
- 1第二篇: 掌握Docker的艺术:深入理解镜像、容器和仓库_docker私人仓库常用镜像
- 2Java毕业设计-社区疫情管理小程序
- 33、任意文件上传漏洞_任意文件上传漏洞条件,View的这些基础知识你必须要知道_任意文件上传导致 xss
- 4掌握Python操作Word:从基础到高级全覆盖_python word编辑
- 5我,32岁,动力机械专业研究生,转行到算法工程师,完成薪资翻倍_开发转算法工程师
- 6【大数据安全-Kerberos】Kerberos常见问题及解决方案_gss initiate failed_client not found in kerberos database
- 7西电通院计网实验七——ACL访问控制实验_计网实验3.2.1
- 8十大经典排序算法(Java实现)_java基础排序算法
- 9速盾:视频cdn和网站cdn的相同点与不同点
- 10用例设计需遵循哪些规范标准?_8.用例的命名规范?
2024年最全医学图像分割 3D nnUNet全流程快速实现_医学图像分割步骤(4),2024年最新想拿高工资_nnunet中断继续
赞
踩
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
③制作dataset.json,nnUNet需要提供一个json文件来描述你的数据集,通过以下代码生成,这个代码nnUNet文件夹中有提供,这里是我修改后的版本,实际需要各自修改后使用
- 1
- 2
- 3
- 4
- 5
“”"
创建数据集的json
“”"
import glob
import os
import re
import json
from collections import OrderedDict
def list_sort_nicely(l):
“”" Sort the given list in the way that humans expect.
“”"
def tryint(s):
try:
return int(s)
except:
return s
def alphanum\_key(s):
""" Turn a string into a list of string and number chunks.
- 1
- 2
“z23a” -> [“z”, 23, “a”]
“”"
return [tryint© for c in re.split(‘([0-9]+)’, s)]
l.sort(key=alphanum_key)
return l
path_originalData = “/data/nas/heyixue_group/PCa//DATASET_nfs/nnUNet_raw/nnUNet_raw_data/Task108_PCa_256/”
if not os.path.exists(path_originalData):
os.mkdir(path_originalData+“imagesTr/”)
os.mkdir(path_originalData+“labelsTr/”)
os.mkdir(path_originalData+“imagesTs/”)
os.mkdir(path_originalData+“labelsTs/”)
train_image = list_sort_nicely(glob.glob(path_originalData+“imagesTr/*”))
train_label = list_sort_nicely(glob.glob(path_originalData+“labelsTr/*”))
test_image = list_sort_nicely(glob.glob(path_originalData+“imagesTs/*”))
test_label = list_sort_nicely(glob.glob(path_originalData+“labelsTs/*”))
文件夹里已经带后缀了,并且有两个模态
train_image = [“{}”.format(patient_no.split(‘/’)[-1]) for patient_no in train_image]
train_label = [“{}”.format(patient_no.split(‘/’)[-1]) for patient_no in train_label]
test_image = [“{}”.format(patient_no.split(‘/’)[-1]) for patient_no in test_image]
去掉后缀,整合
train_real_image = []
train_real_label = []
test_real_image = []
for i in range(0, len(train_image), 2):
train_real_image.append(train_image[i].replace(‘_0000’, ‘’))
for i in range(0, len(train_label)):
train_real_label.append(train_label[i].replace(‘_0000’, ‘’))
for i in range(0, len(test_image), 2):
test_real_image.append(test_image[i])
输出一下目录的情况,看是否成功
print(len(train_real_image), len(train_real_label))
print(len(test_real_image), len(test_label))
print(train_real_image[0])
-------下面是创建json文件的内容--------------------------
可以根据你的数据集,修改里面的描述
json_dict = OrderedDict()
json_dict[‘name’] = “PC” # 任务名
json_dict[‘description’] = " Segmentation"
json_dict[‘tensorImageSize’] = “3D”
json_dict[‘reference’] = “see challenge website”
json_dict[‘licence’] = “see challenge website”
json_dict[‘release’] = “0.0”
这里填入模态信息,0表示只有一个模态,还可以加入“1”:“MRI”之类的描述,详情请参考官方源码给出的示例
json_dict[‘modality’] = {“0”: “PET”, ‘1’: ‘CT’}
这里为label文件中的标签,名字可以按需要命名
json_dict[‘labels’] = {“0”: “Background”, “1”: “cancer”}
下面部分不需要修改
json_dict[‘numTraining’] = len(train_real_image)
json_dict[‘numTest’] = len(test_real_image)
json_dict[‘training’] = []
for idx in range(len(train_real_image)):
json_dict[‘training’].append({‘image’: “./imagesTr/%s” % train_real_image[idx],
“label”: “./labelsTr/%s” % train_real_label[idx]})
json_dict[‘test’] = [“./imagesTs/%s” % i for i in test_real_image]
with open(os.path.join(path_originalData, “dataset.json”), ‘w’) as f:
json.dump(json_dict, f, indent=4, sort_keys=True)
## 3 预处理、训练、测试 将自己的NII数据集转换成nnUNet所需要的格式后,即可在命令行中直接输入命令进行流水线操作了 #### 3.1 预处理 `nnUNet_plan_and_preprocess -t 101` -t后面的数字即为任务的ID,一般直接使用这个命令进行全部预处理就行,会默认的进行2d、3d\_full\_res和3d\_cascade\_fullres三种任务的预处理,如果只想跑单独某一种的预处理的话,需要额外设置其他参数,可以输入`nnUNet_plan_and_preprocess -h` 查看帮助,这里不详细介绍了 **预处理后,还可以自定义nnUNet的分折** nnUNet的默认是随机的五折交叉验证,如果需要用自己定好的分折方式的话,可以通过在预处理结果中创建splits\_final.pkl文件进行设定,代码如下

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
“”"
把自己设定的分折方式写成nnunet的pkl文件
“”"
import numpy as np
from collections import OrderedDict
import pickle
def write_pickle(obj, file, mode=‘wb’):
with open(file, mode) as f:
pickle.dump(obj, f)
获取内部交叉验证训练集、验证集的id,自己修改这部分
Kfold_train_valid_test = {0: {‘train’: train_ids[0], ‘val’: train_ids[1]},
1: {‘train’: train_ids[2], ‘val’: train_ids[3]},
2: {‘train’: train_ids[4], ‘val’: train_ids[5]},
3: {‘train’: train_ids[6], ‘val’: train_ids[7]},
4: {‘train’: train_ids[8], ‘val’: train_ids[9]}}
splits = []
for i in range(5):
# 获取想要的分折的结果
train_id = np.sort(np.array(Kfold_train_valid_test[i][‘train’], np.uint16))
val_id = np.sort(np.array(Kfold_train_valid_test[i][‘val’], np.uint16))
train_keys = np.array([str(id)+‘_image’ for id in train_id])
test_keys = np.array([str(id)+‘_image’ for id in val_id])
splits.append(OrderedDict())
splits[-1][‘train’] = train_keys
splits[-1][‘val’] = test_keys
splits_file = r’*/DATASET/nnUNet_preprocessed/Task101_PC/splits_final.pkl’ # 保存在预处理结果那里
save_pickle = write_pickle
save_pickle(splits, splits_file)
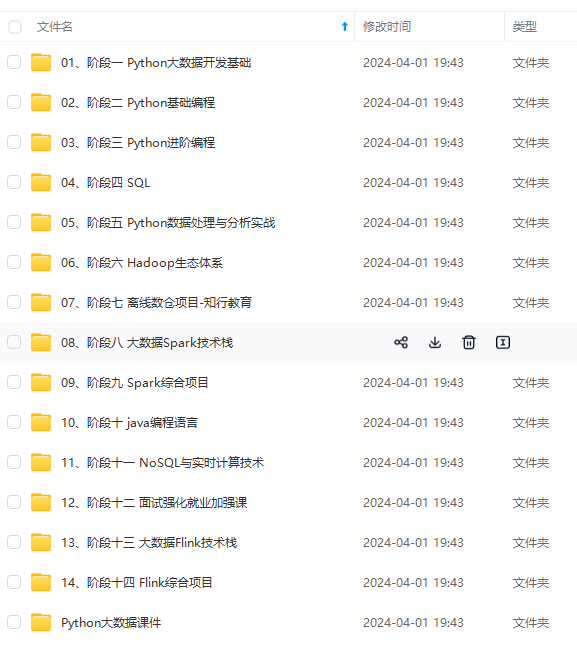
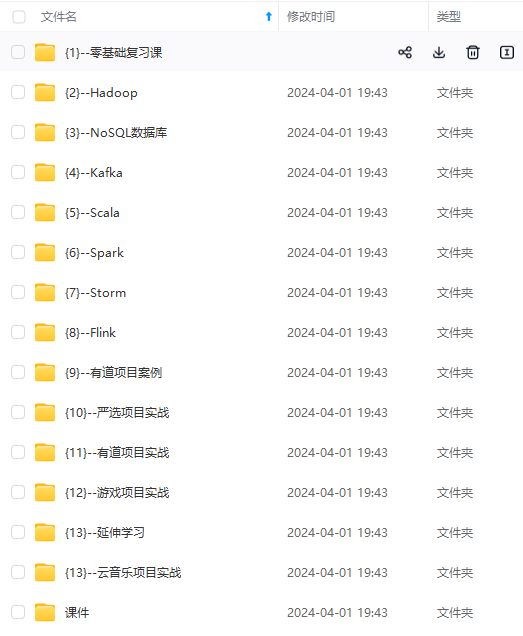
#### 3.2 训练 `nnUNet_train 3d_fullres nnUNetTrainerV2 101 0` 其中101是任务ID,0表示训练第一折(nnUNet的五折是0-4) * 训练中断了想断点继续训,后面加个-c: `nnUNet_train 3d_fullres nnUNetTrainerV2 101 0 -c` * 想训练全部数据,即不分折,折数改为all:`nnUNet_train 3d_fullres nnUNetTrainerV2 101 all` * 训练最少需要大概8g显存,一轮的时间很慢,一个epoch大概600s(很吃CPU,如果CPU不好的话这个时间会大大增加),默认是训练1000个epoch,时间很慢,等它跑完就好啦,如果需要修改训练的epoch数量(默认1000确实太久了),可以修改这里的代码  #### 3.3 验证&推理&评估 * **验证** 正常训练完后会自动进行验证,验证结果在这: DATASET\nnUNet\_trained\_models\nnUNet\3d\_fullres\Task101\_PC\nnUNetTrainerV2\_\_nnUNetPlansv2.1\fold\_0 * **推理** `nnUNet_predict -i 要预测数据的文件夹路径 -o 输出文件夹路径 -t 101 -m 3d_fullres -f 0` -f 表示第几折,如果不加的话会使用五折的集成(需要五折都跑了) * **评估** `nnUNet_evaluate_folder -ref 金标准文件夹 -pred 预测结果文件夹 -l 1` -l 表示要计算的label的类别,正常就是背景-0肿瘤-1,所以设置1,如果有两类就是 -l 1 2,以此类推 这个是nnUNet自带的评估命令,计算分割DSC,可以不用这个,另写代码去算需要的评估指标即可 ## 4 其他 * 本文只说明了3d\_fullres的训练,完整的nnUNet流程还需要跑2d和3d级联的,然后进行三种的择优。不过从实际性能来说,一般3d级联≥3d>2d,是否跑其他两种需要自己考虑。推理最优设置是这个,会返回一个最优设置的predict命令 `nnUNet_find_best_configuration -m 2d 3d_fullres 3d_lowres 3d_cascade_fullres -t 101` * nnUNet虽然号称全流程的实现方式,但是实际经验发现一些数据的预处理(比如卡阈值)还是需要自己提前做的,不然结果可能不理想 * 对nnUNet更详细的了解可以看花老师的博客,里面有nnUNet的一整套分析,包括论文分析、训练测试和常见问题解答,我也是看这些学习的 [花卷汤圆的CSDN博客-医学图像分割](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb) * 另外,由于nnUNet使用命令行进行处理,有时候一直放着等可能会有意外,可以考虑用screen等方式挂到后台 [常用screen操作总结](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb) ## 5 常用命令行指令 1.加后缀\_0000 (不过这个常常自己数据准备时处理好就行了,不需要用nnunet的) `nnUNet_convert_decathlon_task -i /DATASET/nnUNet_raw/nnUNet_raw_data/TaskXXX` 2.预处理 `nnUNet_plan_and_preprocess -t task_id` 3.设置显卡 `export CUDA_VISIBLE_DEVICES=cuda_id` 4.训练 `nnUNet_train 3d_fullres nnUNetTrainerV2 task_id fold_id` `nnUNet_train 3d_fullres nnUNetTrainerV2 task_id fold_id -c` (-c表示中断后继续训) 5.测试(不用-f则是集成) `nnUNet_predict -i 要预测数据的文件夹路径 -o 输出文件夹路径 -t task_id -m 3d_fullres -f 0` 6.推理出测试命令(只跑了3dfullres的不需要) `nnUNet_find_best_configuration -m 2d 3d_fullres 3d_lowres 3d_cascade_fullres -t task_id` 7.测试集评估(nnunet自带的评估方法,算dsc的,如果有其他指标要算就还是自己写一个吧) `nnUNet_evaluate_folder -ref FOLDER_WITH_GT -pred FOLDER_WITH_PREDICTIONS -l 1 2` 8.linux查看程序(前面用户名,后面关键词) `ps aux|grep root|grep nnUNet` 9.清理程序(有时候停掉nnunet时没有完全关掉所有nnunet线程,就要自己手动一个个kill) `kill -9 num`  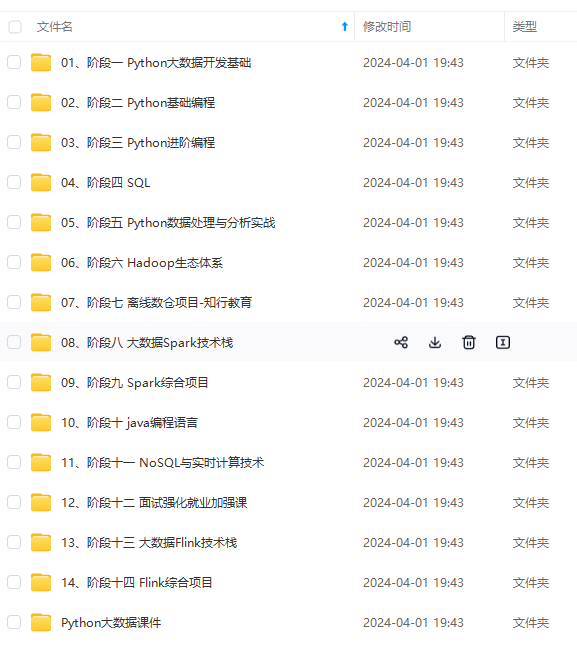 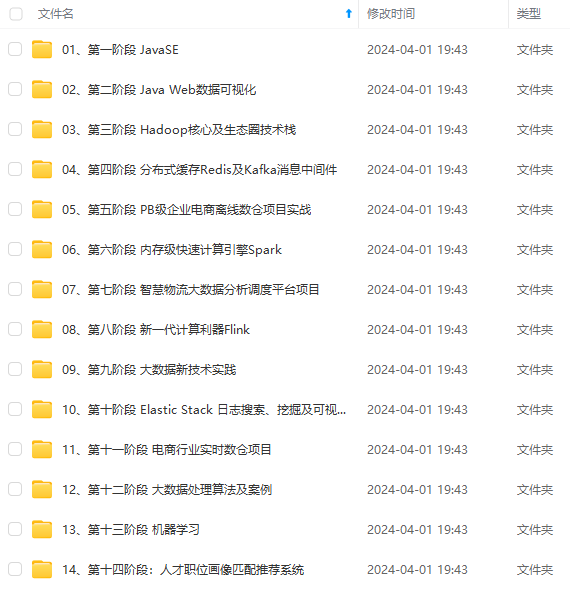 **既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!** **由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新** **[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)** )] **既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!** **由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新** **[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82

