
热门标签
热门文章
- 1google浏览器网站不安全与网站的连接不安全怎么办?_chrome你与此网站之间建立的连接不安全
- 2最简单逢7杀人游戏java代码_java中ab两个人玩抢7游戏
- 3IEEE论文LaTeX模板解析(八)| 列表(List)_latex list
- 4JavaScript 中从数组中删除元素_javascript 数组删除元素
- 5Python3.6安装以及numpy库、matplotlib库的安装方法(Win7)_安装matplotlib库的命令
- 6【突破限制】免费使用Qwen大模型的API接口_qwen api
- 7产品经理面试会被问到什么?_产品经理招聘 非旺季
- 8字节跳动大规模实践埋点自动化测试框架设计_web 埋点 框架
- 9sql server 2008 报错:(provider: 命名管道提供程序, error: 40 - 无法打开到 SQL Server 的连接)_sqlserver2008 无法用servername 登录 命名管道 40
- 10售票系统设计_在web中,休克更新是什么
当前位置: article > 正文
【Python时序预测系列】基于ConvLSTM实现单变量时间序列预测(源码)_convlstm预测时序数据
作者:盐析白兔 | 2024-06-29 16:24:54
赞
踩
convlstm预测时序数据
这是我的第252篇原创文章。
一、引言
ConvLSTM是一种融合了卷积神经网络(CNN)和长短期记忆网络(LSTM)的混合神经网络结构,专门用于处理时空序列数据。ConvLSTM结合了CNN对空间特征的提取和LSTM对时间序列建模的能力,适用于需要同时考虑时空信息的任务,如视频预测、气象预测等。
在Keras中,您可以使用ConvLSTM2D层来构建ConvLSTM模型。本文基于ConvLSTM实现单变量时间序列预测。
二、实现过程
2.1 读取数据集
- # 读取数据集
- data = pd.read_csv('data.csv')
- # 将日期列转换为日期时间类型
- data['Month'] = pd.to_datetime(data['Month'])
- # 将日期列设置为索引
- data.set_index('Month', inplace=True)
data:
2.2 划分数据集
- # 拆分数据集为训练集和测试集
- train_size = int(len(data) * 0.8)
- train_data = data[:train_size]
- test_data = data[train_size:]
-
- # 绘制训练集和测试集的折线图
- plt.figure(figsize=(10, 6))
- plt.plot(train_data, label='Training Data')
- plt.plot(test_data, label='Testing Data')
- plt.xlabel('Year')
- plt.ylabel('Passenger Count')
- plt.title('International Airline Passengers - Training and Testing Data')
- plt.legend()
- plt.show()
共144条数据,8:2划分:训练集115,测试集29。
训练集和测试集:

2.3 归一化
- # 将数据归一化到 0~1 范围
- scaler = MinMaxScaler()
- train_data_scaler = scaler.fit_transform(train_data.values.reshape(-1, 1))
- test_data_scaler = scaler.transform(test_data.values.reshape(-1, 1))
2.4 构造数据集
- # 定义滑动窗口函数
- def create_sliding_windows(data, window_size):
- pass
-
- # 定义滑动窗口大小
- window_size = 3
-
- # 创建滑动窗口数据集
- X_train, Y_train = create_sliding_windows(train_data_scaler, window_size)
- X_test, Y_test = create_sliding_windows(test_data_scaler, window_size)
-
- # ConvLSTM是为读取二维时空数据而开发的,但可以适用于单变量时间序列预测。
- # 该层期望输入为二维图像序列,因此输入数据的形状必须为:
- # [samples, timesteps, rows, columns, features]
- 出于我们的目的,我们可以将每个样本分成多个子序列,其中时间步长将成为子序列数或n_seq,列将是每个子序列的时间步数或n_steps。在处理一维数据时,行数固定为1。
- # 数据重构为5D [samples, timesteps, rows, columns, features]
- X_train = np.reshape(X_train, (X_train.shape[0], window_size,1,1, 1))
- X_test = np.reshape(X_test, (X_test.shape[0],window_size, 1,1, 1))

2.5 建立模型进行预测
- # 初始化顺序模型
- model = Sequential()
- model.add(ConvLSTM2D(...)
- model.add(...)
- model.add(Dense(1))
- model.compile(loss='mse', optimizer='adam')
- model.fit(X_train, Y_train, epochs=50)
- # 打印模型
- model.summary()
-
- # 使用模型进行预测
- train_predictions = model.predict(X_train)
- test_predictions = model.predict(X_test)
-
- # 反归一化预测结果
- train_predictions = scaler.inverse_transform(train_predictions)
- test_predictions = scaler.inverse_transform(test_predictions)
test_predictions:
2.6 预测效果展示
- # 绘制测试集预测结果的折线图
- plt.figure(figsize=(10, 6))
- plt.plot(test_data, label='Actual')
- plt.plot(list(test_data.index)[-len(test_predictions):], test_predictions, label='Predicted')
- plt.xlabel('Month')
- plt.ylabel('Passengers')
- plt.title('Actual vs Predicted')
- plt.legend()
- plt.show()
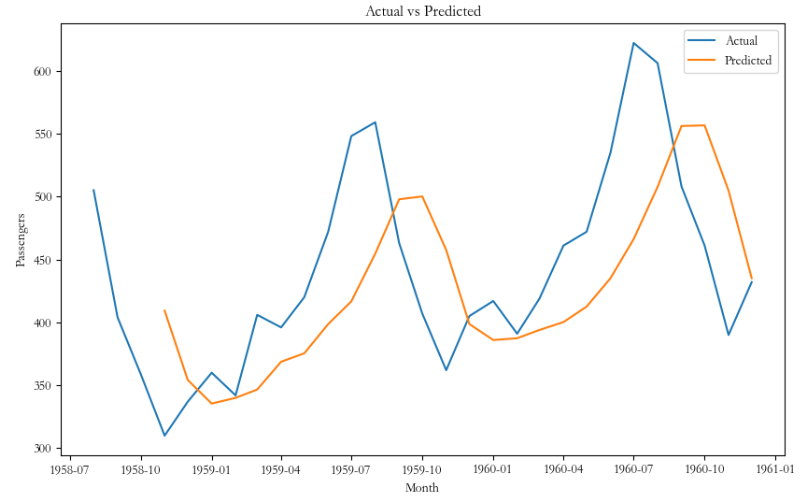
测试集真实值与预测值:
- # 绘制原始数据、训练集预测结果和测试集预测结果的折线图
- plt.figure(figsize=(10, 6))
- plt.plot(data, label='Actual')
- plt.plot(list(train_data.index)[look_back:train_size], train_predictions, label='Training Predictions')
- plt.plot(list(test_data.index)[-(len(test_data)-look_back):], test_predictions, label='Testing Predictions')
- plt.xlabel('Year')
- plt.ylabel('Passenger Count')
- plt.title('International Airline Passengers - Actual vs Predicted')
- plt.legend()
- plt.show()
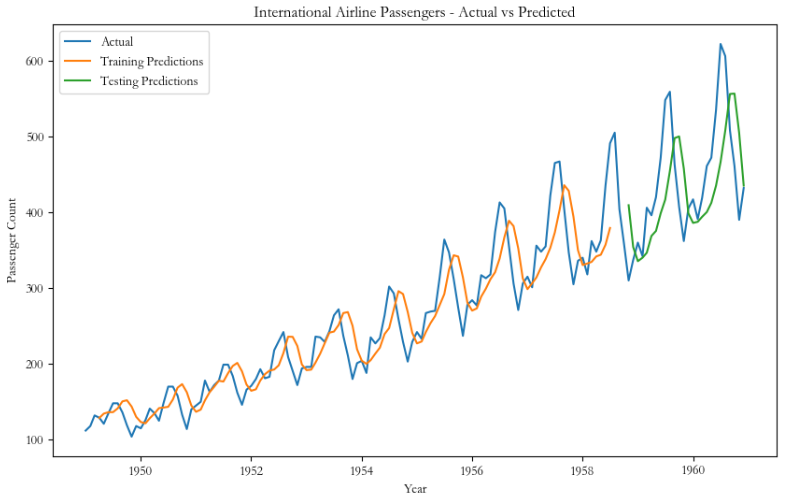
原始数据、训练集预测结果和测试集预测结果:
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/769706
推荐阅读

相关标签

