
- 1基于FPGA的音频信号的FIR滤波(Matlab+Modelsim验证)
- 2Git 基本操作命令汇总_git基本操作命令
- 3SSH远程终端神器,你在用哪一款_ssh工具
- 4Python史上最全知识重点(超详细版)进阶篇_python 进阶 笔记
- 5Flutter 开发3:创建第一个Flutter应用_android studio安装flutter
- 6ARM处理器——I.MX6ULL学习总结_i.mx6ull有srio吗
- 7《强化学习周刊》第8期:强化学习应用之自然语言处理_far-ass: fact-aware reinforced abstractive sentenc
- 8spring使用@value注解读取properties文件失败或者@value值为注解值_读取properties配置文件失败
- 915年研发经验博士手把手教学:从零开始搭建智能客服_ai智能客服设计思路
- 10FPGA学习笔记——以太网_phy与fpga连接
迁移学习--如何训练自己的图像识别分类器_图像识别 训练
赞
踩
前言
前面讲过一篇文章( 链接: VGG16),关于如何利用已训练的VGG16模型来识别图像,而本章内容主要围绕如何利用手上少量的数据,训练实现我们自己的图像分类模型,对已有的模型进行微调,得到我们想要的结果;同时,还会扩展对AlexNet与ResNet-18模型的微调实现。
一、数据准备
迁移学习是将以学习完毕的模型作为基础,通过替换最终的输出层(可加上其他层)来进行学习的方法,即将已经学习好的模型中最后的输出结果替换成我们所需要的输出结果,并根据我们所拥有的数据对被替换的层进行训练,而未被替换的层仍然保持之前训练好的参数值不变,这样训练时间短,即使手头上的数据量很少,也能相对容易实现深度学习。
本文将以蜜蜂与蚂蚁两类图片数据作为训练集,通过调整最终输出层大小实现对蚂蚁与蜜蜂的分类识别,数据集下载代码如下:
import os import urllib.request import zipfile #·文件夹“data”不存在时制作 data_dir = "./data/" if not os.path.exists(data_dir): os.mkdir(data_dir) url = "https://download.pytorch.org/tutorial/hymenoptera_data.zip" save_path = os.path.join(data_dir, "hymenoptera_data.zip") if not os.path.exists(save_path): urllib.request.urlretrieve(url, save_path) # 读取ZIP文件 zip = zipfile.ZipFile(save_path) zip.extractall(data_dir) # 解压缩ZIP zip.close() # 盗取ZIP文件 #删除ZIP文件 os.remove(save_path)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
上述代码将创建一个data文件夹来保存hymenoptera_data数据,里面包含train、val两个数据集,分别为训练集与测试集,里面都包含ants、bees两个数据集,为蚂蚁与蜜蜂的图片数据,其中ants部分数据如下:

二、数据初始化设置
图像标准化与数据增强
首先导入软件包与设置随机种子:
# 导入软件包 import glob import os.path as osp import random import numpy as np import json from PIL import Image #tqdm可用来生成进度条 from tqdm import tqdm import matplotlib.pyplot as plt %matplotlib inline import torch import torch.nn as nn import torch.optim as optim import torch.utils.data as data import torchvision from torchvision import models, transforms import os os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" #主要解决jupyter notebook“内核似乎挂掉了,它很快将自动重启”的问题 # 设置随机数的种子 torch.manual_seed(1234) np.random.seed(1234) random.seed(1234)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
建立dataset,共分三步,首先创建对图像进行预处理操作的ImageTransform类(与链接: VGG16类似);然后建立make_datapath_list函数,将图像文件路径保存到列表中;最后创建HymenopteraDataset类作为dataset。
class ImageTransform(): def __init__(self, resize, mean, std): self.data_transform = { 'train': transforms.Compose([ transforms.RandomRotation(15),#指定的角度范围随机旋转图像 transforms.ColorJitter(),#随机调整图像的亮度、对比度、饱和度和色相,增加数据的多样性 可指定如0.1,0.1,0.1,0.1 #transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), value=0, inplace=False),#以一定概率随机擦除图像的一部分区域,并用随机值填充。 #p擦除概率50%,scale:擦除区域的面积比例范围2% 到 33%,ratio:擦除区域的宽高比范围,value:擦除后用什么值填充擦除区域,默认为 0,inplace:是否替换原图像,默认为 False transforms.RandomResizedCrop(resize, scale=(0.5, 1.0)), #数据增强处理比例裁剪 transforms.RandomHorizontalFlip(), #数据增强处理水平翻转 transforms.ToTensor(), # 转换为张量 transforms.Normalize(mean, std) # 归一化 ]), 'val': transforms.Compose([ transforms.Resize(resize), #调整大小 transforms.CenterCrop(resize), #从图像中央截取resize×resize大小的区 transforms.ToTensor(), #转换为张量 transforms.Normalize(mean, std) #归一化 ]) } def __call__(self, img, phase='train'): return self.data_transform[phase](img)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
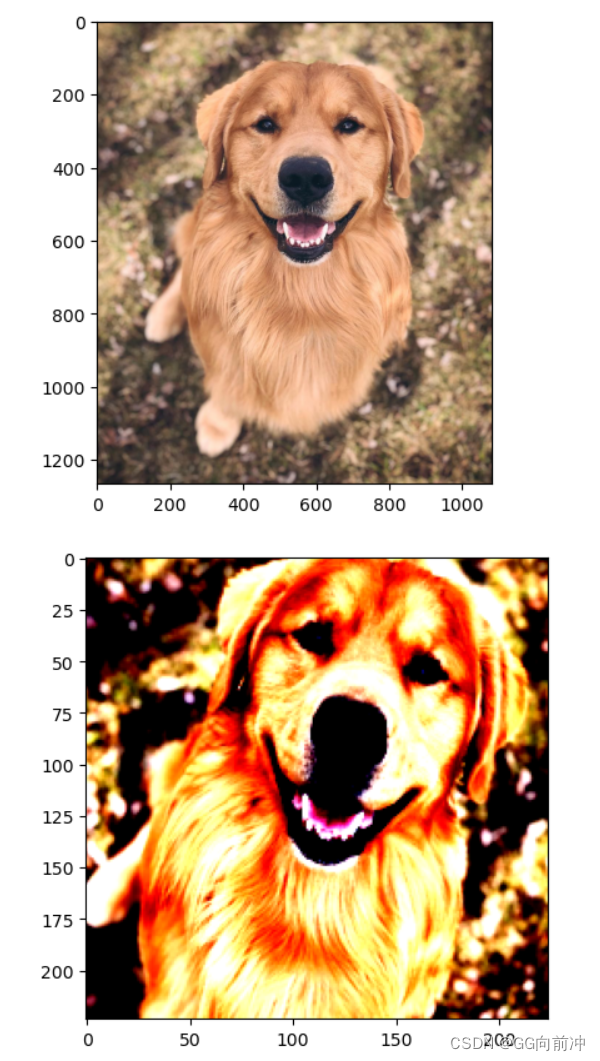
ImageTransform类需要导入图片需要的大小、均值与方差,通过设置标签“train”则将图像进行选择、裁剪等数据增强处理,再进行标准化;设置标签“val”则将图像直接进行标准化处理,无需数据增强。下方代码为展示结果:
# 1. 读入图像文件 image_file_path = './data/R-C.jpg' img = Image.open(image_file_path) #[高度][宽度][颜色RGB] # 2. 显示原图像 plt.imshow(img) plt.show() # 3. 显示预处理前和处理完毕后的图像 size = 224 mean = (0.485, 0.456, 0.406) std = (0.229, 0.224, 0.225) transform = ImageTransform(size, mean, std) img_transformed = transform(img, phase="train") # torch.Size([3, 224, 224]) # 将(颜色、高度、宽度)转换为(高度、宽度、颜色),取值限制在 0~1,并显示 img_transformed = img_transformed.numpy().transpose((1, 2, 0)) img_transformed = np.clip(img_transformed, 0, 1) plt.imshow(img_transformed) plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
接下来进行make_datapath_list类构建,需要设置传入参数phase来识别是训练数据还是测试数据,通过设置phase参数将训练集与测试集的所有图片数据分别保存到train_list 与val_list :
def make_datapath_list(phase="train"): rootpath = "./data/hymenoptera_data/" target_path = osp.join(rootpath+phase+'/*/*.jpg') print(target_path) path_list = [] # 保存到这里 # 使用 glob 取得包括示例目录的文件路径 for path in glob.glob(target_path): path_list.append(path) return path_list # 执行 train_list = make_datapath_list(phase="train") val_list = make_datapath_list(phase="val") train_list
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
最后通过HymenopteraDataset类来建立dataset实例,HymenopteraDataset需要输入训练或测试的文件路径、标准化函数以及phase表示训练还是测试;其次在内部会实现对图片的预处理操作(利用前面的ImageTransform),以及在文件名中抽取出图片标签,并将标签转换为数字(蚂蚁为0,蜜蜂为1),最后将预处理后的图片与标签输出。
class HymenopteraDataset(data.Dataset): def __init__(self, file_list, transform=None, phase='train'): self.file_list = file_list # 文件路径列表 self.transform = transform # 预处理类的实例 self.phase = phase # 指定是train 还是val def __len__(self): return len(self.file_list) def __getitem__(self, index): #载入第index张图片 img_path = self.file_list[index] img = Image.open(img_path) #[高度][宽度][颜色RGB] #对图片进行预处理 img_transformed = self.transform(img, self.phase) # torch.Size([3, 224, 224]) #从文件名中抽取图片的标签 if self.phase == "train": label = img_path[30:34] elif self.phase == "val": label = img_path[28:32] #将标签转换为数字 if label == "ants": label = 0 elif label == "bees": label = 1 return img_transformed, label #执行 train_dataset = HymenopteraDataset( file_list=train_list, transform=ImageTransform(size, mean, std), phase='train') val_dataset = HymenopteraDataset( file_list=val_list, transform=ImageTransform(size, mean, std), phase='val') #确认执行结果 index = 0 print(train_dataset.__getitem__(index)[0].size()) print(train_dataset.__getitem__(index)[1])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43

下面使用dataset来创建dataloader,利用pytorch中torch.utils.data.DataLoader创建,在训练集中,设置shuffle=True,表示随机打乱读入图片数据。
最后将训练集与测试集保存到字典dataloaders_dict 中,方便后续学习与验证操作时方便调用:
#指定小批次尺寸 batch_size = 32 #创建DataLoader train_dataloader = torch.utils.data.DataLoader( train_dataset, batch_size=batch_size, shuffle=True) val_dataloader = torch.utils.data.DataLoader( val_dataset, batch_size=batch_size, shuffle=False) #集中到字典变量中,方便调用 dataloaders_dict = {"train": train_dataloader, "val": val_dataloader} #确认执行结果 batch_iterator = iter(dataloaders_dict["train"]) #转换成迭代器 inputs, labels = next(batch_iterator) #取出第一个元素 print(inputs.size()) print(labels)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
三、创建网络模型
通过上述操作,我们完成了数据的准备工作,接下来创建网络模型,参考链接: VGG16内容,加载已经训练完毕的VGG-16模型。但是输出模型不再是1000种,而是只有蚂蚁与蜜蜂这两种,所以我们需要替换VGG-16最后的全连接层。代码如下:
# 载入已经学习完毕的VGG−16模型
#创建VGG−16模型的实例
use_pretrained = True#指定使用已经训练好的参数
net = models.vgg16(pretrained=use_pretrained)
net
- 1
- 2
- 3
- 4
- 5

#指定使用已经训练好的参数,由于只有两个类别,输出需要将1000改为2 net.classifier[6] = nn.Linear(in_features=4096, out_features=2) #设定为训练模式 net.train() print('网络设置完毕 :载入已经学习完毕的权重,并设置为训练模式') #设置损失函数,交叉熵损失 criterion = nn.CrossEntropyLoss() #将使用迁移学习进行训练的参数保存到params_to_update变量中 params_to_update = [] #需要学习的参数名称,需要改变classifier中的第六层网络参数w与b(权重、偏执) update_param_names = ["classifier.6.weight", "classifier.6.bias"] #除了需要学习的那些参数外,其他参数设置为不进行梯度计算,禁止更新 for name, param in net.named_parameters(): if name in update_param_names: param.requires_grad = True params_to_update.append(param) print(name) else: param.requires_grad = False #确认params_to_update的内容,随机参数 print("-----------") print(params_to_update)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
其中,我们设置交叉熵损失函数,作用与分类模型中,其次,将需要跟新的网络层参数设置为requires_grad = True,这在训练中会计算梯度,参数值会发生改变,如果想要固定值阻止更新,则可设置为requires_grad = False。

下面设置优化算法,这里使用SGD算法,并设置momentum为0.9,这相当于添加一个惯性项,以模拟物理上的惯性效应,从而使得更新方向不仅取决于当前的梯度,还取决于之前更新方向的90%的历史梯度,再将之前需要学习的params_to_update赋值给参数params。
#设置最优化算法
optimizer = optim.SGD(params=params_to_update, lr=0.001, momentum=0.9)
- 1
- 2
四、模型训练与验证
最后对网络模型进行训练与验证,首先定义训练模型用的train_model函数,通过设置epoch来对模型进行循环训练,并通过phase来设置网络是训练模式还是验证模式,其中torch.set_grad_enabled(phase == ‘train’)梯度更新只在训练模型下才进行。
# 创建训练模型用的函数 def train_model(net, dataloaders_dict, criterion, optimizer, num_epochs): #epoch循环 for epoch in range(num_epochs): print('Epoch {}/{}'.format(epoch+1, num_epochs)) print('-------------') # 每个epoch中的学习和验证循环 for phase in ['train', 'val']: if phase == 'train': net.train() #将模式设置为训练模式 else: net.eval() #将模式设置为验证模式 epoch_loss = 0.0#epoch的合计损失 epoch_corrects = 0#epoch的正确答案数量 #为了确认训练前的验证能力,省略epoch=0时的训练 if (epoch == 0) and (phase == 'train'): continue #载入数据并切取出小批次的循环 for inputs, labels in tqdm(dataloaders_dict[phase]): #初始化optimizer optimizer.zero_grad() #计算正向传播(forward) with torch.set_grad_enabled(phase == 'train'): #是否使用梯度计算 outputs = net(inputs) loss = criterion(outputs, labels) #计算损失 _, preds = torch.max(outputs, 1) #预测标签 ##训练时的反向传播 if phase=='train': loss.backward() optimizer.step() # 计算迭代的结果,loss为批次平均的损失 epoch_loss += loss.item() * inputs.size(0) # 更新正确答案数量的总和 epoch_corrects += torch.sum(preds==labels.data) #显示每个epoch的loss和正解率 epoch_loss = epoch_loss / len(dataloaders_dict[phase].dataset) epoch_acc = epoch_corrects.double() / len(dataloaders_dict[phase].dataset) print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
# 开始学习和验证
num_epochs = 2
train_model(net, dataloaders_dict, criterion, optimizer, num_epochs=num_epochs)
- 1
- 2
- 3

通过两轮训练后,可以发现在测试集上的准确率达到了0.941,可以说是能够很好的分类识别蜜蜂与蚂蚁了,但训练集的准确率较低为0.716,可能有两个原因,第一个是模型对于训练数据只迭代了一次,而验证数据则是经历了两次迭代,因此更好。第二个是训练数据使用了数据增强,导致图像变形,可能会造成分类识别困难。不过随着增加num_epochs次数,训练与测试之间的差距会越来越小。
五、扩展
上面我们介绍了怎么利用VGG-16进行迁移学习,接下来介绍如何利用AlexNet模型与ResNet-18模型进行图像识别与分类,使用起来与上文VGG-16的操作步骤类似,代码如下:
# 载入已经学习完毕的VResNet-18模型
#创建VResNet-18模型的实例
use_pretrained = True#指定使用已经训练好的参数
net2 = models.resnet18(pretrained=use_pretrained)
net2
- 1
- 2
- 3
- 4
- 5

残差网络主要由多个残差块构成,最后通过自适应平均池化层输出。
#指定使用已经训练好的参数,由于只有两个类别,输出需要将1000改为2 bias默认为true net2.fc = nn.Linear(in_features=512, out_features=2) #设定为训练模式 net2.train() print('网络设置完毕 :载入已经学习完毕的权重,并设置为训练模式') #设置损失函数,交叉熵损失 criterion2 = nn.CrossEntropyLoss() #将使用迁移学习进行训练的参数保存到params_to_update变量中 params_to_update = [] #需要学习的参数名称,需要改变classifier中的第六层网络参数w与b(权重、偏执) update_param_names = ["fc.weight", "fc.bias"] #除了需要学习的那些参数外,其他参数设置为不进行梯度计算,禁止更新 for name, param in net2.named_parameters(): if name in update_param_names: param.requires_grad = True params_to_update.append(param) print(name) else: param.requires_grad = False #确认params_to_update的内容,随机参数 print("-----------") print(params_to_update)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
#设置最优化算法
optimizer2 = optim.SGD(params=params_to_update, lr=0.01)
- 1
- 2
# 开始学习和验证
num_epochs = 10
train_model(net2, dataloaders_dict, criterion2, optimizer2, num_epochs=num_epochs)
- 1
- 2
- 3
同样使用上面建立的train_model训练测试函数进行学习预测:

经过10轮小批次训练后,可以看到训练误差与测试误差十分相近,分别为0.917与0.941,能够很好的去分类蚂蚁与蜜蜂。对于AlexNet网络操作方法如上,这里就不再赘述。
总结
本文主要展示如何利用迁移学习训练模型,通过修改VGG-16网络层,实现蚂蚁与蜜蜂的分类,这能够让我们在拥有较少的数据集下,能够快速、有效、方便的建立网络模型,实现自己的图像识别分类器。

