
- 1基于Putty的Linux远程登录教程(Windows系统,虚拟机)_putty远程连接ssh
- 2DataTable转相应的实体对象_datatable转对象
- 3快过年了,整理一波2023年技术文章合集,一键打包
- 4十六进制的转换为十进制两种常见方法_十六进制转十进制方法
- 5【目标检测】45、YOLOv3 | 针对小目标效果提升的 YOLO 网络_yolov3大目标和小目标
- 6交换机vlan什么意思_工业以太网交换机的光口和电口是什么意思?
- 7kubernetes和kubersphere的关系_kubesphere
- 8linux运维进阶-基于RHCS+iSCSI+CLVM实现Web服务的共享存储集群架构
- 9Android中自定义Textview解决文字和数字换行不整齐_textview 换行对齐
- 10Google Play上架总结(三)Google Play 上架流程_谷歌上架分发商品
Apache Doris实时数据分析保姆级使用教程
赞
踩
点击上方蓝色字体,选择“设为星标”
回复"面试"获取更多惊喜

Doris安装
集群部署
官网下载地址:
https://doris.apache.org/zh-CN/downloads/downloads.html
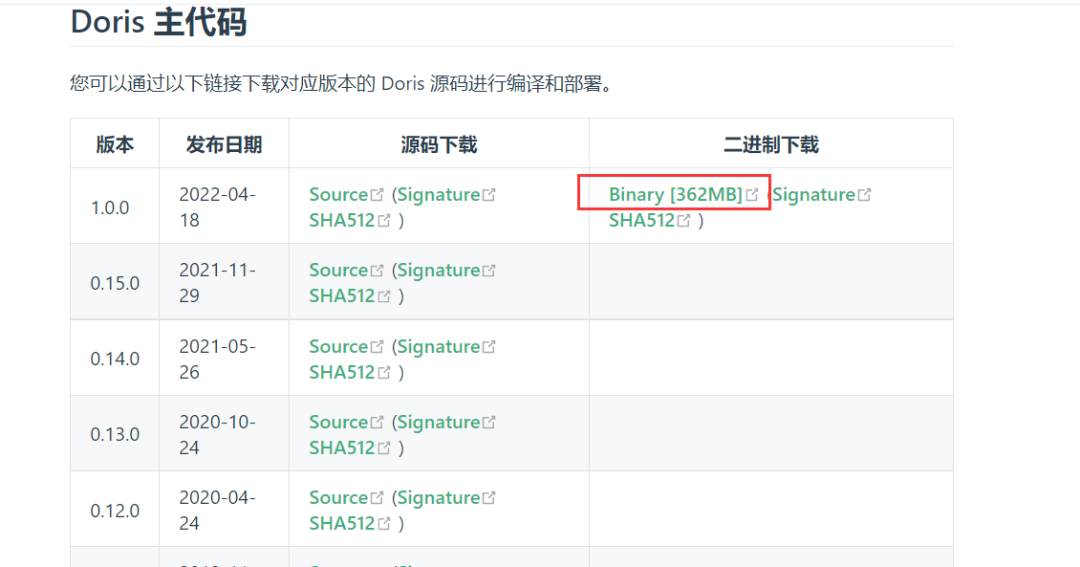
选择二进制下载,源码下载需要自己编译。解压doris文件:
tar -zxvf apache-doris-1.0.0-incubating-bin.tar.gz -C /opt/module/
集群规划

FE部署
修改配置文件vim conf/fe.conf
meta_dir = /opt/module/doris-meta

集群中分发存储路径和FE配置文件,启动FE。
- # 创建meta文件夹存储路径
- mkdir /opt/module/doris-meta
- # 三台机器都要执行
- sh bin/start_fe.sh --daemon
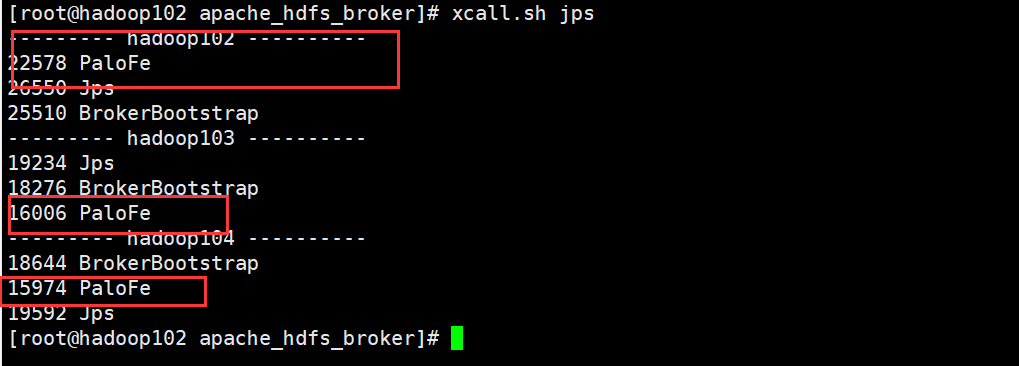
BE部署
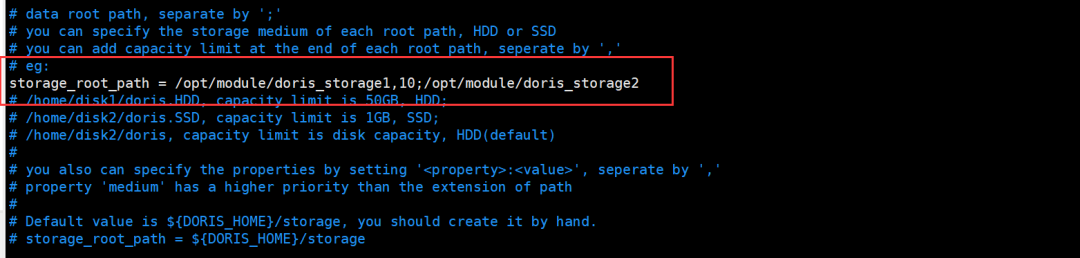
修改配置文件vim conf/be.conf
- # storage_root_path配置存储目录,可以用;来指定多个目录,每个目录后可以跟逗号,指定大小默认GB
- storage_root_path = /opt/module/doris_storage1,10;/opt/module/doris_storage2
集群中分发存储路径和BE配置文件,启动BE
- # 创建storage_root_path存储路径
- mkdir /opt/module/doris_storage1
- mkdir /opt/module/doris_storage2
- # 三台机器都要执行
- sh bin/start_be.sh --daemon

访问Doris PE节点
doris可以使用mysql客户端访问,如果未安装,则需要安装mysql-client。
- # 第一次访问不需要密码,可以自行设置密码
- mysql -hdoris1 -P 9030 -uroot
- # 修改密码
- set password for 'root' = password('root');
添加BE节点
通过mysql客户端登入后,添加be节点,port为be上的heartbeat_service_port端口,默认9050
- mysql> ALTER SYSTEM ADD BACKEND "hadoop102:9050";
- mysql> ALTER SYSTEM ADD BACKEND "hadoop103:9050";
- mysql> ALTER SYSTEM ADD BACKEND "hadoop104:9050";
通过mysql客户端,检测be节点状态,alive必须为true
mysql> SHOW PROC '/backends';
BROKER部署
可选,非必须部署,启动BROKER
- # 三台集群都要启动
- sh bin/start_broker.sh --daemon
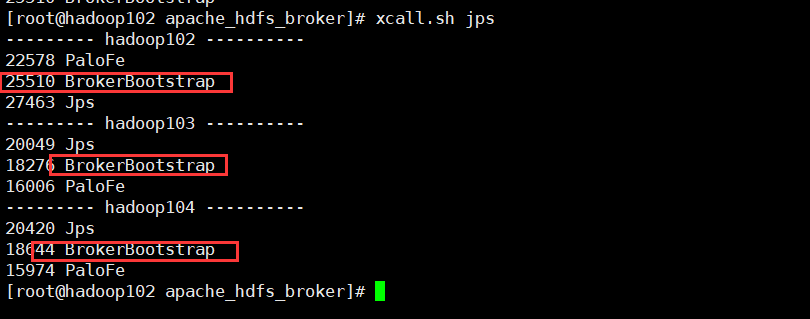
使用mysql客户端访问pe,添加broker节点
mysql> ALTER SYSTEM ADD BROKER broker_name "hadoop102:8000","hadoop103:8000","hadoop104:8000";查看broker状态
mysql> SHOW PROC "/brokers";扩容缩容
Doris可以很方便的扩容和缩容FE、BE、Broker实例。通过页面访问进行监控,访问8030,账户为root,密码默认为空不用填写,除非上述设置了密码使用密码登录http://hadoop102:8030
FE 扩容和缩容
FE 节点的扩容和缩容过程,不影响当前系统运行。
使用mysql登录客户端后,可以使用sql命令查看FE状态,目前就一台FE。
mysql> SHOW PROC '/frontends';
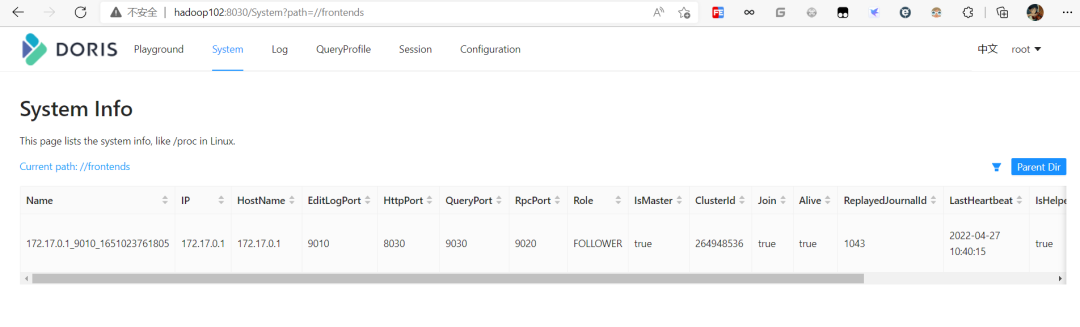
增加FE节点,FE分为Leader,Follower和Observer三种角色。默认一个集群只能有一个Leader,可以有多个Follower和Observer.其中Leader和Follower组成一个Paxos选择组,如果Leader宕机,则剩下的Follower会成为Leader,保证HA。Observer是负责同步Leader数据的不参与选举。如果只部署一个FE,则FE默认就是Leader
第一个启动的FE自动成为Leader。在此基础上,可以添加若干Follower和Observer。添加Follower或Observer。使用mysql-client连接到已启动的FE,并执行:在doris2部署Follower,doris3上部署Observer
- # 执行其中的一个即可,注解如下
- # follower/observer_host IP节点位置
- # edit_log_port fe.conf配置文件中可以查询到
-
- # ALTER SYSTEM ADD FOLLOWER "follower_host:edit_log_port";
- ALTER SYSTEM ADD FOLLOWER "hadoop103:9010";
- # ALTER SYSTEM ADD OBSERVER "observer_host:edit_log_port";
- ALTER SYSTEM ADD OBSERVER "hadoop104:9010";
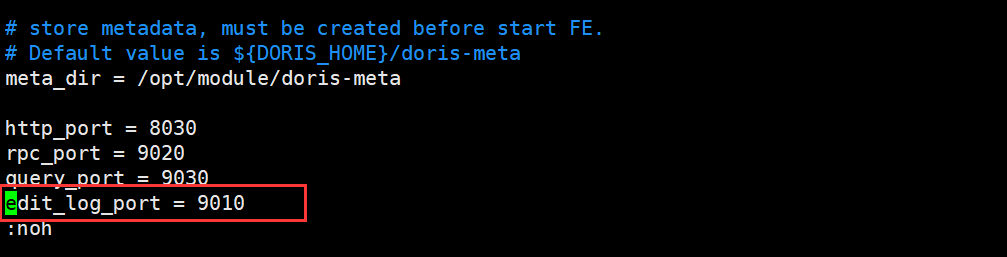
需要重启配置节点的FE,并添加如下参数启动
- # --helper参数指定leader地址和端口号
- sh bin/start_fe.sh --helper hadoop102:9010 --daemon
- sh bin/start_fe.sh --helper hadoop102:9010 --daemon
全部启动完毕后,再通过mysql客户端,查看FE状况
mysql> SHOW PROC '/frontends';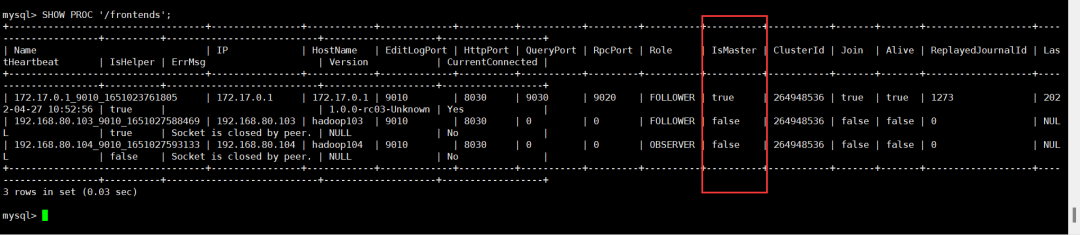
使用以下命令删除对应的FE节点ALTER SYSTEM DROP FOLLOWER[OBSERVER] "fe_host:edit_log_port";删除Follower FE时,确保最终剩余的Follower(包括 Leader)节点为奇数
- ALTER SYSTEM DROP FOLLOWER "hadoop103:9010";
- ALTER SYSTEM DROP OBSERVER "hadoop104:9010";
BE 扩容和缩容
增加BE节点,就像上面安装一样在mysql客户端,使用ALTER SYSTEM ADD BACKEND
删除BE节点,使用ALTER SYSTEM DROP BACKEND "be_host:be_heartbeat_service_port";
具体文档请查看官网。
Doris操作手册
创建用户
- # 连接doris
- mysql -hhadoop102 -P 9030 -uroot
- # 创建用户
- mysql> create user 'test' identified by 'test';
- # 退出使用test即可登录
- mysql> exit;
- mysql -hhadoop102 -P 9030 -utest -ptest
表操作
- # 创建数据库
- mysql> create database test_db;
- # 赋予test用户test库权限
- mysql> grant all on test_dn to test;
- # 使用数据库
- mysql> use test_db;
分区表
分区表分为单分区和复合分区
单分区表,建立一张student表。分桶列为id,桶数为10,副本数为1
- CREATE TABLE student
- (
- id INT,
- name VARCHAR(50),
- age INT,
- count BIGINT SUM DEFAULT '0'
- )
- AGGREGATE KEY (id,name,age)
- DISTRIBUTED BY HASH(id) buckets 10
- PROPERTIES("replication_num" = "1");
复合分区表,第一级称为Partition,即分区。用户指定某一维度列做为分区列(当前只支持整型和时间类型的列),并指定每个分区的取值范围。第二级称为Distribution,即分桶。用户可以指定一个或多个维度列以及桶数进行HASH分布
- #创建student2表,使用dt字段作为分区列,并且创建3个分区发,分别是:
- #P202007 范围值是是小于2020-08-01的数据
- #P202008 范围值是2020-08-01到2020-08-31的数据
- #P202009 范围值是2020-09-01到2020-09-30的数据
- CREATE TABLE student2
- (
- dt DATE,
- id INT,
- name VARCHAR(50),
- age INT,
- count BIGINT SUM DEFAULT '0'
- )
- AGGREGATE KEY (dt,id,name,age)
- PARTITION BY RANGE(dt)
- (
- PARTITION p202007 VALUES LESS THAN ('2020-08-01'),
- PARTITION p202008 VALUES LESS THAN ('2020-09-01'),
- PARTITION p202009 VALUES LESS THAN ('2020-10-01')
- )
- DISTRIBUTED BY HASH(id) buckets 10
- PROPERTIES("replication_num" = "1");

复合分区表,第一级称为Partition,即分区。用户指定某一维度列做为分区列(当前只支持整型和时间类型的列),并指定每个分区的取值范围。第二级称为Distribution,即分桶。用户可以指定一个或多个维度列以及桶数进行HASH分布.
- #创建student2表,使用dt字段作为分区列,并且创建3个分区发,分别是:
- #P202007 范围值是是小于2020-08-01的数据
- #P202008 范围值是2020-08-01到2020-08-31的数据
- #P202009 范围值是2020-09-01到2020-09-30的数据
- CREATE TABLE student2
- (
- dt DATE,
- id INT,
- name VARCHAR(50),
- age INT,
- count BIGINT SUM DEFAULT '0'
- )
- AGGREGATE KEY (dt,id,name,age)
- PARTITION BY RANGE(dt)
- (
- PARTITION p202007 VALUES LESS THAN ('2020-08-01'),
- PARTITION p202008 VALUES LESS THAN ('2020-09-01'),
- PARTITION p202009 VALUES LESS THAN ('2020-10-01')
- )
- DISTRIBUTED BY HASH(id) buckets 10
- PROPERTIES("replication_num" = "1");
数据模型
AGGREGATE KEY
AGGREGATE KEY相同时,新旧记录将会进行聚合操作
AGGREGATE KEY模型可以提前聚合数据,适合报表和多维度业务
UNIQUE KEY
UNIQUE KEY相同时,新记录覆盖旧记录。目前UNIQUE KEY和AGGREGATE KEY的REPLACE聚合方法一致。适用于有更新需求的业务。
DUPLICATE KEY
只指定排序列,相同的行并不会合并。适用于数据无需提前聚合的分析业务
数据导入
为适配不同的数据导入需求,Doris系统提供5种不同的导入方式。每种导入方式支持不同的数据源,存在不同的方式(异步、同步)
Broker load
Broker load是一个导入的异步方式,支持的数据源取决于Broker进程支持的数据源
基本原理:用户在提交导入任务后,FE(Doris系统的元数据和调度节点)会生成相应的PLAN(导入执行计划,BE会执行导入计划将输入导入Doris中)并根据BE(Doris系统的计算和存储节点)的个数和文件的大小,将Plan分给多个BE执行,每个BE导入一部分数据。BE在执行过程中会从Broker拉取数据,在对数据转换之后导入系统。所有BE均完成导入,由FE最终决定是否导入是否成功。
测试导入HDFS数据到Doris
编写测试文件,上传到HDFS.
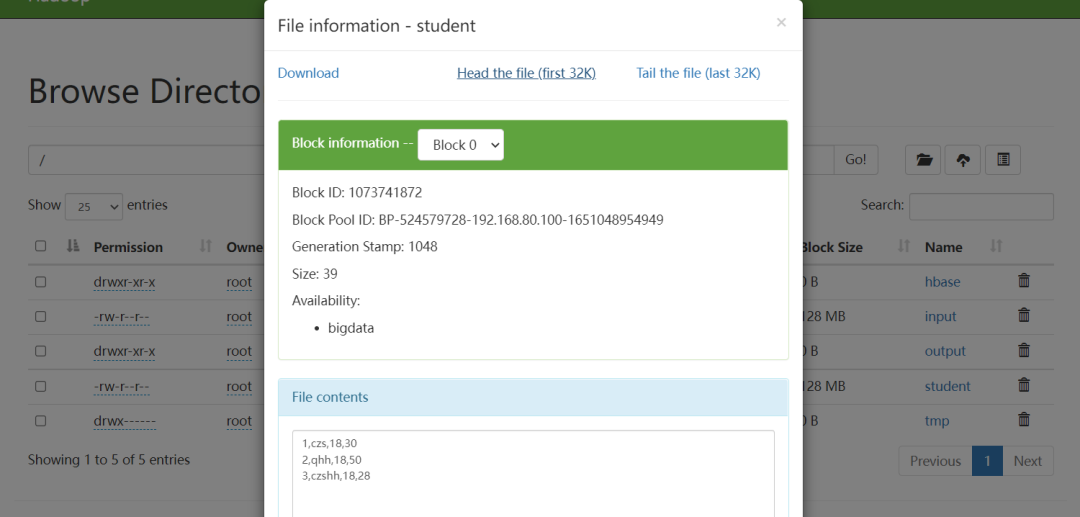
创建doris表,测试导入
- CREATE TABLE student
- (
- id INT,
- name VARCHAR(50),
- age INT,
- count BIGINT SUM DEFAULT '0'
- )
- AGGREGATE KEY (id,name,age)
- DISTRIBUTED BY HASH(id) buckets 10
- PROPERTIES("replication_num" = "1");
编写diros导入sql,更多参数请看官网
- LOAD LABEL test_db.label1
- (
- DATA INFILE("hdfs://bigdata:8020/student")
- INTO TABLE student
- COLUMNS TERMINATED BY ","
- (id,name,age,count)
- SET
- (
- id=id,
- name=name,
- age=age,
- count=count
- )
- )
- WITH BROKER broker_name
- (
- "username"="root"
- )
- PROPERTIES
- (
- "timeout" = "3600"
- );
查看doris导入状态
- use test_db;
- show load;

查看数据导入是否成功
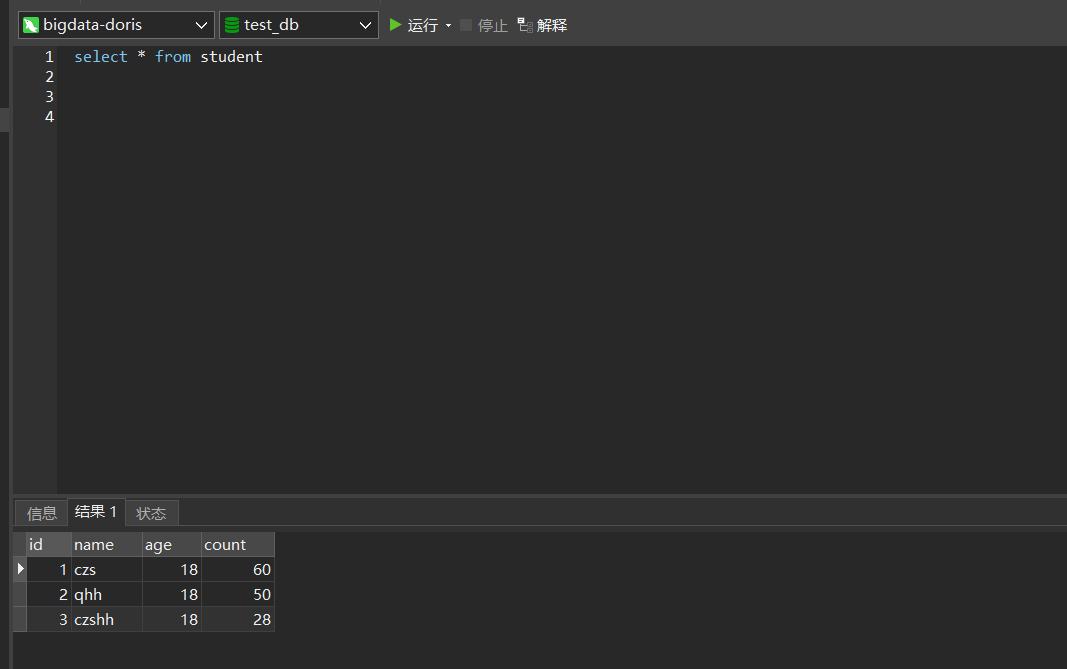
Routine Load
例行导入(Routine Load)功能为用户提供了一种自动从指定数据源进行数据导入的功能
从Kafka导入数据到Doris
创建kafka主题
kafka-topics.sh --zookeeper bigdata:2181 --create --replication-factor 1 --partitions 1 --topic test启动kafka生产者生产数据
- kafka-console-producer.sh --broker-list bigdata:9092 --topic test
-
- # 数据格式
- {"id":"4","name":"czsqhh","age":"18","count":"50"}
在doris中创建对应表
- CREATE TABLE kafka_student
- (
- id INT,
- name VARCHAR(50),
- age INT,
- count BIGINT SUM DEFAULT '0'
- )
- AGGREGATE KEY (id,name,age)
- DISTRIBUTED BY HASH(id) buckets 10
- PROPERTIES("replication_num" = "1");
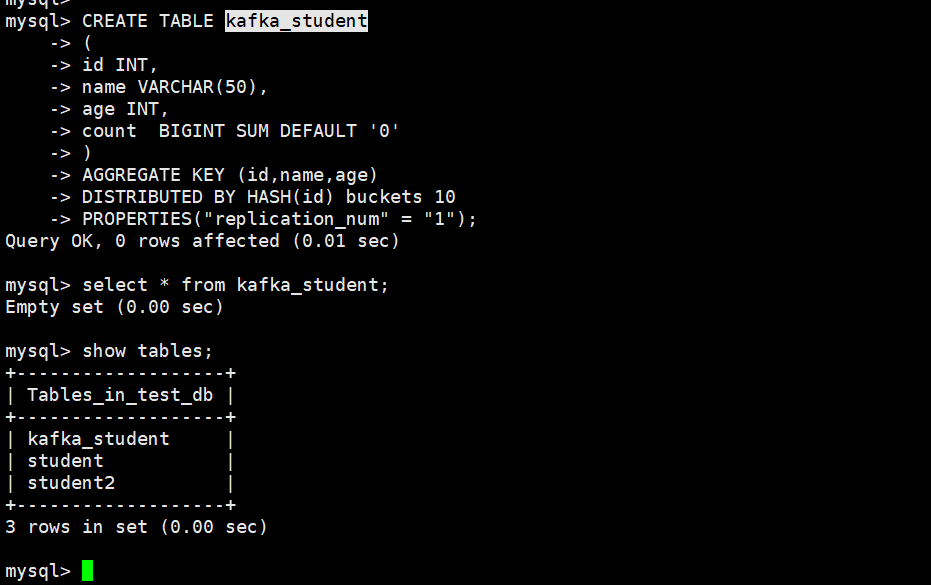
创建导入作业,desired_concurrent_number指定并行度
- CREATE ROUTINE LOAD test_db.job1 on kafka_student
- PROPERTIES
- (
- "desired_concurrent_number"="1",
- "strict_mode"="false",
- "format"="json"
- )
- FROM KAFKA
- (
- "kafka_broker_list"= "bigdata:9092",
- "kafka_topic" = "test",
- "property.group.id" = "test"
- );
查看作业状态
SHOW ROUTINE LOAD;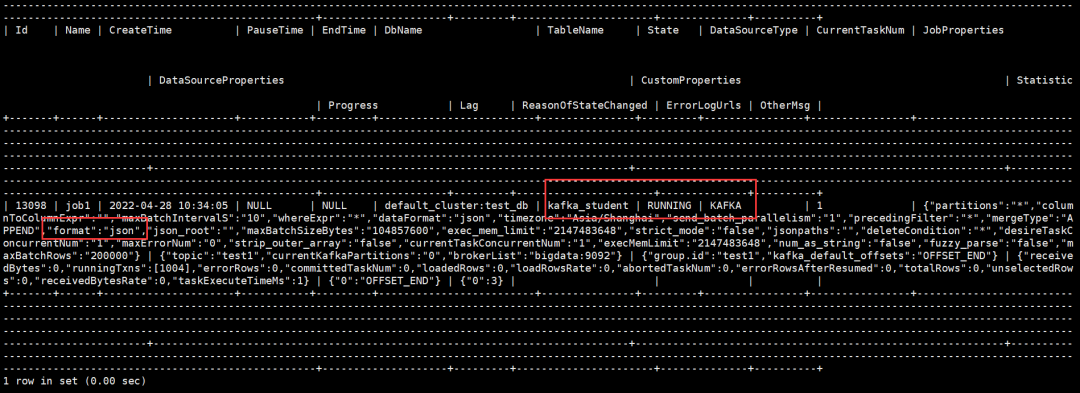
控制作业
- STOP ROUTINE LOAD For jobxxx :停止作业
- PAUSE ROUTINE LOAD For jobxxx:暂停作业
- RESUME ROUTINE LOAD For jobxxx:重启作业
数据导出
Drois导出数据到HDFS
其他参数详见官网
- EXPORT TABLE test_db.student
- PARTITION (student)
- TO "hdfs://bigdata:8020/doris/student/"
- WITH BROKER broker_name
- (
- "username" = "root"
- );
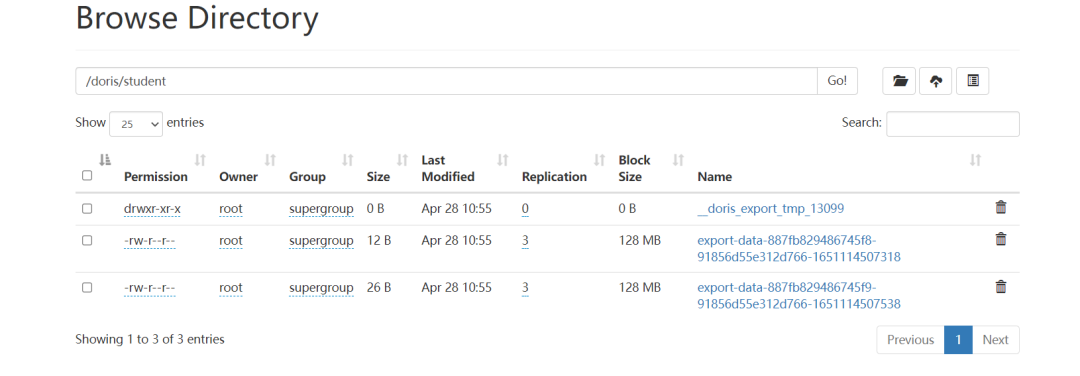
Doris代码操作
Spark
引入依赖
- <dependencies>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-core_2.12</artifactId>
- <version>3.0.0</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-yarn_2.12</artifactId>
- <version>3.0.0</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-sql_2.12</artifactId>
- <version>3.0.0</version>
- </dependency>
-
- <dependency>
- <groupId>mysql</groupId>
- <artifactId>mysql-connector-java</artifactId>
- <version>5.1.27</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-hive_2.12</artifactId>
- <version>3.0.0</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.hive</groupId>
- <artifactId>hive-exec</artifactId>
- <version>1.2.1</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-streaming_2.12</artifactId>
- <version>3.0.0</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
- <version>3.0.0</version>
- </dependency>
- <dependency>
- <groupId>com.fasterxml.jackson.core</groupId>
- <artifactId>jackson-core</artifactId>
- <version>2.10.1</version>
- </dependency>
- <!-- https://mvnrepository.com/artifact/com.alibaba/druid -->
- <dependency>
- <groupId>com.alibaba</groupId>
- <artifactId>druid</artifactId>
- <version>1.1.10</version>
- </dependency>
- </dependencies>
读取doris数据
- object ReadDoris {
- def main(args: Array[String]): Unit = {
- val sparkConf = new SparkConf().setAppName("testReadDoris").setMaster("local[*]")
- val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
-
- val df = sparkSession.read.format("jdbc")
- .option("url", "jdbc:mysql://bigdata:9030/test_db")
- .option("user", "root")
- .option("password", "root")
- .option("dbtable", "student")
- .load()
-
- df.show()
-
- sparkSession.close();
- }
-
- }
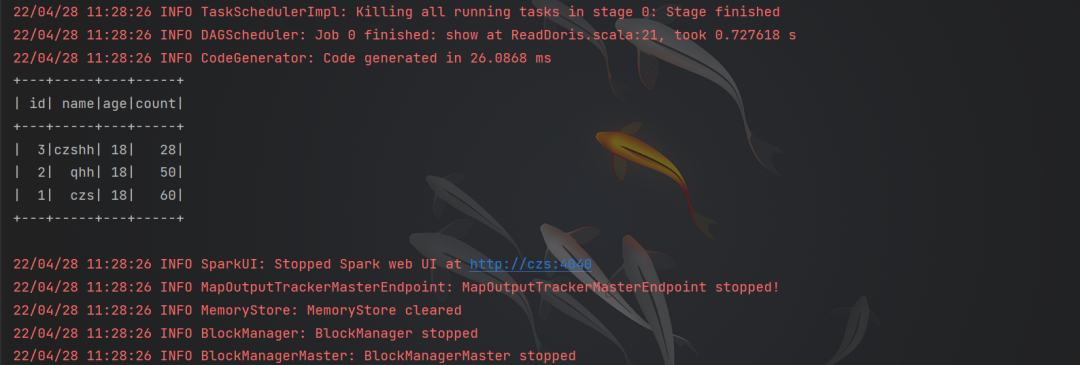
Flink
引入依赖
- <dependencies>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-java</artifactId>
- <version>1.14.3</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-streaming-java_2.12</artifactId>
- <version>1.14.3</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-clients_2.12</artifactId>
- <version>1.14.3</version>
- </dependency>
-
- <dependency>
- <groupId>org.projectlombok</groupId>
- <artifactId>lombok</artifactId>
- <version>1.18.16</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-connector-kafka_2.12</artifactId>
- <version>1.14.3</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-connector-elasticsearch7_2.12</artifactId>
- <version>1.14.3</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.bahir</groupId>
- <artifactId>flink-connector-redis_2.12</artifactId>
- <version>1.1-SNAPSHOT</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-table-api-java-bridge_2.12</artifactId>
- <version>1.14.3</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-table-planner_2.12</artifactId>
- <version>1.14.3</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-table-common</artifactId>
- <version>1.14.3</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-csv</artifactId>
- <version>1.14.3</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-connector-jdbc_2.12</artifactId>
- <version>1.14.3</version>
- </dependency>
- <dependency>
- <groupId>mysql</groupId>
- <artifactId>mysql-connector-java</artifactId>
- <version>8.0.23</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-connector-kafka_2.12</artifactId>
- <version>1.14.3</version>
- </dependency>
-
- </dependencies>
读取数据
- public static void main(String[] args) {
- EnvironmentSettings settings = EnvironmentSettings.newInstance().inBatchMode().build();
- TableEnvironment tEnv = TableEnvironment.create(settings);
-
- String sourceSql = "CREATE TABLE student (\n" +
- "`id` Integer,\n" +
- "`name` STRING,\n" +
- "`age` Integer\n" +
- ")WITH (\n" +
- "'connector'='jdbc',\n" +
- "'url' = 'jdbc:mysql://bigdata:9030/test_db',\n" +
- "'username'='root',\n" +
- "'password'='root',\n" +
- "'table-name'='student'\n" +
- ")";
- tEnv.executeSql(sourceSql);
-
- Table table = tEnv.sqlQuery("select * from student");
- table.execute().print();
- }
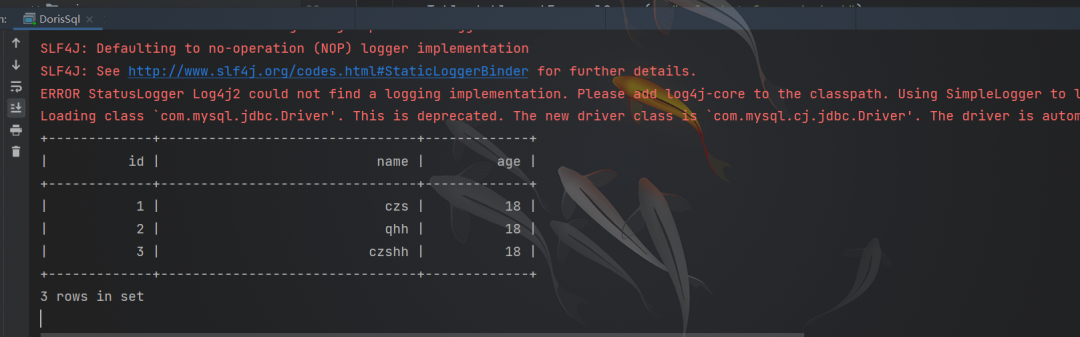
如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!


2022年全网首发|大数据专家级技能模型与学习指南(胜天半子篇)
Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点

