
- 1自动驾驶合集5
- 2一)Stable Diffusion使用教程:安装_stable diffusion官网
- 3【2023新书】《ChatGPT在做什么…以及它为什么好使》
- 4微信小程序保留小数点_小程序正则保留三位小数
- 5Servlet的request.getInputStream()只能读取一次问题_测试环境 mono.just() ioutils.tostring(servletrequest.g
- 6App Widgets 详解一 简单使用_小部件 appwidget_enabled
- 7maven核心,pom.xml详解
- 8项目配置集成unocss指南,配合VsCode插件太香了_vscode unocss
- 92021年熔化焊接与热切割免费试题及熔化焊接与热切割考试技巧_焊接作业最常见危害也最广泛的职业危害是什么
- 10openstack 管理 四十一 创建自己的 glance image_虚机镜像制作glance imange
PyTorch实现 Self Attention
赞
踩
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达通过修改SelfAttention的执行逻辑,可以节省大量的激活值显存开销。
这篇文章的消除方法来自于2021年12月10日谷歌放到arxiv上的文章self attention does not need O(n^2) memory. 该方法巧妙地使用了小学学到的加法分配率,将self attention中的固定激活值降到了O(1)的程度。[1]
Self Attention 固定激活值显存分析
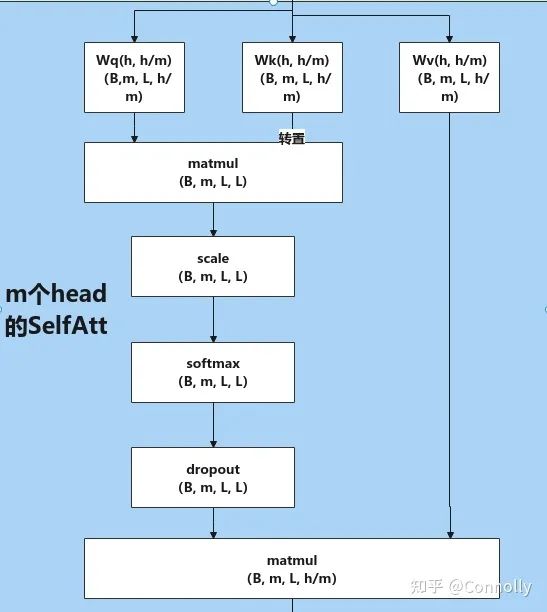
Hugging face Transformers中,SelfAttention 内核实现
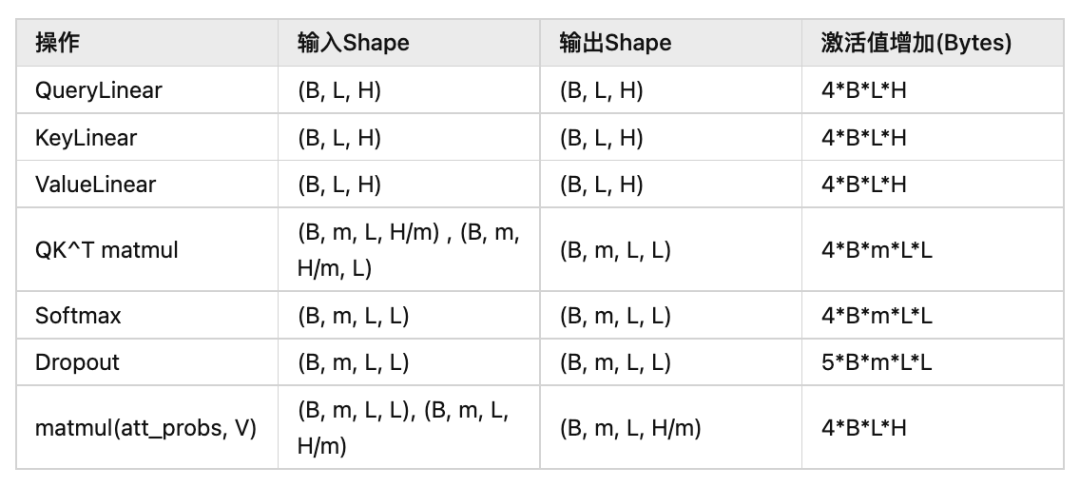
表格中只列举了会实测中产生激活值的操作,其中B为Batch_size,L为sequence_length,H为hidden_size,m为SelfAttention中head的数量。
则总和 。
观察:
当 固定时, 即模型结构是固定的时候, 我们发现激活值是和 线性相关的。
当 变化时, 我们发现会存在一个常数项 , 我称这个常数激活值开销为固定激活值。这个主要是在Query和Key矩阵做乘法, 以及后续的一些操作中生成的。即在 等操作中出现。
SelfAttention 固定激活值显存优化
1. Prerequisites
1.1 Softmax 计算过程
对于向量 表示 中的第 个元素, 那么这个元素的softmax值为:
1.2 SelfAttention计算过程
为了简化计算,我们先忽略掉Scale和Dropout,因为它们都是单操作数的op,这个忽略不会给我们的分析带来影响。考虑最后输出矩阵第i行,第j列的结果,在原始的实现中,他的计算过程为:
, QK的矩阵乘法, 产生Tensor , shape为
维度的Softmax, 产生Tensor , shape为
. Softmax和Value的矩阵乘, 产生最终输出结果, shape为 .
写成伪代码则为:
- """
- inputs: Q[L][H/m], K[L][H/m], V[L][H/m]
- outputs: O[L][H/m]
- matrix A[L][L]=0, S[L][L]=0, O[L][H/m]=0 # 初始化为0矩阵, A,S为中间激活值矩阵
- """
-
- # QK Matmul
- for i in range(L):
- for j in range(L):
- for l in range(H/m):
- A[i][j] += Q[i][l]*Q[l][j]
-
- # Softmax, dim=-1
- for i in range(L):
- temp = 0
- for j in range(L):
- S[i][j] = math.exp(A[i][j])
- temp += S[i][j]
- S[i]/=temp
-
- # OV Matmul
- for i in range(L):
- for j in range(H/m):
- for l in range(L):
- O[i][j] += S[i][l]*Q[l][j]
-
- return O

2. 显存优化
Google采用了一个非常简单的方法来节省Attention核中的大量的显存开销,具体计算过程为:
, QK的矩阵乘法, 但是不单独执行, 直接代入下一个式子。
, 这里没有除以求和值, 而是把除法挪到了下面。
可以发现, 和原来的算法的差别在于把 的计算放到了后面。采用这种方法的好处是, 我 们可以分开计算 和 了。
我们用临时变量 和 来存储这两个值的和, 即
来避开原始的实现中所产生的A和S矩阵。
写成伪代码:
- """
- Inputs: Q[L][H/m], K[L][H/m], V[L][H/m]
- outputs: O[L][H/m]
- matrix O[L][H/m]=0 # 初始化为0矩阵
- """
-
- for i in range(L): # O row, Q row
- sum_s = 0
- for j in range(L): # O column, K^T column, V row
- a_ij = 0
- for k in range(H/m): # Q column, K^T row
- a_ij += Q[i][k]*K[k][j] # Q_i K_j matmul
- a_ij = a_ij / math.sqrt(H) # scale
- s_ij_prime = math.exp(a_ij) # softmax numerator
- sum_s_i += s_prime_ij # softmax denominator of i-th row
- for oj in range(H/m): # broacast along V column axis
- if random.uniform(0,1) > 0.1: # dropout
- O[i][oj] += s_ij_prime * V[j][oj] # attention weight, V matmul
- O[i][:] = O[i][:] / sum_s # attention weight, V matmul
- return O
一个可行的PyTorch api实现,但是效率很低很低,不可能用的。效率想要高估计还是需要用CUDA去写个算子...按照文章的说法,实现的好的话,推断的时候是可以比原始方法要快的,但是就训练而言,这里在后向过程中肯定需要进行丢失信息的重计算,论文里可以预见的会被原始方法慢两倍。
- key_layer = key_layer.transpose(-1, -2)
-
- outputs = torch.zeros([1, self.num_attention_heads, 512, 64])
- for i in range(512): # sequence length
- Qi = torch.narrow(query_layer, 2, i, 1) # (1, 16, 1, 64)
- sum_s = torch.zeros([1, self.num_attention_heads, 1, 1])
- outputs_i = torch.narrow(outputs, 2, i, 1) # (1, 16, 1, 64)
-
- for j in range(512):
- Kj = torch.narrow(key_layer, 3, j, 1) # (1, 16, 64, 1)
- A_ij = torch.matmul(Qi, Kj) / math.sqrt(self.attention_head_size) # (1, 16, 1, 1)
- s_ij_prime = torch.exp(A_ij)
- sum_s.add(s_ij_prime)
- V_j = torch.narrow(value_layer, 2, j, 1) # (1, 16, 1, 64) jth_row
- if random.uniform(0,1) > 0.1:
- outputs_i.add(s_ij_prime.mul(V_j)) # (1, 16, 1, 64)
- outputs_i.div(sum_s)
-
- outputs = outputs.permute(0, 2, 1, 3).contiguous()
- outputs_shape = outputs.size()[
- :-2] + (self.all_head_size,)
- outputs = outputs.view(*outputs_shape)
这个实现增加的显存约为 , 相比 来说已经减少了很多了,拿Bert-Large举例,他的L=512, H=1024,在B等于1的时候,原始实现中每个selfattention的matmul等操作核会产生52MB的显存,改良后则会产生2MB的显存,太顶了。考虑到Bert-Large有24层,这一下就去掉了1.2GB/sample的显存,真的是舒服哇。
不想写CUDA又想要提升性能的话,可以考虑narrow的时候多取几行或者几列,跟GPU的核数对应上应该比较合适(文章里是4096,也忒大了),然后换成einsum的张量乘法实现可调整遍历窗口大小的优化方法。
总结
这个方法跟原始方法在逻辑上是等价的,而且计算复杂度也是一致的。
显存开销极大降低,根据实现的方法,最低是可以到O(1)的,但是为了速度考虑可以适当调整每次narrow出来的size来提高GPU利用率。文章中显存开销是 .
使用的时候需要注意在计算指数的时候可能会存在的溢出问题(这个原始实现里也有),因此文章里面的实现在做指数运算前减去了最大的A_ij值。
收敛性相同,且在训练小Transformer时有4个百分点的速度提升。
需要在Backward的时候重计算丢失掉的信息,这里可能会影响到dropout,所以dropout的结果我猜肯定在前向的时候是不能被丢弃的。
推理系统的福音,可以调整并降低中间产生的激活值峰值,同时保证一定的推理速度。
参考
^self attention does not need O(n^2) memory https://arxiv.org/abs/2112.05682
- 下载1:OpenCV-Contrib扩展模块中文版教程
-
- 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
-
-
- 下载2:Python视觉实战项目52讲
- 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
-
-
- 下载3:OpenCV实战项目20讲
- 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
-
-
- 交流群
-
- 欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

