
热门标签
热门文章
- 1快速解决:phpstudy中的MySQL数据库无法启动_phpstudy的mysql无法启动
- 2flutter环境搭建及其遇到的坑_flutter could not download kotlin-reflect-1.9.20.j
- 3【Git系列】Git LFS常用命令的使用_git lfs 命令
- 4Linear Regression(多变量) Task4_linearregression模型多变量代码
- 5几乎完全零基础,从一无所知开始学会渗透该如何开始?_网上为什么学不到真正的渗透技术
- 62024人工智能大语言模型发展技术研究报告
- 7泰迪智能科技大数据人工智能实训室优势特色介绍_人工智能实验室的亮点
- 8Github最新注册及使用教程_repositories, branches, commits, and pull requests
- 9超过100个的优秀开源项目_具有上传下载及用户管理功能的开源项目
- 10vue移动端电影排片轮播(仿淘票票、猫眼)_vue电影排行代码热播经典
当前位置: article > 正文
百度图片的爬取(python)_爬取图片加content
作者:木道寻08 | 2024-07-09 02:15:11
赞
踩
爬取图片加content
一,构建框架
1,导入项目所需要的库
- # 导入需要的库
- import os
- import re
- import requests
2,获取网站源码
- # 获取网站源码
- def get_html(url, header, params):
- response = requests.get(url, headers=header, params=params)
- # 源码的编码方式
- response.encoding = "utf_8"
- # 利用循环判断网页能否打开
- if response.status_code ==200:
- return response.text
- else:
- print("网址源码获取错误")
3,解析提取图片的源址
- # 解析提取图片的源地址
- def parse_pic_url(html):
- result = re.findall('thumbURL": "(.*?)"', html, re.S)
- return result
4, 获取图片二进制源码
- # 获取图片二进制源码
- def get_pic_content(url):
- response = requests.get(url)
- return response.content
5,创建文件夹对图片保存
- # 定义一个文件夹保存
- def create_fold(fold_name):
- # 加异常处理
- try:
- os.mkdir(fold_name)
- except:
- print("文件夹已存在")
6,保存图片
- # 保存图片
- def save_pic(fold_name, content, pic_name):
- with open(fold_name + "/" + str(pic_name) + ".jpg", "wb") as f:
- f.write(content)
- f.close
7,定义main函数对调用get_html函数
- #定义main函数调用get_html函数
- def main():
- #输入文件夹名字
- fold_name = input("请输入图片名:")
- #输入你要抓取的数量
- page_num = input("请输入你要抓取的页数:")
- #调用函数,创建文件夹
- create_fold(fold_name)
- #定义图片名字
- pic_name = 0
- #构建循环.控制页面
- for i in range(int(page_num)):
- url =
- headers = {}
- params = {}
-
- html = get_html(url, headers, params)
- result = parse_pic_url(html)
- # 使用for循环遍历列表
- for item in result:
- # 调用函数,获取二进制源码
- pic_content = get_pic_content(item)
- save_pic(fold_name, pic_content, pic_name)
- pic_name += 1
- print("正在保存第" + str(pic_name))
-
- # 执行main函数
- if __name__ == '__main__':
- main()

二,图片爬取
1,导入数据
打开浏览器搜索要爬取的图片,以大熊猫为例
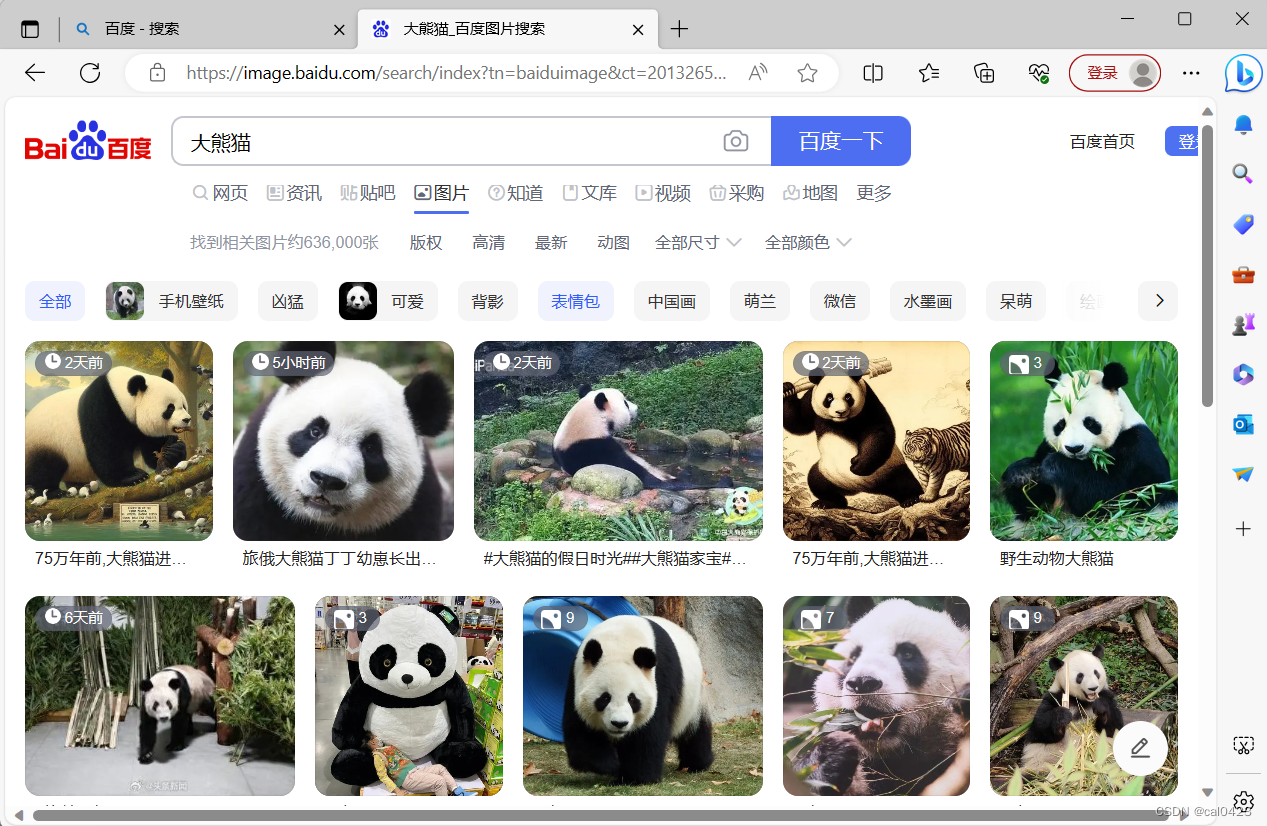
单击鼠标右键检查(F12)
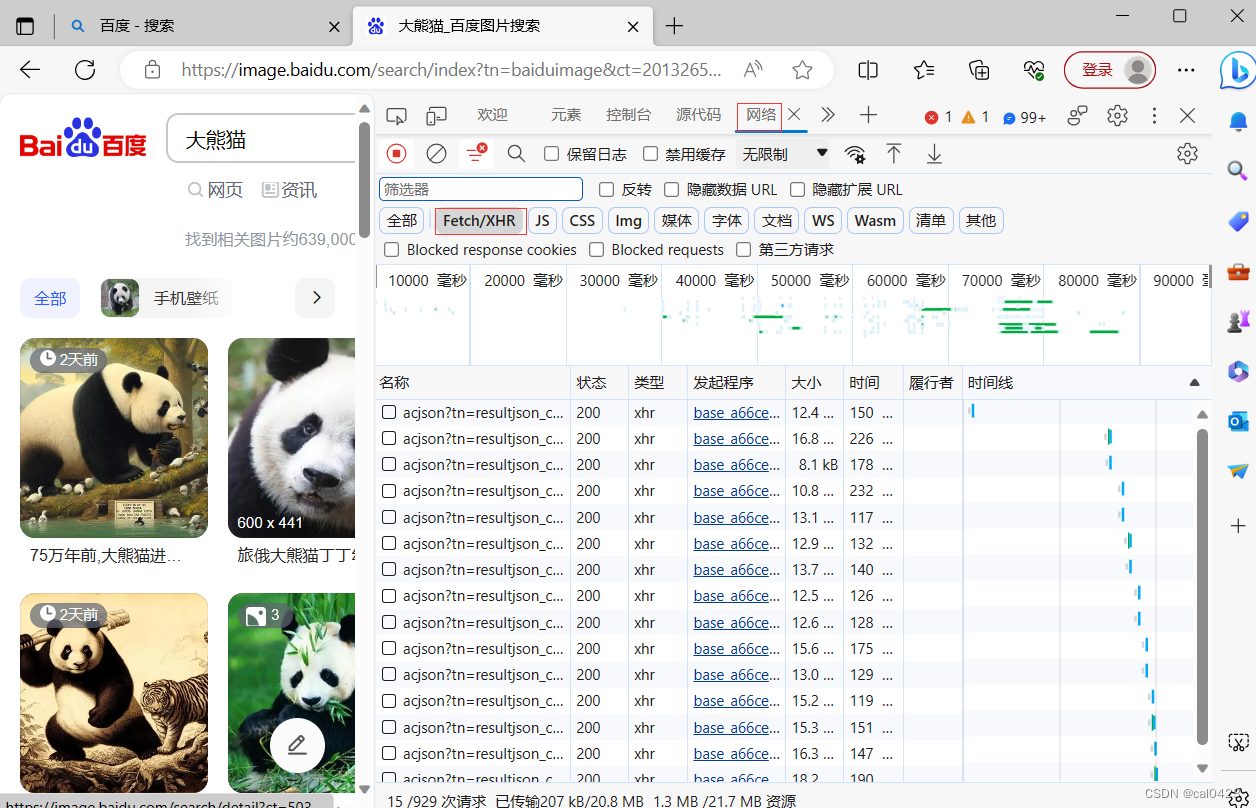
选中网络,选择Fetch/XHR,刷新界面一直下拉,acjson就会一直增加
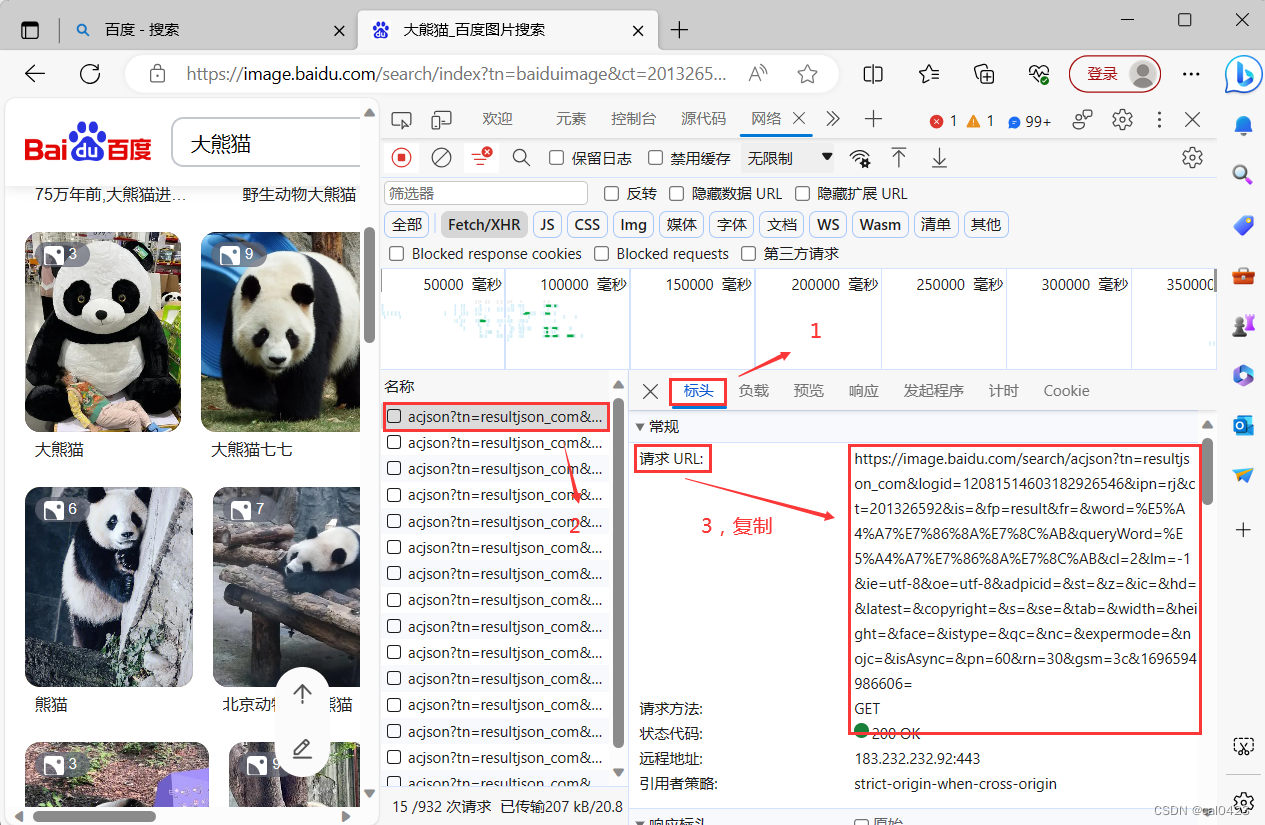
选择一个acjson文件选择标头,复制"请求URL"

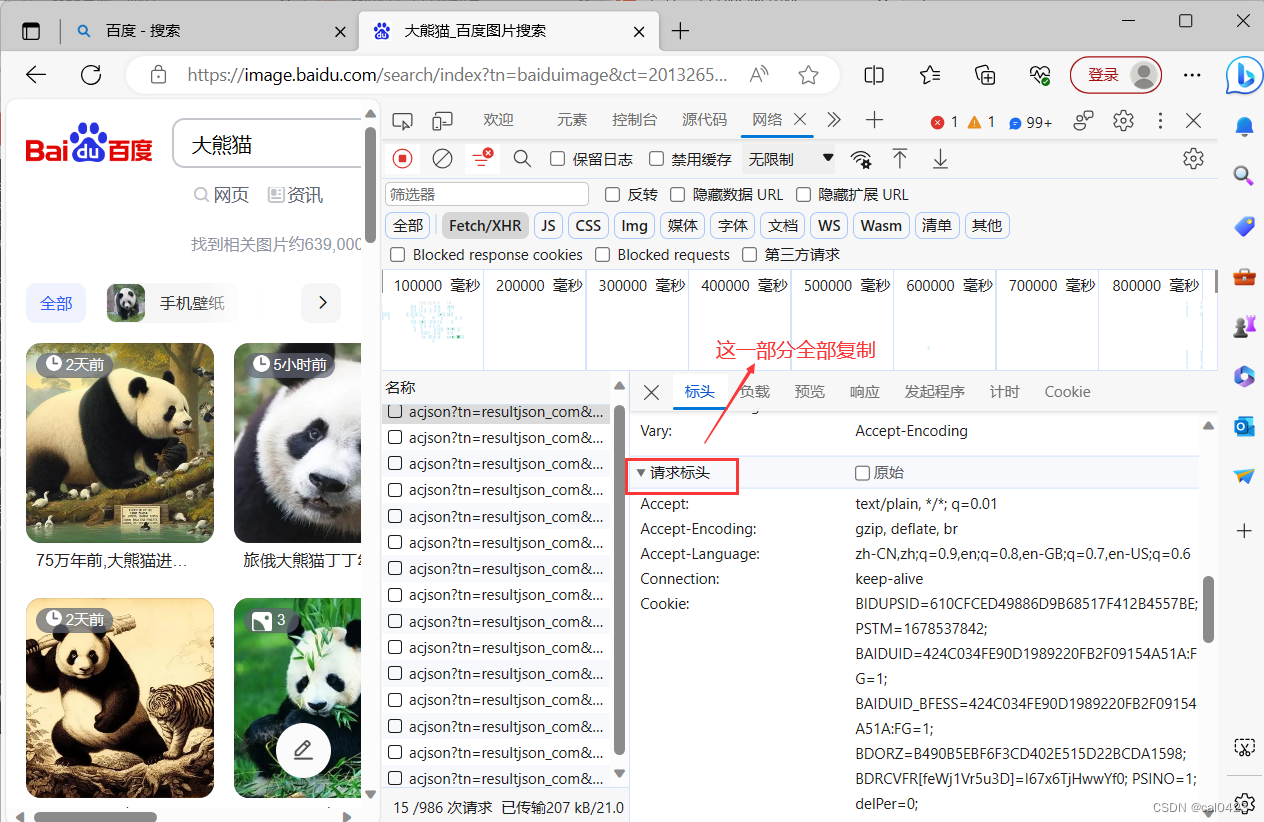
对该页面往下翻,并复制框中信息粘贴在header中(注:粘贴时优先打三对双引号注释后再粘贴,这样能够最高程度避免粘贴胡乱换行的情况)
粘贴完成后,分别给左边名称和右边信息添加双引号(已有双引号就加单引号)
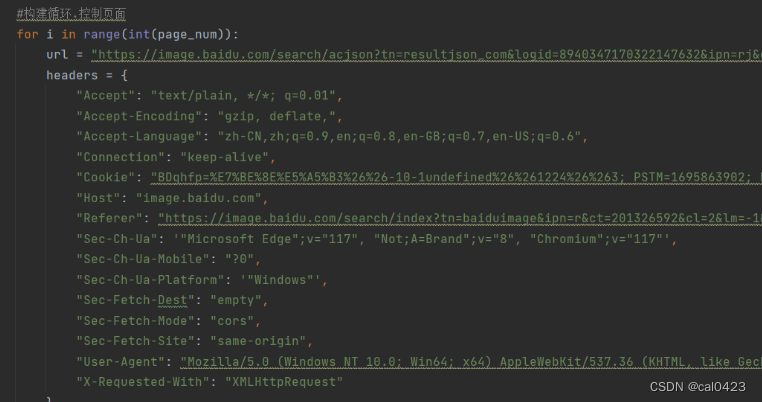
回到网页选择负载,复制内容粘贴在params中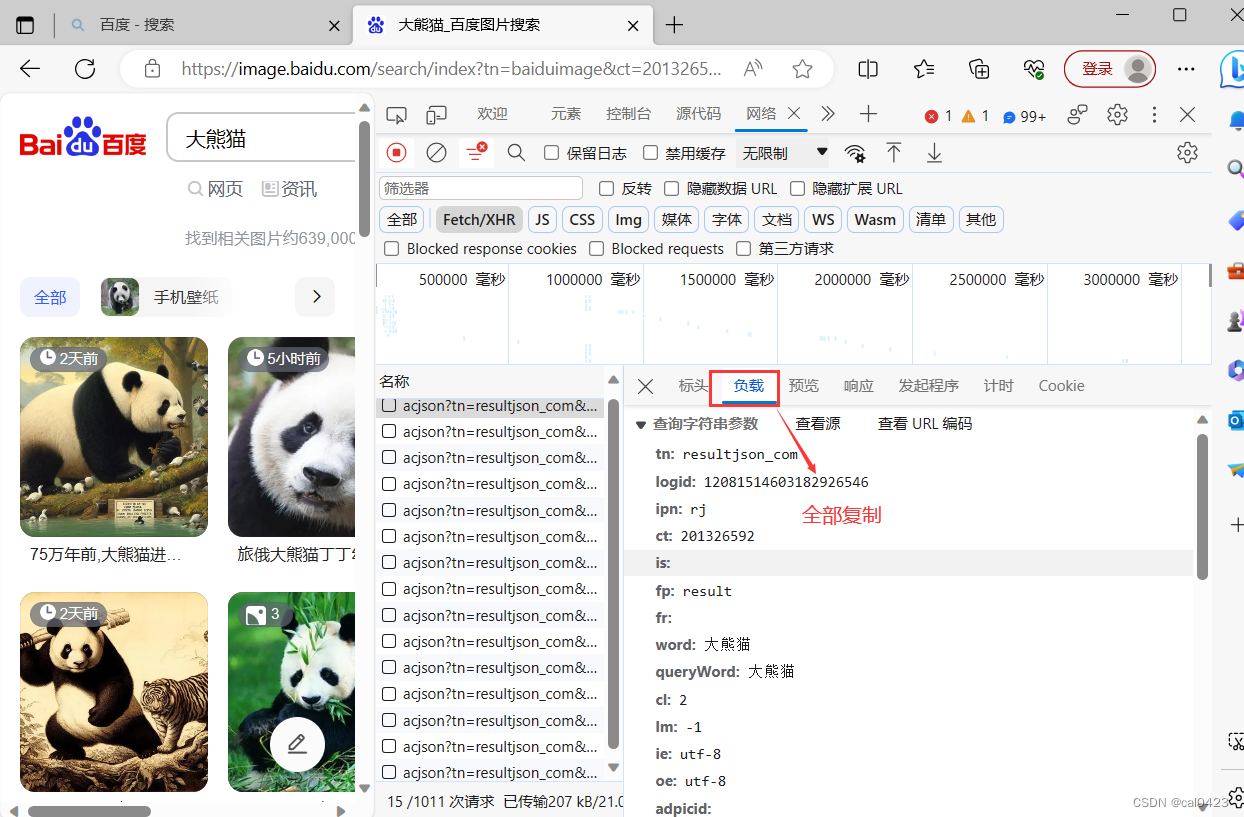
同样在两边添加双引号,同时删除没有内容的词条
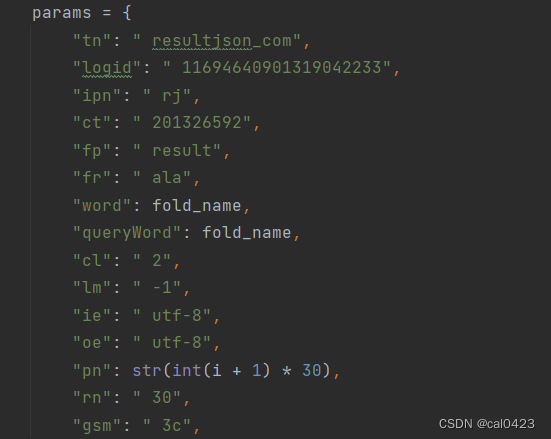
(pn原数据为60,这里已修改)
完成后就可以正常爬取图片了
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/木道寻08/article/detail/801093?site
推荐阅读
相关标签

