
热门标签
热门文章
- 1【数学建模】—【新手小白到国奖选手】—【学习路线】_数学建模学习路线
- 2RISC-V教学内容及短视频吸引因素
- 313个Python GUI库_pygui
- 4【Linux】进程信号_3
- 5Stable Diffusion如何Mac电脑本地部署教程_stable diffusion mac
- 6IT入门知识第八部分《云计算》(8/10)_云计算在典型应用中通过提高弹性的计算资源和存储能力支持者什么的实施周有高
- 7使用 GPT-2 生成文本_gpt2在线生成
- 8linux编译opencv详细配置_linux 编译 opencv4.6
- 9Taro的UI框架_taro-ui
- 10关于Attention、Self-Attention机制的理解_attention与self-attention的区别
当前位置: article > 正文
大数据学习(二),hadoop集群重要节点概述以及HDFS文件系统的原理_hadoop集群节点
作者:码创造者 | 2024-06-30 10:36:40
赞
踩
hadoop集群节点
概述
在介绍hadoop集群的重要节点之前,先举一个简单的例子说明一下:
场景就是,我们有一个网站,网站中有很多用户,每个用户都有自己的信息和动态等,那么对于这些信息,我们网站的后台都是需要记录的。
怎么记录呢,直接就根据用户的标号,放在一个文件夹里吧,然后存在磁盘中(或者放在数据库里,都可以)
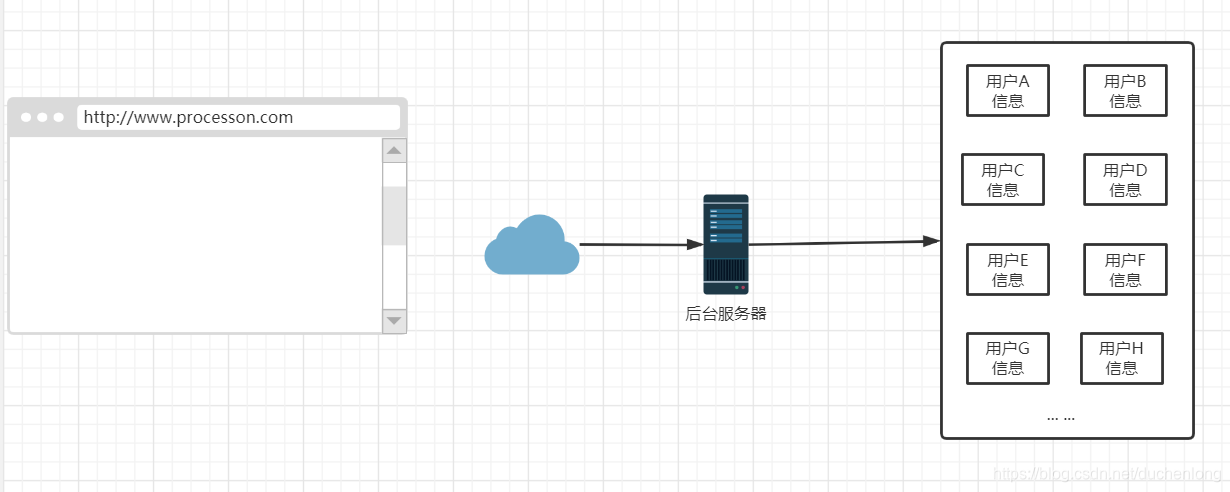
然后呢,随着时间的发展,用户的数量越来越多,我们后台的一个服务器里可能存不下这么多的数据,这个时候两种方式:
- 给磁盘扩容
- 加机器
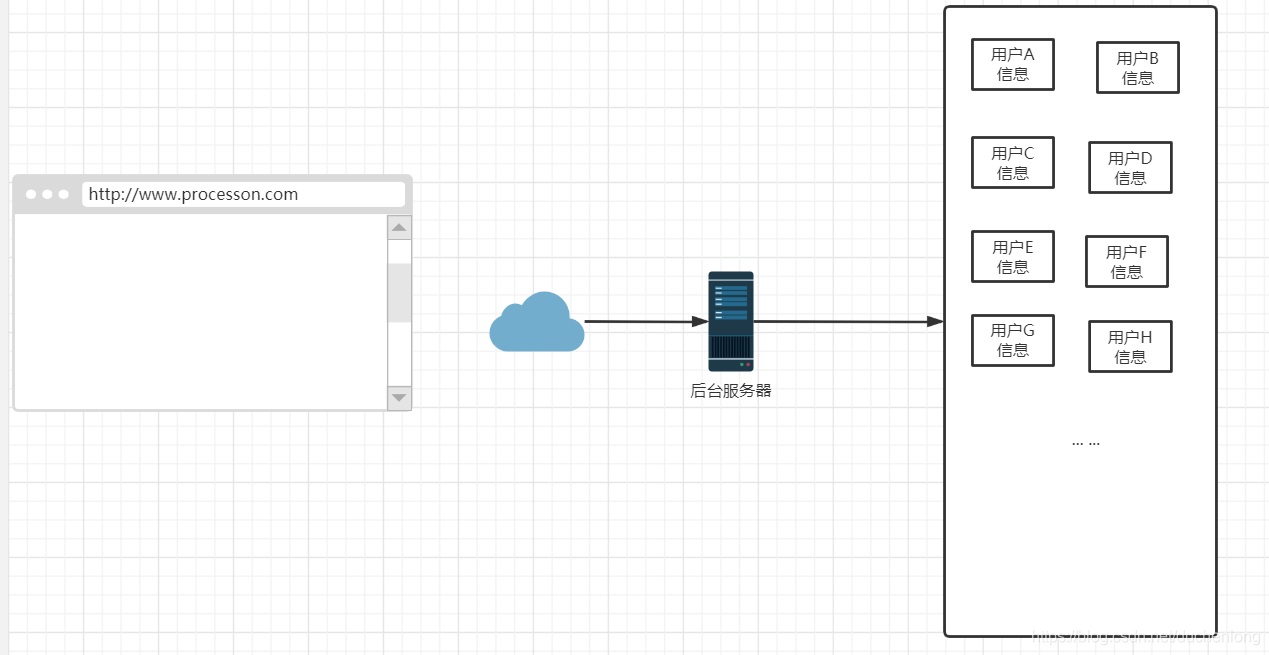
如果我们给磁盘扩容的方式去处理,但是是不是需要考虑到我们一个服务器的处理能力,这样虽然可以在同一台机器中存储下来,这样就意味着服务器在找一个资源的时候,需要花费的时间变长了,因为分母变大了,他的效率就会有点小
采用加机器的方式,利用Nginx这些技术,将不同用户的信息存储在多个服务器中,至于来了一个用户,怎么确定他的信息在哪里,就需要看后端的算法怎么写的了 ,可以使用哈希,也可以使用自己定义的规则,但是一定要让第二次请求用户信息时,可以找到第一个存储的位置
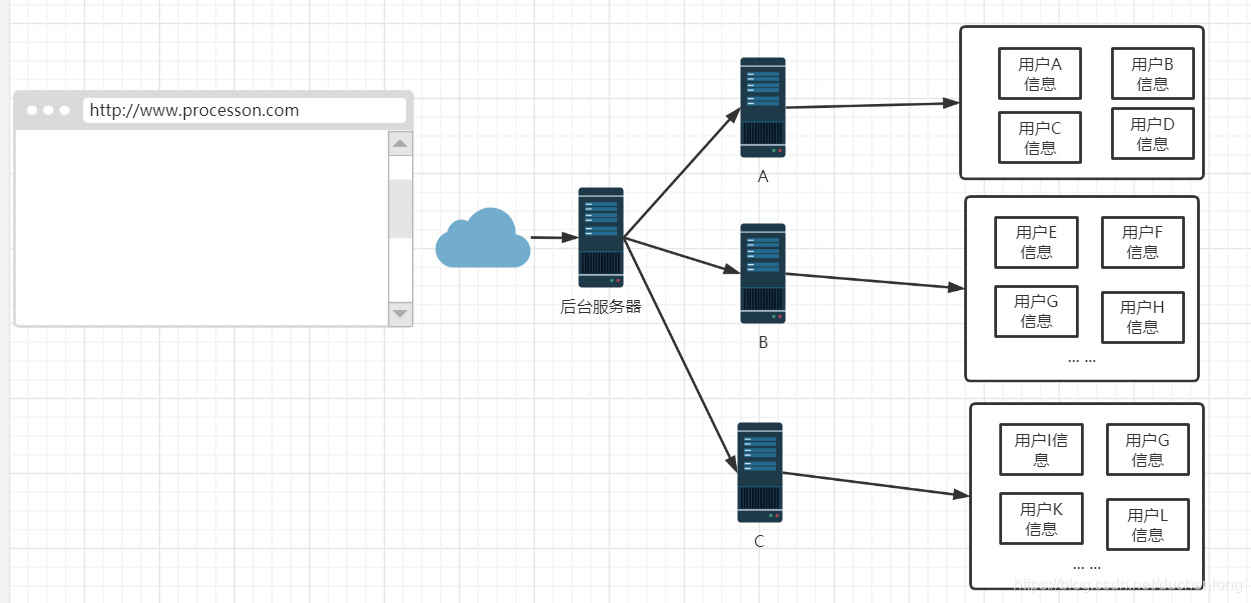
但是这样还是有着一些问题,就比如我中间的一些用户信息存储在服务器A,但是某一段时间服务器A突然宕机了,那么就意味着服务器A暂时无法提供数据。
这样该怎么解决呢,hadoop分布式存储中的一系列机制,就确保了数据的稳定

他框架的核心就是:
- 海量数据提供存储的
HDFS - 提供计算的
MapReduce,他的主要工作就是从磁盘或者网络中读取数据,以及对数据进行计算,就是那些IO密集和CPU密集工作
分布式文件系统的结构
在我们的操作系统(linux,Windows)中,文件系统会把磁盘空间划分为一些块,叫做磁盘块,他的大小一般为 512
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/码创造者/article/detail/772380
推荐阅读
相关标签

