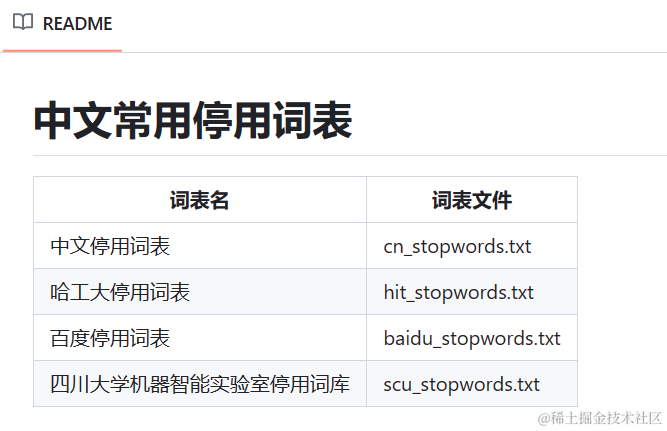
于博客中找到以下停用词表,拥有上千条停用词
最全中文停用词表(可直接复制)_停用词库-CSDN博客
将其放在项目中
将nltk替换为本地的停用词表
# stop_words = set(stopwords.words('chinese'))
# 使用本地停用词表替换nltk的停用词表
with open('/opt/code/tour/stop_words_Chinese', 'r', encoding='utf-8') as f:
stop_words = set(f.read().splitlines())
broadcastVar = spark.sparkContext.broadcast(stop_words)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
重新运行后
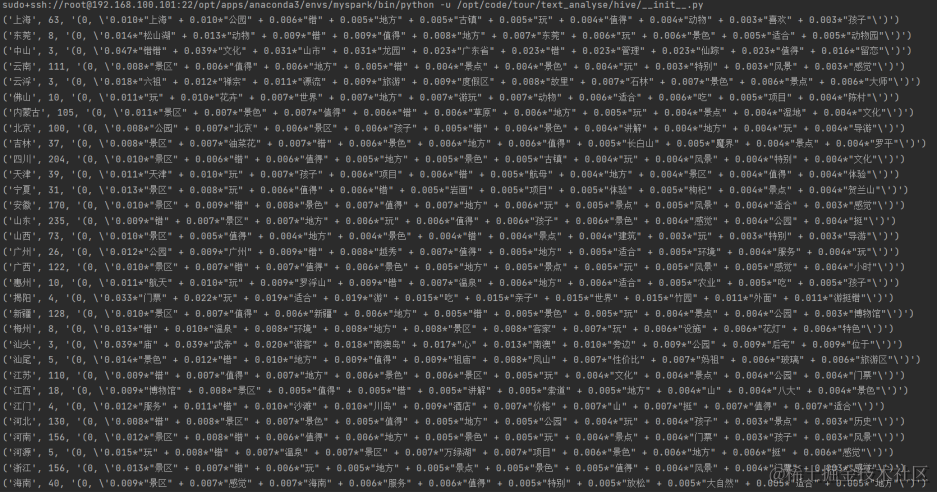
更加合理。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/码创造者/article/detail/804737
推荐阅读
相关标签

