
- 1oracle千万级数据处理,Oracle千万级数据更新
- 2程序猿使用Python的tkinter库进行GUI编程肯定要会的事件处理啦_tkinter 猿编程
- 3解决文件超过大小限制(50M)不能推送到远程仓库
- 4变分模态分解(VMD)与其改进算法
- 5初探使用iOS 7 Sprite Kit与Cocos2d开发游戏的对比_spritekit 流星效果
- 6真实环境IBMP740小机确定网卡插槽及ip对应关系.
- 7逻辑漏洞——会话管理问题_会话管理缺陷练习
- 8CAD2023 2024 2025以上版本出现无法运行 AutoCAD,原因可能如下1) 此版本的 AutoCAD 安装不正确_autocad2025安装错误2147024891
- 9精通AI虚拟数字人制作与应用_ai 数字人开发
- 10自然语言处理 —— 2.7负采样_负采样才到相同的怎么版
【环境空气质量评价挑战赛】baseline,Python程序设计基础教程_空气质量记录pycharm代码
赞
踩
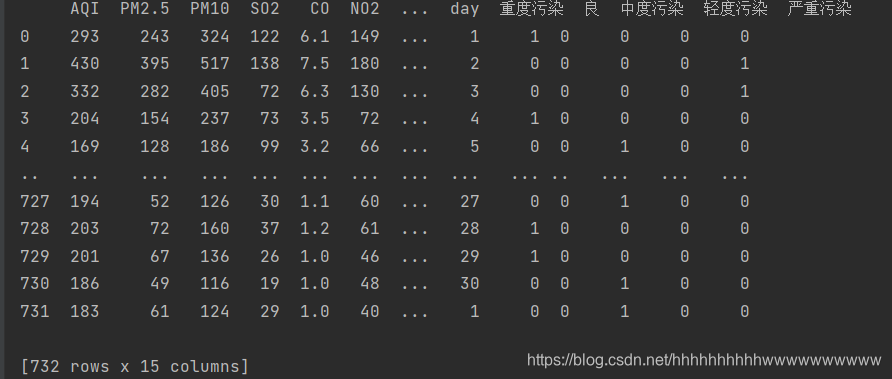
第三列 质量等级,共5个等级,这个毫无疑问用OneHot编码做,我使用pandas 自带的方法实现OneHot编码,编码完成后把质量等级和日期列删除,代码如下:
df = pd.DataFrame({‘质量等级’: [‘重度污染’, ‘良’, ‘中度污染’, ‘轻度污染’, ‘严重污染’]})
ff = pd.get_dummies(data[‘质量等级’].values)
data[‘重度污染’] = ff[‘重度污染’]
data[‘良’] = ff[‘良’]
data[‘中度污染’] = ff[‘中度污染’]
data[‘轻度污染’] = ff[‘轻度污染’]
data[‘严重污染’] = ff[‘严重污染’]
del data[‘质量等级’]
del data[‘日期’]
print(data)
运行结果:
标签数据处理 标签采用MinMaxScaler(feature_range=(0, 1)),把标签缩放到0-1之间,方便预测,代码如下:
scaler_y = MinMaxScaler(feature_range=(0, 1))
train[‘IPRC’] = scaler_y.fit_transform(train[‘IPRC’].values.reshape(-1, 1))
target = train[‘IPRC’]
数据分析的完整代码如下:
import numpy as np
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler, MinMaxScaler
train = pd.read_csv(‘data/train/train.csv’)
print(train.head(5))
test = pd.read_csv(‘data/test/test.csv’)
smb = test[‘日期’].values
scaler_y = MinMaxScaler(feature_range=(0, 1))
train[‘IPRC’] = scaler_y.fit_transform(train[‘IPRC’].values.reshape(-1, 1))
target = train[‘IPRC’]
del train[‘IPRC’]
data = pd.concat([train, test], axis=0, ignore_index=True)
data = data.fillna(0)
data[“year”] = pd.to_datetime(data[“日期”]).dt.year
data[“month”] = pd.to_datetime(data[“日期”]).dt.month
获取日
data[“day”] = pd.to_datetime(data[“日期”]).dt.day
df = pd.DataFrame({‘质量等级’: [‘重度污染’, ‘良’, ‘中度污染’, ‘轻度污染’, ‘严重污染’]})
ff = pd.get_dummies(data[‘质量等级’].values)
data[‘重度污染’] = ff[‘重度污染’]
data[‘良’] = ff[‘良’]
data[‘中度污染’] = ff[‘中度污染’]
data[‘轻度污染’] = ff[‘轻度污染’]
data[‘严重污染’] = ff[‘严重污染’]
del data[‘质量等级’]
del data[‘日期’]
print(data)
cols = [“PM2.5”, “PM10”, “SO2”, “CO”, “NO2”, “O3_8h”,“day”,“month”,“year”]
scaler = MinMaxScaler(feature_range=(0, 1))
for clo in cols:
data[clo] = scaler.fit_transform(data[clo].values.reshape(-1, 1))
train = data[:train.shape[0]]
test = data[train.shape[0]:]
print(X_train)
X_train = train.values
y_train = target.values
X_test = test.values
模型选用lightgbm ,lightgbm 是曾经的刷分神器,在kaggle的各种大赛盛极一时。今天我们就讲解如何是用lightgbm 实现回归算法。
第一步 配置参数。
常用的参数有学习力,l2 正则,叶子的节点等等,下面的代码列出了常用的参数配置:
param = {‘num_leaves’: 600,
‘min_data_in_leaf’: 30,
‘objective’: ‘rmse’,
‘max_depth’: -1,
‘learning_rate’: 0.001,
“min_child_samples”: 30,
“boosting”: “gbdt”,
“feature_fraction”: 0.9,
“bagging_freq”: 1,
“bagging_fraction”: 0.9,
“bagging_seed”: 12,
“metric”: ‘mse’,
“lambda_l2”: 0.1,
‘is_unbalance’: True,
“verbosity”: -1}
为了防止数据不均匀,提高模型的精确度,减轻过拟合,我们采用10折交叉验证。代码如下:
五折交叉验证
folds = KFold(n_splits=10, shuffle=True, random_state=42)
oof = np.zeros(len(train))
predictions = np.zeros(len(test))
然后开始训练和测试,设置迭代次数为100000,设置earlystop为1000,如果迭代1000次,loss没有发生变化则终止迭代,代码如下:
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train, y_train)):
print(“fold n°{}”.format(fold_ + 1))
trn_data = lgb.Dataset(X_train[trn_idx], y_train[trn_idx])
val_data = lgb.Dataset(X_train[val_idx], y_train[val_idx])
num_round = 100000
clf = lgb.train(param,
trn_data,
num_round,
valid_sets=[trn_data, val_data],
verbose_eval=2000,
early_stopping_rounds=1000)
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)

最后
不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~
给大家准备的学习资料包括但不限于:
Python 环境、pycharm编辑器/永久激活/翻译插件
python 零基础视频教程
Python 界面开发实战教程
Python 爬虫实战教程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划

程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划


