
- 1最优雅最简洁的VsCode配置Jupyter多版本Python内核的方法(不涉及Anaconda)_vscode jupyter_vscode添加内核
- 2【2024华为OD机试C卷】456、分披萨 | 机试真题+思路参考+代码解析(C语言、C++、Java、Py、JS)_华为od机试真题-分披萨
- 3基于PaddleOCR的DBNet神经网络实现全网最快最准的身份证识别_paddleocr 身份证识别
- 4软考高级论文真题“论大数据lambda架构”
- 5Generative AI 新世界 | 大语言模型(LLMs)在 Amazon SageMaker 上的动手实践_aws llms产品
- 6sqlserver创建函数
- 7Facebook 推出多模态通用模型 FLAVA,吊打 CLIP 平均十个点!
- 8用子查询的方法查找研发部比财务部所有雇员收入都高的雇员的姓名_用子查询的方法查找研发部比市场部所有雇员收入都高的雇员的姓名
- 9hive的安装与基本配置(超详细,超简单)_hive安装与配置
- 10AI技术在软件测试中的应用和实践_测试接入ai
BART论文解读_bard论文
赞
踩
1 概述
- 全称:Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension。BART来源于Bidirectional and Auto-Regressive Transformers
- 发表时间: 2019.10.29
- 团队:Facebook AI
Paper地址arxiv.org/pdf/1910.13461.pdf
Code地址github.com/huggingface/transformers/blob/master/tests/test_modeling_bart.py
2. 主要贡献
- 背景:由于基于BERT类的生成模型大多在预训练和下游任务之间存在一定的差异,导致生成模型的结果并不理想,本文提出了BART模型,更加充分去利用上下文信息和自回归特点。
- 主要贡献:BART提出了一个结合双向和自回归的预训练模型。BART模型首先使用任意噪声来破坏原文本,然后学习模型重构原文本。这样使得,BART不仅很好的处理文本生成任务,同时理解任务上的表现也不错。
3 模型架构
3.1 Architecture
BART使用了标准的seq2seq tranformer结构。BART-base使用了6层的encoder和decoder, BART-large使用了12层的encoder和decoder。BART的模型结构与BERT类似,不同点在于:
(1)decoder部分基于encoder的输出节点在每一层增加了cross-attention(类似于tranformer的seq2seq模型);
(2)BERT的词预测之前使用了前馈网络,而BART没有。总的来讲,在同等规模下,BART比BERT多了10%的参数。
3.2 Pre-training BART
BART的预训练是在于破坏原文档然后优化重构loss,通过交叉熵来计算decoder输出与原文档的差异。极端情况下,当原文档信息全部丢失时,BART相当于语言模型。

图1 BART预训练方式
BART采用了多种方式破坏原文档,即采用了多种Noise.
- Token Masking 随机替换原始token为[MASK]
- Token Deletion 随机删除输入的token。相比较于Token Masking,模型必须决定哪个位置是遗漏的。
- Text Infilling Text infilling是基于spanBERT的思路,取连续的token用[MASK]替换,span的长度服从
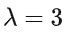 的泊松分布。特殊情况下,当span长度为0时,相当于插入了一个mask。
的泊松分布。特殊情况下,当span长度为0时,相当于插入了一个mask。 - Sentence Permutation 打乱文档中句子的顺序。
- Document Rotation 随机选择一个token,然后旋转文本使得新的文本以这个token开头。此任务的目的用于判别文本的开头。
3.3 Fine-tuning BART
3.3.1 Sequence Classification Tasks
对于序列分类(文本分类)任务,encoder和decoder部分都用相同的输入,将deocoder最后一个节点用于多类别线性分类器中。此方法与BERT的CLS token较为类似;区别在于,BART在decoder部分最后增加了一个token,如此,便可获得来自完整输入的解码信息。(见图) - 思考:此方法,在inference上会更耗时吗
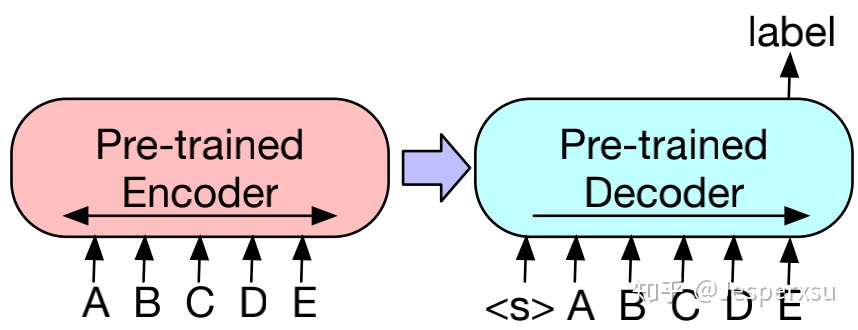
图2 BART在文本分类上finetune的方式
3.3.2 Token Classification Tasks
对于序列标注任务,同样是在decoder和encoder采用相同的文本输入,以decoder的隐藏节点输出用于预测每个节点的类别。
3.3.3 Sequence Generation Tasks
由于BART的模型框架本身就采用了自回归方式,因而在finetune序列生成任务时,可直接在encoder部分输入原始文本,decoder部分用于预测待生成的文本。
3.3.4 Machine Translation
BART预训练模型同样也可用于将其它语言翻译为英文(BART的预训练模型是基于英语来训练的)。
先前的研究工作已经表明,在机器翻译中,encoder部分融合预训练模型能带来较大的效果提升,然后在decoder部分却受到限制。本文本表明在仅仅在encoder更换部分参数,就可利用到整个BART模型(包括encoder和decoder)。
更准确地说,本文替换encoder的embedding layer的参数为随机初始化所得(因输入语言不再是预训练模型采用的英语)。然后,整个finetue阶段便可分为两步:1)先冻结BART的大部分参数,仅仅更新encoder部分的randomly initialized encoder和BART positional embeddings,以及输入到BART的第一层self-attention映射矩阵。2)更新BART的全部参数,这一步,仅需迭代几次即可。
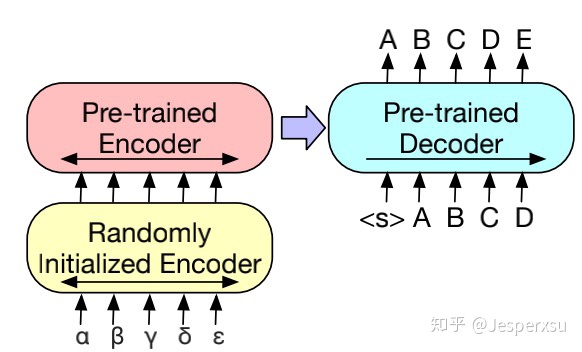
图3 BART机器翻译finetune的模型结构
4 实验结果

表1 不同的预训练方式对比
表1表明,基于消融实验,上述所采用的噪声处理方式基本上相比之前的模型,在准确率上都有一定的提升。

表2 SQuAD和GLUE任务上实验结果
表2表明,BART在SQuAD和GLUE上的效果堪比RoBERTa和XLNET,在部分任务上效果最优,也说明了采用单向编码器并不会降低判别任务上的效果。

表3 文本摘要上实验结果
表3表明,BART在摘要提取效果都有明显提升,也再次表明,预训任务与下流任务尽可能接近时,下游任务会达到更好的效果。
5 写在最后
5.1 总结
BART通过重构带有噪声的文本,不仅能在判别任务达到与RoBERTa持平的效果,甚至可在生成任务上达到SOTA.
5.2 一点点思考
- 与MASS和UniLM初衷较为类似,也希望不仅利用到BERT类的上下文信息,同时也希望像GPT一样学到自回归特性。只是做法上较为独特,在自编码上融合了更多的噪声信息,猜想,假设后续出现更多的噪声处理方式,是否也可融入进来?
参考
- 好奇的小will 【FB-BART新的预训练模型】阅读笔记 - 知乎
- 潘小小 【论文精读】生成式预训练之BART - 知乎
- kaiyuan BART原理简介与代码实战 - 知乎
- 机器之心 https://zhuanlan.zhihu.com/p/90

