
- 1hadoop的三大核心组件之HDFS和YARN_hdfs yern
- 2【实体对齐·HGCN】Jointly Learning Entity and Relation Representations for Entity Alignment
- 3Linux系统简介_linux硬件设备由什么直接管理
- 4Git入门到精通(大全)_git从入门到精通
- 5软件测试只会“点点点”,凭什么让开发看的起你?_软件测试点点点
- 6echarts的简单使用_echarts简单使用
- 7Introduction to 3D Game Programming with DirectX 12 学习笔记之 --- 第七章:在Direct3D中绘制(二)_direct3d画圆
- 8HarmonyOS Next 使用Web获取相机拍照图片案例_onshowfileselector返回值
- 9用70行Python编写一个概率编程语言_pyro教材 概率编程
- 10自动化搞钱:7个最强免费AI工具,10倍速提升赚钱、超过99%的人_7個最強免費ai工具,10倍速提升賺錢、自媒體內容創作、工作效率,超過99%的人
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model翻译
赞
踩
摘要
我们提出了 DeepSeek-V2,一种强大的混合专家 (MoE) 语言模型,具有训练经济、推理高效的特点。它包含 236B 总参数,其中每个 token 激活 21B,支持 128K token 的上下文长度。DeepSeek-V2 采用了包括 Multi-head Latent Attention (MLA) 和 DeepSeekMoE 在内的创新架构。MLA 通过将key-value (KV) 缓存显著压缩为潜在向量来保证高效推理,而 DeepSeekMoE 通过稀疏计算以经济的成本训练强大的模型。与 DeepSeek 67B 相比,DeepSeek-V2 实现了显著增强的性能,同时节省了 42.5% 的训练成本、减少了 93.3% 的 KV 缓存、并将最大生成吞吐量提升至 5.76 倍。我们在由 8.1T token组成的高质量多源语料库上对 DeepSeek-V2 进行了预训练,并进一步执行有监督微调 (SFT) 和强化学习 (RL) 以充分发挥其潜力。评估结果表明,即使只有 21B 激活参数,DeepSeek-V2 及其chat版本仍然在开源模型中实现了顶级性能。模型checkpoint可在 https://github.com/deepseek-ai/DeepSeek-V2 上找到。
1.介绍
过去几年,大型语言模型 (LLM) 经历了快速发展,让我们看到了通用人工智能 (AGI) 的曙光。一般来说,LLM 的智能会随着参数数量的增加而提高,从而能够在各种任务中展现出新兴的能力。然而,这种改进是以更大的训练计算资源和潜在的推理吞吐量下降为代价的。这些限制带来了重大挑战,阻碍了 LLM 的广泛采用和使用。为了解决这个问题,我们推出了 DeepSeek-V2,这是一个强大的开源混合专家 (MoE) 语言模型,其特点是通过创新的 Transformer 架构实现经济的训练和高效的推理。它总共配备了 236B 个参数,其中每个 token 激活 21B,并支持 128K 个 token 的上下文长度。
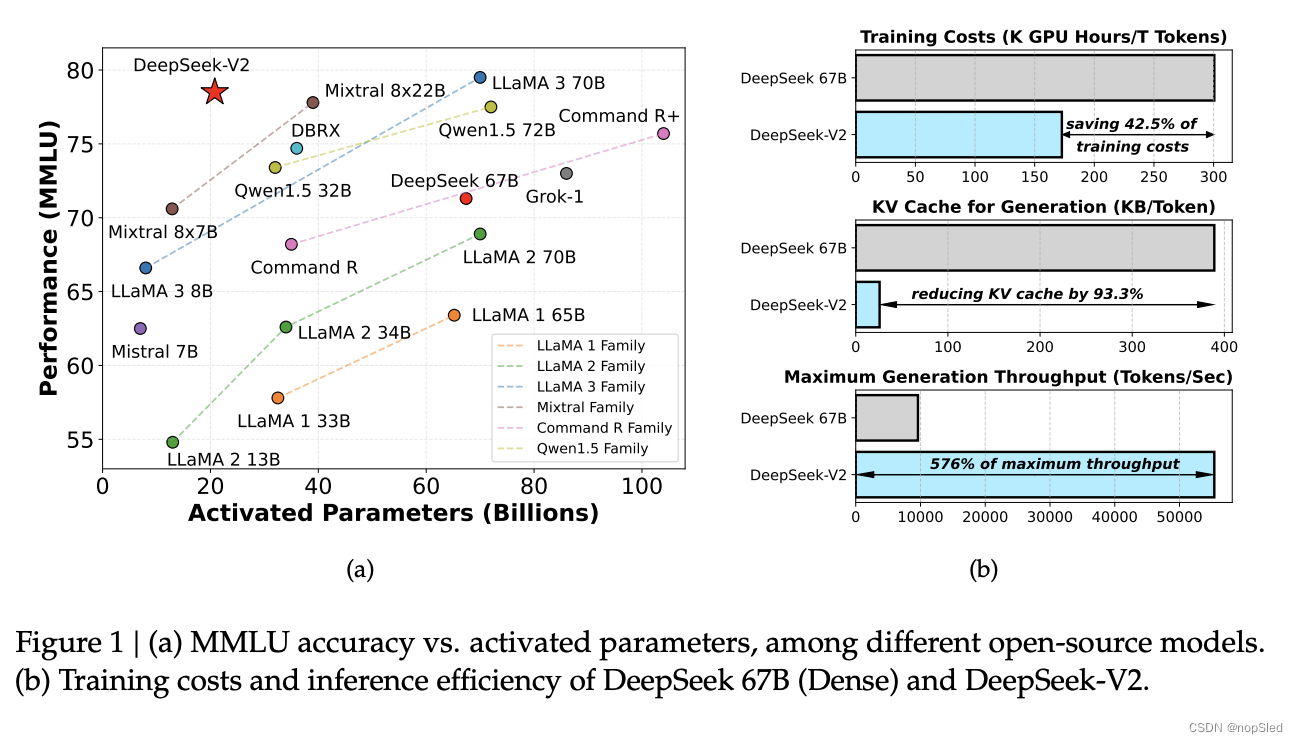
我们利用提出的 Multi-head Latent Attention (MLA) 和 DeepSeekMoE 优化了 Transformer 框架中的注意力模块和前馈网络 (FFN)。(1)在注意力机制中,多头注意力 (MHA) 的key-value (KV) 缓存对 LLM 的推理效率造成了重大阻碍。人们已经探索了各种方法来解决这个问题,包括group-query注意力 (GQA) 和multi-query注意力 (MQA)。然而,这些方法在试图减少 KV 缓存时往往会损害性能。为了兼顾两全其美,我们引入了 MLA,一种配备低秩key-value联合压缩的注意力机制。从经验上看,MLA 与 MHA 相比实现了相当的性能,同时显著减少了推理过程中的 KV 缓存,从而提高了推理效率。(2) 对于前馈网络 (FFN),我们遵循 DeepSeekMoE 架构,该架构采用细粒度专家分割和共享专家隔离,以实现更高效的专业化潜力。与 GShard 等传统 MoE 架构相比,DeepSeekMoE 架构表现出巨大优势,使我们能够以经济的成本训练出强大的模型。由于我们在训练过程中采用专家并行,我们还设计了补充机制来控制通信开销并确保负载平衡。通过结合这两种技术,DeepSeek-V2 同时具有强大的性能(图 1(a))、经济的训练成本和高效的推理吞吐量(图 1(b))。
我们构建了一个由 8.1T token组成的高质量、多源预训练语料库。与 DeepSeek 67B(我们之前的版本)中使用的语料库相比,这个语料库的数据量更大,尤其是中文数据,数据质量更高。我们首先在完整的预训练语料库上对 DeepSeek-V2 进行预训练。然后,我们收集了 1.5M 个对话会话,涵盖数学、代码、写作、推理、安全等各个领域,对 DeepSeek-V2 Chat(SFT)进行有监督微调(SFT)。最后,我们遵循 DeepSeekMath 使用 Group Relative Policy Optimization (GRPO) 使模型进一步与人类偏好保持一致并生成 DeepSeek-V2 Chat(RL)。
我们对英文和中文的大量基准测试集进行了 DeepSeek-V2 评估,并将其与具有代表性的开源模型进行了比较。评估结果表明,即便在只有 21B 激活参数的情况下,DeepSeek-V2 仍然取得了开源模型中顶级的性能,成为最强的开源 MoE 语言模型。图 1(a) 突出显示了在 MMLU 上,DeepSeek-V2 仅使用少量激活参数就取得了顶级性能。此外,如图 1(b) 所示,与 DeepSeek 的 67B 相比,DeepSeek-V2 节省了 42.5% 的训练成本,减少了 93.3% 的 KV 缓存,并将最大生成吞吐量提高了 5.76 倍。我们还在开源基准测试集上评估了 DeepSeek-V2 Chat (SFT) 和 DeepSeek-V2 Chat (RL)。值得一提的是,DeepSeek-V2 Chat (RL) 在 AlpacaEval 2.0 上获得了 38.9 的长度控制胜率,在 MT-Bench 上获得了 8.97 的总分,在 AlignBench 上获得了 7.91 的总分。英文开源对话评测表明,DeepSeek-V2 Chat (RL) 在开源聊天模型中拥有顶级性能。此外,AlignBench 的评测表明,在中文中,DeepSeek-V2 Chat (RL) 的表现优于所有开源模型,甚至超越了大多数闭源模型。
为了方便大家对 MLA 和 DeepSeekMoE 进行进一步的研究和开发,我们还向开源社区发布了搭载 MLA 和 DeepSeekMoE 的较小模型 DeepSeek-V2-Lite,共计 15.7B 个参数,其中每个 token 激活 2.4B 个参数。DeepSeek-V2-Lite 的详细描述可参见附录 B。
在本文的其余部分,我们首先详细描述了 DeepSeek-V2 的模型架构(第 2 节)。随后,我们介绍了我们的预训练工作,包括训练数据构建、超参数设置、基础设置、长上下文扩展以及模型性能和效率的评估(第 3 节)。接下来,我们展示了我们在协同方面的努力,包括监督微调 (SFT)、强化学习 (RL)、评估结果和其他讨论(第 4 节)。最后,我们总结结论,讨论 DeepSeek-V2 当前的局限性,并概述我们未来的工作(第 5 节)。
2.Architecture
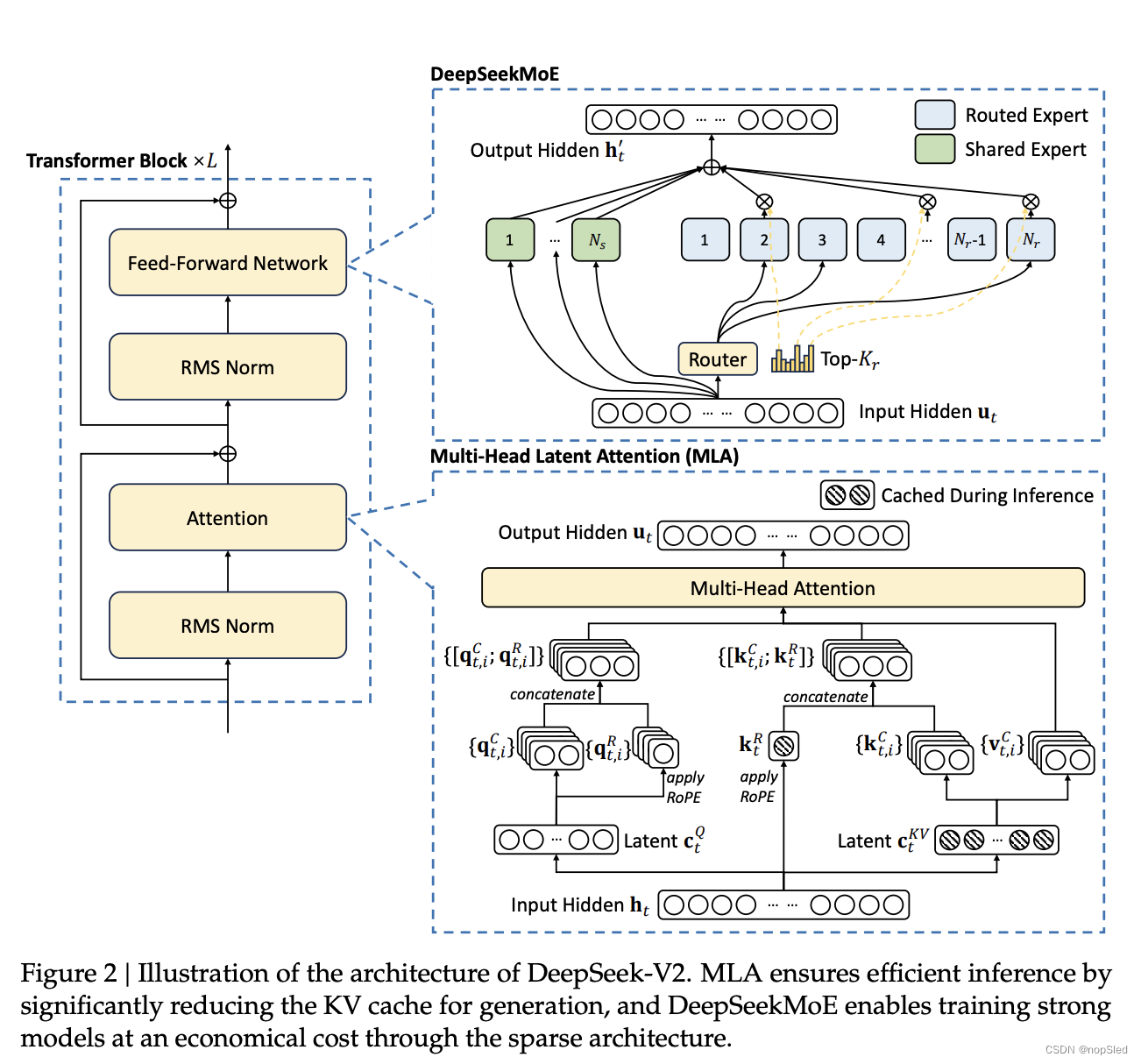
总体来说,DeepSeek-V2 还是 Transformer 架构,每个 Transformer 模块由一个注意力模块和一个前馈网络(FFN)组成。不过,无论是注意力模块还是 FFN,我们都设计并采用了创新的架构。对于注意力模版,我们设计了 MLA,利用低秩key-value联合压缩以消除推理时key-value缓存的瓶颈,从而支持高效推理。对于 FFN,我们采用了 DeepSeekMoE 架构,这是一种高性能的 MoE 架构,能够以经济的成本训练出强大的模型。DeepSeek-V2 的架构如图 2 所示,本节我们将介绍 MLA 和 DeepSeekMoE 的细节。对于其他微小的细节(例如,FFN 中的层归一化和激活函数),除非特别说明,DeepSeek-V2 都遵循 DeepSeek 67B 的设置。
2.1 Multi-Head Latent Attention: Boosting Inference Efficiency
传统的 Transformer 模型通常采用多头注意力机制(MHA),但在生成过程中,其较大的key-value(KV)缓存会成为限制推理效率的瓶颈。为了减少 KV 缓存,提出了multi-query注意力机制(MQA)和group-query注意力机制(GQA)。它们需要的 KV 缓存量级较小,但性能却不如 MHA(我们在附录 D.1 中给出了 MHA、GQA 和 MQA 的比较)。
对于 DeepSeek-V2,我们设计了一种创新的注意力机制,称为 Multi-head Latent Attention (MLA)。MLA 配备了低秩key-value联合压缩,性能优于 MHA,但所需的 KV 缓存量明显较少。我们在下面介绍了它的架构,并在附录 D.2 中提供了 MLA 和 MHA 之间的比较。
2.1.1 Preliminaries: Standard Multi-Head Attention
我们首先介绍标准的 MHA 机制作为背景。令
d
d
d 为 embedding 维度,
n
h
n_h
nh 为注意力头的数量,
d
h
d_h
dh 为每个注意力头的维度,
h
t
∈
R
d
\textbf h_t ∈ \mathbb R^d
ht∈Rd 为注意力层上第
t
t
t 个 token 的注意力输入。标准 MHA 首先通过三个矩阵
W
Q
,
W
K
,
W
V
∈
R
d
h
n
h
×
d
W^Q, W^K, W^V ∈ \mathbb R^{d_hn_h×d}
WQ,WK,WV∈Rdhnh×d 分别产生
q
t
,
k
t
,
v
t
∈
R
d
h
n
h
\textbf q_t, \textbf k_t, \textbf v_t ∈ \mathbb R^{d_hn_h}
qt,kt,vt∈Rdhnh:
q
t
=
W
Q
h
t
,
(1)
\textbf q_t=W^Q\textbf h_t,\tag{1}
qt=WQht,(1)
k
t
=
W
K
h
t
,
(2)
\textbf k_t=W^K\textbf h_t,\tag{2}
kt=WKht,(2)
v
t
=
W
V
h
t
,
(3)
\textbf v_t=W^V\textbf h_t,\tag{3}
vt=WVht,(3)
然后,
q
t
,
k
t
,
v
t
\textbf q_t, \textbf k_t, \textbf v_t
qt,kt,vt 将被切成
n
h
n_h
nh 个头,以进行多头注意力计算:
[
q
t
,
1
;
q
t
,
2
;
.
.
.
;
q
t
,
n
h
]
=
q
t
,
(4)
[\textbf q_{t,1};\textbf q_{t,2};...;\textbf q_{t,n_h}]=\textbf q_t,\tag{4}
[qt,1;qt,2;...;qt,nh]=qt,(4)
[
k
t
,
1
;
k
t
,
2
;
.
.
.
;
k
t
,
n
h
]
=
k
t
,
(5)
[\textbf k_{t,1};\textbf k_{t,2};...;\textbf k_{t,n_h}]=\textbf k_t,\tag{5}
[kt,1;kt,2;...;kt,nh]=kt,(5)
[
v
t
,
1
;
v
t
,
2
;
.
.
.
;
v
t
,
n
h
]
=
v
t
,
(6)
[\textbf v_{t,1};\textbf v_{t,2};...;\textbf v_{t,n_h}]=\textbf v_t,\tag{6}
[vt,1;vt,2;...;vt,nh]=vt,(6)
o
t
,
i
=
∑
j
=
1
t
S
o
f
t
m
a
x
j
(
q
t
,
i
T
k
j
,
i
d
h
)
v
j
,
i
,
(7)
\textbf o_{t,i}=\sum^t_{j=1}Softmax_j(\frac{\textbf q^T_{t,i}\textbf k_{j,i}}{\sqrt{d_h}})\textbf v_{j,i},\tag{7}
ot,i=j=1∑tSoftmaxj(dh
qt,iTkj,i)vj,i,(7)
u
t
=
W
O
[
o
t
,
1
;
o
t
,
2
;
.
.
.
;
o
o
t
,
n
h
]
,
(8)
\textbf u_t=W^O[\textbf o_{t,1};\textbf o_{t,2};...;\textbf o_{o_{t,n_h}}],\tag{8}
ut=WO[ot,1;ot,2;...;oot,nh],(8)
其中
q
t
,
i
,
k
t
,
i
,
v
t
,
i
∈
R
d
h
\textbf q_{t,i}, \textbf k_{t,i},\textbf v_{t,i} ∈ \mathbb R^{d_h}
qt,i,kt,i,vt,i∈Rdh 分别表示第
i
i
i 个注意力头的 query、key 和 value;
W
O
∈
R
d
×
d
h
n
h
W^O ∈ \mathbb R^{d\times d_hn_h}
WO∈Rd×dhnh 表示输出投影矩阵。在推理过程中,需要缓存所有 key 和 value 以加速推理,因此 MHA 需要为每个 token 缓存
2
n
h
d
h
l
2n_hd_hl
2nhdhl 个元素。在模型部署中,这种繁重的 KV 缓存是限制最大batch大小和序列长度的一大瓶颈。
2.1.2 Low-Rank Key-Value Joint Compression
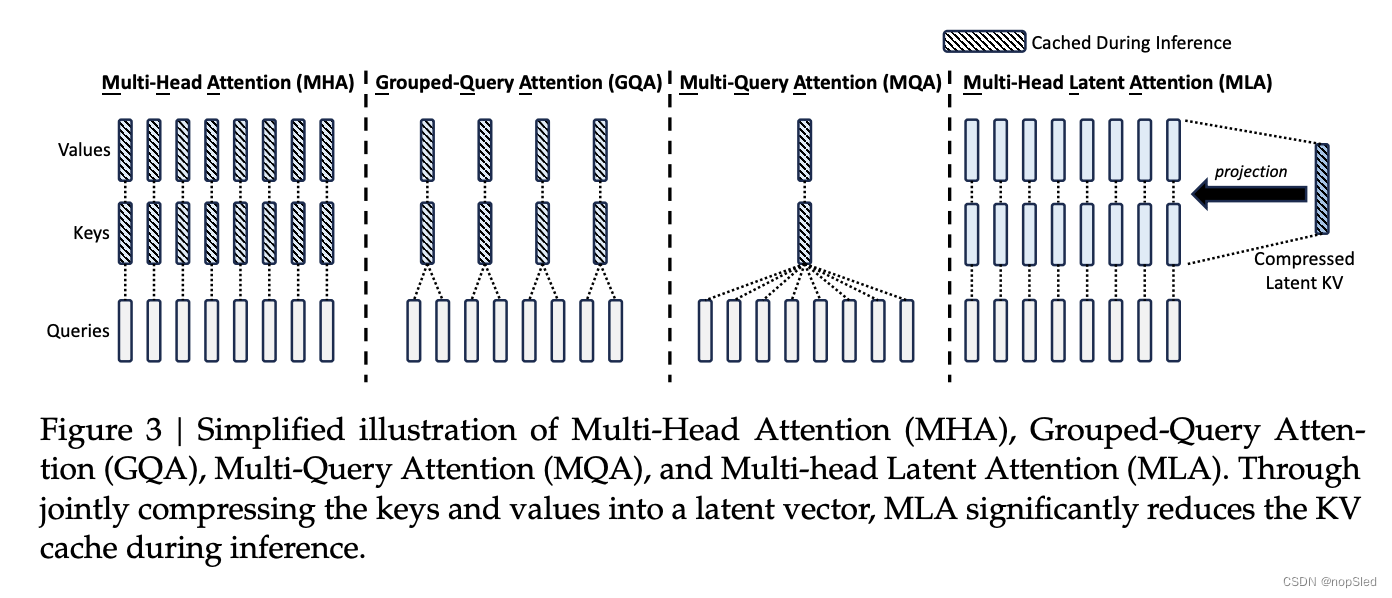
MLA的核心是对key和value进行低秩联合压缩,以减少KV缓存:
c
t
K
V
=
W
D
K
V
h
t
,
(9)
\textbf c^{KV}_t=W^{DKV}\textbf h_t,\tag{9}
ctKV=WDKVht,(9)
k
t
C
=
W
U
K
c
t
K
V
,
(10)
\textbf k^C_t=W^{UK}\textbf c^{KV}_t,\tag{10}
ktC=WUKctKV,(10)
v
t
C
=
W
U
V
c
t
K
V
,
(11)
\textbf v^C_t=W^{UV}\textbf c^{KV}_t,\tag{11}
vtC=WUVctKV,(11)
其中
c
t
K
V
∈
R
d
c
\textbf c^{KV}_t ∈\mathbb R^{d_c}
ctKV∈Rdc 是key和value的压缩潜在向量;
d
c
(
≪
d
h
n
h
)
d_c(≪d_hn_h)
dc(≪dhnh) 表示 KV 压缩维度;
W
D
K
V
∈
R
d
c
×
d
W^{DKV}∈\mathbb R^{d_c\times d}
WDKV∈Rdc×d 是下投影矩阵;
W
U
K
,
W
U
V
∈
R
d
h
n
h
×
d
c
W^{UK},W^{UV} ∈ \mathbb R^{d_hn_h×d_c}
WUK,WUV∈Rdhnh×dc 分别是key和value的上投影矩阵。在推理过程中,MLA 只需要缓存
c
t
K
V
c^{KV}_t
ctKV,因此其 KV 缓存只有
d
c
l
d_cl
dcl 个元素,其中
l
l
l 表示层数。此外,在推理过程中,由于
W
U
V
W^{UV}
WUV可以被吸收到
W
O
W^O
WO中,我们甚至不需要计算出用于注意的key和value。图3直观地说明了MLA中的KV联合压缩如何减少KV缓存。
下面是对query进行低秩压缩,即使它不能减少KV缓存:
c
t
Q
=
W
D
Q
h
t
,
(12)
\textbf c^Q_t=W^{DQ}\textbf h_t,\tag{12}
ctQ=WDQht,(12)
q
t
C
=
W
U
Q
c
t
Q
,
(13)
\textbf q^C_t=W^{UQ}\textbf c^Q_t,\tag{13}
qtC=WUQctQ,(13)
其中
c
t
Q
∈
R
d
c
′
c^Q_t ∈ \mathbb R^{d'_c}
ctQ∈Rdc′ 是query的压缩潜在向量;
d
c
′
(
≪
d
h
n
h
)
d'_c (≪ d_hn_h)
dc′(≪dhnh) 表示query压缩维度;
W
D
Q
∈
R
d
c
′
×
d
,
W
U
Q
∈
R
d
h
n
h
×
d
c
′
W^{DQ} ∈ \mathbb R^{d'_c\times d},W^{UQ} ∈ \mathbb R^{d_hn_h×d'_c}
WDQ∈Rdc′×d,WUQ∈Rdhnh×dc′ 分别是query的下投影和上投影矩阵。
2.1.3 Decoupled Rotary Position Embedding

继 DeepSeek 67B 之后,我们打算在 DeepSeek-V2 中使用旋转位置嵌入 (RoPE)。然而,RoPE 与低秩 KV 压缩不兼容。具体来说,RoPE 对key和value都是位置敏感的。如果我们对key
k
t
C
\textbf k^C_t
ktC 应用 RoPE,则等式 10 中的
W
U
K
W^{UK}
WUK 将与位置敏感的 RoPE 矩阵耦合。这样,
W
U
K
W^{UK}
WUK 在推理过程中就无法再被吸收到
W
Q
W^Q
WQ 中,因为与当前生成的 token 相关的 RoPE 矩阵将位于
W
Q
W^Q
WQ 和
W
U
K
W^{UK}
WUK 之间,而矩阵乘法不遵循交换律。因此,我们必须在推理过程中重新计算所有前缀 token 的key,这将严重影响推理效率。
作为解决方案,我们提出了解耦 RoPE 策略,该策略使用额外的多头query
q
t
,
i
R
∈
R
d
h
R
\textbf q^R_{t,i}∈\mathbb R^{d^R_h}
qt,iR∈RdhR 和共享key
k
t
R
∈
R
d
h
R
k^R_t ∈ \mathbb R^{d^R_h}
ktR∈RdhR 来引入 RoPE,其中
d
h
R
d^R_h
dhR 表示解耦query和key的每个头维度。配备解耦 RoPE 策略后,MLA 可执行以下计算:
[
q
t
,
1
R
;
q
t
,
2
R
;
,
.
.
.
;
q
t
,
n
h
R
]
=
q
t
R
=
R
o
P
E
(
W
Q
R
c
t
Q
)
,
(14)
[\textbf q^R_{t,1};\textbf q^R_{t,2};,...;\textbf q^R_{t,n_h}]=\textbf q^R_t=RoPE(W^{QR}\textbf c^Q_t),\tag{14}
[qt,1R;qt,2R;,...;qt,nhR]=qtR=RoPE(WQRctQ),(14)
k
t
R
=
R
o
P
E
(
W
K
R
h
t
)
,
(15)
\textbf k^R_t=RoPE(W^{KR}\textbf h_t),\tag{15}
ktR=RoPE(WKRht),(15)
q
t
,
i
=
[
q
t
,
i
C
;
q
t
,
i
R
]
,
(16)
\textbf q_{t,i}=[\textbf q^C_{t,i};\textbf q^R_{t,i}],\tag{16}
qt,i=[qt,iC;qt,iR],(16)
k
t
,
i
=
[
k
t
,
i
C
;
k
t
R
]
,
(17)
\textbf k_{t,i}=[\textbf k^C_{t,i};\textbf k^R_t],\tag{17}
kt,i=[kt,iC;ktR],(17)
o
t
,
i
=
∑
j
=
1
t
S
o
f
t
m
a
x
j
(
q
t
,
i
T
k
j
,
i
d
h
+
d
h
R
)
v
j
,
i
C
,
(18)
\textbf o_{t,i}=\sum^t_{j=1}Softmax_j(\frac{\textbf q^T_{t,i}\textbf k_{j,i}}{\sqrt{d_h+d^R_h}})\textbf v^C_{j,i},\tag{18}
ot,i=j=1∑tSoftmaxj(dh+dhR
qt,iTkj,i)vj,iC,(18)
u
t
=
W
O
[
o
t
,
1
;
o
t
,
2
;
.
.
.
;
o
t
,
n
h
]
,
(19)
\textbf u_t=W^O[\textbf o_{t,1};\textbf o_{t,2};...;\textbf o_{t,n_h}],\tag{19}
ut=WO[ot,1;ot,2;...;ot,nh],(19)
其中
W
Q
R
∈
R
d
h
R
n
h
×
d
c
′
W^{QR} ∈ \mathbb R^{d^R_hn_h×d'_c}
WQR∈RdhRnh×dc′ 和
W
K
R
∈
R
d
h
R
×
d
W^{KR} ∈ \mathbb R^{d^R_h×d}
WKR∈RdhR×d 分别是用于生成解耦query和key的矩阵;RoPE(·) 表示应用 RoPE 矩阵的运算;[·; ·] 表示向量拼接运算。在推理过程中,解耦的key也应该被缓存。因此,DeepSeek-V2 需要包含
(
d
c
+
d
h
R
)
l
(d_c + d^R_h)l
(dc+dhR)l 元素的总 KV 缓存。
为了展示MLA的完整计算过程,我们还在附录C中整理并提供了其完整公式。
2.1.4 Comparison of Key-Value Cache
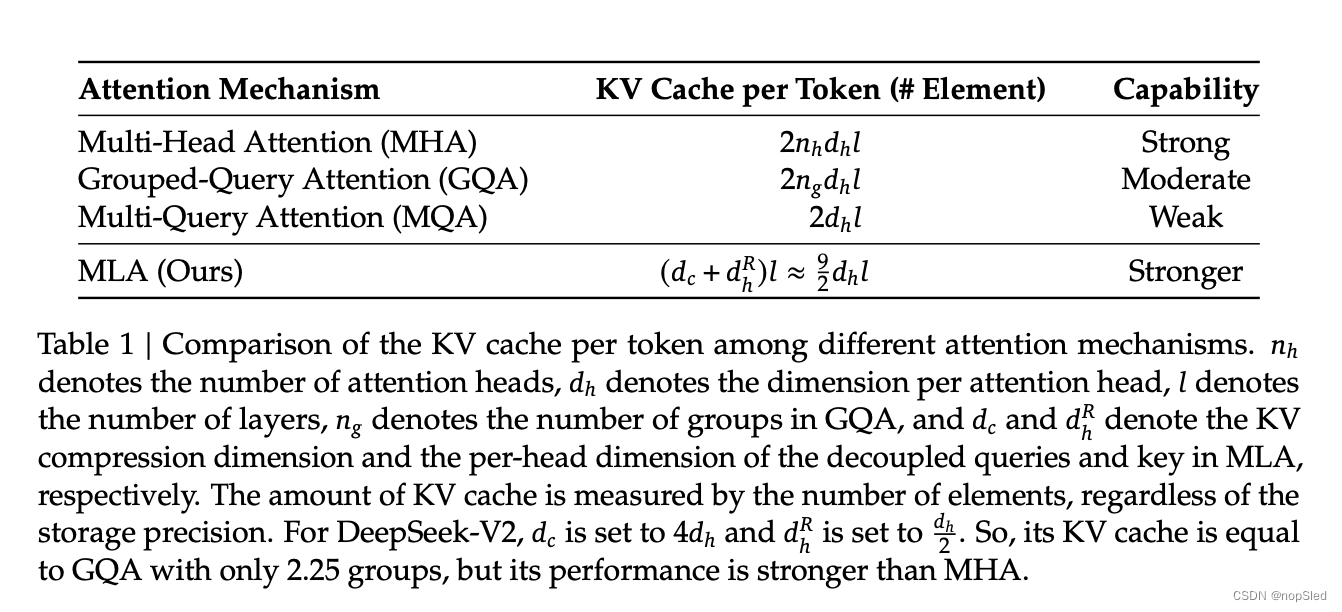
我们在表 1 中展示了不同注意力机制中每个 token 的 KV 缓存的比较。MLA 只需要少量的 KV 缓存,相当于只有 2.25 个组的 GQA,但可以获得比 MHA 更强的性能。
2.2 DeepSeekMoE: Training Strong Models at Economical Costs
2.2.1 Basic Architecture
对于 FFN,我们采用 DeepSeekMoE 架构。DeepSeekMoE 有两个关键思想:将专家细分为更细的粒度,以提高专家的专业化程度和更准确的知识获取;隔离一些共享专家,以减轻路由专家之间的知识冗余。在激活和总专家参数数量相同的情况下,DeepSeekMoE 的表现可以大大优于 GShard 等传统 MoE 架构。
令
u
t
\textbf u_t
ut 为第
t
t
t 个 token 的 FFN 输入,我们计算 FFN 输出
h
t
′
h'_t
ht′ 如下:
h
t
′
=
u
t
+
∑
i
=
1
N
s
F
F
N
i
(
s
)
(
u
t
)
+
∑
i
=
1
N
r
g
i
,
t
F
F
N
i
(
r
)
(
u
t
)
,
(20)
\textbf h'_t=\textbf u_t+\sum^{N_s}_{i=1}FFN^{(s)}_i(\textbf u_t)+\sum^{N_r}_{i=1}g_{i,t}FFN^{(r)}_i(\textbf u_t),\tag{20}
ht′=ut+i=1∑NsFFNi(s)(ut)+i=1∑Nrgi,tFFNi(r)(ut),(20)
g
i
,
t
=
{
s
i
,
t
,
s
i
,
t
∈
T
o
p
K
(
{
s
j
,
t
∣
1
⩽
j
⩽
N
r
}
,
K
r
)
,
0
,
o
t
h
e
r
w
i
s
e
,
(21)
g_{i,t}={si,t,si,t∈TopK({sj,t|1⩽j⩽Nr},Kr),0,otherwise,\tag{21}
gi,t={si,t,0,si,t∈TopK({sj,t∣1⩽j⩽Nr},Kr),otherwise,(21)
s
i
,
t
=
S
o
f
t
m
a
x
i
(
u
t
T
e
i
)
,
(22)
s_{i,t}=Softmax_i(\textbf u^T_t\textbf e_i),\tag{22}
si,t=Softmaxi(utTei),(22)
其中
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

