
- 1PyTorch实现 Self Attention
- 2A survey of self-supervised and few-shot object detection论文整理_survey self supervised
- 3RabbitMQ基础笔记
- 4AI新工具 又一个开源大模型DBRX击败GPT3.5;根据音频和图像输入生成会说话、唱歌的动态视频
- 5以数智化驱动为核心,构建研发效能增长动力_数智化能源技术架构
- 6国内区块链企业已超4.8万家,实际项目不过1800多个
- 7怎么分析某个明星或者公众人物ins的数据?_分析其他人ins账号点赞数
- 8python 机器学习中模型评估和调参
- 9美创科技获浙江省网络空间安全协会多项荣誉认可
- 10python实现BP神经网络模型对鸢尾花分类_python实现bp神经网络分类
resnet结构_来聊聊ResNet及其变种
赞
踩
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
01 ResNet网络结构
2015 年,ResNet 横空出世,一举斩获 CVPR 2016 最佳论文奖,而且在 Imagenet 比赛的三个任务以及 COCO 比赛的检测和分割任务上都获得了第一名。四年过去,这一论文的被引量已超 40000 次.。
我们知道,增加网络深度后,网络可以进行更加复杂的特征提取,因此更深的模型可以取得更好的结果。但事实并非如此,人们发现随着网络深度的增加,模型精度并不总是提升,并且这个问题显然不是由过拟合(overfitting)造成的,因为网络加深后不仅测试误差变高了,它的训练误差竟然也变高了。作者提出,这可能是因为更深的网络会伴随梯度消失/爆炸问题,从而阻碍网络的收敛。作者将这种加深网络深度但网络性能却下降的现象称为退化问题(degradation problem)。
02ResNet中的Bottleneck结构和1*1卷积
ResNet50起,就采用Bottleneck结构,主要是引入1x1卷积。我们来看一下这里的1x1卷积有什么作用:
对通道数进行升维和降维(跨通道信息整合),实现了多个特征图的线性组合,同时保持了原有的特征图大小;
相比于其他尺寸的卷积核,可以极大地降低运算复杂度;
如果使用两个3x3卷积堆叠,只有一个relu,但使用1x1卷积就会有两个relu,引入了更多的非线性映射;
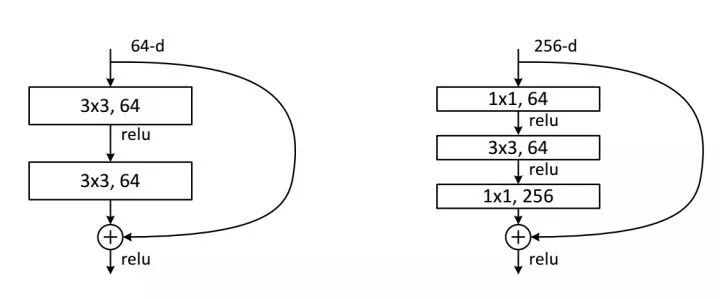
我们来计算一下1*1卷积的计算量优势:首先看上图右边的bottleneck结构,对于256维的输入特征,参数数目:1x1x256x64+3x3x64x64+1x1x64x256=69632,如果同样的输入输出维度但不使用1x1卷积,而使用两个3x3卷积的话,参数数目为(3x3x256x256)x2=1179648。简单计算下就知道了,使用了1x1卷积的bottleneck将计算量简化为原有的5.9%,收益超高。
03 ResNet的网络设计规律
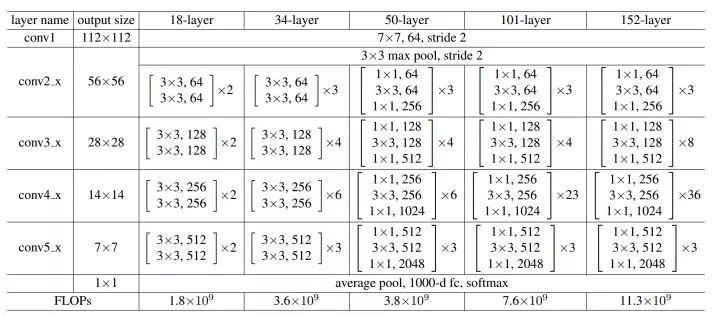
整个ResNet不使用dropout,全部使用BN。此外,回到最初的这张细节图,我们不难发现一些规律和特点:
受VGG的启发,卷积层主要是3×3卷积;
对于相同的输出特征图大小的层,即同一stage,具有相同数量的3x3滤波器;
如果特征地图大小减半,滤波器的数量加倍以保持每层的时间复杂度;(这句是论文和现场演讲中的原话,虽然我并不理解是什么意思)
每个stage通过步长为2的卷积层执行下采样,而却这个下采样只会在每一个stage的第一个卷积完成,有且仅有一次。
网络以平均池化层和softmax的1000路全连接层结束,实际上工程上一般用自适应全局平均池化 (Adaptive Global Average Pooling);
从图中的网络结构来看,在卷积之后全连接层之前有一个全局平均池化 (Global Average Pooling, GAP) 的结构。
总结如下:
相比传统的分类网络,这里接的是池化,而不是全连接层。池化是不需要参数的,相比于全连接层可以砍去大量的参数。对于一个7x7的特征图,直接池化和改用全连接层相比,可以节省将近50倍的参数,作用有二:一是节省计算资源,二是防止模型过拟合,提升泛化能力;
这里使用的是全局平均池化,但我觉得大家都有疑问吧,就是为什么不用最大池化呢?这里解释很多,我查阅到的一些论文的实验结果表明平均池化的效果略好于最大池化,但最大池化的效果也差不到哪里去。实际使用过程中,可以根据自身需求做一些调整,比如多分类问题更适合使用全局最大池化(道听途说,不作保证)。如果不确定话还有一个更保险的操作,就是最大池化和平均池化都做,然后把两个张量拼接,让后续的网络自己学习权重使用。
为了更好地理解,大家看一下何凯明的现场演讲,有助于更好地理解ResNet,CVPR2016 最佳论文, ResNet 现场演讲:
https://zhuanlan.zhihu.com/p/54072011
04 ResNet的常见改进
4.1 改进一
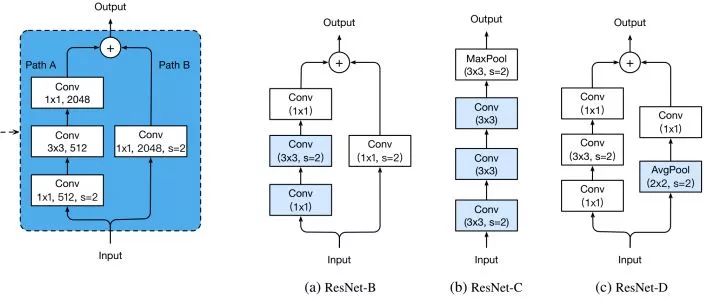
改进downsample部分,减少信息流失。前面说过了,每个stage的第一个conv都有下采样的步骤,我们看左边第一张图左侧的通路,input数据进入后在会经历一个stride=2的1*1卷积,将特征图尺寸减小为原先的一半,请注意1x1卷积和stride=2会导致输入特征图3/4的信息不被利用,因此ResNet-B的改进就是就是将下采样移到后面的3x3卷积里面去做,避免了信息的大量流失。ResNet-D则是在ResNet-B的基础上将identity部分的下采样交给avgpool去做,避免出现1x1卷积和stride同时出现造成信息流失。ResNet-C则是另一种思路,将ResNet输入部分的7x7大卷积核换成3个3x3卷积核,可以有效减小计算量,这种做法最早出现在Inception-v2中。其实这个ResNet-C 我比较疑惑,ResNet论文里说它借鉴了VGG的思想,使用大量的小卷积核,既然这样那为什么第一部分依旧要放一个7x7的大卷积核呢,不知道是出于怎样的考虑,但是现在的多数网络都把这部分改成3个3x3卷积核级联。
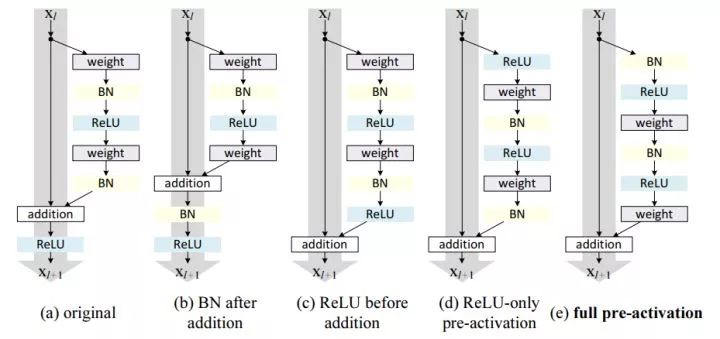
4.2 改进二:ResNet V2
这是由ResNet原班人马打造的,主要是对ResNet部分组件的顺序进行了调整。各种魔改中常见的预激活ResNet就是出自这里。
4.3 改进三:ResNeXt
ResNeXt是FAIR的大神们(恺明、Ross、Piotr等)对ResNet的改进。其关键核心模块如下所示。尽管ResNeSt与ResNeXt比较类似,不过两者在特征融合方面存在明显的差异:ResNeXt采用一贯的Add方式,而ResNeSt则采用的Cat方式。这是从Cardinal角度来看,两者的区别所在。这点区别也导致了两种方式在计算量的差异所在。其中,inception block人工设计痕迹比较严重,因此引入参数K,直接将子模型均分,有K个bottleneck组成。如下图所示。
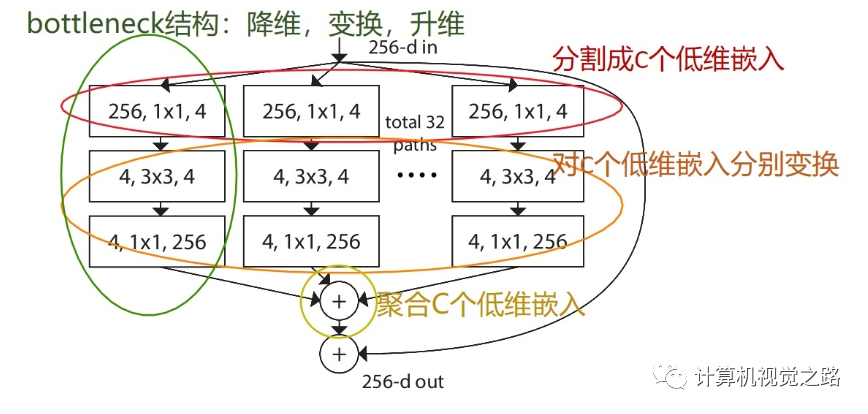
ResNeXt V2
4.4 Selective Kernel Networks(SKNet)
SKNet提出了一种机制,即卷积核的重要性,即不同的图像能够得到具有不同重要性的卷积核。SKNet对不同图像使用的卷积核权重不同,即一种针对不同尺度的图像动态生成卷积核。
论文地址:https://arxiv.org/abs/1903.06586代码地址:https://github.com/implus/SKNet
整体结构如下图所示:
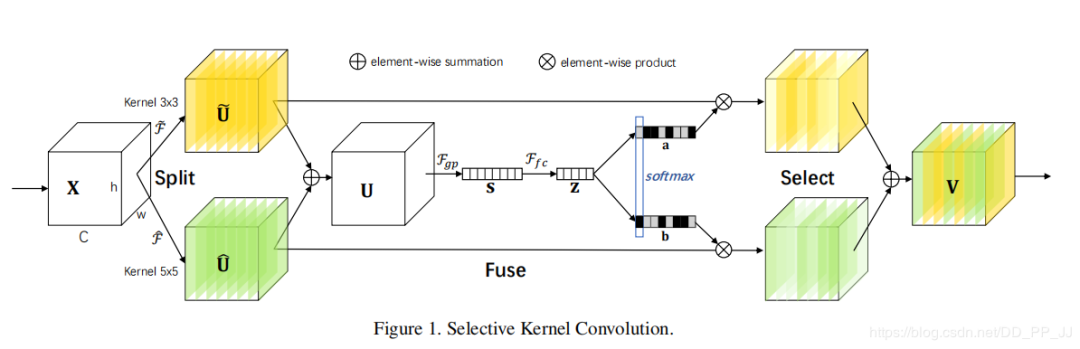
此图为GiantPandaCV公众号作者根据代码重画的网络图
网络主要由Split、Fuse、Select三部分组成。
Split部分是对原特征图经过不同大小的卷积核部分进行卷积的过程,这里可以有多个分支。
对输入X使用不同大小卷积核分别进行卷积操作(图中的卷积核size分别为3x3和5x5两个分支,但是可以有多个分支)。操作包括卷积、efficient grouped/depthwise convolutions、BN。
Fuse部分是计算每个卷积核权重的部分。
将两部分的特征图按元素求和
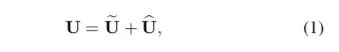
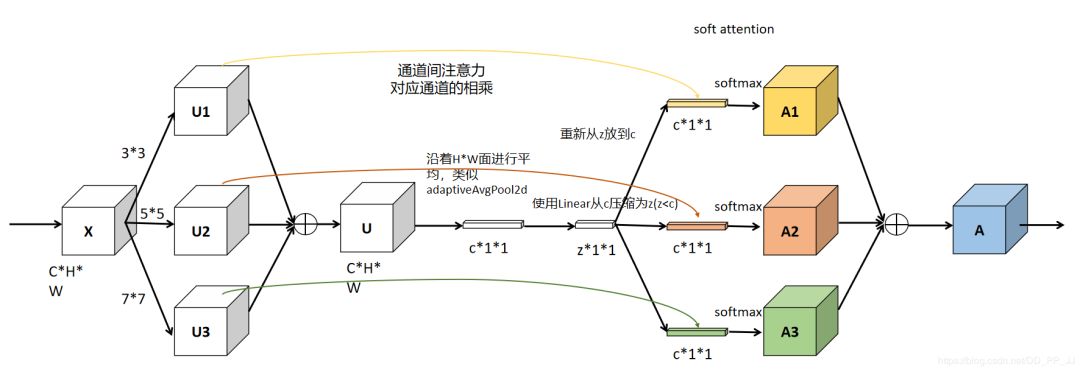
U通过全局平均池化(GAP)生成通道统计信息。得到的Sc维度为C * 1
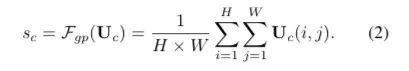
经过全连接生成紧凑的特征z(维度为d * 1), δ是RELU激活函数,B表示批标准化(BN),z的维度为卷积核的个数,W维度为d×C, d代表全连接后的特征维度,L在文中的值为32,r为压缩因子。
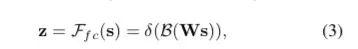
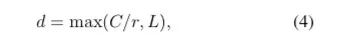
Select部分是根据不同权重卷积核计算后得到的新的特征图的过程。
进行softmax计算每个卷积核的权重,计算方式如下图所示。如果是两个卷积核,则 ac + bc = 1。z的维度为(d * 1)A的维度为(C * d),B的维度为(C * d),则a = A x z的维度为1 * C。
Ac、Bc为A、B的第c行数据(1 * d)。ac为a的第c个元素,这样分别得到了每个卷积核的权重。
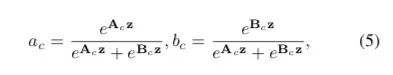
将权重应用到特征图上。其中V = [V1,V2,...,VC], Vc 维度为(H x W),如果
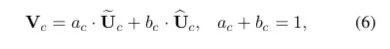
select中softmax部分可参考下图(3个卷积核)
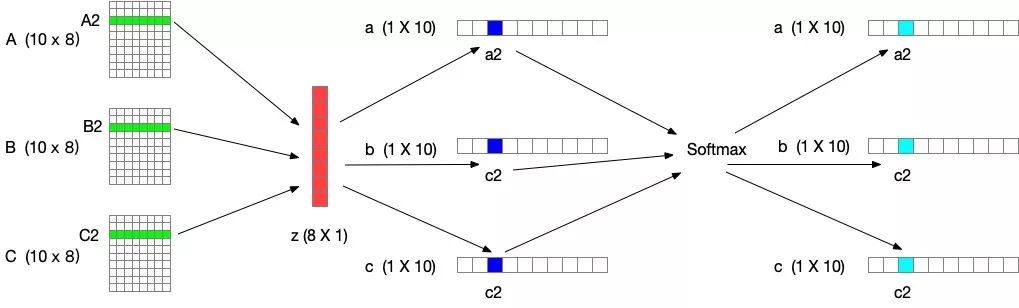
4.5 改进五:ResNeSt
ResNeSt 提出了一种模块化 Split-Attention 块,可以将注意力分散到若干特征图组中。按照 ResNet 的风格堆叠这些 Split-Attention 块,研究者得到了一个 ResNet 的新变体,称为 ResNeSt。它保留了整体的 ResNet 结构,可直接用于下游任务,但没有增加额外的计算量。主要是基于 SENet,SKNet 和 ResNeXt,把 attention 做到 group level。
论文地址:https://hangzhang.org/files/resnest.pdf
项目地址:https://github.com/zhanghang1989/ResNeSt
 特征图组(Feature-map Group)
与 ResNeXt 块一样,输入的特征图可以根据通道维数被分为几组,特征图组的数量由一个基数超参数 K 给出,得到的特征图组被称为基数组(cardinal group)。研究者引入了一个新的底数超参数 R,该参数规定了基数组的 split 数量。
然后将块输入 X 根据通道维数 X = {X1, X2, ...XG} 分为 G = KR 个组。在每个单独的组中应用不同的变换 {F_1, F_2, ...F_G},则每个组的中间表征为 Ui = Fi(Xi), i ∈ {1, 2, ...G}。
基数组中的 Split Attention
根据 [30,38],每个基数组的组合表征可以通过跨多个 split 的元素求和融合来获得。第 k 个基数组的表征为:
特征图组(Feature-map Group)
与 ResNeXt 块一样,输入的特征图可以根据通道维数被分为几组,特征图组的数量由一个基数超参数 K 给出,得到的特征图组被称为基数组(cardinal group)。研究者引入了一个新的底数超参数 R,该参数规定了基数组的 split 数量。
然后将块输入 X 根据通道维数 X = {X1, X2, ...XG} 分为 G = KR 个组。在每个单独的组中应用不同的变换 {F_1, F_2, ...F_G},则每个组的中间表征为 Ui = Fi(Xi), i ∈ {1, 2, ...G}。
基数组中的 Split Attention
根据 [30,38],每个基数组的组合表征可以通过跨多个 split 的元素求和融合来获得。第 k 个基数组的表征为: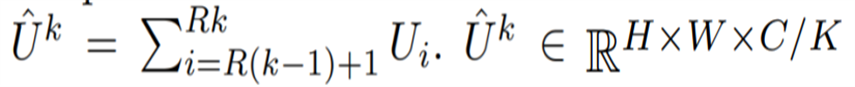 ,k ∈ 1, 2, ...K。带有嵌入 channel-wise 统计数据的全局上下文信息可以通过全局池化来获得。第 c 个分量的计算公式为:
,k ∈ 1, 2, ...K。带有嵌入 channel-wise 统计数据的全局上下文信息可以通过全局池化来获得。第 c 个分量的计算公式为:
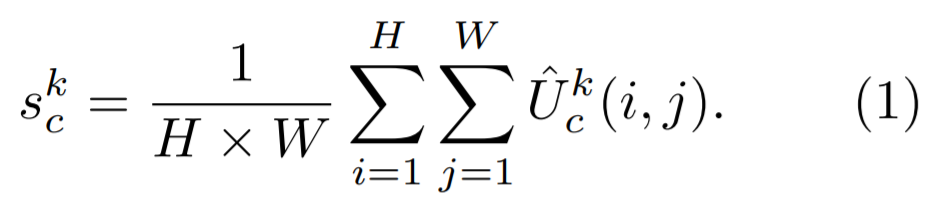 基数组表征 V^k ∈ R^{H×W×C/K} 的加权融合通过使用 channel-wise 软注意力来聚合。其中,每个特征图通道都是在若干 split 上使用一个加权组合获得的。第 c 个通道的计算公式如下:
基数组表征 V^k ∈ R^{H×W×C/K} 的加权融合通过使用 channel-wise 软注意力来聚合。其中,每个特征图通道都是在若干 split 上使用一个加权组合获得的。第 c 个通道的计算公式如下:
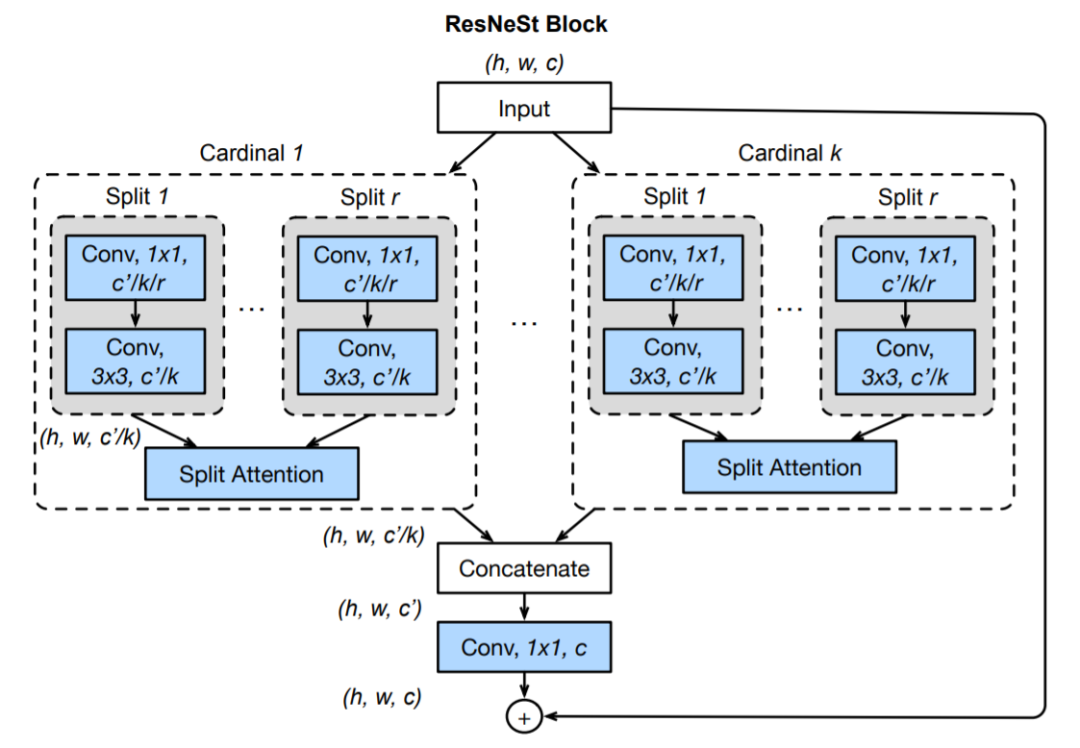
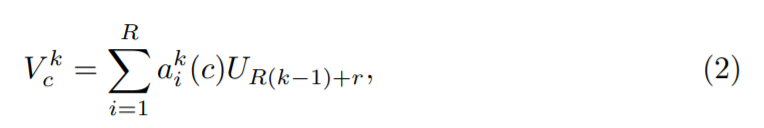 ResNeSt 块
随后,将基数组表征根据通道维数进行级联:V = Concat{V^1 , V^2 , ...V^K}。和标准残差块中一样,如果输入和输出特征图共享相同的形状,则使用快捷连接生成 Split-Attention 块的最终输出 Y,Y = V +X。对于步幅较大的块,将适当的变换 T 应用于快捷连接以对齐输出形状:Y = V + T(X)。T 可以是跨步卷积或带有池化的组合卷积。
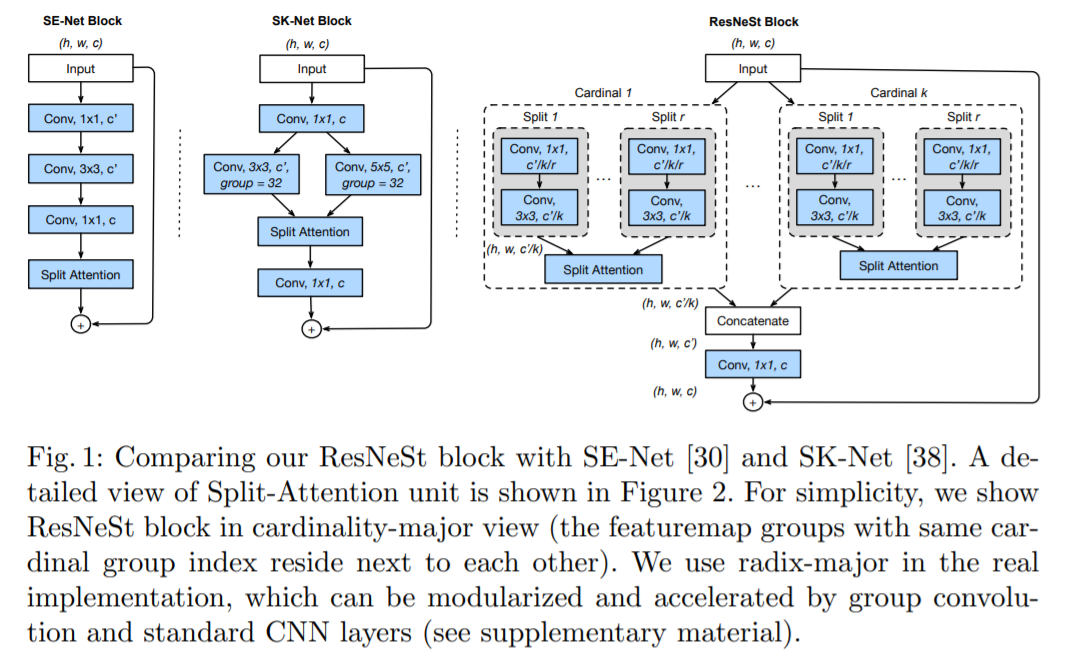
图 1 展示了 ResNeSt 块与 SE-Net 和 SK-Net 块的整体对比。图 1 右为 Split-Attention 块的实例,组变换 F_i 是 1×1 卷积,然后是 3×3 卷积,注意力权重函数 G 使用两个带有 ReLU 激活函数的全连接层进行参数化。
ResNeSt 块
随后,将基数组表征根据通道维数进行级联:V = Concat{V^1 , V^2 , ...V^K}。和标准残差块中一样,如果输入和输出特征图共享相同的形状,则使用快捷连接生成 Split-Attention 块的最终输出 Y,Y = V +X。对于步幅较大的块,将适当的变换 T 应用于快捷连接以对齐输出形状:Y = V + T(X)。T 可以是跨步卷积或带有池化的组合卷积。
图 1 展示了 ResNeSt 块与 SE-Net 和 SK-Net 块的整体对比。图 1 右为 Split-Attention 块的实例,组变换 F_i 是 1×1 卷积,然后是 3×3 卷积,注意力权重函数 G 使用两个带有 ReLU 激活函数的全连接层进行参数化。
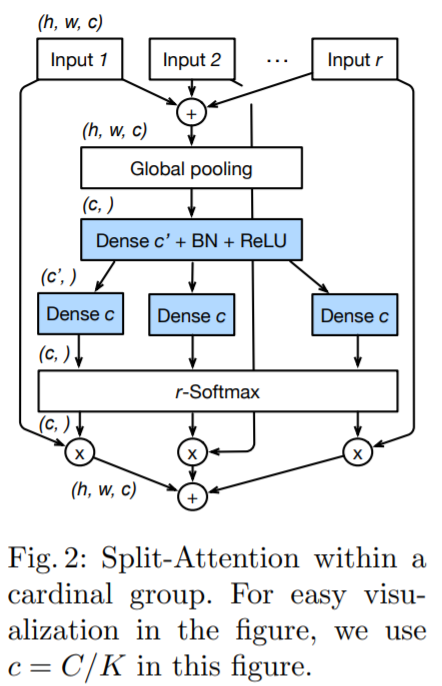
 Split-Attention 的细节可参考图 2。
Split-Attention 的细节可参考图 2。
参考资料:
https://zhuanlan.zhihu.com/p/31852747
https://zhuanlan.zhihu.com/p/40050371
https://zhuanlan.zhihu.com/p/28124810
https://zhuanlan.zhihu.com/p/37820282
https://zhuanlan.zhihu.com/p/47766814
https://zhuanlan.zhihu.com/p/54289848
推荐阅读:
VoVNet:超越ResNet,实时目标检测新backbone
ResNet到底在解决一个什么问题呢?
ResNet最强改进版来了!ResNeSt:Split-Attention Networks

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:AI移动应用-小极-北大-深圳),即可申请加入AI移动应用极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~ 

