
- 1ASF-YOLO:一种基于注意力尺度序列融合的细胞实例分割YOLO模型_asf yolo
- 2让支付更简单 Sping Boot 对接微信支付V3 (Java详细教程)_binarywang 微信支付 v3
- 3栈和队列(Java实现)_java栈
- 4大模型是不是有点太多了?
- 5程序员必备开发神器:领取云主机,零码创建专属AI Agent
- 6权限管理系统笔记_权限ream
- 7浅谈数字图书馆智能推荐系统的发展趋势_关键词突现图解释
- 8国土GIS应用专题(二)_jpg、prj、jgw、xml
- 9python用turtle画出给定图片的图像_python 按照提供的图片绘制图像
- 10【2024年第三届中国高校大数据挑战赛】赛题 D:行业职业技术培训能力评价 思路+代码+参考论文_2024年中国高校大数据竞赛d题讲解
Keras Gemma distributed finetuning and inference之实践项目_the model generates a list of great comedy movies
赞
踩
Overview
Gemma is a family of lightweight, state-of-the-art open models built from research and technology used to create Google Gemini models. Gemma can be further finetuned to suit specific needs. But Large Language Models, such as Gemma, can be very large in size and some of them may not fit on a sing accelerator for finetuning. In this case there are two general approaches for finetuning them:
- Parameter Efficient Fine-Tuning (PEFT), which seeks to shrink the effective model size by sacrificing some fidelity. LoRA falls in this category and the Finetune Gemma models in Keras using LoRA tutorial demonstrates how to finetune the Gemma 2B model
gemma_2b_enwith LoRA using KerasNLP on a single GPU. - Full parameter finetuning with model parallelism. Model parallelism distributes a single model's weights across multiple devices and enables horizontal scaling. You can find out more about distributed training in this Keras guide.
This tutorial walks you through using Keras with a JAX backend to finetune the Gemma 7B model with LoRA and model-parallism distributed training on Google's Tensor Processing Unit (TPU). Note that LoRA can be turned off in this tutorial for a slower but more accurate full-parameter tuning.
Using accelerators
Technically you can use either TPU or GPU for this tutorial.
Notes on TPU environments
Google has 3 products that provide TPUs:
- Colab provides TPU v2, which is not sufficient for this tutorial.
- Kaggle offers TPU v3 for free and they work for this tutorial.
- Cloud TPU offers TPU v3 and newer generations. One way to set it up is:
- Create a new TPU VM
- Set up SSH port forwarding for your intended Jupyter server port
- Install Jupyter and start it on the TPU VM, then connect to Colab through "Connect to a local runtime"
Notes on multi-GPU setup
Although this tutorial focuses on the TPU use case, you can easily adapt it for your own needs if you have a multi-GPU machine.
If you prefer to work through Colab, it's also possible to provision a multi-GPU VM for Colab directly through "Connect to a custom GCE VM" in the Colab Connect menu.
We will focus on using the free TPU from Kaggle here.
Before you begin
linkcode
Gemma setup
To complete this tutorial, you will first need to complete the setup instructions at Gemma setup. The Gemma setup instructions show you how to do the following:
Gemma models are hosted by Kaggle. To use Gemma, request access on Kaggle:
- Sign in or register at kaggle.com
- Open the Gemma model card and select "Request Access"
- Complete the consent form and accept the terms and conditions

上面的页面往下滑到下面:选中New Notebook
- # This Python 3 environment comes with many helpful analytics libraries installed
- # It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
- # For example, here's several helpful packages to load
-
- import numpy as np # linear algebra
- import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
-
- # Input data files are available in the read-only "../input/" directory
- # For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
-
- import os
- for dirname, _, filenames in os.walk('/kaggle/input'):
- for filename in filenames:
- print(os.path.join(dirname, filename))
-
- # You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
- # You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session

Installation
Install Keras and KerasNLP with the Gemma model.
- # Install Keras 3 last. See https://keras.io/getting_started/ for more details.
- !pip install -q tensorflow-cpu
- !pip install -q -U keras-nlp tensorflow-hub
- !pip install -q -U keras>=3
- !pip install -U tensorflow-text
Set up Keras JAX backend
linkcode
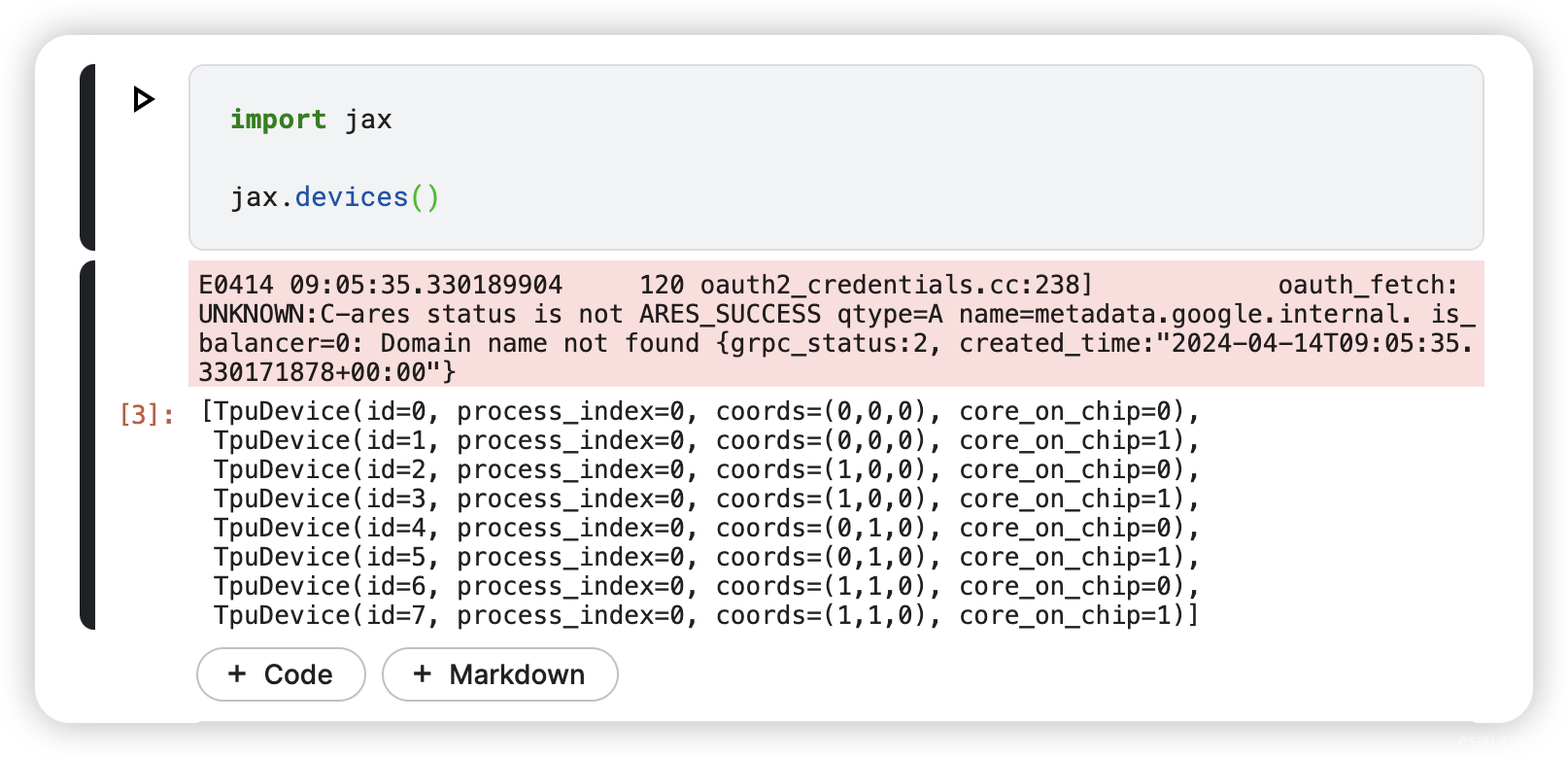
Import JAX and run a sanity check on TPU. Kaggle offers TPUv3-8 devices which have 8 TPU cores with 16GB of memory each.
- import jax
-
- jax.devices()
- import os
-
- # The Keras 3 distribution API is only implemented for the JAX backend for now
- os.environ["KERAS_BACKEND"] = "jax"
- # Pre-allocate 90% of TPU memory to minimize memory fragmentation and allocation
- # overhead
- os.environ["XLA_PYTHON_CLIENT_MEM_FRACTION"] = "0.9"

Load model
- import keras
- import keras_nlp
To load the model with the weights and tensors distributed across TPUs, first create a new DeviceMesh. DeviceMesh represents a collection of hardware devices configured for distributed computation and was introduced in Keras 3 as part of the unified distribution API.
The distribution API enables data and model parallelism, allowing for efficient scaling of deep learning models on multiple accelerators and hosts. It leverages the underlying framework (e.g. JAX) to distribute the program and tensors according to the sharding directives through a procedure called single program, multiple data (SPMD) expansion. Check out more details in the new Keras 3 distribution API guide.
- # Create a device mesh with (1, 8) shape so that the weights are sharded across
- # all 8 TPUs.
- device_mesh = keras.distribution.DeviceMesh(
- (1, 8),
- ["batch", "model"],
- devices=keras.distribution.list_devices())

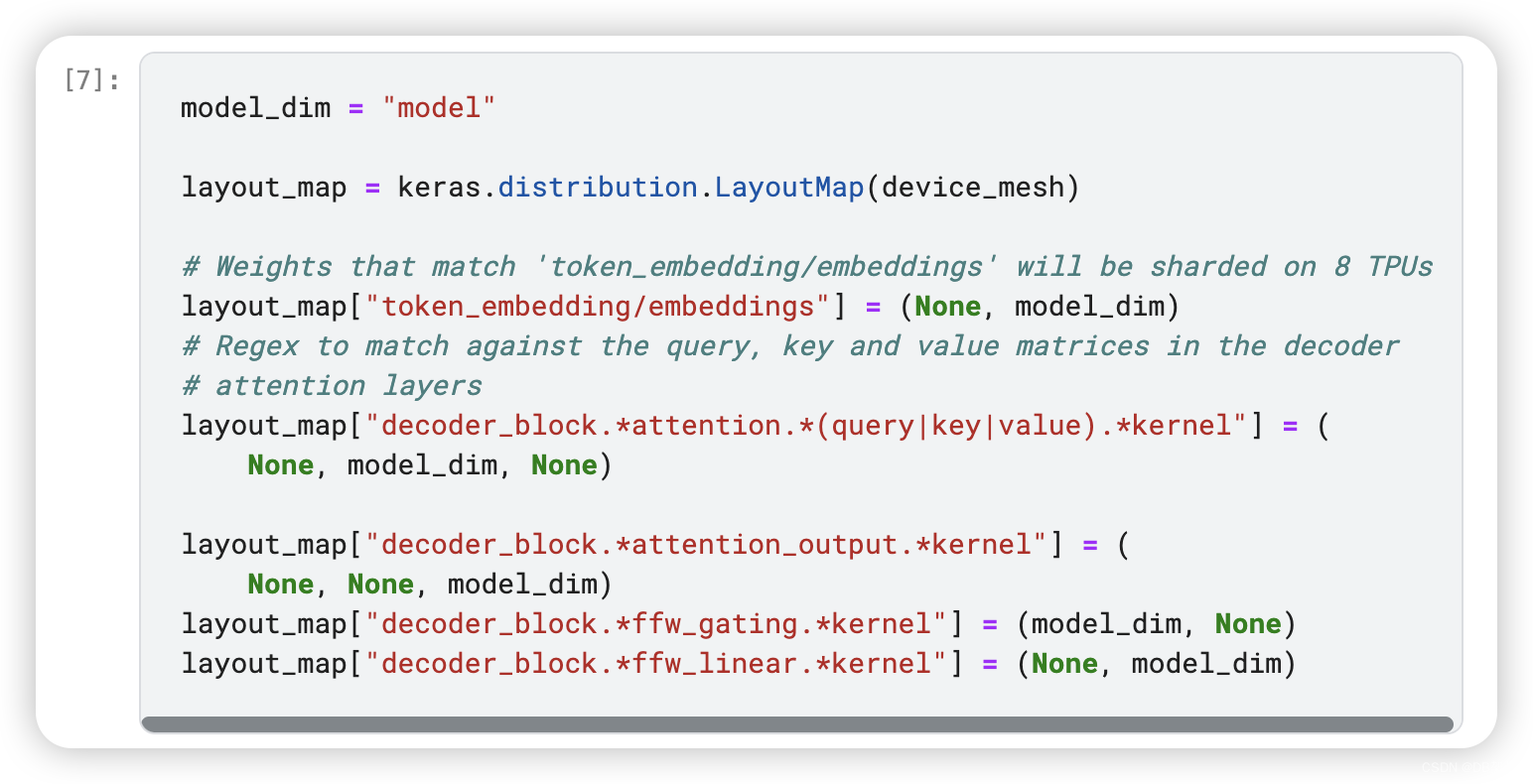
LayoutMap from the distribution API specifies how the weights and tensors should be sharded or replicated, using the string keys, for example, token_embedding/embeddings below, which are treated like regex to match tensor paths. Matched tensors are sharded with model dimensions (8 TPUs); others will be fully replicated.
- model_dim = "model"
-
- layout_map = keras.distribution.LayoutMap(device_mesh)
-
- # Weights that match 'token_embedding/embeddings' will be sharded on 8 TPUs
- layout_map["token_embedding/embeddings"] = (None, model_dim)
- # Regex to match against the query, key and value matrices in the decoder
- # attention layers
- layout_map["decoder_block.*attention.*(query|key|value).*kernel"] = (
- None, model_dim, None)
-
- layout_map["decoder_block.*attention_output.*kernel"] = (
- None, None, model_dim)
- layout_map["decoder_block.*ffw_gating.*kernel"] = (model_dim, None)
- layout_map["decoder_block.*ffw_linear.*kernel"] = (None, model_dim)
ModelParallel allows you to shard model weights or activation tensors across all devcies on the DeviceMesh. In this case, some of the Gemma 7B model weights are sharded across 8 TPU chips according the layout_map defined above. Now load the model in the distributed way.
- model_parallel = keras.distribution.ModelParallel(
- device_mesh, layout_map, batch_dim_name="batch")
-
- keras.distribution.set_distribution(model_parallel)
- gemma_lm = keras_nlp.models.GemmaCausalLM.from_preset("gemma_7b_en")
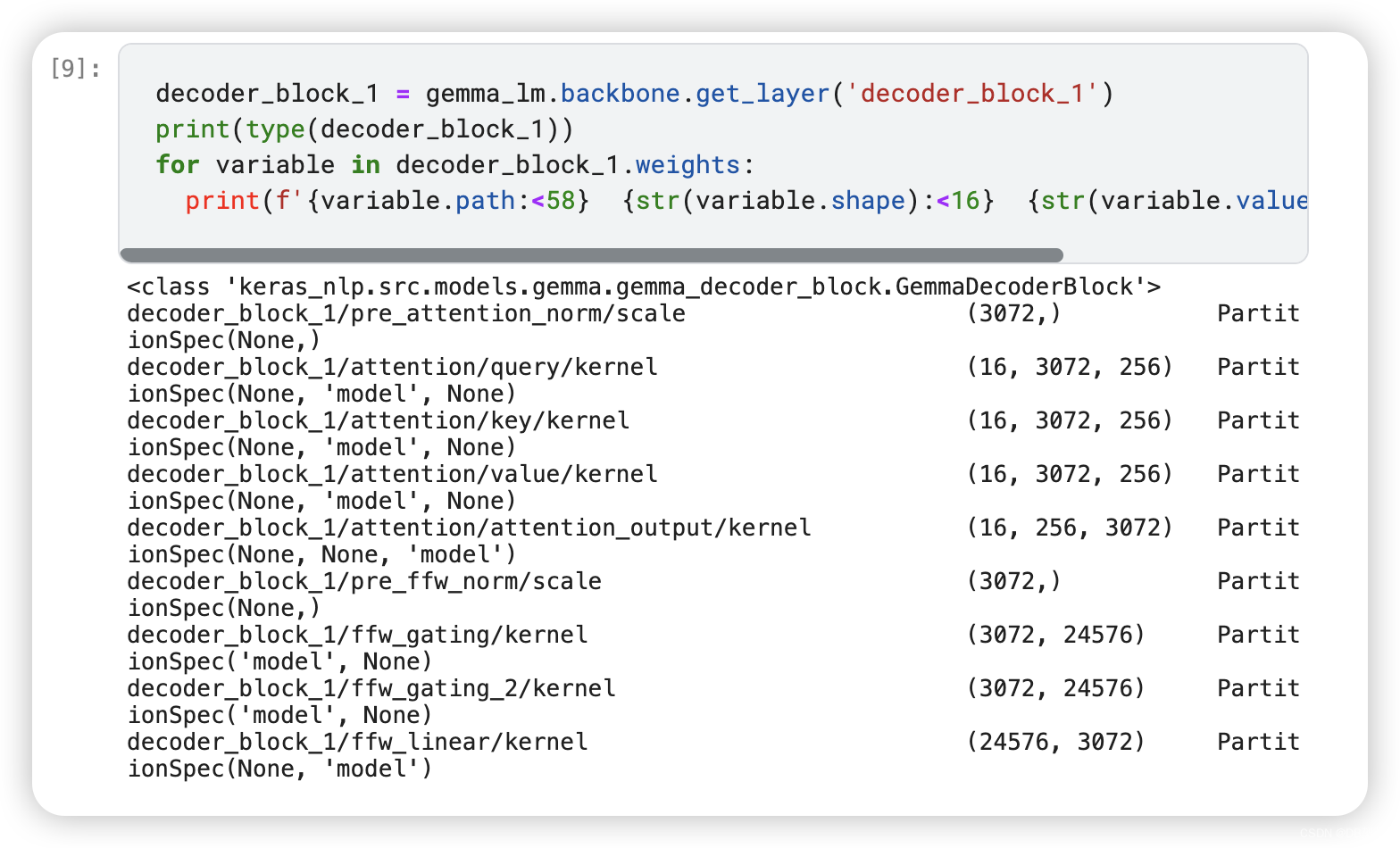
- decoder_block_1 = gemma_lm.backbone.get_layer('decoder_block_1')
- print(type(decoder_block_1))
- for variable in decoder_block_1.weights:
- print(f'{variable.path:<58} {str(variable.shape):<16} {str(variable.value.sharding.spec)}')
Inference before finetuning
gemma_lm.generate("Best comedy movies in the 90s ", max_length=64)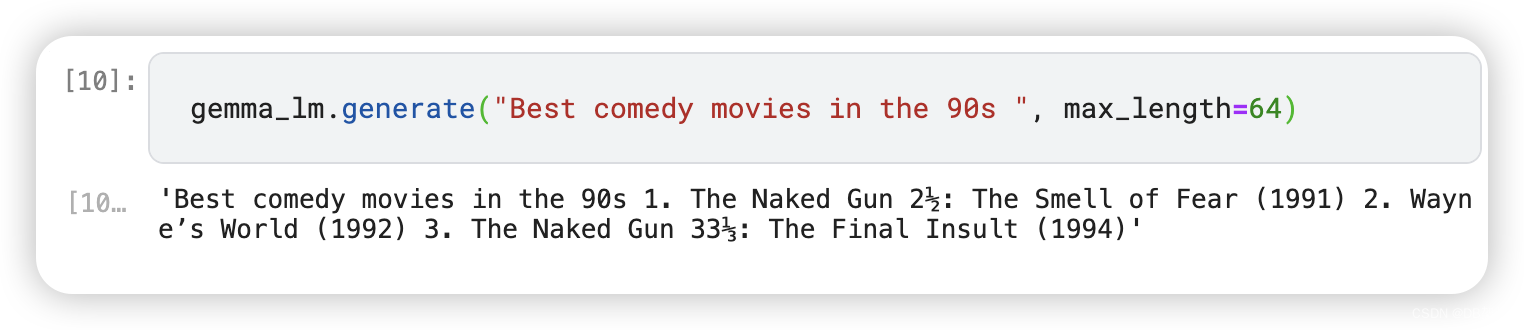
The model generates a list of great comedy movies from the 90s to watch. Now we finetune the Gemma model to change the output style.
Finetune with IMDB
- import tensorflow_datasets as tfds
-
- imdb_train = tfds.load(
- "imdb_reviews",
- split="train",
- as_supervised=True,
- batch_size=2,
- )
- # Drop labels.
- imdb_train = imdb_train.map(lambda x, y: x)
-
- imdb_train.unbatch().take(1).get_single_element().numpy()

- # Use a subset of the dataset for faster training.
- imdb_train = imdb_train.take(2000)

Perform finetuning using Low Rank Adaptation (LoRA). LoRA is a fine-tuning technique which greatly reduces the number of trainable parameters for downstream tasks by freezing the full weights of the model and inserting a smaller number of new trainable weights into the model. Basically LoRA reparameterizes the larger full weight matrices by 2 smaller low-rank matrices AxB to train and this technique makes training much faster and more memory-efficient.
- # Enable LoRA for the model and set the LoRA rank to 4.
- gemma_lm.backbone.enable_lora(rank=4)
- # Fine-tune on the IMDb movie reviews dataset.
-
- # Limit the input sequence length to 128 to control memory usage.
- gemma_lm.preprocessor.sequence_length = 128
- # Use AdamW (a common optimizer for transformer models).
- optimizer = keras.optimizers.AdamW(
- learning_rate=5e-5,
- weight_decay=0.01,
- )
- # Exclude layernorm and bias terms from decay.
- optimizer.exclude_from_weight_decay(var_names=["bias", "scale"])
-
- gemma_lm.compile(
- loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
- optimizer=optimizer,
- weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
- )
- gemma_lm.summary()
- gemma_lm.fit(imdb_train, epochs=1)
Inference after finetuning
gemma_lm.generate("Best comedy movies in the 90s ", max_length=64)
