
- 1【从零开始学习深度学习】31. 卷积神经网络之残差网络(ResNet)介绍及其Pytorch实现_resnet31
- 2自动化测试入门 —— 自动化测试概论!
- 3Resnet残差网络学习_残差学习
- 4NVD API
- 5ElasticSearch-基础
- 6java.lang.IllegalArgumentException异常的正确解决方法
- 7【路由与交换】基于思科模拟器的路由与交换实训报告(单臂路由、三层交换机实现vlan通信、ospf、rip、dhcp、acl、nat技术总结)
- 8Kubernetes应用的更新与动态扩容指南_kubeborad 应用更新状态
- 9OpenCalib: 自动驾驶多传感器的一个开源标定工具箱
- 10FPGA使用ISERDES2过采样
Python--爬虫--XPath入门_python——xpath基础
赞
踩
目录
一、XPath简介
全称:XML Path Language;
作用: 解析数据(HTML,XML),提取节点与节点包含的内容;
什么是节点?
HTML为例:<body>是一个根节点,<div>,<a>等是根节点的子节点,<div>,<a>等节点包含的节点是他们的子节点,实例如下。
- <!DOCTYPE html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <title>xpath_test</title>
- </head>
- <body>
- <div>这里是根节点body的子节点div<div/>
- <p>这里是div的子节点p<p/>
- <a>这里是根节点body的子节点a<a/>
- <p>这里是div的子节点p<p/>
-
- </body>
- </html>
二、xpath函数
2.1、XPath常用函数:
xlm/html对象.etree()函数
使用方法:
2.1.1、etree = tree.xpath("/父节点1/子结点2")->返回的是子节点,返回内容如下:
(<Element 子节点2 at 地址>)
2.1.2、etree = tree.xpath("/父节点1/子结点2/text()")->返回的是子节点2的文本内容
2.1.3、etree = tree.xpath("/父结点1//子结点2")->返回的是子节点2的全部后代节点
2.1.4、etree = tree.xpath("/父结点1/子结点2/@子节点2的属性值")->返回的是子节点2的的属性值
2.1.5、etree = tree.xpath("./节点/节点")->相对查找,一般在缩小范围准备提取内容时在循环遍历使用。
x = html.xpath()函数
*:表示任意节点
节点[第几个],1开始
./:相对查找
//:绝对查找
/@属性:拿属性的值
/text():拿标签的文本内容
父节点//子节点->显示全部 //->后代
三、步骤
3.1、运行环境:win10家庭版,phcharm edu;
3.2、下载所用的库(提供两种方法):在编辑器(如pycharm)控制台输入:pip install lxml,pip install requests,也可以在编辑器的设置里,Python Interpreter直接搜索包并下载;
3.3、操作步骤
3.3.1、目标实例
天堂电影;
3.3.2、需求
抓取2022新片推荐下载链接(可下载);
3.4、源码
- # 天堂电影
- # 2022新片
-
- from lxml import html
- import requests
-
- # 发起请求拿源码,发现是get方式传参
- url = "https://www.dy2018.com/"
- resp = requests.get(url)
- resp.encoding = 'gb2312'
- resp_content = resp.text
- # print(resp_content),测试是否成功拿到源码
- # 创建html的etree解析,并把html源码交给etree解析
- etree = html.etree
- html = etree.HTML(resp_content)
-
- # 开始定位
- lis = html.xpath('//*[@id="header"]/div/div[3]/div[4]/div[1]/div[2]/ul/li')
- # 循环遍历取出
- for li in lis:
- hrefs = li.xpath("./a/@href")
- # print(hrefs)
- all_href = ''.join(hrefs) # 把列表中的元素放在空串中,元素间用空格隔开
- all_hrefs = url + all_href # 把链接拼接起来
-
- if all_href == "https://www.jianpian12.com/": # 出现一个没用的干扰链接,去掉
- all_href = ""
- else:
- titles = li.xpath("./a/text()")
- all_titles = ''.join(titles) # 把列表中的元素放在空串中,元素间用空格隔开
- # print(all_titles, end=" ") 拿到电影名称
- # print(all_hrefs) 拿到电影跳转具体下载链接
- # 第二次请求
- resp2 = requests.get(all_hrefs)
- resp2.encoding = 'gb2312' # 查看源码,得到编码方式,进行解析
- resp_content2 = resp2.text
- # print(resp_content),测试是否成功拿到源码
- # 创建html的etree解析,并把html源码交给etree解析
- # etree = html.etree
- html2 = etree.HTML(resp_content2)
- # 开始定位
- # ”//*[@id="Zoom"]/div[1]/ul/li/a“
- # "//*[@id="Zoom"]/div[1]/ul/li/a" 发现每一个的id都一样直接copy,xpath路径进行使用
- lis2 = html2.xpath('//*[@id="Zoom"]/div[1]/ul/li')
-
- for lis in lis2:
- all_href2 = lis.xpath("./a/@href")
- all_hrefs2 = ''.join(all_href2) # 把列表中的元素放在空串中,元素间用空格隔开
- all_hrefs2 = all_hrefs2.split("=")[-1]
- # all_hrefs2 = all_hrefs2.split("/")
- print(all_hrefs2)
- # 下一步应该是拿到了下载链接的地址进行下载并保存
- # 但发现链接访问失败(在浏览器访问下载链接也是失败的,很奇怪),先进行到这步,之后在探究是什么问题之后继续补充
-
-
-
-
-

四、结果
4.1、返回的结果
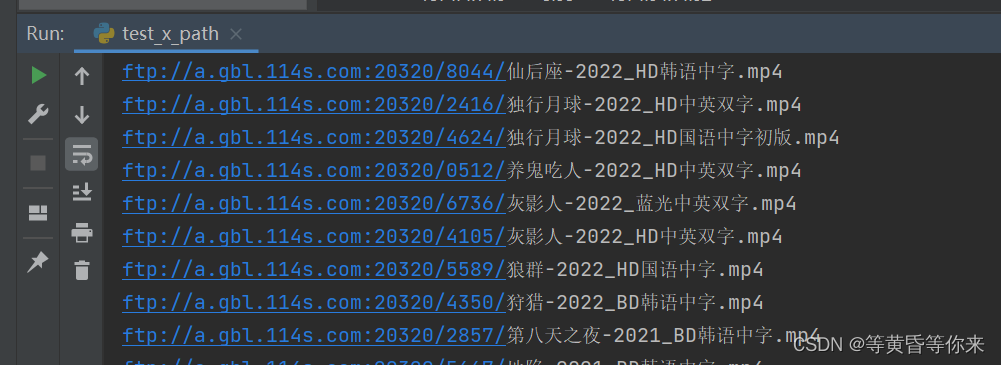
五、问题与总结
5.1、问题
5.1.1、爬取到的链接访问不到内容(是否是存在防盗链呢?);
5.1.2、爬取并输出的内容分割性不好,代码需要优化;
5.2、总结
5.2.1、好好学习。


