摘要
本文结合实例详细阐明了Spark数据倾斜的几种场景以及对应的解决方案,包括避免数据源倾斜,调整并行度,使用自定义Partitioner,使用Map侧Join代替Reduce侧Join,给倾斜Key加上随机前缀等。
为何要处理数据倾斜(Data Skew)
什么是数据倾斜
对Spark/Hadoop这样的大数据系统来讲,数据量大并不可怕,可怕的是数据倾斜。
何谓数据倾斜?数据倾斜指的是,并行处理的数据集中,某一部分(如Spark或Kafka的一个Partition)的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈。
对于分布式系统而言,理想情况下,随着系统规模(节点数量)的增加,应用整体耗时线性下降。如果一台机器处理一批大量数据需要120分钟,当机器数量增加到三时,理想的耗时为120 / 3 = 40分钟,如下图所示。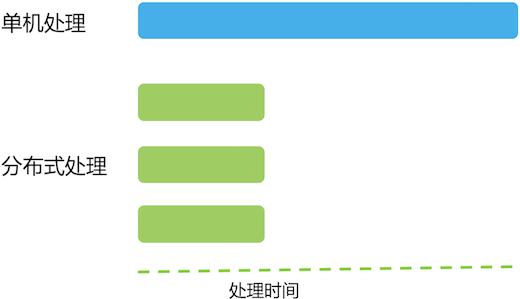
但是,上述情况只是理想情况,实际上将单机任务转换成分布式任务后,会有overhead,使得总的任务量较之单机时有所增加,所以每台机器的执行时间加起来比单台机器时更大。这里暂不考虑这些overhead,假设单机任务转换成分布式任务后,总任务量不变。
但即使如此,想做到分布式情况下每台机器执行时间是单机时的1 / N,就必须保证每台机器的任务量相等。不幸的是,很多时候,任务的分配是不均匀的,甚至不均匀到大部分任务被分配到个别机器上,其它大部分机器所分配的任务量只占总得的小部分。比如一台机器负责处理80%的任务,另外两台机器各处理10%的任务,如下图所示。
在上图中,机器数据增加为三倍,但执行时间只降为原来的80%,远低于理想值。
数据倾斜的危害
从上图可见,当出现数据倾斜时,小量任务耗时远高于其它任务,从而使得整体耗时过大,未能充分发挥分布式系统的并行计算优势。
另外,当发生数据倾斜时,部分任务处理的数据量过大,可能造成内存不足使得任务失败,并进而引进整个应用失败。
数据倾斜是如何造成的
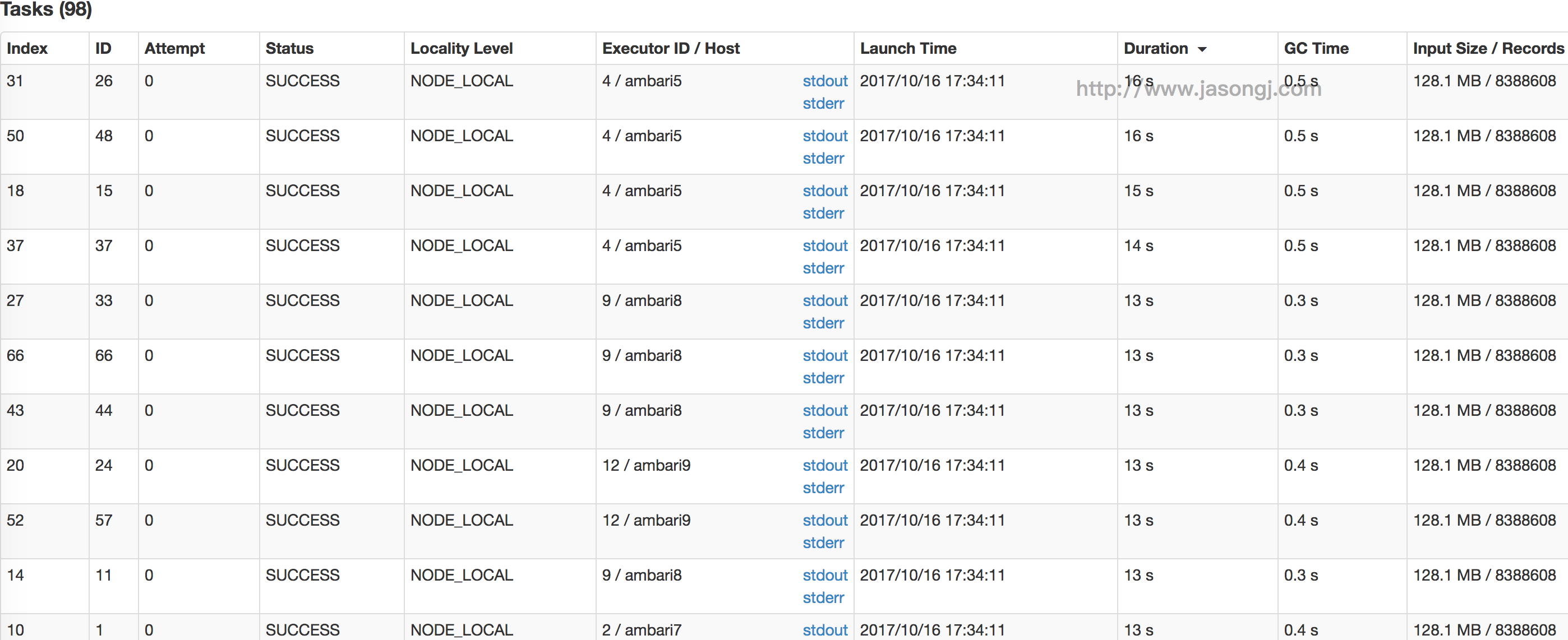
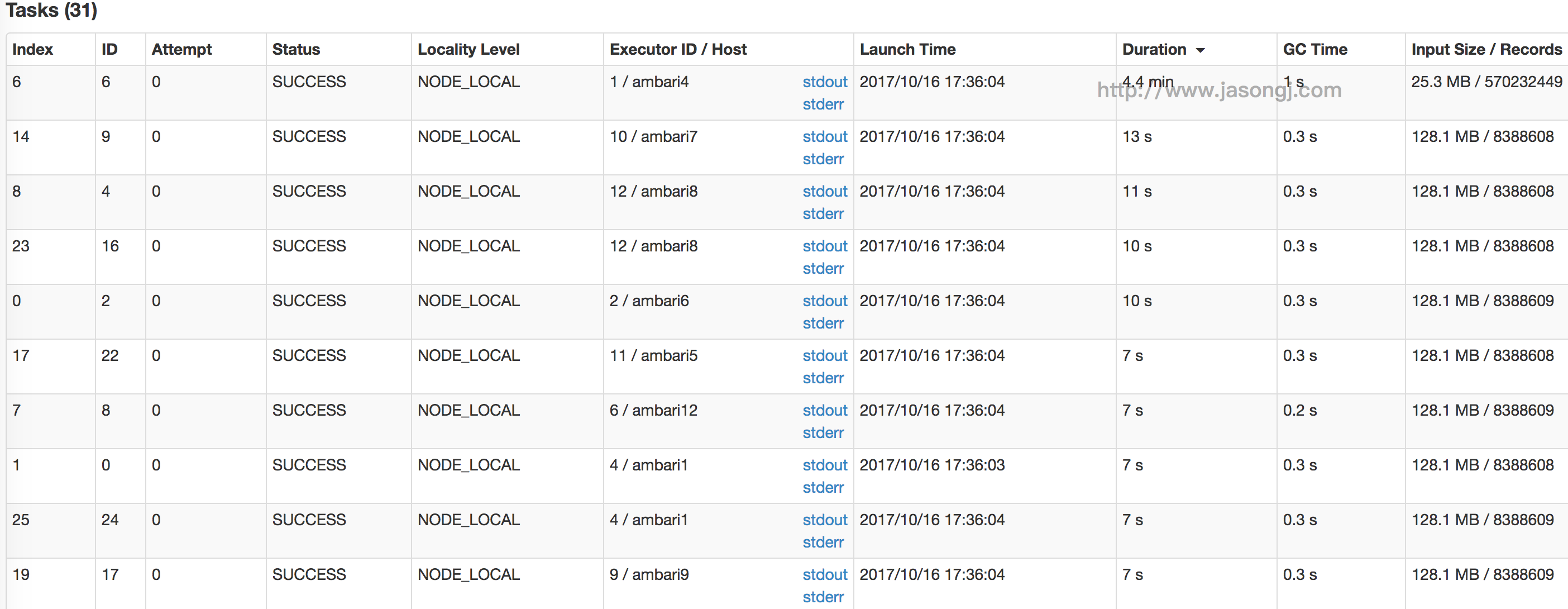
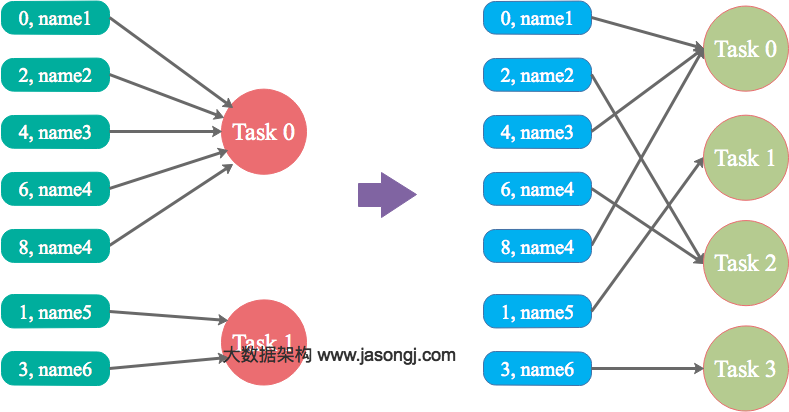
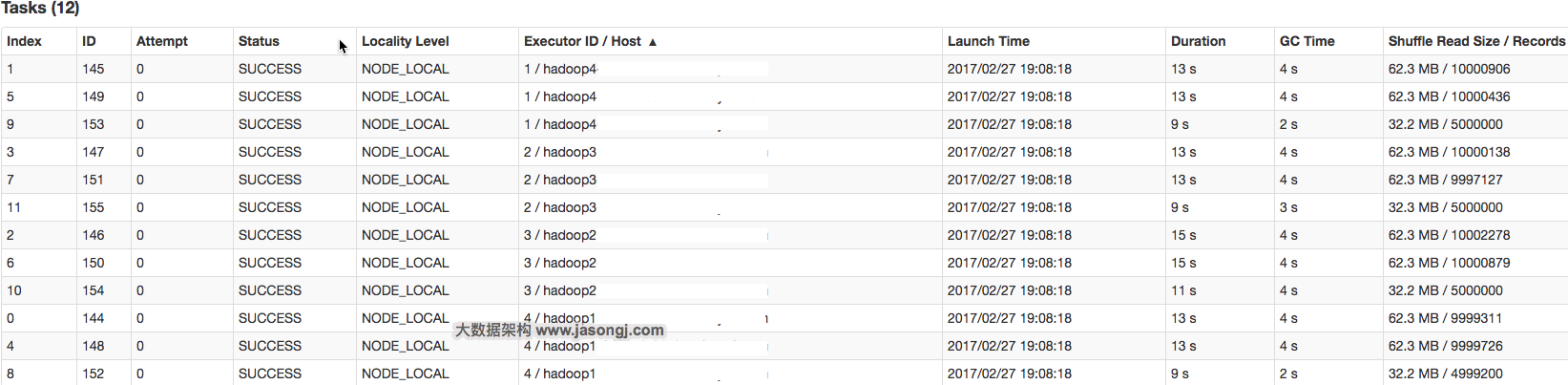
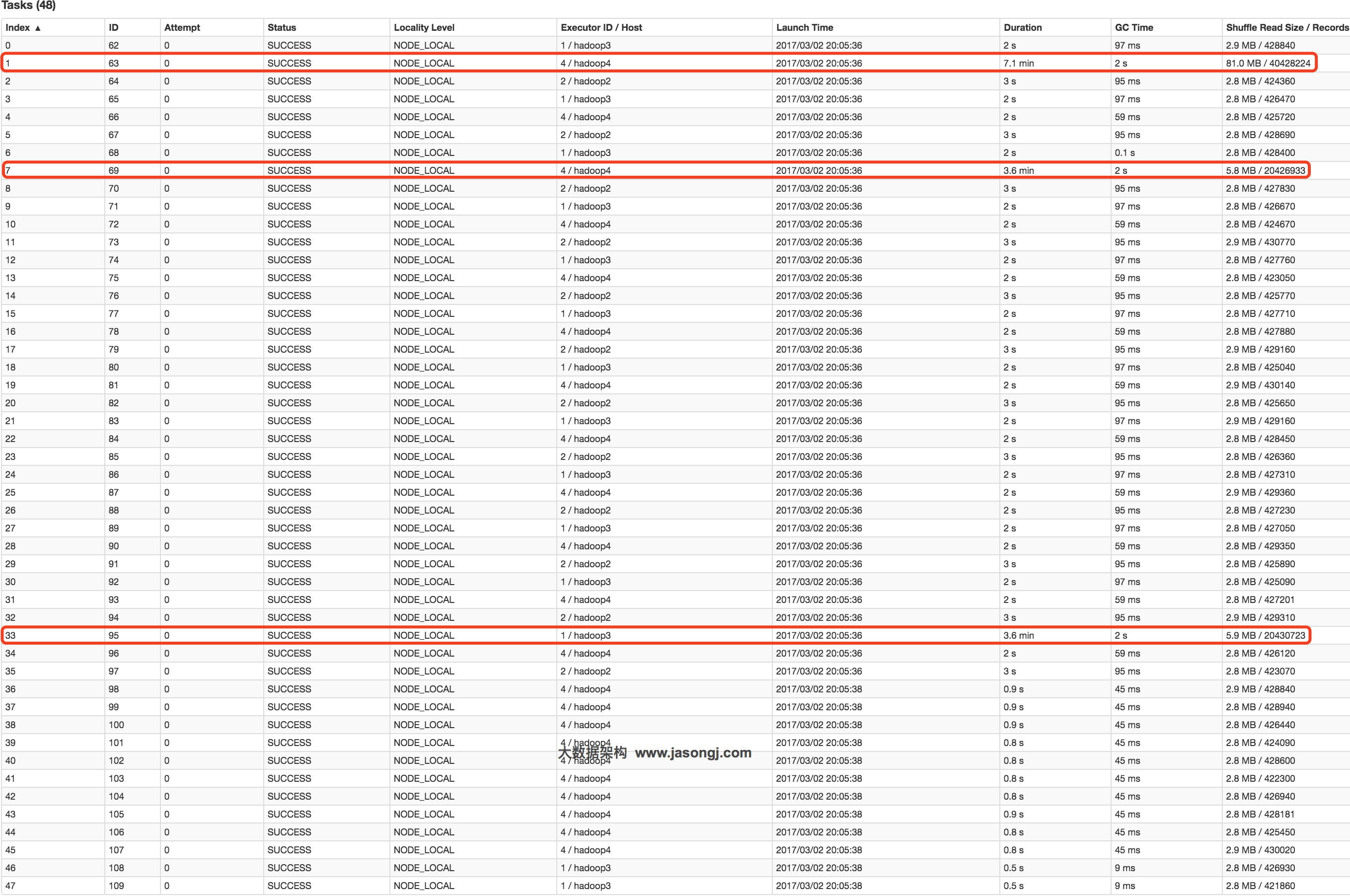
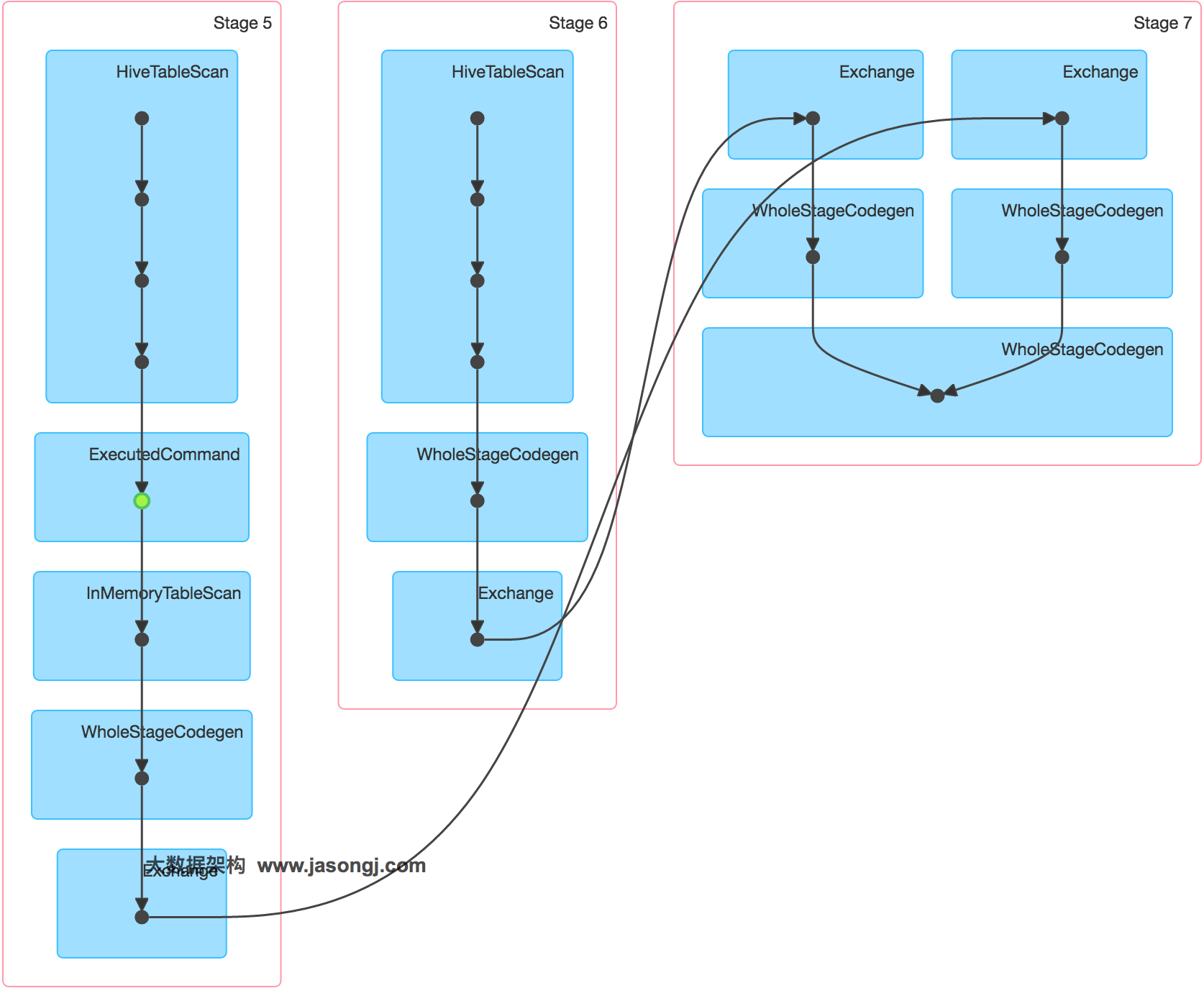
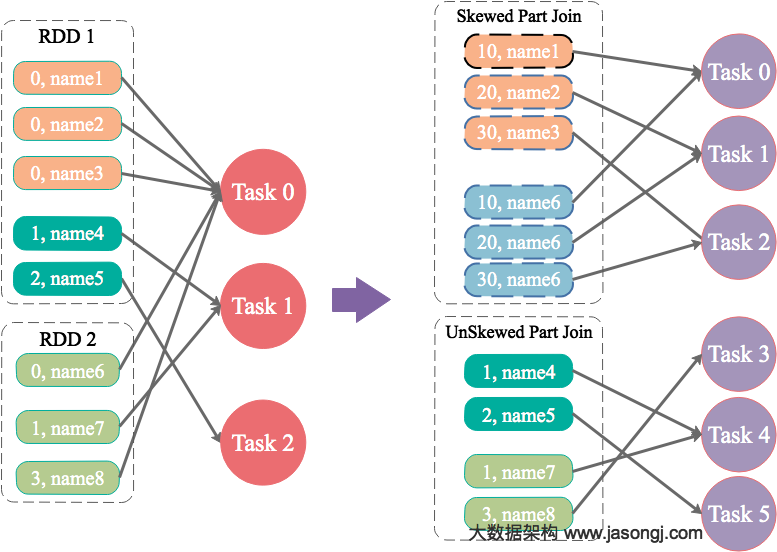
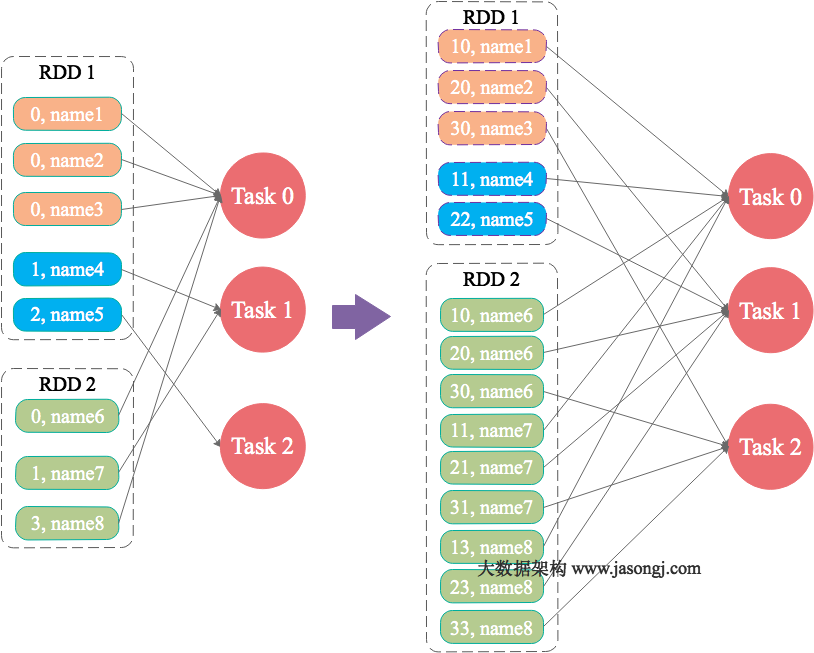
在Spark中,同一个Stage的不同Partition可以并行处理,而具有依赖关系的不同Stage之间是串行处理的。假设某个Spark Job分为Stage 0和Stage 1两个Stage,且Stage 1依赖于Stage 0,那Stage 0完全处理结束之前不会处理Stage 1。而Stage 0可能包含N个Task,这N个Task可以并行进行。如果其中N-1个Task都在10秒内完成,而另外一个Task却耗时1分钟,那该Stage的总时间至少为1分钟。换句话说,一个Stage所耗费的时间,主要由最慢的那个Task决定。
由于同一个Stage内的所有Task执行相同的计算,在排除不同计算节点计算能力差异的前提下,不同Task之间耗时的差异主要由该Task所处理的数据量决定。
Stage的数据来源主要分为如下两类
- 从数据源直接读取。如读取HDFS,Kafka
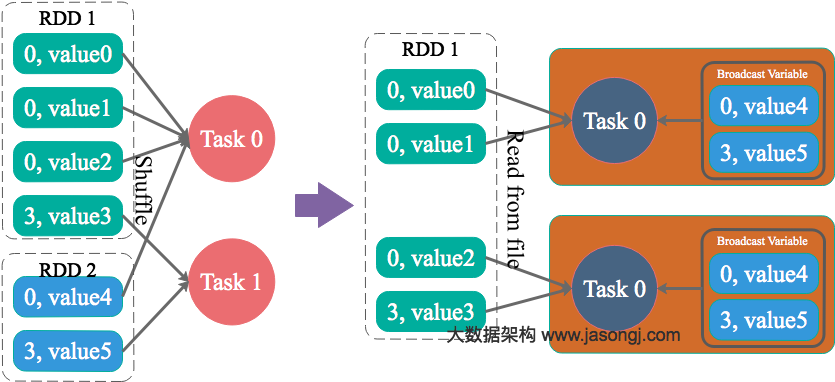
- 读取上一个Stage的Shuffle数据
如何缓解/消除数据倾斜
避免数据源的数据倾斜 ———— 读Kafka
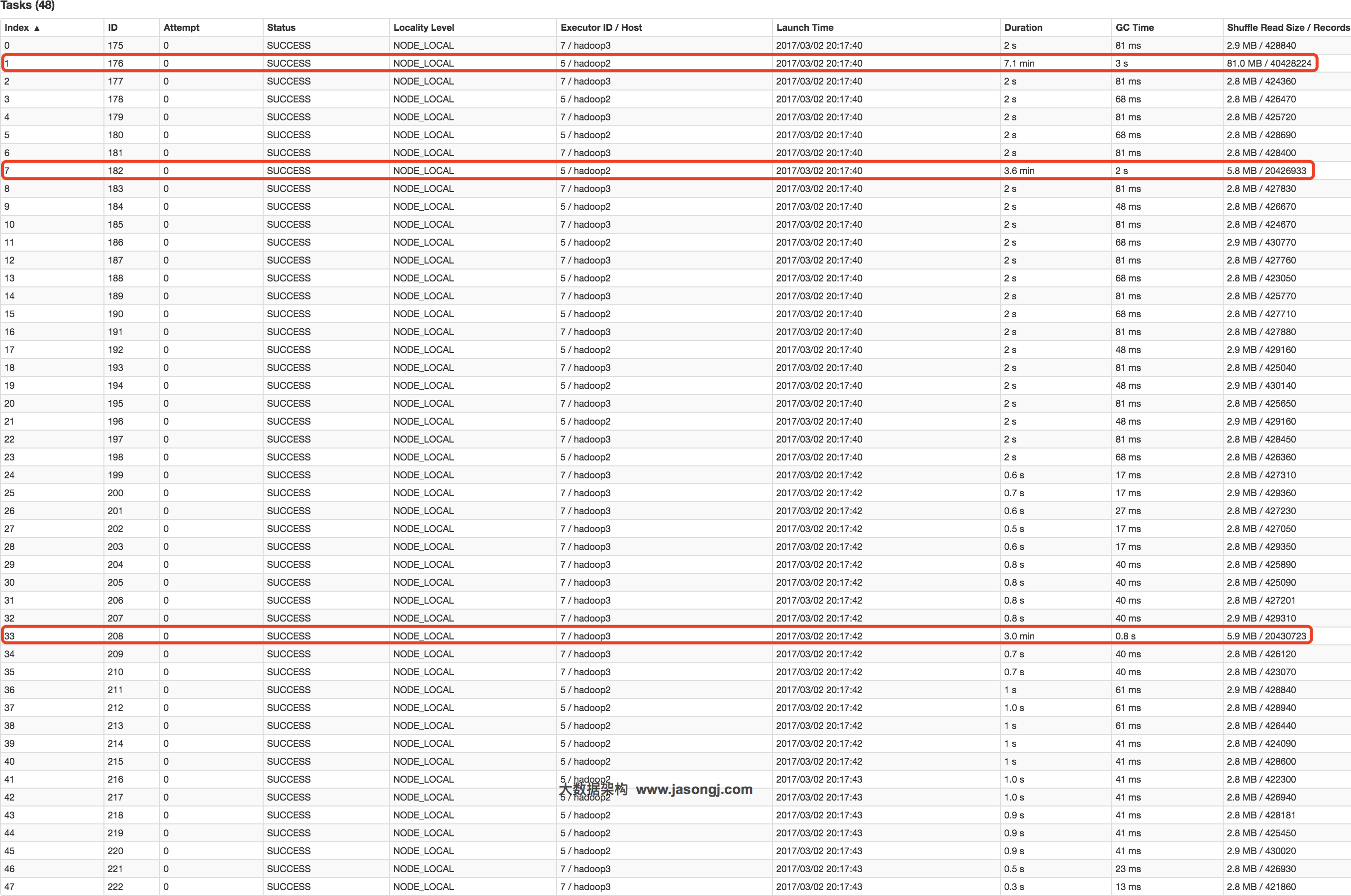
以Spark Stream通过DirectStream方式读取Kafka数据为例。由于Kafka的每一个Partition对应Spark的一个Task(Partition),所以Kafka内相关Topic的各Partition之间数据是否平衡,直接决定Spark处理该数据时是否会产生数据倾斜。
如《Kafka设计解析(一)- Kafka背景及架构介绍》一文所述,Kafka某一Topic内消息在不同Partition之间的分布,主要由Producer端所使用的Partition实现类决定。如果使用随机Partitioner,则每条消息会随机发送到一个Partition中,从而从概率上来讲,各Partition间的数据会达到平衡。此时源Stage(直接读取Kafka数据的Stage)不会产生数据倾斜。
但很多时候,业务场景可能会要求将具备同一特征的数据顺序消费,此时就需要将具有相同特征的数据放于同一个Partition中。一个典型的场景是,需要将同一个用户相关的PV信息置于同一个Partition中。此时,如果产生了数据倾斜,则需要通过其它方式处理。
避免数据源的数据倾斜 ———— 读文件
原理
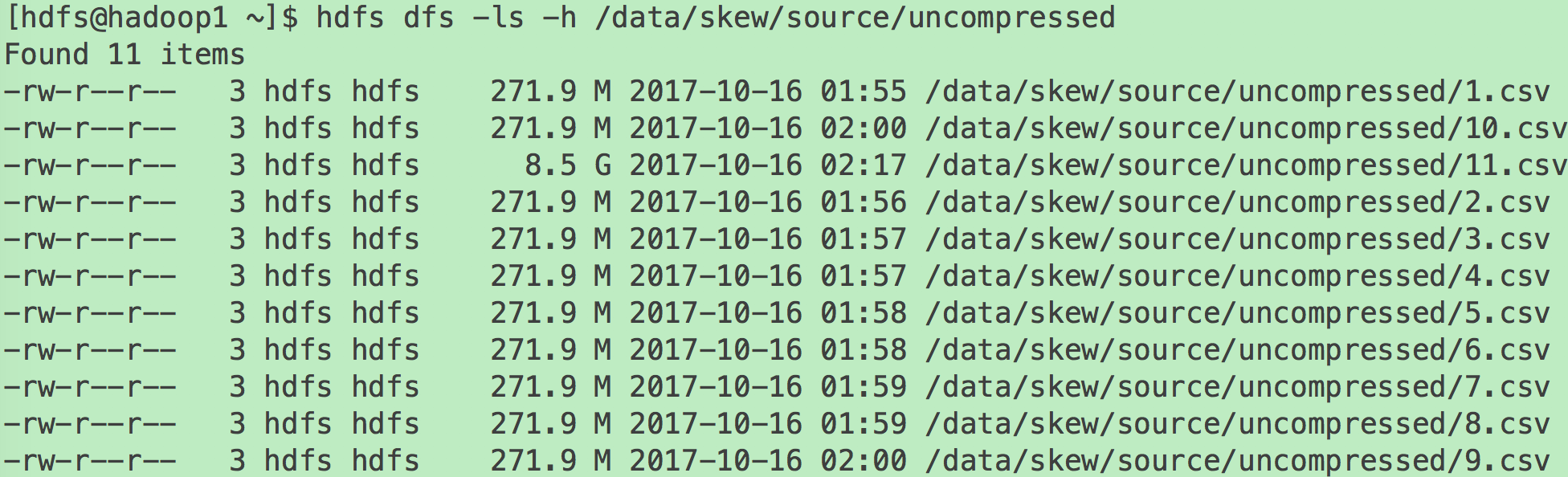
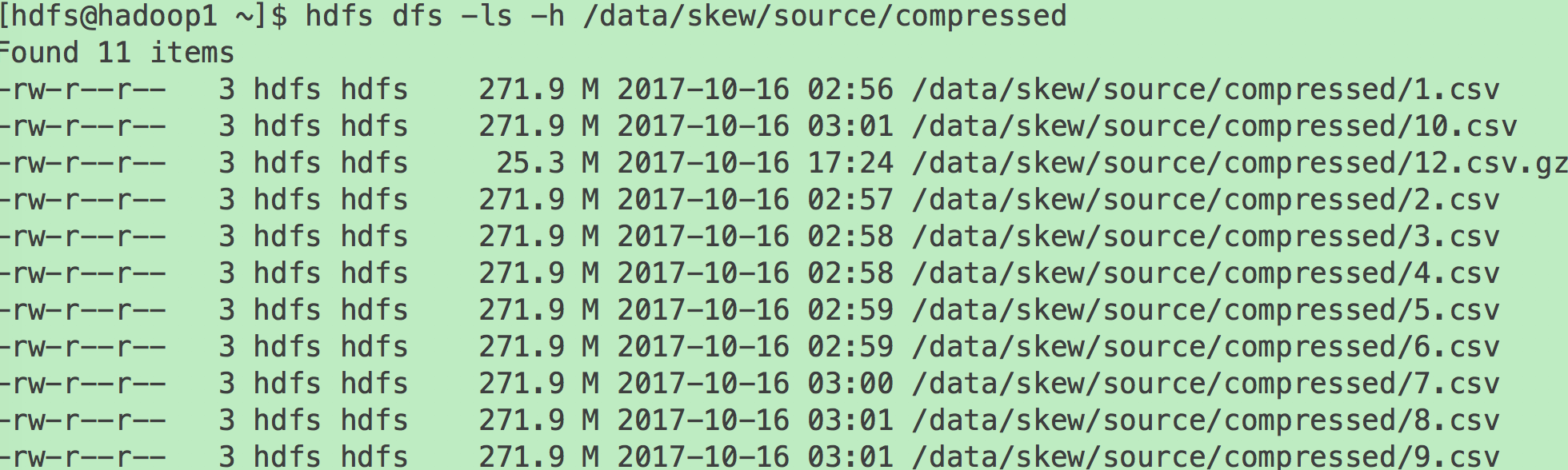
Spark以通过textFile(path, minPartitions)方法读取文件时,使用TextFileFormat。
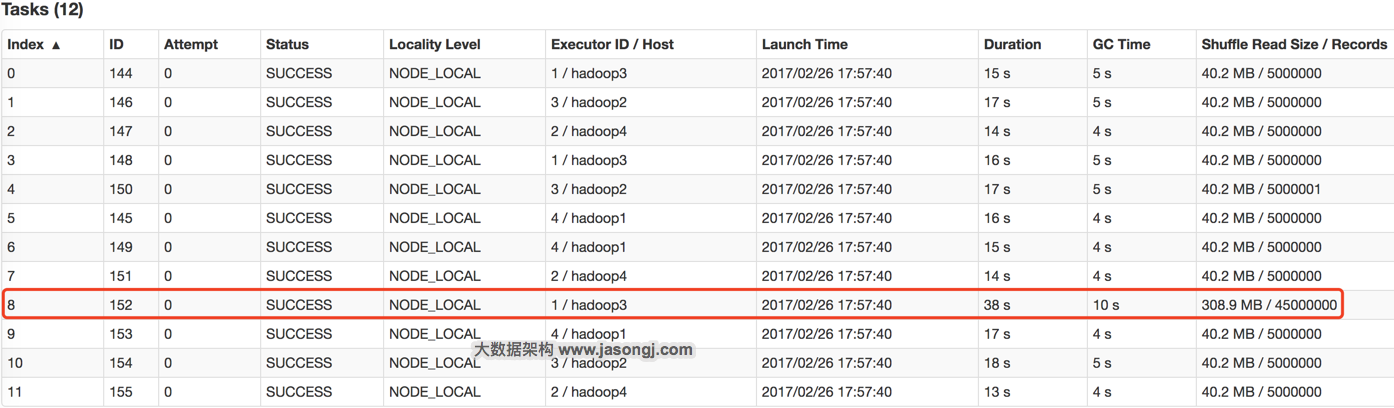
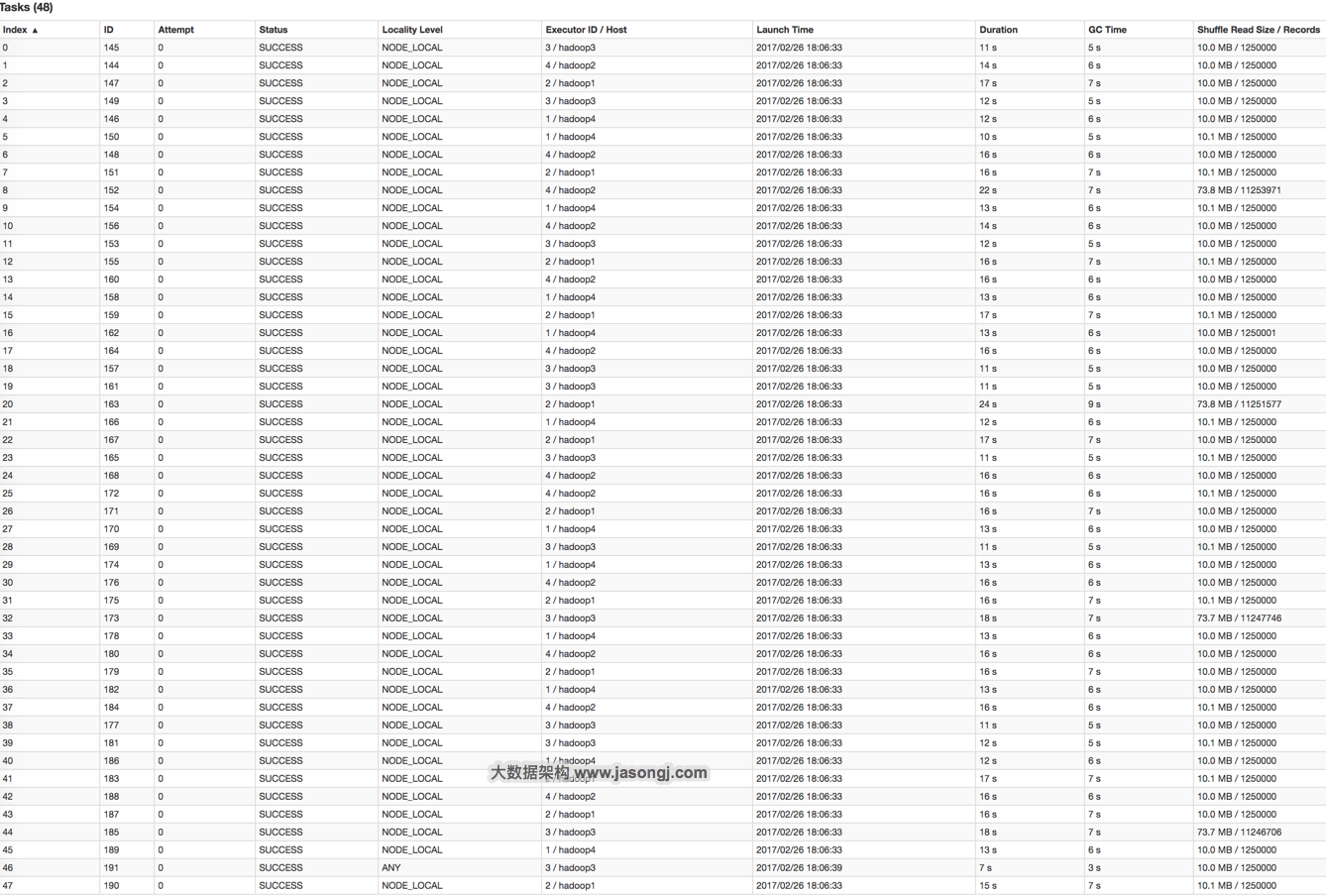
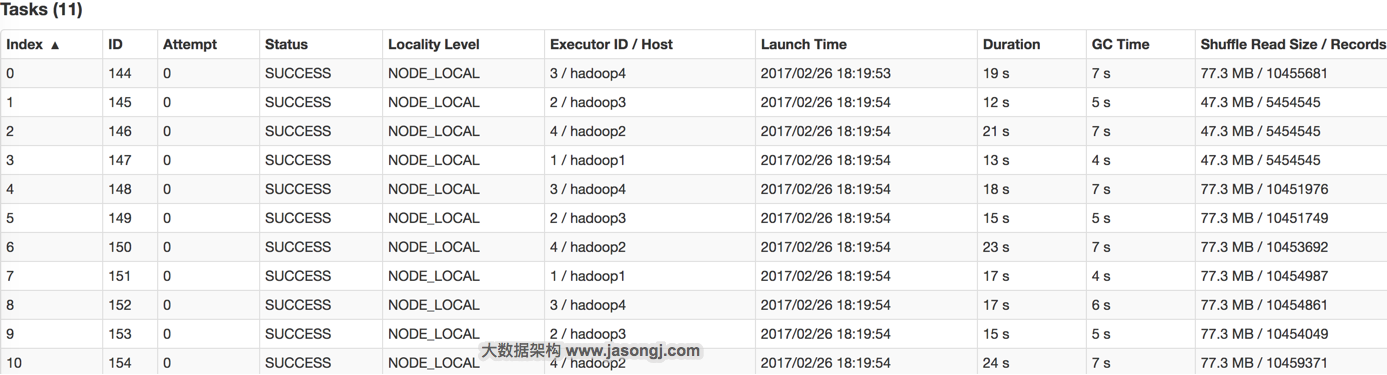
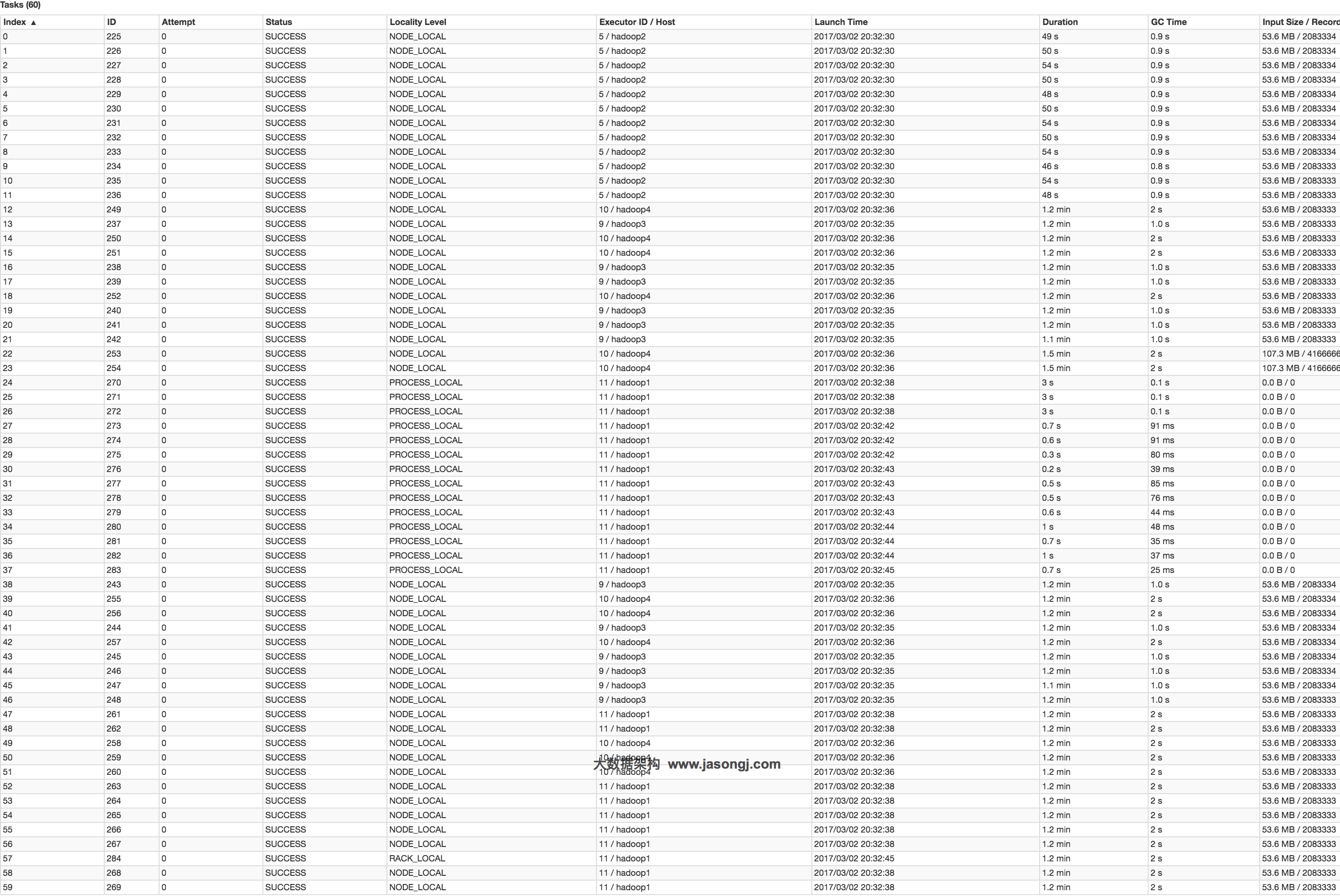
对于不可切分的文件,每个文件对应一个Split从而对应一个Partition。此时各文件大小是否一致,很大程度上决定了是否存在数据源侧的数据倾斜。另外,对于不可切分的压缩文件,即使压缩后的文件大小一致,它所包含的实际数据量也可能差别很多,因为源文件数据重复度越高,压缩比越高。反过来,即使压缩文件大小接近,但由于压缩比可能差距很大,所需处理的数据量差距也可能很大。
此时可通过在数据生成端将不可切分文件存储为可切分文件,或者保证各文件包含数据量相同的方式避免数据倾斜。
对于可切分的文件,每个Split大小由如下算法决定。其中goalSize等于所有文件总大小除以minPartitions。而blockSize,如果是HDFS文件,由文件本身的block大小决定;如果是Linux本地文件,且使用本地模式,由fs.local.block.size决定。