
- 1积极人生/The Seven Habits of Highly Effective People_7 key habits感想
- 2python制作ico图标_使用PyInstaller工具,把Python程序打包EXE可执行文件
- 303.14 @ 深圳丨网易智企 X 垦丁律所,娱乐社交行业城市沙龙再起航
- 4[OpenHarmony RK3568](四)WIFI芯片适配_sdio_pwrseq
- 5linux表示文件类型,linux文件类型说明
- 6Android JNI静态注册和动态注册方法详解
- 7npm run dev命令的执行顺序和原理
- 8全国计算机竞赛能保送清华北大吗,2020这些人将被保送至清华北大!
- 9基于微信小程序的实验室教室会议室预约系统源码_图书会议室小程序
- 105.鸿蒙hap可以直接点击包安装吗?_hap包不能直接安装嘛
金融业运维数据中台需求来源及灵魂_数据运维需求
赞
踩
一、运维工作现状介绍
运维工作既与需要运维的平台采用的技术息息相关,也与运维工具的发展息息相关,还与运维服务的用户相关。
运维对象从早期烟囱式的技术架构发展到以x86为主的架构,再到现在大量采用的微服务、云原生的架构,以及大数据、机器学习技术平台,运维对象发生了剧烈的变化。
运维工具从早期的基础设施监控,发展到日志监控,再到现在的应用性能监控(APM),可观察性监控。
运维面向的用户也从早期的以企业内部用户为主,发展到了以企业提供线上服务的用户为主。
二、运维数据中台需求来源:运维工作面临的问题
由于运维对象、运维工具、运维需求的快速变化,导致金融机构有少则几套监控工具,多则数十套监控工具,而这些监控工具通常是在不同时期建设的,所以他们之间往往数据没有打通,技术栈也有较大的区别,形成了一座座运维数据的孤岛。
运维人员日常需要在众多的监控工具之间切换来切换去,导致故障的发现困难,故障的定位耗时耗力,故障的解决重复劳动,无法形成有效的知识积累。并且以前基于固定阈值的告警规则无法满足海量监控指标的设置和管理,需要将人工智能技术与运维工作结合到一起。随着智能运维(AIOps)的快速发展,机器学习的算法、模型等对运维数据的规范化提出了更高的要求。
所以现在迫切需要一套以各种监控工具生成的数据为源头,以统一的运维数据管理体系为规范,可以支撑运维数据的编排、AIOps算法编排和各类运维数据关联分析的运维数据中台,来采集各种各样的运维数据,经过清洗转换提供给AIOps的场景来使用。
伴随知识图谱技术在各行各业的广泛应用,在运维行业,各种运维实体(包括硬件实体和软件服务等)和他们之间的关系也可以构建成运维知识图谱,运用图算法、知识推理和机器学习技术来进行关联分析和根因定位等。
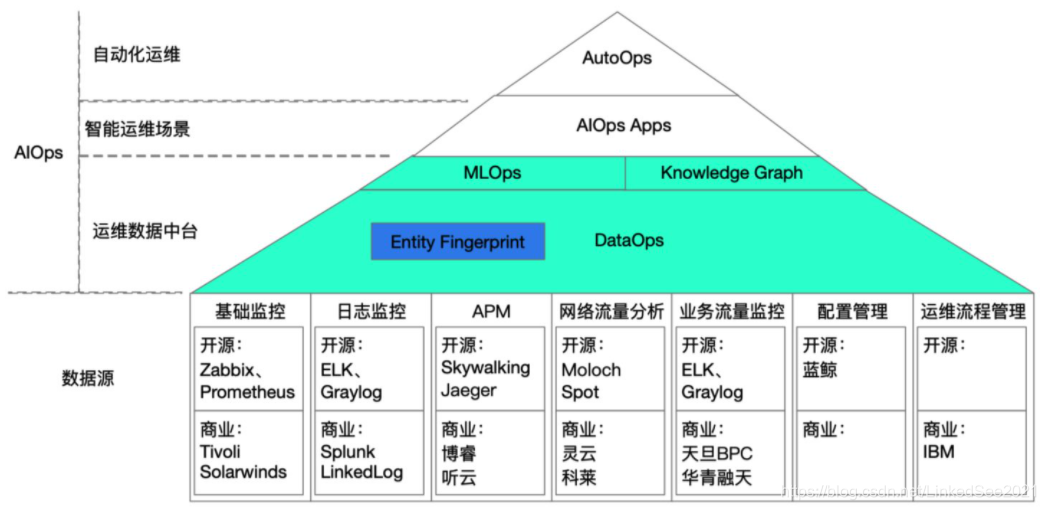
如果用一个简单的公式来概括的话,AIOps = DataOps + MLOps + KG + AIOps Apps + AutoOps,Ops在这里指的是编排的意思。
DataOps: 巧妇难为无米之炊,刀功再好只用豆腐也做不出来真正的红烧肉,数据才是基础。DataOps指的是将运维数据通过各种各样的编排,提供给AIOps使用。
MLOps: 指的是将算法流程进行编排,例如日志异常检测流程可以分为格式解析、日志聚合、异常检测等步骤,每一步又可以使用不同的算法,这样通过不同的排列组合仅日志异常检测算法就可以有数十种。
KG: Konwleage Graph,指的是知识图谱,通过知识图谱将各种各样的运维数据关联起来,来给数据平台和算法平台提供一套关联逻辑,以及使用图算法和因果发现来推导根因。

AIOps Apps: 指的是各种各样的智能运维场景,包括指标异常检测、日志异常检测、告警降噪、根因分析等。
AutoOps: 指的是自动化运维,如果智能运维最后判断出的根因在知识库中有对应的故障解决方案和自动化操作步骤,那么自动化运维就可以产生作用,迅速修复故障。
最后把这些组件整合起来,结合一整套面向运维的数据治理体系,就形成了AIOps平台。
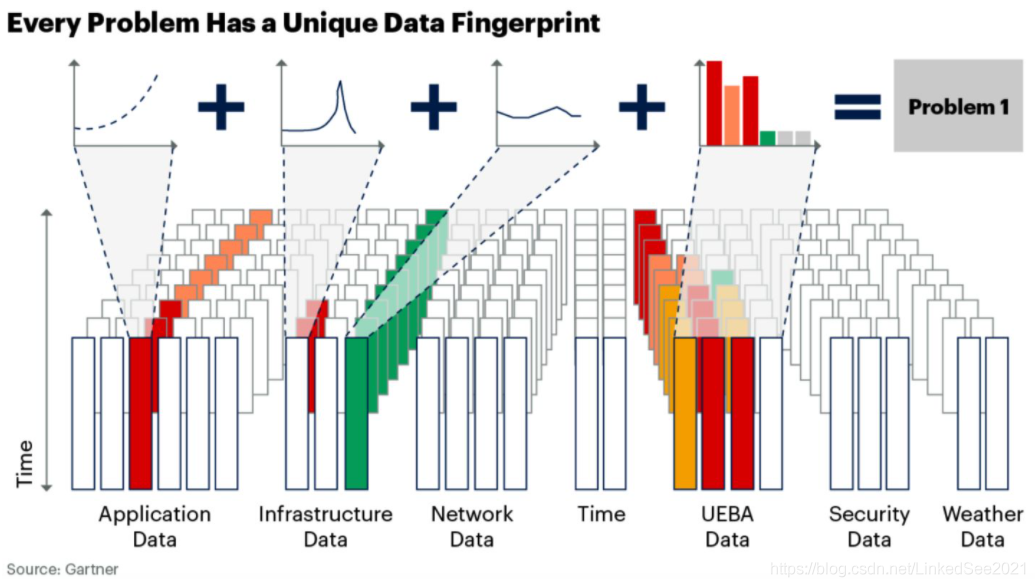
Entity Fingerprint:可以理解为国内通常所说的运维画像,Gartner称之为data fingerprint(数据指纹),有了数据指纹就可以定位一个具体的故障事件。这里所说的数据指纹不局限于一种单一的运维数据,包括多种时序运维数据组合而成的指纹,例如指标、日志、tracing、告警等。
三、灵魂:基于标签的运维数据命名空间管理体系
运维数据包括了指标、日志、事件等基本数据,另外随着云原生/可观察性概念和AIOps的发展,也包含了Tracing数据、软硬件知识图谱等数据。
让我们从一个问题开始对运维数据的思考,下图中service_1_http_requests_total和service_2_http_requests_total共同组成了服务的总流量,那么当增加了一个新的服务service_3的时候服务的总流量如何计算?我们需要重新修改总流量的定义吗?这不合理,既不符合敏捷的原则,也满足不了日新月异的软件架构变化。
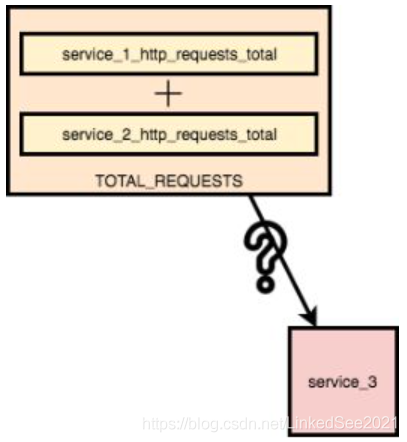
让我们用命名空间来解决上面的问题,如下图:
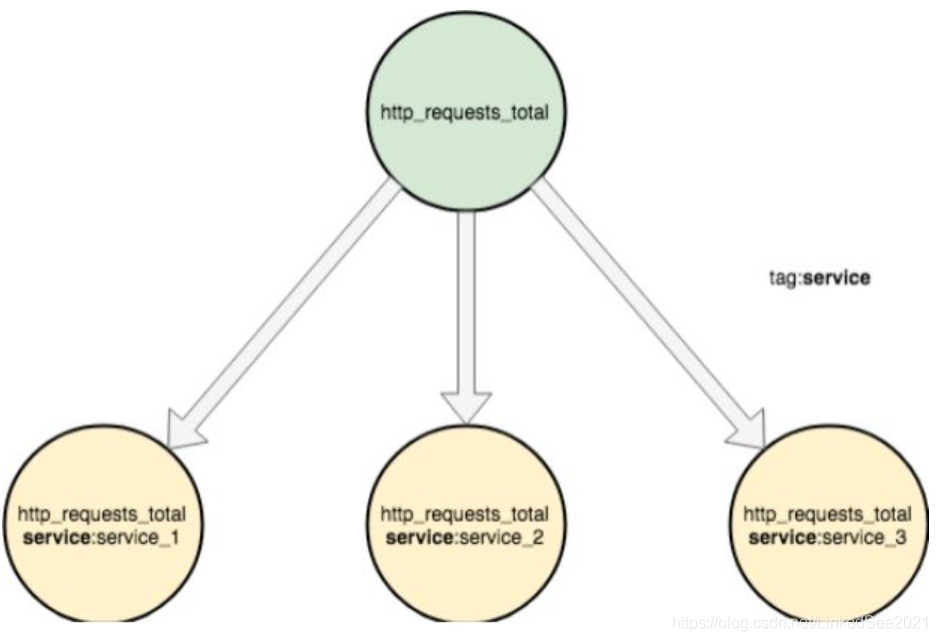
所有包含标签service的指标汇总成了服务的总流量。同时通过标签的命名空间也支持查看特定子集的明细数据:如在灰度机器上所有成功http请求的p99(p99表示过去10秒内最慢的1%请求)延迟是多少,见下图:
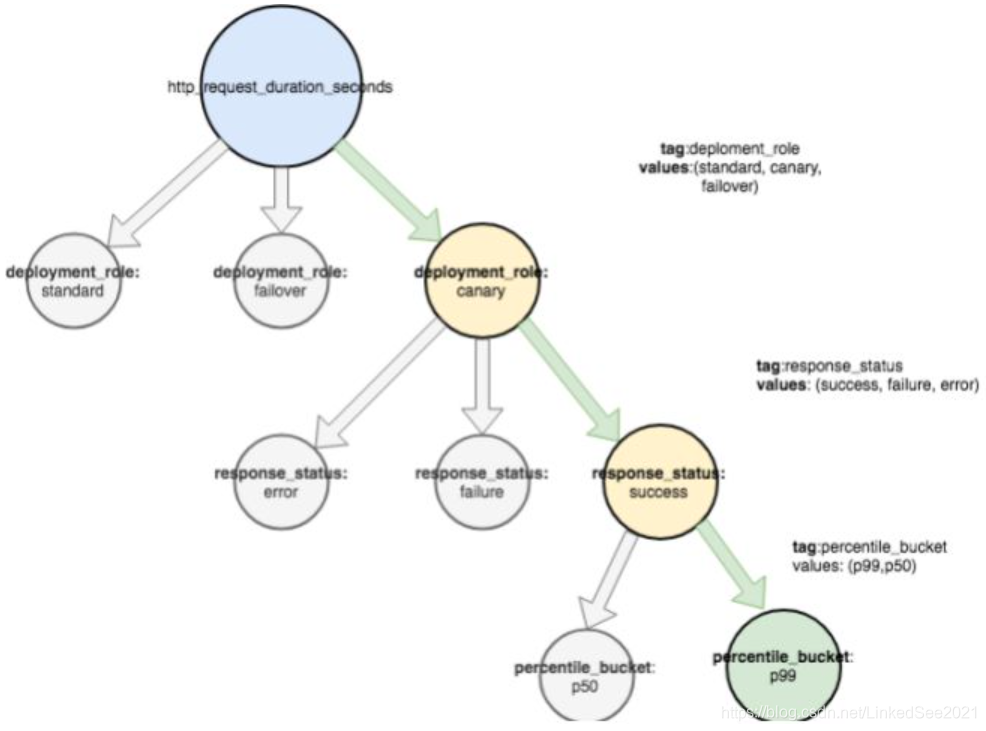
对应数据的标签表达式为 deployment_role=“canary”, response_status=“success”,percentile_bucket=p99 。
相信关注云原生的同学会发现这套体系与Prometheus和Grafana关系密切,如果说运维数据中台中的大数据组件是骨骼的话,那么运维数据管理体系就是灵魂。
通常对运维数据的标签管理体系介绍到这里就结束了,但实际上我们在AIOps的实施过程中,碰到的问题远不止运维数据的管理,在AIOps算法模型管理时我们也借鉴了标签体系。
参考:
https://medium.com/dm03514-tech-blog/sre-observability-metric-namespaces-and-structures-12ffcf5a5bdc
Gartner
Google

