
热门标签
热门文章
- 1茅台党福音来了,一款开源自动预约茅台_又是大佬开源的一款自动预约i茅台app的系统
- 2力扣2187.完成旅途的最少时间
- 3Kaggle图像识别竞赛 Plant Seedlings Classification(植物幼苗分类)具体实现_kaggle图像识别竞赛 plant seedlings classification(植物幼苗分类
- 4《大数据技术基础》实验1-实验7_大数据技术基础实验一(1)_大数据安全技术实验一
- 5微信小程序开发资源汇总_微信开发者工具素材
- 6国开电大计算机科学与技术网络技术与应用试题及答案,分享几个实用搜题和学习工具 #媒体#其他#知识分享_电大计算机专业考试上哪里搜
- 7在Linux系统安装edge浏览器_linux默认浏览器将火绒更改edge
- 8HRD 1. 一个简单而靠谱的HRD的检测方法_hrd检测
- 9读论文——“时间序列预测方法综述”_时间序列预测方法综述 杨海民
- 10Redis 配置详解 —— 全网最新最全_redis配置文件详解
当前位置: article > 正文
论文阅读:DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation_dreambooth论文
作者:人工智能uu | 2024-06-24 03:47:34
赞
踩
dreambooth论文
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
论文链接
代码链接

这篇文章提出了一个新的个性化文生图模型方法:DreamBooth。给定几张参考图片,然后微调预训练的文生图模型,使得模型具备生成这些图片对应的特定物体的能力。在推理阶段,只需输入包含该特定物体的场景提示词,即可生成处于指定场景的特定物体的图片。
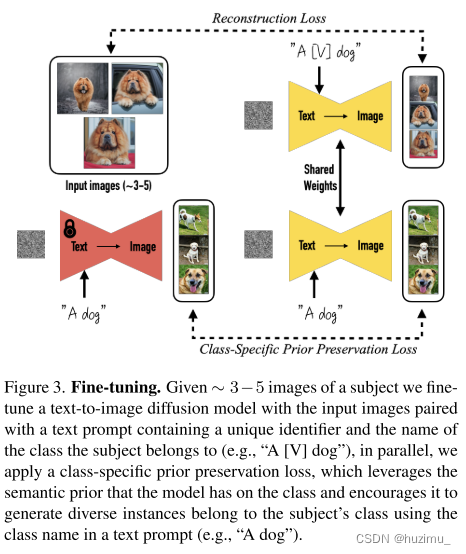
论文中指出,文生图模型微调会面临两个威胁:language drift和reduced output diversity。为了解决这两个威胁,作者使用了一个先验保存损失项,即下面的损失函数公式(2)的第二项。该项对使用原始的文生图模型生成的样本微调模型的过程进行约束,以保持微调后的模型的先验知识不被遗忘,对应上面的图3下方的黄色模型的微调过程。公式中的第一项,将参考图片对应的知识嵌入到模型中,对应上面的图3上方的黄色模型的微调过程。
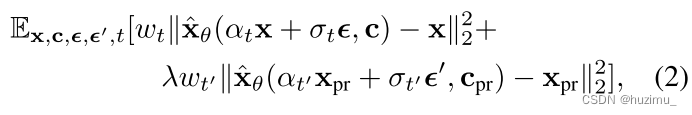
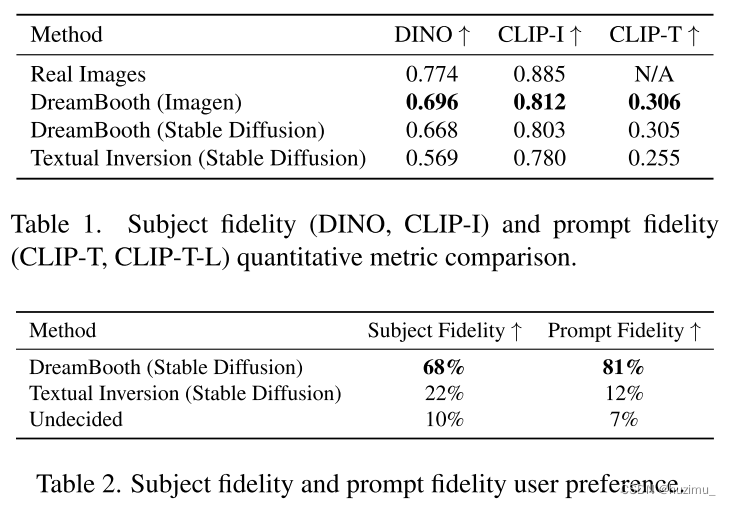
DreamBooth在量化评估比较和用户偏好调查中均优于基准方法:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/人工智能uu/article/detail/751571
推荐阅读
相关标签

