- 13D-DIC数字图像相关法测量流程介绍-数字图像采集_视觉软件中触发周期是什么意思
- 2【windows】亲测-win11系统跳过联网和微软账户登录,实现本地账户登录_win11跳过联网激活
- 3【数据结构和算法初阶(C语言)】时间复杂度(衡量算法快慢的高端玩家,搭配例题详细剖析)_衡量一个算法好坏一般以最坏的时间复杂度为标准
- 4如何在群晖NAS搭建bitwarden密码管理软件并实现无公网IP远程访问_群晖怎么安装bitwarden
- 5基于Hadoop的区块链海量数据存储的设计与实现_区块链 hdfs
- 6iOS(一):Swift纯代码模式iOS开发入门教程_swift 开发ios入门教程
- 7学懂C语言系列(三):C语言基本语法
- 8kafka架构深入
- 9Langchain-chatchat: Langchain核心组件及应用_langchain chatchat
- 10【爬虫】1.4 POST 方法向网站发送数据_网页爬虫 post数据
通用大模型研究重点之三:model App_大模型 profile是什么意思
赞
踩
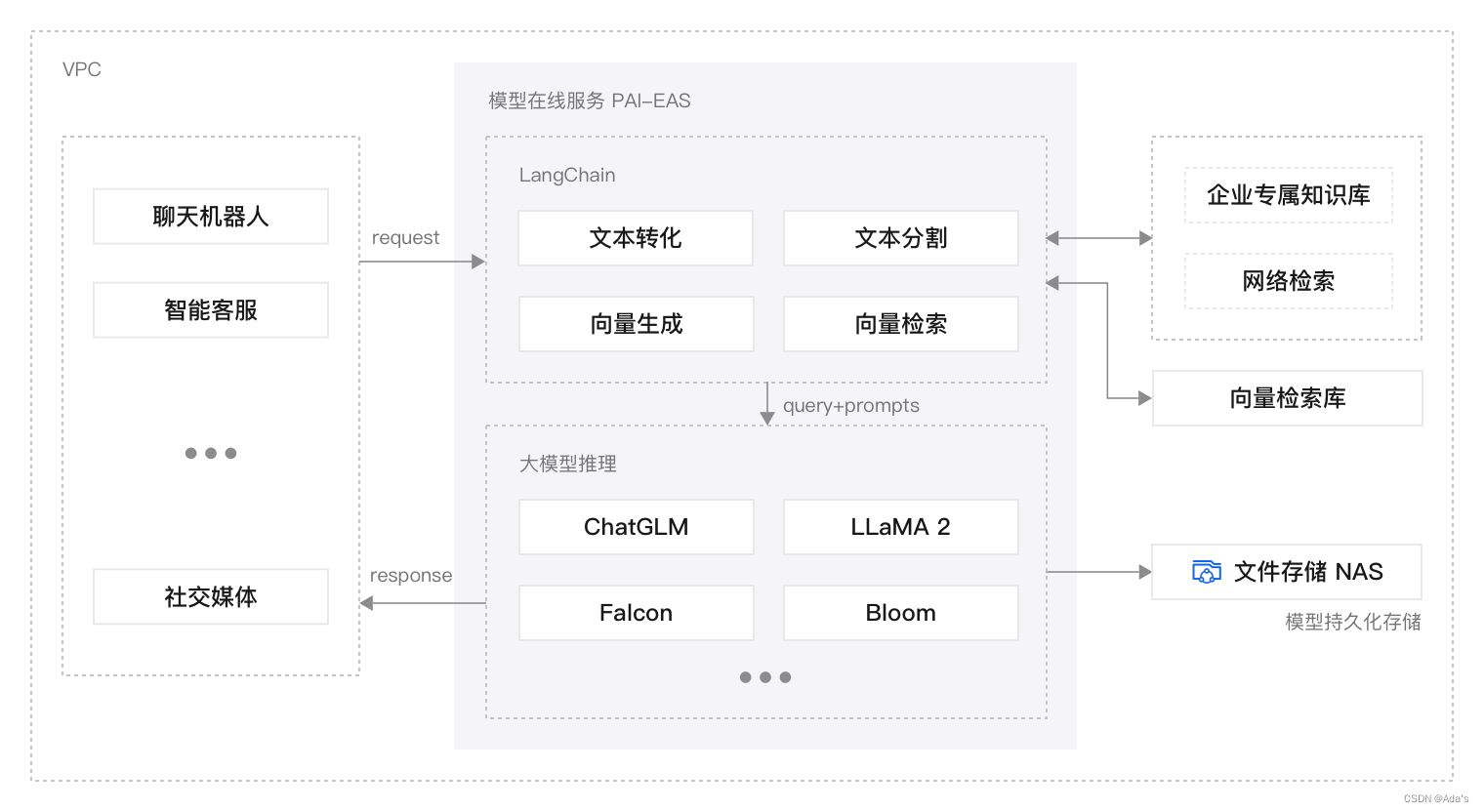
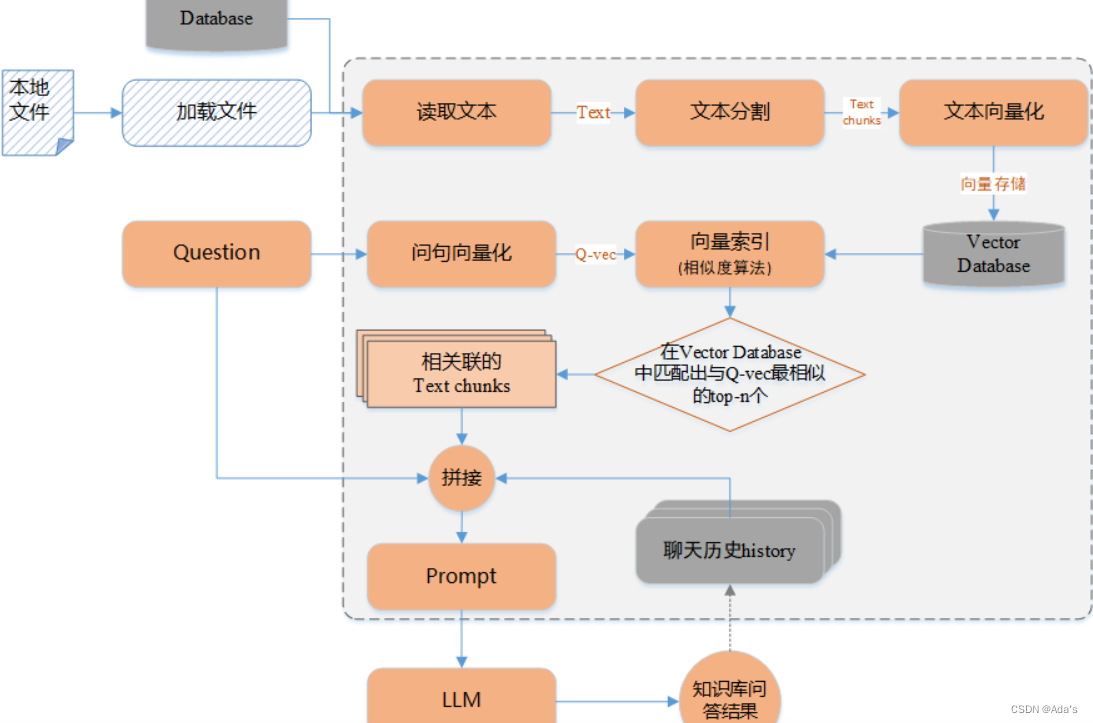
RAG;Agent
RAG方案架构图,工具为LangChain WebUI,milvus,gradio,streamlit,FastAPI
图片来源网络
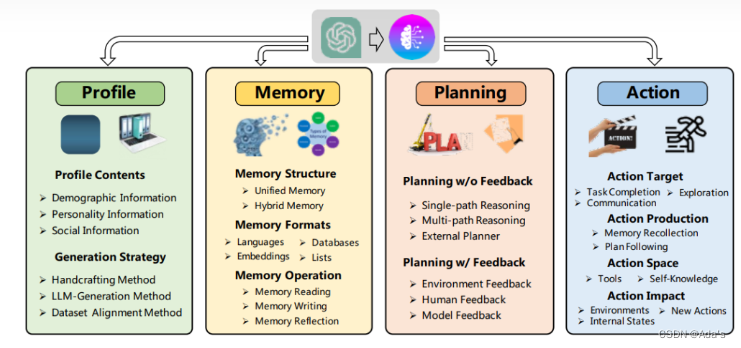
Agent 的一般结构如下图所示:Agent=LLM+Planning+Memony+Tools
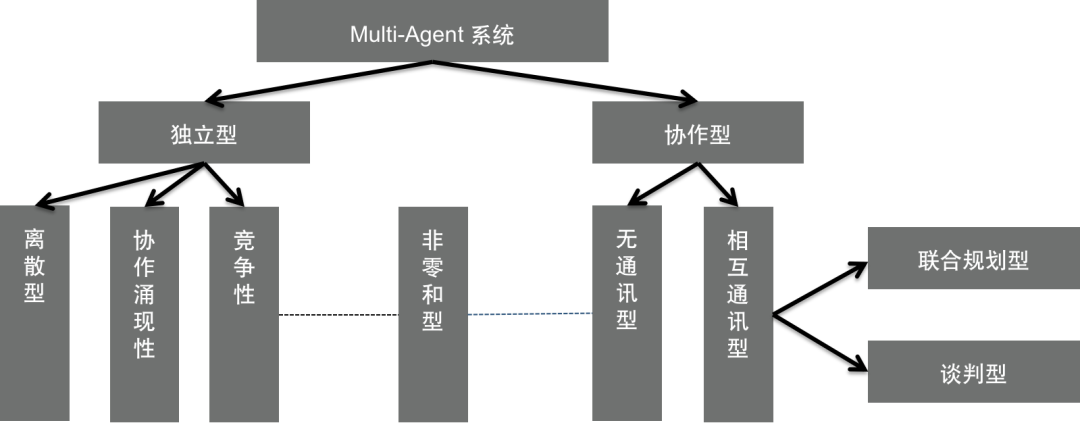
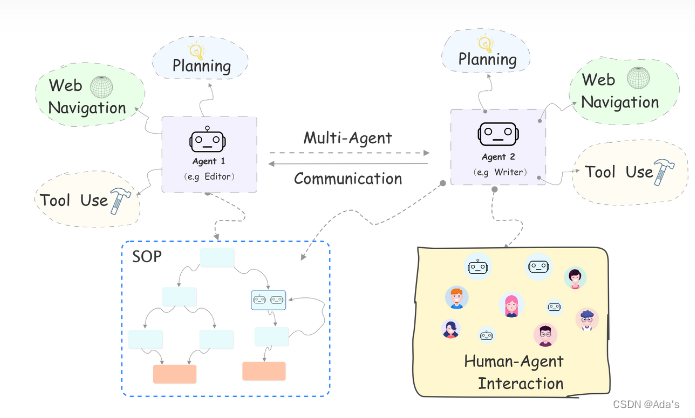
Agent 的主要特性有:
● 自主性(Autonomy) :运行无需人类或其它 Agent 的直接干预,对其自身行为及内部状态进行某种控制。
● 社会性(Social Ability) 能通过某种 通信与其它 Agent(或人类)进行交互。交互主要有 三种类型:协作(Cooperation)、协调(Coordination)和协商 (Negotiation)。
● 反应性(Reactivity):能感知环境(可以是物理世界、一个经图形用户接口连接的用户、一系列其 它Agent、Internet 或所有这些的组合),并能对环境的变化及时作出反应。
● 主动性(Pro-activeness):不但能对环境作出反应,能够积极主动地做出使其目标得以实现的行为。
目前行业里通常通用的一种架构是由Profile、Memory、Planning、Action所构建的四级架构。
1.Profile模块
Profile模块解决的问题是告诉Agent他的角色,或者换一种说法,是告诉Agent需要解决的问题的背景信息。Profile有三种实现模式。第一种是人工设定模式,比如告诉Agent你是个外向的厨师,你需要解决点餐环节客人的问题。第二种是LLM延申模式,先把一些背景告诉LLM,让LLM给出一些候选集,比方说告诉LLM生成几种人物,解决点餐的问题,然后基于LLM的输出选择合适的Profile方向。第三种是基于database,比方说已经在数据库中存储了某些厨师的数据,包含他的各种身体特征,然后完成设定。
2.Memory模块
Memory模块是Agent解决方案中的重要一环。Memory主要解决的是行业知识的传递问题,可以让Agent拥有长期和短期记忆,让他表现得更智能。
Shot-Memory一般用来传递上下文的的对话信息,常常通过Prompt作为传递介质。而Long-Memory更多的是领域知识,需要有独立的存储模块。Long-Memory的存储结构可能是自然语言、Embedding、结构化的表等。比如做一个餐厅服务点餐Agent,那么完全可以把菜单内容以自然语言的形式存储为Long-Memory,每次点餐要求Agent从约定内容里面选择。随着LLM的发展,目前向量数据库也成为了投资的重点领域,因为以Embedding存储,可以更有利于在大规模数据的前提下压缩信息和高效检索。
3.Planning模块
通过prompt要求LLM Think Step by Step,让LLM有将困难任务逐步分解成更小更简单的步骤,赋予了LLM Planning能力;
Planning模块可以是两种结构,一种是Single-Path,这里引入CoT的概念(Chain of thought),可以要求LLM基于任务一步步推理,形成一个解决方案。每一步推理后产出的内容可以再次输入给LLM去判断下一步如何走。另一种是Muti-Path,这个方案更符合人类的思维方式,因为要解决问题,很难完全设定好端到端的流程,需要给出几种候选的模式,另外需要考虑环境反馈,可以每走一步再次推理和选择最优模式,这里可以参考最近非常火的ReAct的模式,另外LLM也可以代替人类去做多种方案的选择,我们可以把需要考虑的边界给到LLM,由LLM去思考每一步如何选择。按照 think(思考)->act(行动)->observation(观察)->think→act→observation…的模式来解决问题。
4.Action模块
这一步是执行模块,需要按照Planning的设计,完成目标。在这一步需要建设的能力是与外部的服务关联,比如我们的Agent是解决帮用户买飞机票的问题,那么在执行阶段就需要与飞机票务系统的订票接口关联,也需要与用户的信用卡付款接口关联。
在大脑做出分析、决策后,代理还需要做出行动以适应或改变环境:
Embedding背景
Embedding 起源于 Word Embedding,经过多年的发展,已取得长足进步。从横向发展来看,由原来单纯的 Word Embedding,发展成现在的Item Embedding、Entity Embedding、Graph Embedding、Position Embedding、Segment Embedding等;从纵向发展来看,由原来静态的Word Embedding发展成动态的预训练模型,如ELMo、BERT、GPT、GPT-2、GPT-3、ALBERT、XLNet等,这些预训练模型可以通过微调服务下游任务。Embedding 不再固定不变,从而使这些预训练模型可以学习到新的语义环境下的语义,高效完成下游的各种任务,如分类、问答、摘要生成、阅读理解等,其中有很多任务的完成效率已超过人工完成的平均水平。
embedding 技术的发展可以追溯到 20 世纪五六十年代的语言学研究,其中最著名的是 Harris 在 1954 年提出的分布式语义理论(distributional semantic theory)。这个理论认为,单词的语义可以通过它们在上下文中的分布来表示,也就是说,单词的含义可以从其周围的词语中推断出来。
从2010年以来,随着深度学习技术的发展,embedding 技术得到了广泛的应用和研究。在这个时期,出现了一些重要的嵌入算法,例如Word2Vec、GloVe和FastText等
- 1
- 2
- 3
- 4
- 5
embedding 技术得到了进一步的改进和发展。例如,BERT、ELMo 和 GPT 等大型语言模型可以生成上下文相关的 embedding 表示,可以更好地捕捉单词的语义和上下文信息。
Embedding作用
1:降低维度
2:扑住语义
3:增强适应
4:提高泛化
5:可解释性
Word Embedding:词嵌入通常被用来生成词的向量表示,这个过程通常是静态的,即一旦训练完成,每个词的向量表示就确定了。词嵌入的主要目标是捕获单词或短语的语义和语法信息,并将这些信息以向量形式表示出来。词嵌入的一个重要特性是,语义上相近的词在嵌入空间中的距离也比较近。然而,词嵌入并不能理解上下文信息,即相同的词在不同的上下文中可能有不同的含义,但词嵌入无法区分这些含义。
Language Model:语言模型则是预测词序列的概率模型,这个过程通常是动态的,会根据输入的上下文进行变化。语言模型的主要目标是理解和生成文本。这包括对上下文的理解,词的预测,句子的生成等等。语言模型会用到词嵌入,但同时也会对上下文进行建模,这样可以处理词在不同上下文中的不同含义。在某种程度上,你可以将词嵌入看作是语言模型的一部分或者输入,语言模型使用词嵌入捕捉的信息,来进行更深层次的语义理解和文本生成。当然,现在有一些更先进的模型,比如 BERT,GPT 等,它们生成的是上下文相关的词嵌入,即词的嵌入会根据上下文变化,这样一定程度上弥补了传统词嵌入模型的不足。
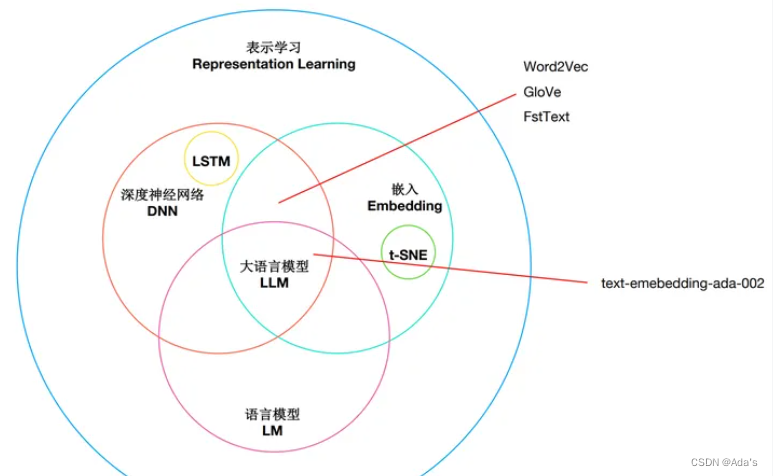
资料来源网络:
技术的未来发展可能会沿着以下几个方向:
模型的细粒度和多模态性:字符级(Char-level)的嵌入、语义级的嵌入,以及结合图像、声音等多模态信息的嵌入。
更好的理解和利用上下文信息:例如,动态的、可变长度的上下文,以及更复杂的上下文结构。
模型的可解释性和可控制性:这包括模型的内部结构和嵌入空间的理解,以及对模型生成结果的更精细控制。
更大规模的模型和数据:例如,GPT-4、GPT-5等更大规模的预训练模型,以及利用全球范围的互联网文本数据。
Embedding应用【RAG、MoE、Agent、debugger】
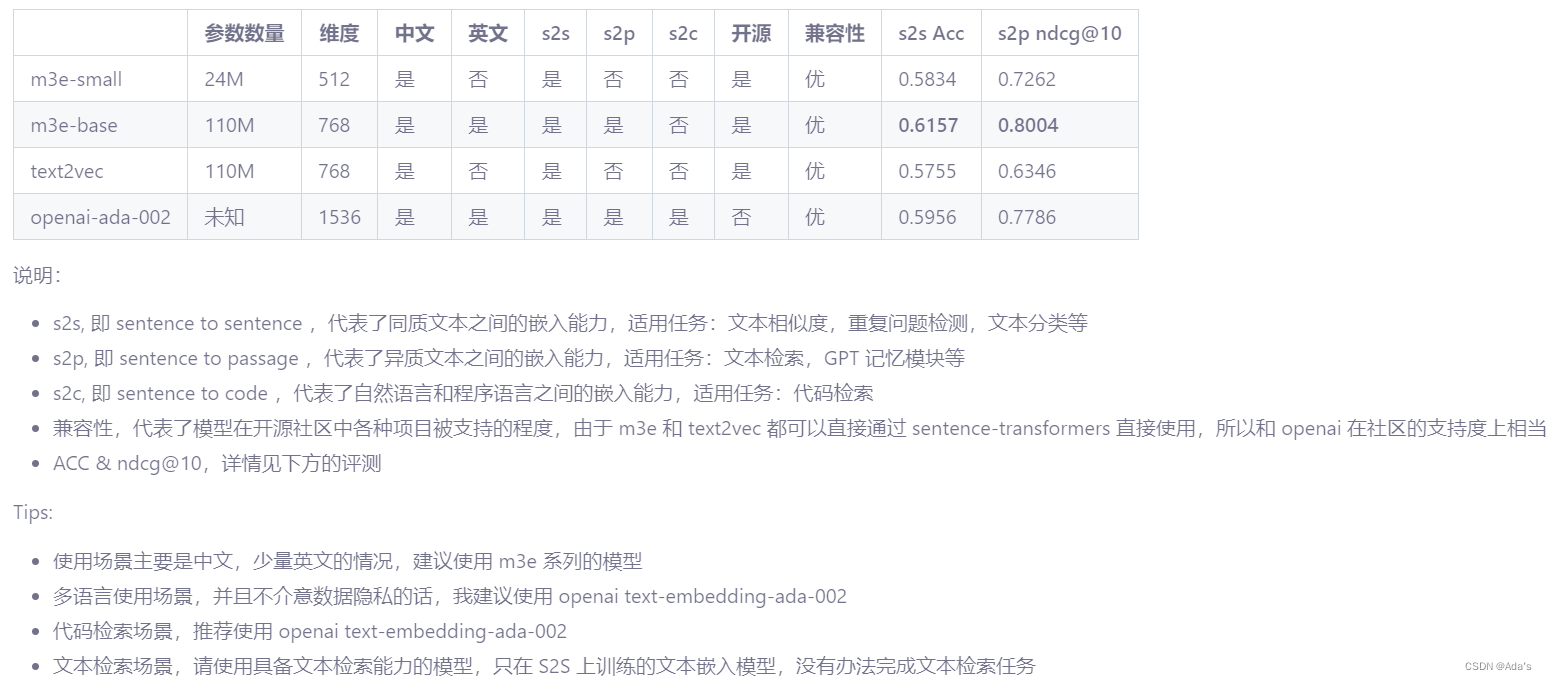

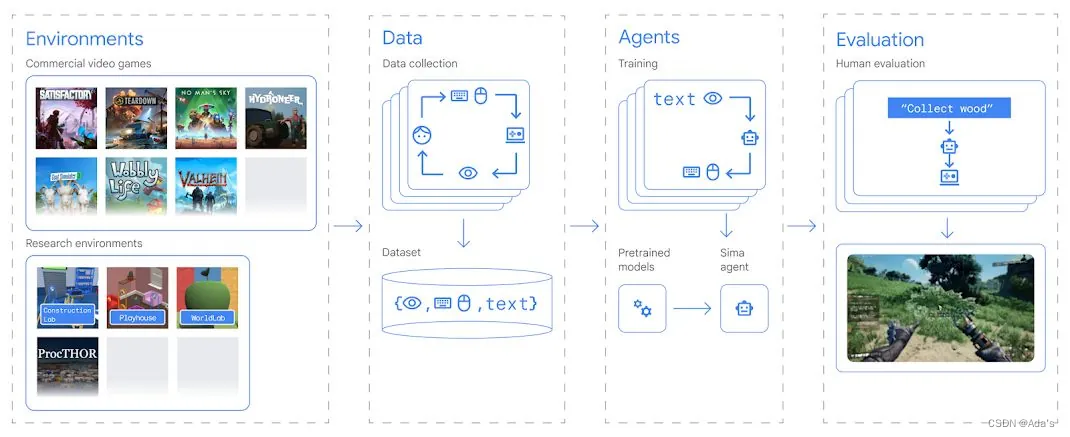
《SIMA generalist AI agent for 3D virtual environments - Google DeepMind》
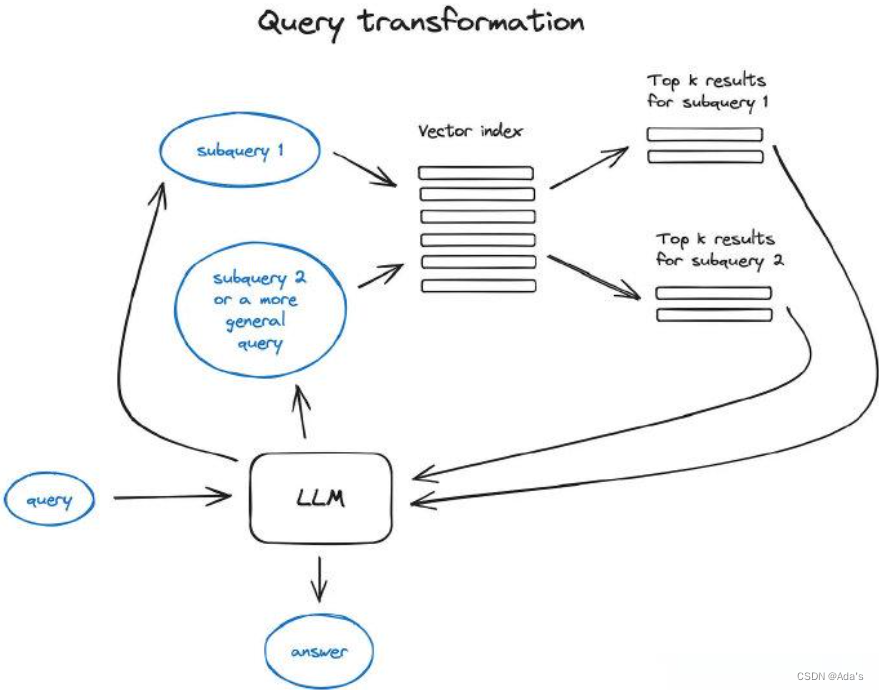
《Advanced RAG Techniques: an Illustrated Overview | by IVAN ILIN | Dec, 2023 | Towards AI》
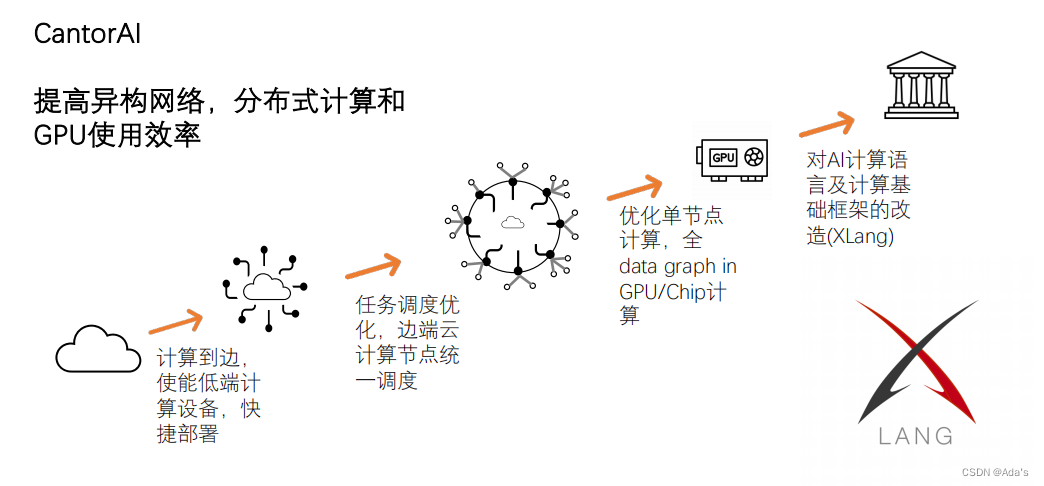
CantorAI 通过使能低端计算设备和大规模的快捷部署,使计算能够真正有效地下沉到边,而不是过度依靠云的计算,整体提高计算系统的计算效率。这一切都建立在 XLang™ 语言的应用特性:高效的机器码执行效率、小巧的内存占用以及对设备资源的极低消耗。
-
我们的任务调度机制将系统中所有具备计算能力的节点,无论它们处于边缘端、终端还是云端环境,均视为一体化的计算资源,根据任务的要求统一优化调度。这一切也建立在 XLang™ 的分布式计算能力之上。
-
针对单节点上面的 GPU 计算。现在数据在 CPU 和 GPU 之间吞吐时,GPU 有大量的空闲。XLang™ 优化 DataGraph 管理的底层算法,减少不必要的吞吐,有望将 GPU 的使用率提高到 80% 甚至更高,接近 100%。
当前业界标杆的分布式计算平台当属加州伯克利的 Ray 平台。虽然 CantorAI 的很多机制是从 Ray 学习过来的,但 CantorAI 青出于蓝而胜于蓝,甚至开始支持一些不同的场景。
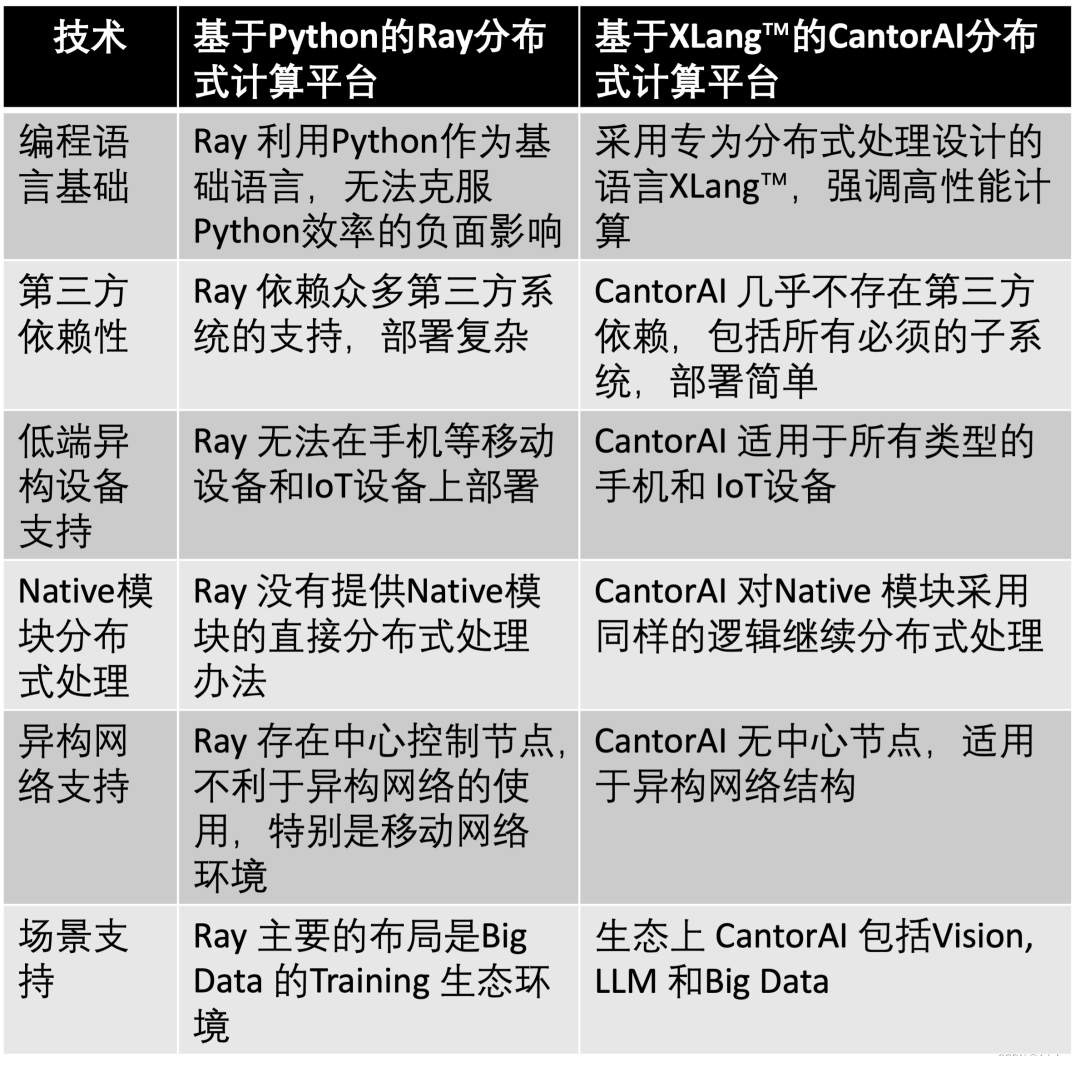
两大分布式计算平台异同
CantorAI 的实践初步证明,相较于 Python,用 XLang™ 来构建 AI 系统会更精炼、灵活,并展现出更好的性能。XLang™ 使能了边缘 AI 计算。
XLang™ 的开源和发展,经过两年孕育开发的 XLang™ 已经初具能力,但要成为 AI 时代新编程语言的愿景十分宏大,需要广大开发者一起来完成。XLang™ 已经由 XLang™ 基金会开源[4],我们邀请全球开发者社区做出贡献,以 GitHub[5] 作为协作中心。XLang™ 基金会热诚地鼓励开发人员加入该项目,并为人工智能编程领域的这一开创性工作做出贡献。