
- 1腾讯云轻量服务器和云服务器区别12点不同之处_腾讯 轻量服务器 区别
- 2llama.cpp部署多模态视觉模型到应用实践_mmproj-model-f16.gguf
- 3Nginix配置详解_ng的配置
- 4基于卷积神经网络-双向长短期记忆网络结合注意力机制CNN-BiLSTM-attention回归区间预测-Matlab
- 5已解决org.apache.zookeeper.KeeperException.InvalidACLException异常的正确解决方法,亲测有效!!!_2024-03-25 21:25:47.285 info 782449 --- [.26.1.153
- 6【授时防火墙】GPS北斗卫星授时信号安全防护装置系统
- 7AAAI2024-分享若干篇有代码的优秀论文-图神经网络、时间序列预测、知识图谱、大模型等_多模态知识图谱aaai2024
- 8区域双碳目标与路径规划研究(华为杯数模数据分析题)_区域双碳目标与路径规划研究数学建模
- 9chatgpt赋能python:Python颜色函数:探索颜色世界的魅力_python hsl
- 10AutoGPTQ量化方案
word2vec模型原理与实现 word2vec是Google在2013年开源的一款将词表征为实数值向量的高效工具. gensim包提供了word2vec的python接口. word2vec采用_word2vec 是一种广泛使用的词向量生成方法,由google的研究人员开发
赞
踩
word2vec模型原理与实现
word2vec是Google在2013年开源的一款将词表征为实数值向量的高效工具.
gensim包提供了word2vec的python接口.
word2vec采用了CBOW(Continuous Bag-Of-Words,连续词袋模型)和Skip-Gram两种模型.
模型原理
语言模型的基本功能是判断一句话是否是自然语言, 从概率的角度来说就是计算一句话是自然语言的概率.
直观地讲"natural language"这个词组出现的概率要比"natural warship"这个词组出现的概率大的多.
对于机器翻译或语音识别得到的结果, 使用极大似然估计法可以对句子中下一个单词的候选词进行选择.
向量空间模型(Vector space model, VSM)将词语表示为一个连续的词向量, 且语义接近的单词对应的词向量在空间上(欧式距离, cosine相似度等)也是接近的.
VSM基于分布假说, 即若两个单词的上下文相同则两个单词的语义也相同.
基于分布假说的生成词向量的方法分为两大类:
-
统计法(count-based methods), 比如潜在语义分析(Latent Semantic Analysis, LSA)
-
预测法(predictive methods), 比如神经网络语言模型(Neural Network Language Model)
word2vec就是一种典型的神经网络语言模型.
N-gram模型
传统的统计词向量模型使用单词在特定上下文中出现的概率表征这个句子是自然语言的概率:
p(sentence) = p(word|context)上下文context是指单词前面的特定的单词.N-gram模型又称为n元组模型, 所谓n元组是单词和它的上下文(即它前面的n-1个单词)组成的词组.
在N=1时, 认为单词w出现的概率不依赖上下文, 只取决于其在语料库中出现的频率.这种模型又称为上下文无关模型, 但其不具备实际应用意义.
在N=2时, N-gram模型又称Bigram模型.以句子:"I love natural language processing"为例, 单词"love"的上下文即为"I":
p(sentence) = p("love"|"I")P("I")在N>2时, p(sentence)需要进一步迭代:
p(sentence) = p("natural"|"I love")p("love"|"I")P("I")N-gram算法面临的一个问题是一些单词在语料库中没有出现过, 从而使得句子出现的概率变为0.
解决这问题的方法是每个词组出现的概率都加1, 没有出现过的n元组频数就变为了1.
这种方法称为Laplace平滑, 其本质是引入先验分布进行修正, 根据引入先验分布的方法不同产生了不同的平滑方法.
N-pos模型是对N-gram模型的改进, 它认为单词出现的概率依赖于单词前面单词的语法功能(Part-of-Speech, POS).
N-pos引入了类别映射函数c, 使得模型变形为:
p(sentence) = p("natural"|c("I love"))p("love"|c("I"))P(c("I"))N-gram模型的另一个问题在于计算量过大, 计算一次条件概率就要扫描一遍语料库, 使得可以实际应用的深度(N值)一般为2或3.
这个问题可以采用拟合的方法来解决即预测法.神经网络模型即计算部分概率值用于训练神经网络, 然后使用神经网络预测其它概率值.
CBOW
连续词袋模型(Continuous Bag-of-Word Model, CBOW)是一个三层神经网络, 输入已知上下文输出对下个单词的预测.
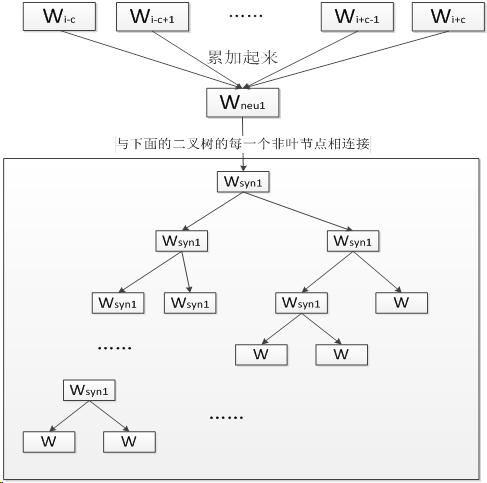
CBOW模型的第一层是输入层, 输入已知上下文的词向量. 中间一层称为线性隐含层, 它将所有输入的词向量累加.
第三层是一棵哈夫曼树, 树的的叶节点与语料库中的单词一一对应, 而树的每个非叶节点是一个二分类器(一般是softmax感知机等), 树的每个非叶节点都直接与隐含层相连.
将上下文的词向量输入CBOW模型, 由隐含层累加得到中间向量.将中间向量输入哈夫曼树的根节点, 根节点会将其分到左子树或右子树.
每个非叶节点都会对中间向量进行分类, 直到达到某个叶节点.该叶节点对应的单词就是对下个单词的预测.
首先根据预料库建立词汇表, 词汇表中所有单词拥有一个随机的词向量.我们从语料库选择一段文本进行训练.
将单词W的上下文的词向量输入CBOW, 由隐含层累加, 在第三层的哈夫曼树中沿着某个特定的路径到达某个叶节点, 从给出对单词W的预测.
训练过程中我们已经知道了单词W, 根据W的哈夫曼编码我们可以确定从根节点到叶节点的正确路径, 也确定了路径上所有分类器应该作出的预测.
我们采用梯度下降法调整输入的词向量, 使得实际路径向正确路径靠拢.在训练结束后我们可以从词汇表中得到每个单词对应的词向量.
Skip-gram
Skip-gram模型同样是一个三层神经网络. 输入一个单词, 输出对上下文的预测.
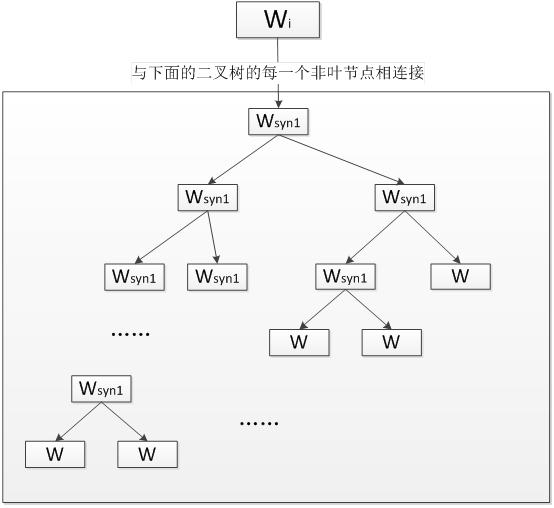
Skip-gram的核心同样是一个哈夫曼树, 每一个单词从树根开始到达叶节点可以预测出它上下文中的一个单词.
对每个单词进行N-1次迭代, 得到对它上下文中所有单词的预测, 根据训练数据调整词向量得到足够精确的结果.
模型实现
继承python内置的collections.Counter编写词频统计器WordCounter
实现哈夫曼树HuffmanTree,关于构造哈夫曼树的算法参考这里.
定义模型类:
- class Word2Vec:
- def __init__(self, vec_len=15000, learn_rate=0.025, win_len=5):
- self.cutted_text_list = None
- self.vec_len = vec_len
- self.learn_rate = learn_rate
- self.win_len = win_len
- self.word_dict = None
- self.huffman = None
词汇表word_dict是一个字典:
word_dict = {word: {word, freq, possibility, init_vector, huffman_code}, ...}build_word_dict方法根据WordCounter建立词汇表:
- def build_word_dict(self, word_freq):
- # word_dict = {word: {word, freq, possibility, init_vector, huffman_code}, }
- word_dict = {}
- freq_list = [x[1] for x in word_freq]
- sum_count = sum(freq_list)
- for item in word_freq:
- temp_dict = dict(
- word=item[0],
- freq=item[1],
- possibility=item[1] / sum_count,
- vector=np.random.random([1, self.vec_len]),
- Huffman=None
- )
- word_dict[item[0]] = temp_dict
- self.word_dict = word_dict
train方法控制训练流程, 将单词及其上下文交给CBOW方法或SkipGram方法进行具体训练:
- def train(self, word_list, model='cbow', limit=100, ignore=0):
- # build word_dict and huffman tree
- if self.huffman is None:
- if self.word_dict is None:
- counter = WordCounter(word_list)
- self.build_word_dict(counter.count_res.larger_than(ignore))
- self.cutted_text_list = counter.word_list
- self.huffman = HuffmanTree(self.word_dict, vec_len=self.vec_len)
- # get method
- if model == 'cbow':
- method = self.CBOW
- else:
- method = self.SkipGram
- # train word vector
- before = (self.win_len - 1) >> 1
- after = self.win_len - 1 - before
- total = len(self.cutted_text_list)
- count = 0
- for epoch in range(limit):
- for line in self.cutted_text_list:
- line_len = len(line)
- for i in range(line_len):
- word = line[i]
- if is_stop_word(word):
- continue
- context = line[max(0, i - before):i] + line[i + 1:min(line_len, i + after + 1)]
- method(word, context)
- count += 1

CBOW方法对输入变量累加求和, 交由along_huffman方法进行一次预测并得到误差, 最后根据误差更新词向量:
- def CBOW(self, word, context):
- if not word in self.word_dict:
- return
- # get sum of all context words' vector
- word_code = self.word_dict[word]['code']
- gram_vector_sum = np.zeros([1, self.vec_len])
- for i in range(len(context))[::-1]:
- context_gram = context[i] # a word from context
- if context_gram in self.word_dict:
- gram_vector_sum += self.word_dict[context_gram]['vector']
- else:
- context.pop(i)
- if len(context) == 0:
- return
- # update huffman
- error = self.along_huffman(word_code, gram_vector_sum, self.huffman.root)
- # modify word vector
- for context_gram in context:
- self.word_dict[context_gram]['vector'] += error
- self.word_dict[context_gram]['vector'] = preprocessing.normalize(self.word_dict[context_gram]['vector'])
SkipGram方法使用Skip-gram模型进行训练, 它进行多次迭代:
- def SkipGram(self, word, context):
- if not word in self.word_dict:
- return
- word_vector = self.word_dict[word]['vector']
- for i in range(len(context))[::-1]:
- if not context[i] in self.word_dict:
- context.pop(i)
- if len(context) == 0:
- return
- for u in context:
- u_huffman = self.word_dict[u]['code']
- error = self.along_huffman(u_huffman, word_vector, self.huffman.root)
- self.word_dict[word]['vector'] += error
- self.word_dict[word]['vector'] = preprocessing.normalize(self.word_dict[word]['vector'])
along_huffman方法进行一次预测并得到误差:
- def along_huffman(self, word_code, input_vector, root):
- node = root
- error = np.zeros([1, self.vec_len])
- for level in range(len(word_code)):
- branch = word_code[level]
- p = sigmoid(input_vector.dot(node.value.T))
- grad = self.learn_rate * (1 - int(branch) - p)
- error += grad * node.value
- node.value += grad * input_vector
- node.value = preprocessing.normalize(node.value)
- if branch == '0':
- node = node.right
- else:
- node = node.left
- return error
从词汇表中取出词向量:
- def __getitem__(self, word):
- if not word in self.word_dict:
- return None
- return self.word_dict[word]['vector']
-
- > wv = Word2Vec(vec_len=50)
- > wv.train(data, model='cbow')
- > wv['into']
- array(1, 50)
完整源代码参见Word2Vec
gensim中的word2vec封装
gensim是著名的向量空间模型包, 使用pip安装:
pip gensimgensim中封装了包括了word2vec, doc2vec等模型:
- from gensim.models.word2vec import Word2Vec
-
- profiler = Word2Vec()
首先根据语料库构建词汇表:
profiler.build_vocab(word_source)数据源word_source是一个句子组成的序列:
- word_source = [
- ['I', 'love', 'natural', 'language', 'processing'],
- ['word2vec', 'is', 'a', 'useful', 'model']
- ]
因为内存有限, 使用list作为数据源通常只能保存很少数据. word2vec也可以使用generator作为数据源.
word2vec需要再次扫描数据集进行训练:
self.profiler.train(word_source)word2vec支持在线训练(resume training, 又称继续训练),即进行过训练的模型可以再次训练, 进一步提高精度.
从训练好的模型中获得词向量:
- >>>profiler[word]
- array([-0.00449447, -0.00310097, 0.02421786, ...], dtype=float32)
word2vec可以计算单词相似度:
- >>>profiler.similarity('woman', 'man')
- 0.73723527
将训练好的模型存储为文件:
profiler.save(filename)读取模型文件:
profiler = Word2Vec.load(filename)
