
热门标签
热门文章
- 1华为官方推荐:学习鸿蒙开发高分好书,这6本能帮你很多!_鸿蒙开发 推荐 书籍
- 2ELF文件中得section(.data .bss .text .altinstr_replacement、.altinstr_aux)_.section .datar, data
- 3ssm的maven坐标_ssm maven 坐标
- 4MySQL存储引擎详解(一)-InnoDB架构_mysql引擎innodb
- 5(一)使用AI、CodeFun开发个人名片微信小程序_ai生成小程序代码
- 6求助:R包安装失败_cannot open compressed file description
- 74款超好用的AI换脸软件,一键视频直播换脸(附下载链接)
- 8【深度学习】激活函数(sigmoid、ReLU、tanh)_sigmoid激活函数
- 9操作系统的程序内存结构 —— data和bss为什么需要分开,各自的作用_为什么分bss和data
- 10记一次 Docker Nginx 自定义 log_format 报错的解决方案_log_format" directive no dyconf_version config in
当前位置: article > 正文
llama.cpp部署多模态视觉模型到应用实践_mmproj-model-f16.gguf
作者:我家自动化 | 2024-04-07 01:59:29
赞
踩
mmproj-model-f16.gguf
一、安装cmake
https://cmake.org/
因为我使用是win10系统cmake版本是3.26.4,请根据自己系统选择版本。
二、下载源码
- git clone https://github.com/ggerganov/llama.cpp.git
-
-
-
- #进入llama.cpp文件夹
-
- cd llama.cpp
-
- mkdir build
-
- cd build
-
-
-
- #编译llama.cpp
-
- cmake .. -G "Visual Studio 16 2019" -DLLAMA_CUBLAS=on -DLLAMA_CUDA_F16=1 -DCMAKE_CUDA_ARCHITECTURES=75 -DCMAKE_GENERATOR_TOOLSET="cuda=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1"

注意:DCMAKE_CUDA_ARCHITECTURES=75,75是显卡算力如果报错请根据自己显卡算力修改这个数值。
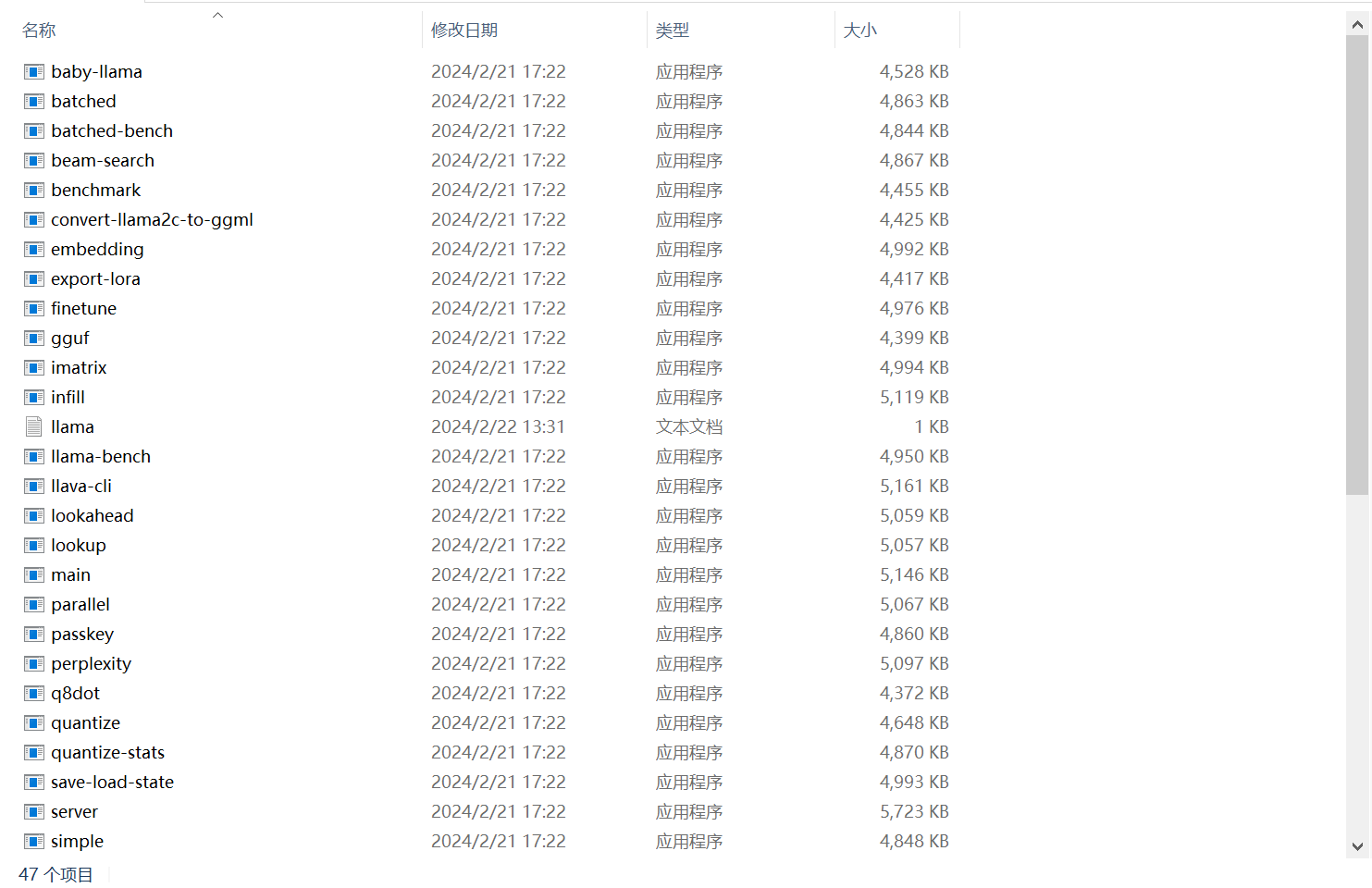
三、编译成功样子
在llama.cpp\build\bin\Release
四、gguf模型转换
- #下载llava-v1.5-7b模型放在llama.cpp文件夹下
-
- #下载openaiclip-vit-large-patch14-336模型放在llama.cpp文件夹下
-
- cd llama.cpp
-
-
-
- #模型拆分
-
- python examples/llava/llava-surgery.py -m llava-v1.5-7b
-
-
-
- #转换为 GGUF
-
- python examples/llava/convert-image-encoder-to-gguf.py -m openaiclip-vit-large-patch14-336 --llava-projector llava-v1.5-7b/llava.projector --output-dir llava-v1.5-7b
-
-
-
- #转换为 GGUF:convert.py
-
- python convert.py llava-v1.5-7b --skip-unknown
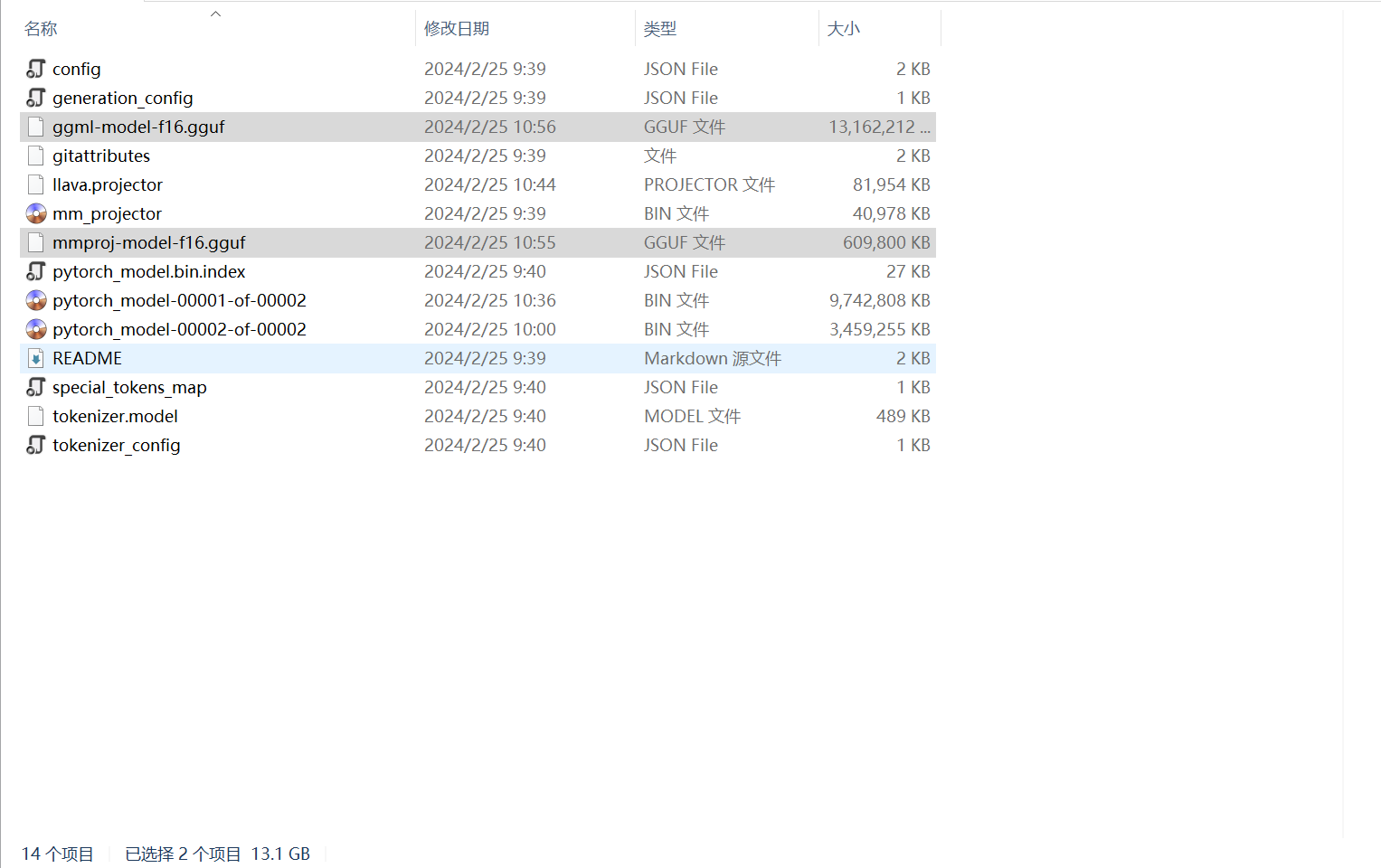
注意:完成上述步骤后在llava-v1.5-7b文件夹会多出两个文件ggml-model-f16.gguf和mmproj-model-f16.gguf把这两个文件复制到llama.cpp/models就可以运行服务器了。
五、模型转换成功的样子
六、运行刚才转换的模型
- #打开命令行进入llama.cpp文件夹
-
-
-
- cd llama.cpp
-
-
-
- #在命令行输入下面命令运行模型服务器
-
- build/bin/Release/server -m models/ggml-model-f16.gguf --mmproj models/mmproj-model-f16.gguf --port 8080 -ngl 35 -t 20
七、模型服务器运行样子

八、前端运行样子



九、模型转换到应用探索结束
如遇编译错误
已经编译好的版本见知识星球-xingxingyu
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/375685
推荐阅读
相关标签

