
- 1[深度学习入门案例1]基于Keras的手写数字图像识别_基于keras的手写数字识别
- 2如何在ubuntu18.04下安装Firefox中国版解决Ubuntu与Windows下Firefox账号同步问题(已解决)_ubuntu 1804下载火绒
- 3实验一:人工智能之启发式搜索算法(含源码+实验报告)_人工智能之启发式搜索算法头歌
- 4车载ADAS面试题,零基础也能看得懂!
- 5第七章 字典和集合_从字典d = {'北京': 2030, '上海': 2200, '天津': 1985, '重庆':
- 6论文笔记:Pixel-Aware Stable Diffusion for Realistic Image Super-Resolution and Personalized Stylization
- 7如何查看docker 项目的配置文件_docker的配置文件在哪
- 8git 回滚指令_git rollback 命令行
- 9MongoDB快速上手_mogoose query 对象拷贝
- 10git回滚代码_在码云仓库回滚了版本号文件为什么还有
Hugging Face系列1:详细剖析Hugging Face网站资源——models/datasets/spaces_huaggingface 常用模型
赞
踩
前言
本系列文章旨在全面系统的介绍Hugging Face,让小白也能熟练使用Hugging Face上的各种开源资源,并上手创建自己的第一个Space App,在本地加载Hugging Face管线训练自己的第一个模型,并使用模型生成采样数据,同时详细解决部署中出现的各种问题。后续文章会分别介绍采样器及其加速、显示分类器引导扩散模型、CLIP多模态图像引导生成、DDMI反转及控制类大模型ControlNet等,根据反馈情况可能再增加最底层的逻辑公式和从零开始训练LLM等,让您从原理到实践彻底搞懂扩散模型和大语言模型。欢迎点赞评论、收藏和关注,这些对本系列文章非常重要。
本系列文章如下:
- 《详细剖析Hugging Face网站资源——models/datasets/spaces》:全面系统的介绍Hugging Face资源;
- 《详细剖析Hugging Face网站资源——实战六类开源库》
- 《从0到1:使用Hugging Face管线加载Diffusion模型生成第一张图像》:在本地加载Hugging Face管线训练自己的第一个模型,并使用模型生成采样数据,同时详细解决部署中出现的各种问题。
本篇摘要
本篇主要介绍Hugging Face。Hugging Face是一个人工智能的开源社区,是相关从业者协作和交流的平台。它的核心产品是Hugging Face Hub,这是一个基于Git进行版本管理的存储库,截至2024年5月,已托管了65万个模型、14.5万个数据集以及超过17万个Space应用。另外,Hugging Face还开源了一系列的机器学习库如Transformers、Datasets和Diffusers等,以及界面演示工具Gradio。此外,Hugging Face设计开发了很多学习资源,比如与NLP(大语言模型)、扩散模型及深度强化学习等相关课程。最后介绍一些供大家交流学习的平台。为了更有趣,本篇介绍了大量有趣的Spaces应用,比如换装IDM-VTON、灯光特效IC-Light、LLM性能排行Artificial Analysis LLM Performance Leaderboard和自己部署的文生图模型stable-diffusion-xl-base-1.0、对图片精细化的stable-diffusion-xl-refiner-1.0等。只要读者认真按着文章操作,上述操作都可自己实现。下面对以上内容逐一介绍。
1. Hugging Face Hub三大件
1.1 模型
1.1.1 模型简介
Hugging Face收录了大量的文生文、文生图、文生音频、文生视频及图生视频等多模态模型。模型界面的内容大致包括以下几方面:标签、模型卡片、文件和版本、社区交流、训练/部署/应用、推理API和应用的Spaces等。以大名鼎鼎的文生图模型stable-diffusion-xl-base-1.0为例,各部分所在区域如下图所示:

下面逐一介绍模型内容:
- 模型标签:相当于模型的关键字,包括使用的许可协议、安全协议、模型用途、引用的arXiv.org论文、开发库、支持语言、部署方法等。
- 模型卡片:是了解模型的主要途径,内容包括模型介绍(模型名称、开发者、输入输出、模型结构、发布日期及状态等)、使用说明(应用代码或命令行、软硬件说明、支持库等)、训练数据及评判基准等。
- 文件和版本:存储模型版本对应的文件,不需要授权的文件可以直接下载。
- 社区交流:包括社区求助和问题讨论等贴吧交流。
- 推理API:这里输入prompt,模型会推理出结果,相当于一个简易的demo。但有的程序不支持推理API。
- Spaces应用:使用此模型部署的Space。Space相当于一个封装了该模型的App,并通常提供一个UI给用户使用。
1.1.2 制作模型卡片
模型卡片是对模型的重要说明,是了解模型的窗口。当把模型开源到Hugging Face时,就需要制作卡片对模型进行详细介绍,示例代码如下所示:
from huggingface_hub import ModelCard, ModelCardData, EvalResult # Using the Template,Including Evaluation Results(Optional) card_data = ModelCardData( language='en', license='mit', library_name='timm', tags=['image-classification', 'resnet'], datasets=['beans'], metrics=['accuracy'], eval_results=[ EvalResult( task_type='image-classification', dataset_type='beans', dataset_name='Beans', metric_type='accuracy', metric_value=0.9, ), ], model_name='my-cool-model', ) card = ModelCard.from_template( card_data, model_description='This model does x + y...' ) card.push_to_hub(hub_model_id)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
1.1.3 模型下载和上传
用户可以在Hub下载或上传模型,比如下载BERT的基础模型的git命令及huggingface-cli命令如下:
git clone https://hf.co/bert-base-uncase # git命令,可在最后添加下载目录
huggingface-cli download --resume-download google-bert/bert-base-uncased --local-dir bert-base-uncased #huggingface-cli命令,--local-dir用于建立软链接
- 1
- 2
上传模型的代码如下(这里只做简单演示,代码讲解及应用参见后续):
from huggingface_hub import HfApi, create_repo
from huggingface_hub import get_full_repo_name
model_name = "XXX"
hub_model_id = get_full_repo_name(model_name) #获取完整路径
create_repo(hub_model_id) #创建存储库
api = HfApi() #获取上传接口,并上传文件夹及文件
api.upload_folder(folder_path=f"{model_name}/scheduler", path_in_repo="", repo_id=hub_model_id)
api.upload_folder(folder_path=f"{model_name}/unet", path_in_repo="", repo_id=hub_model_id)
api.upload_file(path_or_fileobj=f"{model_name}/model_index.json", path_in_repo="model_index.json", repo_id=hub_model_id)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1.1.4 模型应用
我们可以在通过几行简单的代码来使用这些模型,并查看其生成效果。单击训练/部署/应用区域的“Deploy->Inference API",出现如下不同语言的应用代码:

也可选择其它的应用方案,比如单击“Use in Diffusers”获取如下代码:
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0")
- 1
- 2
- 3
Q:你能看出上面两种应用方案的不同吗?
1.2 数据集
1.2.1 数据集简介
上文已提到,Hugging Face Hub开源和维护了大量的数据集,它还按照语言对数据集进行了拆分,并清理了文章中不必要的符号信息,以便开发者直接调用。以databricks公司收集的数据集databricks-dolly-15k为例,它是指令引导式的开源数据集,可用于任何商业和学术目的,这些记录符合InstructionGPT论文中概述的行为类别,包括封闭式QA、开放式QA、文本生成、信息提取、标签分类、头脑风暴和概括总结等。数据集界面如下图:
 其内容形式大致与模型界面类似,这里不再赘述。唯一需要关注的不同点是Viewer,通过Viewer可以概览数据集中的数据,对各类数据记录有个大概认识。
其内容形式大致与模型界面类似,这里不再赘述。唯一需要关注的不同点是Viewer,通过Viewer可以概览数据集中的数据,对各类数据记录有个大概认识。
1.2.2 调用及下载
对于经典数据集databricks/databricks-dolly-15k的调用代码如下,也可以点击“Use in Datasets library”查看这段代码:
from datasets import load_dataset
dataset = load_dataset("databricks/databricks-dolly-15k", split="train")
train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=128, shuffle=True)
- 1
- 2
- 3
- 4
也可以通过命令huggingface-cli下载代码:
huggingface-cli download --repo-type dataset --resume-download databricks/databricks-dolly-15k --local-dir databricks-dolly-15k
- 1
1.2.3 AutoTrain在线微调
Hugging Face Hub还支持通过上传自己的数据集,直接在线微调模型。我们以cognitivecomputations/dolphin-2.9-llama3-8b为例,此时有两种方法创建AutoTrain Project:第一种,在AutoTrain功能主页点击“Create new project”,如下图:

第二种,需在模型界面点击Train->Auto Train(部分模型不支持)->Create a new AutoTrain project,后续操作类似,点击后出现如下界面:
 此时自动创建Space,起名为cognitivecomputations-dolphin-2.9-llama3-8b,协议选择other(可在模型标签查看其协议),Space SDK选择Docker,Docker template选择AutoTrain,其余保持默认,点击“Create Space”。
此时自动创建Space,起名为cognitivecomputations-dolphin-2.9-llama3-8b,协议选择other(可在模型标签查看其协议),Space SDK选择Docker,Docker template选择AutoTrain,其余保持默认,点击“Create Space”。
此时没登录会提示登录,登录后对新建AutoTrainLLM进行授权,授权后进入训练界面,如下图所示:
 此处操作步骤如下:
此处操作步骤如下:
- 为微调工程命名(名字中不能有特殊字符,否则回报不知名错误,如笔者图中去掉名字中点号后才运行成功,即cognitivecomputations-dolphin-29-llama3-8b),也可以选择已创建的工程。
- Hardware默认或调整为自己的硬件环境,Task选择为LLM SFT,Base Model选择需要微调的模型,此处选为cognitivecomputations/dolphin-2.9-llama3-8b。
- 重点来了,Dataset训练数据集即对模型进行微调的数据集,如果有自己的数据集,选择Upload Dataset后上传自己的数据集。否则可以从Hugging Face Hub中挑选数据集,如我们选用1.2.2小节提到的数据集databricks/databricks-dolly-15k,根据数据集的训练提示,Train Split填为15000,然后根据实际需要调节右侧训练参数Training Parameters,最后点击“Start Training->Yes, I’m sure”,微调成功后会提示“Success! Monitor your job locally /in logs”。
此时查看右上角的Logs,会有训练的日志输出,如下图:
 普通用户尤其是企业用户,可以用自己企业的数据微调已有的优秀LLM模型,从而调制自己专有的LLM模型。
普通用户尤其是企业用户,可以用自己企业的数据微调已有的优秀LLM模型,从而调制自己专有的LLM模型。
1.3 Space应用
1.3.1 内容简介
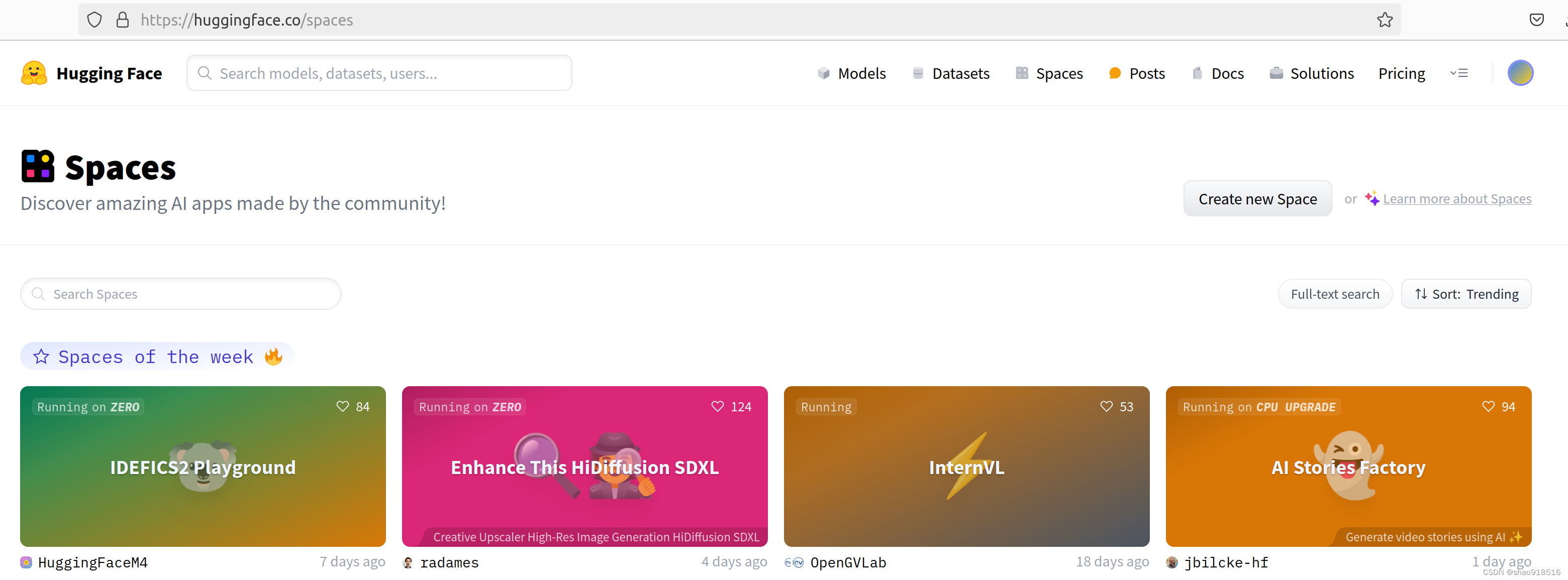
此节我们介绍丰富多彩的Spaces应用,帮大家了解Spaces一二,方便大家可以自己探索并使用这些令人眼花缭乱又惊喜不断的Apps。其Spaces首页如下图:
 使用Spaces可在几分钟内构建、托管和共享ML应用程序,它具有如下优势:
使用Spaces可在几分钟内构建、托管和共享ML应用程序,它具有如下优势:
- Get started quickly:提供了构建和托管大型人工智能应用程序和演示所需的所有工具,比如CLion,KDevelop等。
- Optimized for AI:运行在Hugging Face优化的ML基础硬件设施上,只需点击几下即可大规模部署您的应用程序。
- Zero GPU:通过一种新型的分布式GPU,可以在运行中自动扩展应用程序。
- Craft collaboratively(协同制作):通过开箱即用的基于git的版本控制工作流,个人和团队可以轻松协作构建人工智能应用程序。
- Build it your way:使用Streamlit、Gradio甚至Docker来构建、部署和托管人工智能应用程序。
- Various Hardware:从免费的CPU到TPU,为您的应用程序获得合适的硬件。
- Build your portfolio:向社区展示您的工作,构建独特的应用程序,并与其他人工智能社区人员建立新的联系。
Hugging Face为每个Space应用提供了免费的两核CPU+16GB内存的服务器资源,但免费服务器会在闲置一定时间后自动进入休眠状态,并在有用户访问时被再次唤醒。为了获得更稳定访问,可以付费升级、向社区申请赞助或向官方申请免费升级。
下面我们就来看一看具体的Spaces应用并亲手创建一个自己的Spaces应用程序。
1.3.2 虚拟换装:IDM-VTON
IDM-VTON是一个在线衣服试穿程序,通过上传人像和衣服照片,可以自动生成试穿效果,其界面如下图所示:

操作步骤如下:
- 上传人物照片和衣服照片,也可选择示例图。
- 编写prompt(可留空)添加自己想要的效果,如beautiful woman, detailed face, sunset over sea, top light。
- 可勾选自动生成掩码图像,以便加速生成同一个人物图片的试穿效果。 可勾选自适应调整大小,避免图片被拉伸变形。
- 最后,还可通过Advances设置去噪步数和随机种子。增加去噪步数可以生成更精美图像,当对本次生成结果不满,可设置不同的随机种子来生成不同效果的图像。
设置完毕后点击最下方的"try on",等待几十秒即可看到试穿效果。
1.3.3 灯光特效:IC-Light
通过IDM-VTON换装的图片还缺点大片特效,IC-Light正好可以添加不同风格的光影特效,让你的图片秒变大师手笔,效果如下图所示:

操作步骤如下:
- 上传需换装的照片;
- 选择灯光偏好、人物细节及灯光细节,选择后会在输入框中出现对应的prompt,当然也可以自己编写prompt;
- 选择生成图片张数、随机种子及分辨率,分辨率最大支持1024*1024;
- 点击Advanced options(高级可选),选择调整steps(迭代步数)、CFG Scale(代表图像与提示的匹配程度)、Lowres Denoise(低分辨率去噪)、Highres Denoise(高分辨率去噪)、Highres Scale(高分辨率缩放)、Prompt和Negative Prompt(负面提示),读者可根据自己需要尝试不同的组合,体验不同的生成效果。
设置完毕后点击"Relight",等待几十秒钟即可得到不同特效的照片以及去除背景的前景照片,最后我们就可以把精美大片分享给自己的好友啦。
1.3.4 Artificial Analysis LLM Performance Leaderboard
Artificial Analysis LLM Performance Leaderboard(人工分析LLM性能排行榜)是通过LLM提供的API,独立进行性能基准&计价的榜单,表中罗列了各模型的API供应商、模型名称、上下文窗口、模型质量、计价(美元/百万tokens)、吞吐量、延迟和详细分析,如下图所示:
 其中上下文窗口、模型质量、计价、吞吐量和延迟均可展开,以便查看更详细的性能指标。
其中上下文窗口、模型质量、计价、吞吐量和延迟均可展开,以便查看更详细的性能指标。
点击详细分析中的Model/Providers,会跳转到artificialanalysis.ai,Model通过图表的形式提供了该模型更详细的性能分析,Providers则通过图表对比该厂商名下的各个不同版本的Moel的各项指标,方便我们根据自己的需要选择,如下图所示:

1.3.5 创建自己的Space应用
通过Hugging Face提供的免费硬件,我们可以创建属于自己的Space应用,并可供它人访问、下载和互动。这里介绍两种创建方式:第一种,在Spaces主页点击“Create new space”,如下图:
 第二种,直接引用已有模型作为基础模型,创建自己的Space。为了让大家体验不同的模型,这里引用1.1.1节介绍的文生图模型stabilityai/stable-diffusion-xl-base-1.0。在模型界面点击Deploy->Spaces,弹出如下窗口:
第二种,直接引用已有模型作为基础模型,创建自己的Space。为了让大家体验不同的模型,这里引用1.1.1节介绍的文生图模型stabilityai/stable-diffusion-xl-base-1.0。在模型界面点击Deploy->Spaces,弹出如下窗口:

点击“Create new Space”,跳到创建Space页面,如下图所示:

操作步骤如下:
- 选择创建者和填写Space名称,然后选择License,License可从模型标签中查找。
- Space SDK选为Gradio,对应的Gradio template选为text-to-image。
- Space hardware选择免费版即可,不过免费版在两天闲置后就会陷入休眠,如长期使用可升级为收费版硬件。
- Preset Files为预置文件,如果通过Spaces主页创建,则预置文件为空。
- 操作权限根据提示和自己需要选择,此处选为Public。
操作完毕后,点击Create Space进入Building&Starting界面,等待1分左右,就会创建成功。输入Prompt:There are a panda and a tiger playing happily in the bamboo forest, and there is a big waterfall next to them, with sunshine lighting, Superfine details. 最终效果如下图:
HOMEWORK:使用stabilityai/stable-diffusion-xl-refiner-1.0可以渲染更多的图片细节,其模型界面如下图:

作者在创建它的Space时,遇到错误提示ValueError: Unsupported pipeline type: image-to-image,您可以解决这个错误吗?
通过文生图模型生成图片后,再通过精细化模型对细节进行调整,最后呈现效果如下图所示:
 可以看到,熊猫和老虎的眼睛、嘴巴、爪子和瀑布、竹林、石头的细节都得到了强化。您还可以用它来美化老照片、去除马赛克等。
可以看到,熊猫和老虎的眼睛、嘴巴、爪子和瀑布、竹林、石头的细节都得到了强化。您还可以用它来美化老照片、去除马赛克等。
参考资料:
- 《扩散模型从原理到实战》,李忻玮,苏步升,徐浩然,余海铭著,人民邮电出版社。

