- 12023 hnust 湖南科技大学 大数据技术与应用 期末考试 复习资料_1.画出region与region服务器之间的对应关系图(hregion的分布方式)
- 2六种本地化运行大语言模型的方法(2024.1月)_本地语言模型
- 3论文阅读:DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation_dreambooth论文
- 4人工智能与数据分析:新时代的趋势和机会_数据分析和人工智能
- 5mysql事务没有提交会释放锁吗
- 6PostgreSQL 视图_postgres中视图的作用
- 7深入理解计算机系统 CSAPP 家庭作业6.23
- 8这么多年,终于有人讲清楚Transformer了_transform编码器重复堆叠的数量由什么决定
- 9java框架的作用_java三大框架的作用介绍
- 10Vue3框架下的顶尖UI组件库大盘点_vue3 ui框架
大数据技术之Hadoop-Apache Hive分布式SQL计算平台_hivesql 开发平台
赞
踩
一、Apache Hive 概述
1、分布式SQL计算

对数据进行统计分析,SQL是目前最为方便的编程工具。
大数据体系中充斥着非常多的统计分析场景
所以,使用SQL去处理数据,在大数据中也是有极大的需求的。

MapReduce支持程序开发(Java、Python等)但不支持SQL开发
2、分布式SQL计算 - Hive
Apache Hive是一款分布式SQL计算的工具, 其主要功能是:
- 将SQL语句 翻译成MapReduce程序运行
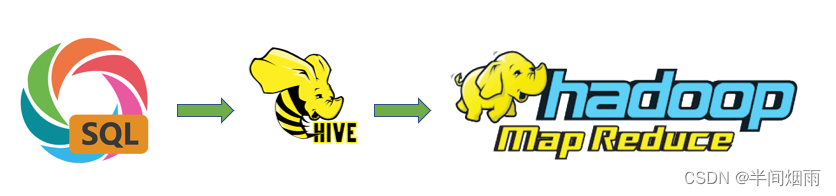
基于Hive为用户提供了分布式SQL计算的能力
写的是SQL、执行的是MapReduce
3、为什么使用Hive
使用Hadoop MapReduce直接处理数据所面临的问题
- 人员学习成本太高 需要掌握java、Python等编程语言
- MapReduce实现复杂查询逻辑开发难度太大
使用Hive处理数据的好处
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
- 底层执行MapReduce,可以完成分布式海量数据的SQL处理
二、模拟实现Hive功能
1、元数据管理
假设有如下结构化文本数据存储在HDFS中。

假设要执行: SELECT city, COUNT(*) FROM t_user GROUP BY city;
对这个SQL翻译成MapReduce程序,会出现哪些困难?
针对SQL:SELECT city, COUNT(*) FROM t_user GROUP BY city;
若翻译成MapReduce程序,有如下问题:
- 数据文件在哪里?
- 使用什么符号作为列的分隔符?
- 哪些列可以作为city使用?
- city列是什么类型的数据?
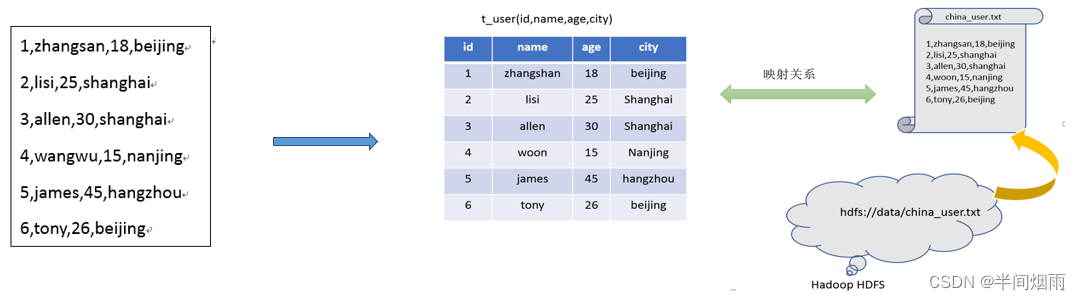
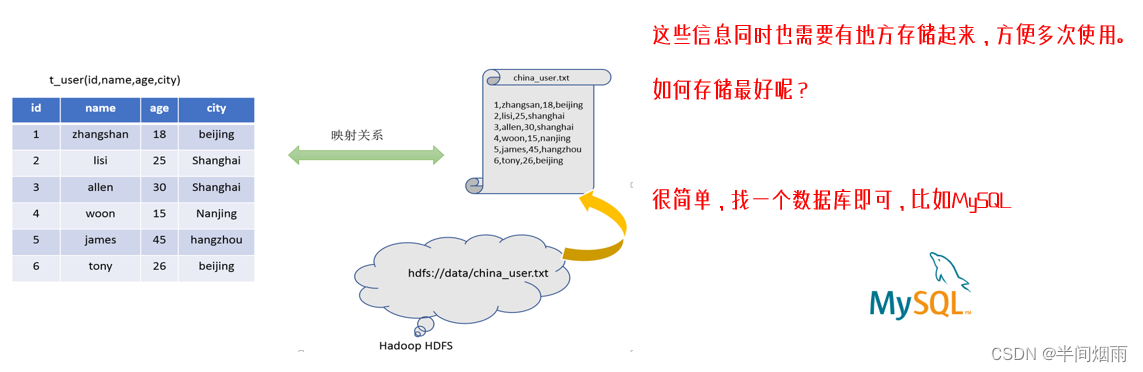
所以,我们可以总结出来第一个点, 即构建分布式SQL计算, 需要拥有:
元数据管理功能,即:
- 数据位置
- 数据结构
- 等对数据进行描述
进行记录

2、解析器
解决了元数据管理后,我们还有一个至关重要的步骤, 即完成SQL到MapReduce转换的功能。

我们称呼它为:SQL解析器,期待它能做到:
- SQL分析
- SQL到MapReduce程序的转换
- 提交MapReduce程序运行并收集执行结果
当拥有这2个组件, 基本上分布式SQL计算的能力就实现了。
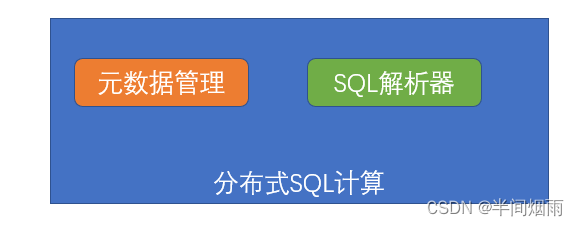
3、Hive架构
Apache Hive其2大主要组件就是:SQL解析器以及元数据存储, 如下图。
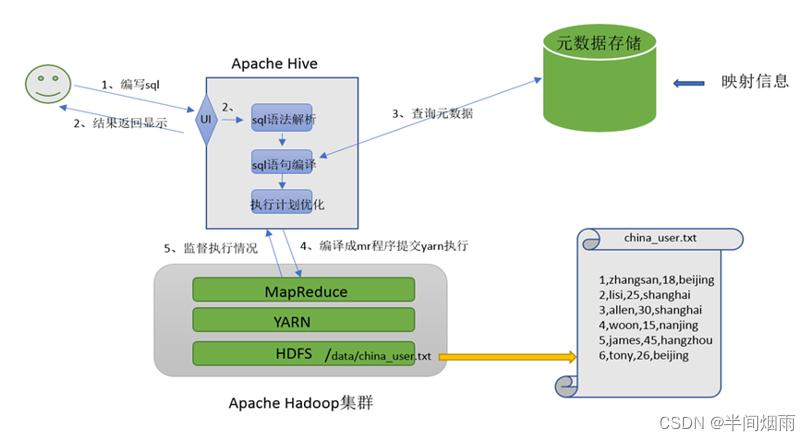
三、Hive基础架构
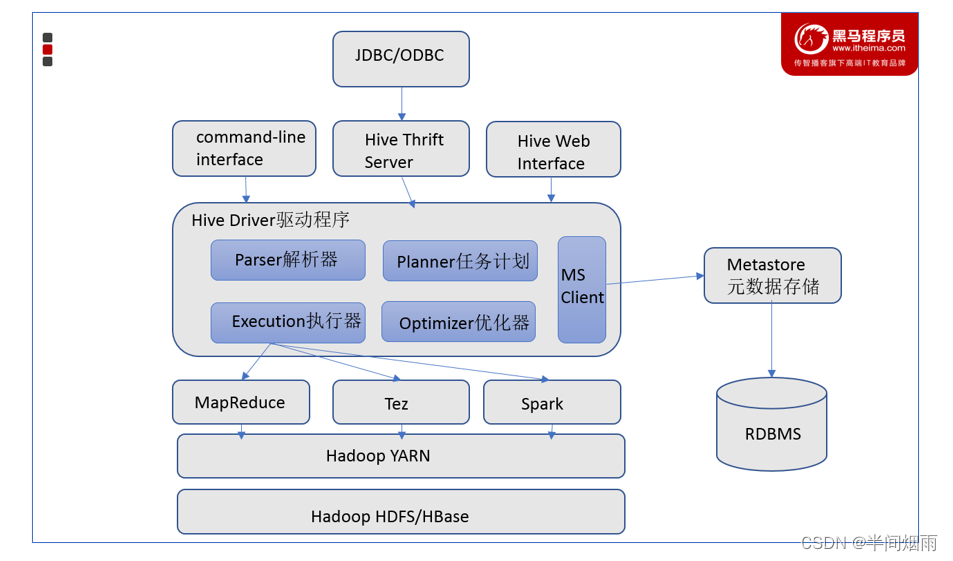
1、Hive组件
- 元数据存储
通常是存储在关系数据库如 mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
-- Hive提供了 Metastore 服务进程提供元数据管理功能
- Driver驱动程序,包括语法解析器、计划编译器、优化器、执行器
完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有执行引擎调用执行。
这部分内容不是具体的服务进程,而是封装在Hive所依赖的Jar文件即Java代码中。
- 用户接口
包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。
-- Hive提供了 Hive Shell、 ThriftServer等服务进程向用户提供操作接口
四、Hive部署
1、规划
我们知道Hive是单机工具后,就需要准备一台服务器供Hive使用即可。
同时Hive需要使用元数据服务,即需要提供一个关系型数据库,我们也选择一台服务器安装关系型数据库即可。

2、步骤1:安装MySQL数据库
- # 更新密钥
- rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
-
- # 安装Mysql yum库
- rpm -Uvh http://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm
-
- # yum安装Mysql
- yum -y install mysql-community-server
-
- # 启动Mysql设置开机启动
- systemctl start mysqld
- systemctl enable mysqld
-
- # 检查Mysql服务状态
- systemctl status mysqld
-
- # 第一次启动mysql,会在日志文件中生成root用户的一个随机密码,使用下面命令查看该密码
- grep 'temporary password' /var/log/mysqld.log
-
- # 修改root用户密码
- mysql -u root -p -h localhost
- Enter password:
-
- mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'Root!@#$';
-
- # 如果你想设置简单密码,需要降低Mysql的密码安全级别
- set global validate_password_policy=LOW; # 密码安全级别低
- set global validate_password_length=4; # 密码长度最低4位即可
-
- # 然后就可以用简单密码了(课程中使用简单密码,为了方便,生产中不要这样)
- ALTER USER 'root'@'localhost' IDENTIFIED BY 'root';
-
- /usr/bin/mysqladmin -u root password 'root'
-
- grant all privileges on *.* to root@"%" identified by 'root' with grant option;
- flush privileges;

3、步骤2:配置Hadoop
Hive的运行依赖于Hadoop(HDFS、MapReduce、YARN都依赖)
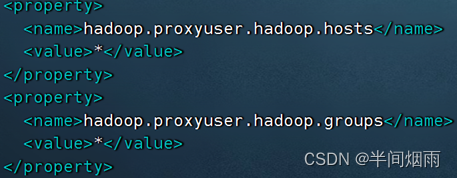
同时涉及到HDFS文件系统的访问,所以需要配置Hadoop的代理用户
即设置hadoop用户允许代理(模拟)其它用户
配置如下内容在Hadoop的core-site.xml中,并分发到其它节点,且重启HDFS集群
4、步骤3:下载解压Hive
- 切换到hadoop用户
- su - hadoop
- 下载Hive安装包:
- http://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
- 解压到node1服务器的:/export/server/内
- tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /export/server/
- 设置软连接
- ln -s /export/server/apache-hive-3.1.3-bin /export/server/hive
5、步骤4:提供MySQL Driver包
- 下载MySQL驱动包:
- https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.34/mysql-connector-java-5.1.34.jar
-
- 将下载好的驱动jar包,放入:Hive安装文件夹的lib目录内
- mv mysql-connector-java-5.1.34.jar /export/server/hive/lib/
-
6、步骤5:配置Hive
- 在Hive的conf目录内,新建hive-env.sh文件,填入以下环境变量内容:
-
- export HADOOP_HOME=/export/server/hadoop
- export HIVE_CONF_DIR=/export/server/hive/conf
- export HIVE_AUX_JARS_PATH=/export/server/hive/lib
在Hive的conf目录内,新建hive-site.xml文件,填入以下内容:
- <configuration>
- <property>
- <name>javax.jdo.option.ConnectionURL</name>
- <value>jdbc:mysql://node1:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
- </property>
-
- <property>
- <name>javax.jdo.option.ConnectionDriverName</name>
- <value>com.mysql.jdbc.Driver</value>
- </property>
-
- <property>
- <name>javax.jdo.option.ConnectionUserName</name>
- <value>root</value>
- </property>
-
- <property>
- <name>javax.jdo.option.ConnectionPassword</name>
- <value>123456</value>
- </property>
-
- <property>
- <name>hive.server2.thrift.bind.host</name>
- <value>node1</value>
- </property>
-
- <property>
- <name>hive.metastore.uris</name>
- <value>thrift://node1:9083</value>
- </property>
-
- <property>
- <name>hive.metastore.event.db.notification.api.auth</name>
- <value>false</value>
- </property>
-
- </configuration>
7、步骤6:初始化元数据库
支持,Hive的配置已经完成,现在在启动Hive前,需要先初始化Hive所需的元数据库。
- 在MySQL中新建数据库:hive
- CREATE DATABASE hive CHARSET UTF8;
- 执行元数据库初始化命令:
- cd /export/server/hive
- bin/schematool -initSchema -dbType mysql -verbos
- # 初始化成功后,会在MySQL的hive库中新建74张元数据管理的表。
8、步骤7:启动Hive(使用Hadoop用户)
- 确保Hive文件夹所属为hadoop用户
- 创建一个hive的日志文件夹:
- mkdir /export/server/hive/logs
- 启动元数据管理服务(必须启动,否则无法工作)
- 前台启动:bin/hive --service metastore
- 后台启动:nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
- 启动客户端,二选一(当前先选择Hive Shell方式)
- Hive Shell方式(可以直接写SQL): bin/hive
- Hive ThriftServer方式(不可直接写SQL,需要外部客户端链接使用): bin/hive --service hiveserver2
五、Hive初体验
1、Hive体验
首先,确保启动了Metastore服务。
- 可以执行:bin/hive,进入到Hive Shell环境中,可以直接执行SQL语句。
- 创建表
- CREATE TABLE test(id INT, name STRING, gender STRING);
- 插入数据
- INSERT INTO test VALUES(1, ‘王力红’, ‘男’), (2, ‘周杰轮’, ‘男’), (3, ‘林志灵’, ‘女’);
- 查询数据
- SELECT gender, COUNT(*) AS cnt FROM test GROUP BY gender;
- 验证Hive的数据存储
Hive的数据存储在HDFS的:/user/hive/warehouse中
- 验证SQL语句启动的MapReduce程序
打开YARN的WEB UI页面查看任务情况:http://node1:8088
六、Hive客户端
1、HiveServer2服务
在启动Hive的时候,除了必备的Metastore服务外,我们前面提过有2种方式使用Hive:
- 方式1: bin/hive 即Hive的Shell客户端,可以直接写SQL
- 方式2: bin/hive --service hiveserver2
后台执行脚本:nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
- bin/hive --service metastore,启动的是元数据管理服务
- bin/hive --service hiveserver2,启动的是HiveServer2服务
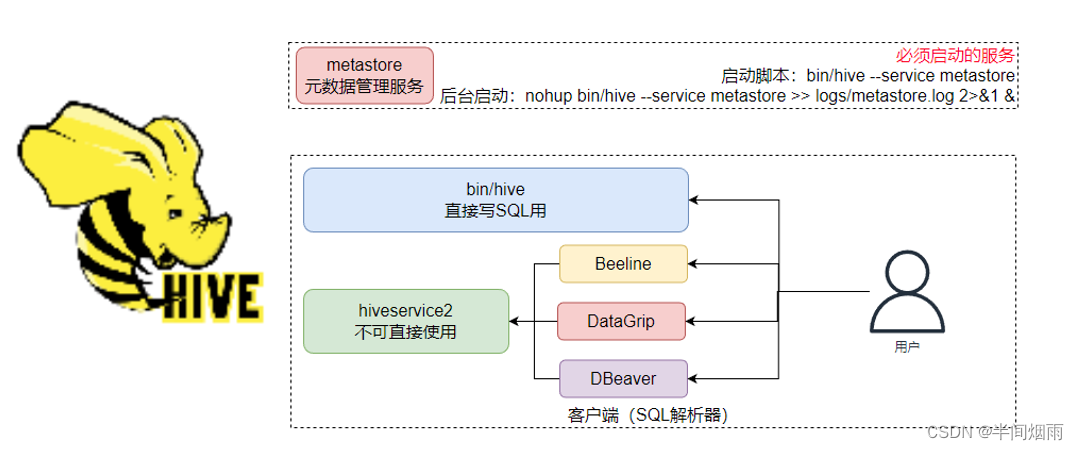
HiveServer2是Hive内置的一个ThriftServer服务,提供Thrift端口供其它客户端链接
可以连接ThriftServer的客户端有:
- Hive内置的 beeline客户端工具(命令行工具)
- 第三方的图形化SQL工具,如DataGrip、DBeaver、Navicat等
Hive的客户端体系如下
2、启动
在hive安装的服务器上,首先启动metastore服务,然后启动hiveserver2服务。
- #先启动metastore服务 然后启动hiveserver2服务
- nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
- nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
3、beeline
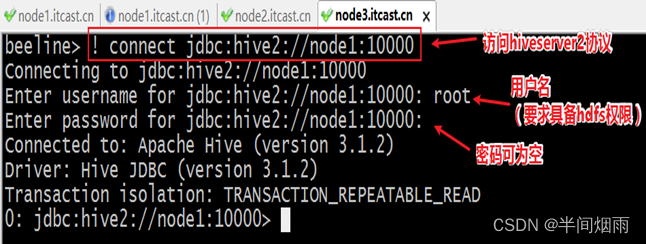
在node1上使用beeline客户端进行连接访问。需要注意hiveserver2服务启动之后需要稍等一会才可以对外提供服务。
Beeline是JDBC的客户端,通过JDBC协议和Hiveserver2服务进行通信,协议的地址是:jdbc:hive2://node1:10000
- [root@node1 ~]# /export/server/hive/bin/beeline
- Beeline version 3.1.2 by Apache Hive
- beeline> ! connect jdbc:hive2://node1:10000
- Connecting to jdbc:hive2://node1:10000
- Enter username for jdbc:hive2://node1:10000: root
- Enter password for jdbc:hive2://node1:10000:
- Connected to: Apache Hive (version 3.1.2)
- Driver: Hive JDBC (version 3.1.2)
- Transaction isolation: TRANSACTION_REPEATABLE_READ
- 0: jdbc:hive2://node1:10000>
2、Hive第三方客户端
DataGrip、Dbeaver、SQuirrel SQL Client等
可以在Windows、MAC平台中通过JDBC连接HiveServer2的图形界面工具;
这类工具往往专门针对SQL类软件进行开发优化、页面美观大方,操作简洁,更重要的是SQL编辑环境优雅;
SQL语法智能提示补全、关键字高亮、查询结果智能显示、按钮操作大于命令操作;
3、Hive可视化工具客户端
3.1、DataGrip
DataGrip是由JetBrains公司推出的数据库管理软件,DataGrip支持几乎所有主流的关系数据库产品,如DB2、Derby、MySQL、Oracle、SQL Server等,也支持几乎所有主流的大数据生态圈SQL软件,并且提供了简单易用的界面,开发者上手几乎不会遇到任何困难。
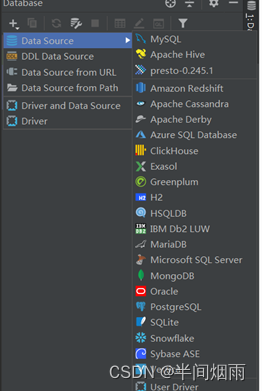
3.2、DataGrip使用教程
step1:windows创建工程文件夹

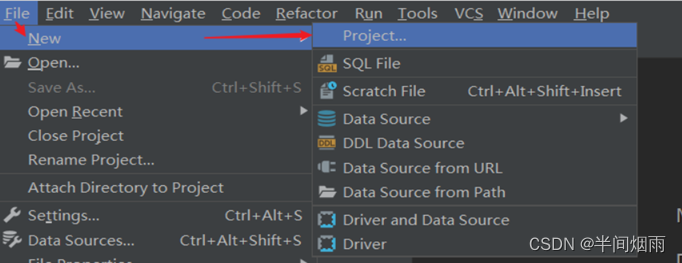
step2:DataGrip中创建新Project
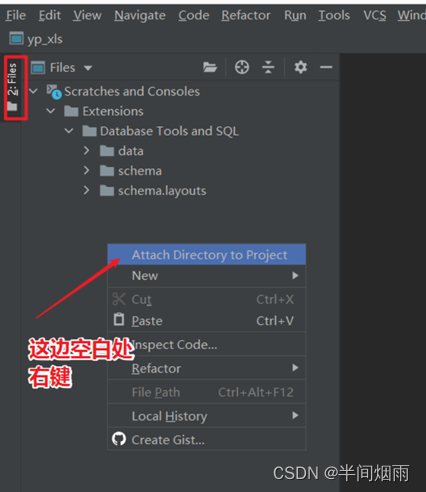
 lstep3:关联本地工程文件夹
lstep3:关联本地工程文件夹
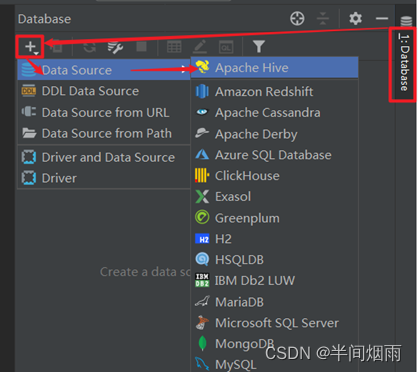
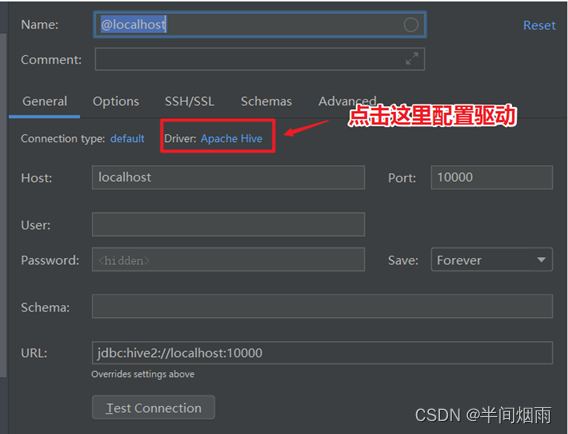
step4:DataGrip连接Hive
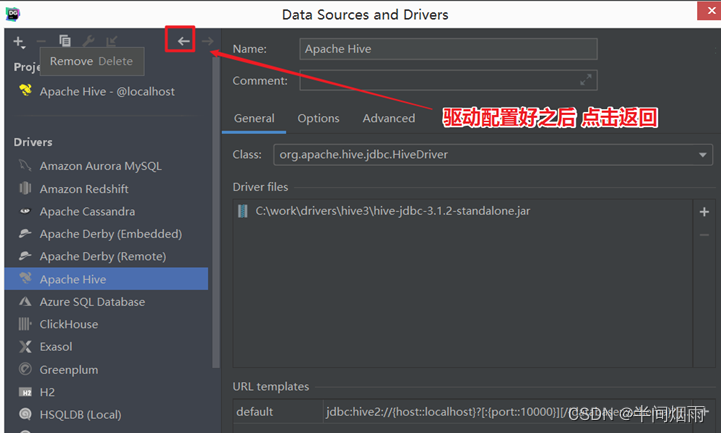
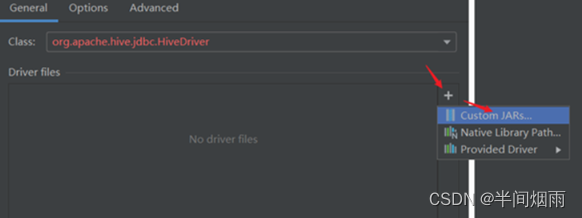
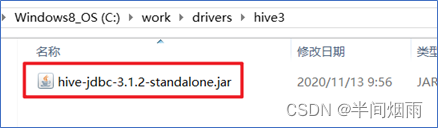
step5:配置Hive JDBC连接驱动
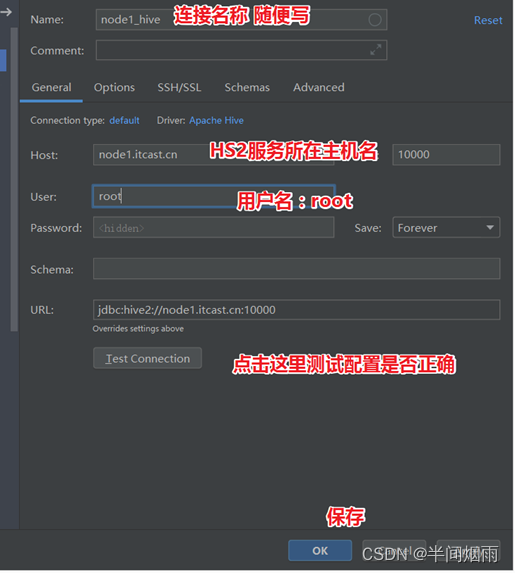
step6:返回,配置Hiveserver2服务连接信息