
热门标签
热门文章
- 1P1164-小A买菜(动态规划,01背包)
- 2Web2.0里面的Tags功能的实现_webui tagger
- 3Redis踩坑
- 4spring-cache集成redis_springcache集成redis
- 5IDEA使用(03)_git撤回(已经commit未push的)操作
- 61970-2021年全国区县级碳排放数据8_edgar的中国碳排放数据
- 7C语言与密码学算法实现:RSA、AES、ECC等公钥与对称加密算法详解(一)_rsa ecc des aes
- 8xilinx原语(a7是不支持idelay2及ctl原语的)_ibufds gte3
- 9推荐switch-case语句使用枚举来判断_switch case 枚举
- 10飞凌嵌入式丨2020年技术干货合集大放送!_飞凌1103网关
当前位置: article > 正文
llama_factory的使用_llama factory使用
作者:正经夜光杯 | 2024-07-07 08:28:16
赞
踩
llama factory使用
1.git clone llama_factory到本地
2.记得安环境,在clone后

3.多显卡要设置一下
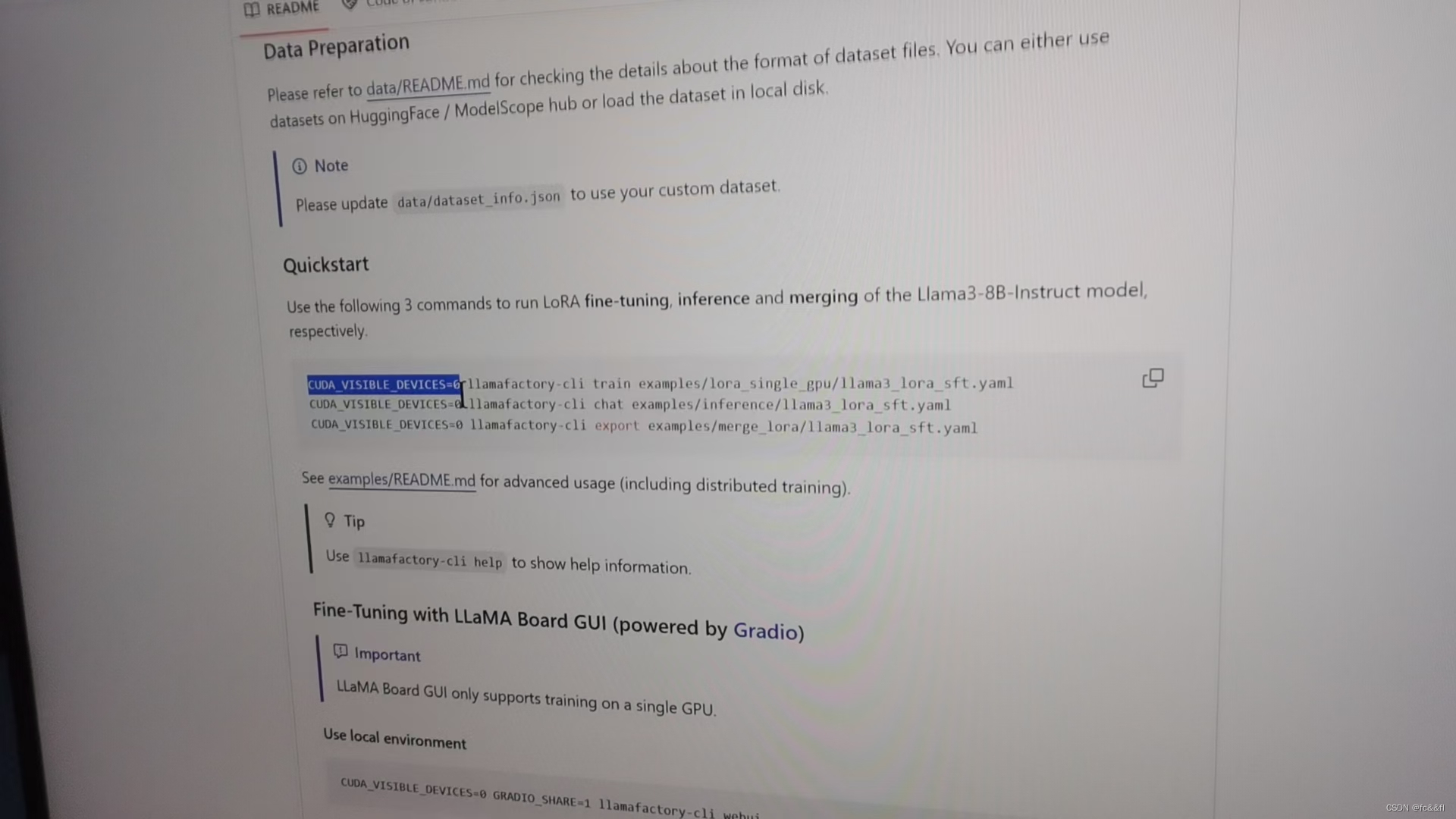
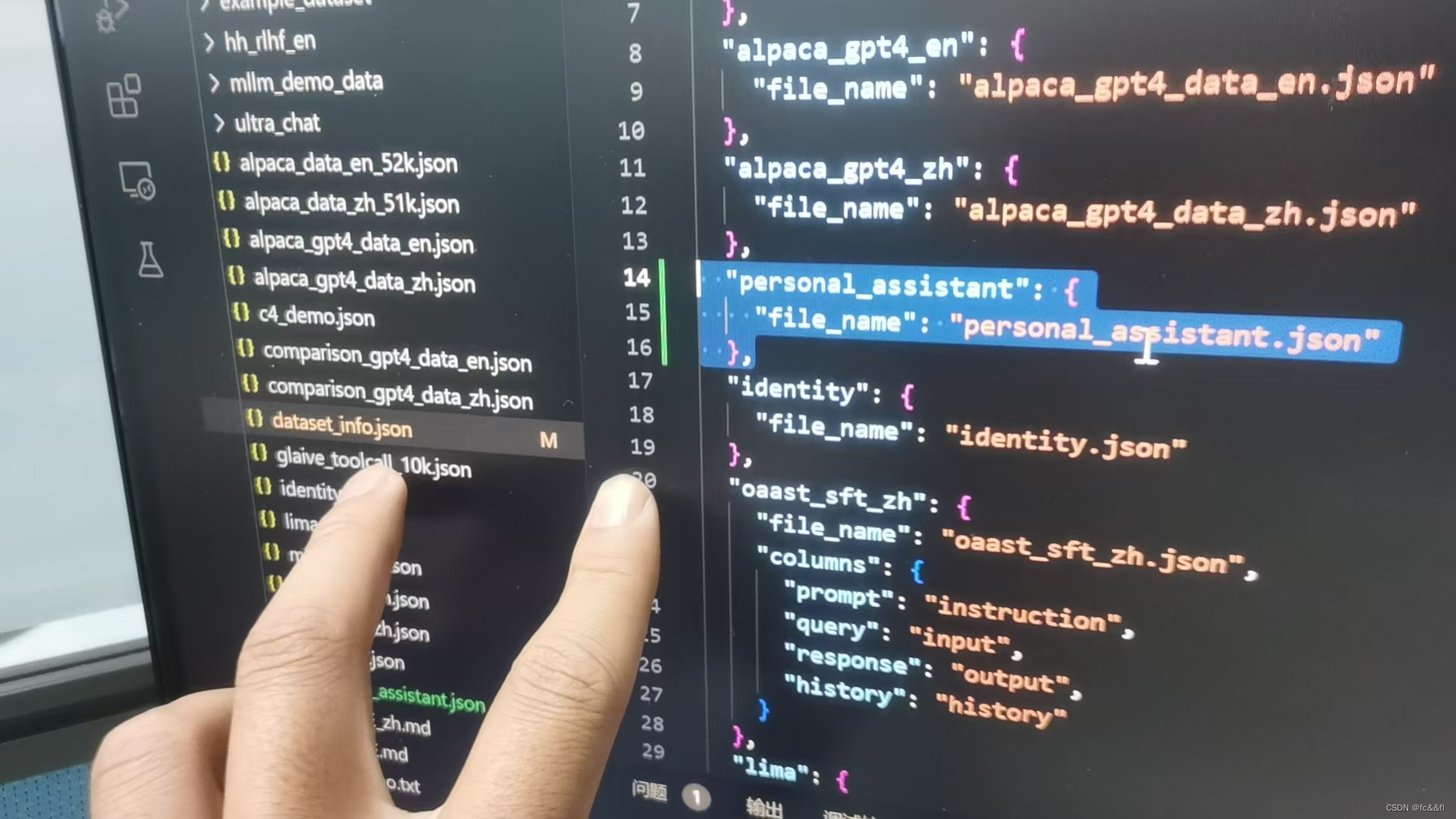
4.数据文件放在data里面,仿照模板里的格式
5.进入llama_factory微调页面
一定要注意训练的时候改下模板,不要default,改成你训练模型的模板,不然等你推理的时候会胡言乱语

python src/webui.py
- 训练模型
- llamafactory-cli train \
- --stage pt \
- --do_train True \
- --model_name_or_path /home/models/Qwen1.5-7B \
- --preprocessing_num_workers 16 \
- --finetuning_type lora \
- --template qwen \
- --flash_attn auto \
- --dataset_dir /home/cxh/LLaMA-Factory/data \
- --dataset a1_demo \
- --cutoff_len 1024 \
- --learning_rate 5e-05 \
- --num_train_epochs 70.0 \
- --max_samples 1024 \
- --per_device_train_batch_size 2 \
- --gradient_accumulation_steps 8 \
- --lr_scheduler_type cosine \
- --max_grad_norm 1.0 \
- --logging_steps 5 \
- --save_steps 100 \
- --warmup_steps 0 \
- --optim adamw_torch \
- --packing True \
- --report_to none \
- --output_dir saves/Qwen1.5-7B/lora/train_2024-06-21-11-00-39 \
- --bf16 True \
- --plot_loss True \
- --ddp_timeout 180000000 \
- --include_num_input_tokens_seen True \
- --lora_rank 8 \
- --lora_alpha 16 \
- --lora_dropout 0 \
- --lora_target all
-
- 运行对话
- CUDA_VISIBLE_DEVICES=0 llamafactory-cli chat --model_name_or_path /home/models/Qwen1.5-7B --adapter_name_or_path /home/cxh/LLaMA-Factory/src/saves/Qwen1.5-7B/lora/train_2024-06-21-11-37-49 --template qwen --finetuning_type lora
6.如果显存爆了,配置一下
vim ~/.bashrc
#然后在文件中加入下面这行
export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:86
#保存退出,然后运行下面的指令
source ~/.bashrc
7.llama_factory介绍:
10分钟打造你个人专属的语言大模型:LLaMA-Factory LLM Finetune_哔哩哔哩_bilibili
部分训练数据展示
- [{
- "text": "page_content='内容1111' metadata={'source': 'D:\\\\Downloads\\\\维护文档\\\\docs/2006-三体.txt'}"
- }, {
- "text": "page_content='内容2222' metadata={'source': 'D:\\\\Downloads\\\\维护文档\\\\docs/2006-三体.txt'}"
- },
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/正经夜光杯/article/detail/795172
推荐阅读
相关标签

