
热门标签
热门文章
- 1Apache2.4 + PHP 5.5 源码编译安装_apache2.4.59编译源码安装configure: warning: *** lua 5.4
- 2对标车载驾舱OMS(Occupant Monitoring System)_oms 监控 occupation
- 3MySQL:VIEW视图
- 415、Drools自然语言DSL,DSLR的说明——6.4版本_dsl dslr
- 5Python爬虫入门实战,图文详细教学,一看就懂_python爬虫开发从入门到实战
- 6【数据库】postgressql设置数据库执行超时时间_pg 慢sql 设置
- 7深度分析:智算中心建设 - GPU选型_智算中心如何配置
- 8OCCT使用指南:Visualization
- 9揭秘百度快照劫持的原因以及解决技巧_zblog0day漏洞
- 10linux-Nginx-arm的编译安装步骤详解_nginx arm
当前位置: article > 正文
hadoop3.3.0完全分布式安装_hadoop 3.3.0 tar.gz
作者:我家小花儿 | 2024-07-31 23:01:44
赞
踩
hadoop 3.3.0 tar.gz
hadoop集群
1. 安装:
1.1 安装工具准备:
jdk_1.8(已经安装完毕)
hadoop_3.3.0 (压缩包)
虚拟机安装:vim (查看配置文件带有高亮)
yum install vim -y
- 1
1.2 集群规划:
| hadoop1 | hadoop2 | hadoop3 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
1.3 配置虚拟机
- 修改虚拟机名(可自定义):
vim /etc/hostname
- 1

- 配置/etc/hosts(配置虚拟机之间的映射文件):
vim /etc/hosts
- 1

虚拟机配置完成(别忙着去克隆)
1.4 hadoop配置:
1. 上传压缩包:
可利用xshell,SecureCRT,FileZilla等工具上传。
2. 解压:
可以自由选择文件夹,有人习惯创建一个soft文件夹去安装软件,有人喜欢在opt中安装,看自己选择
tar -zxvf hadoop-3.3.0.tar.gz
- 1
我的安装目录:

3. 配置hadoop环境变量:
vim /etc/profile.d/my_env.sh
- 1
添加:(注意HADOOP_HOME后面跟的是自己的安装目录)
export HADOOP_HOME=/opt/hadoop/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 1
- 2

生效环境变量:
source /etc/profile
- 1
4. 验证
hadoop
- 1
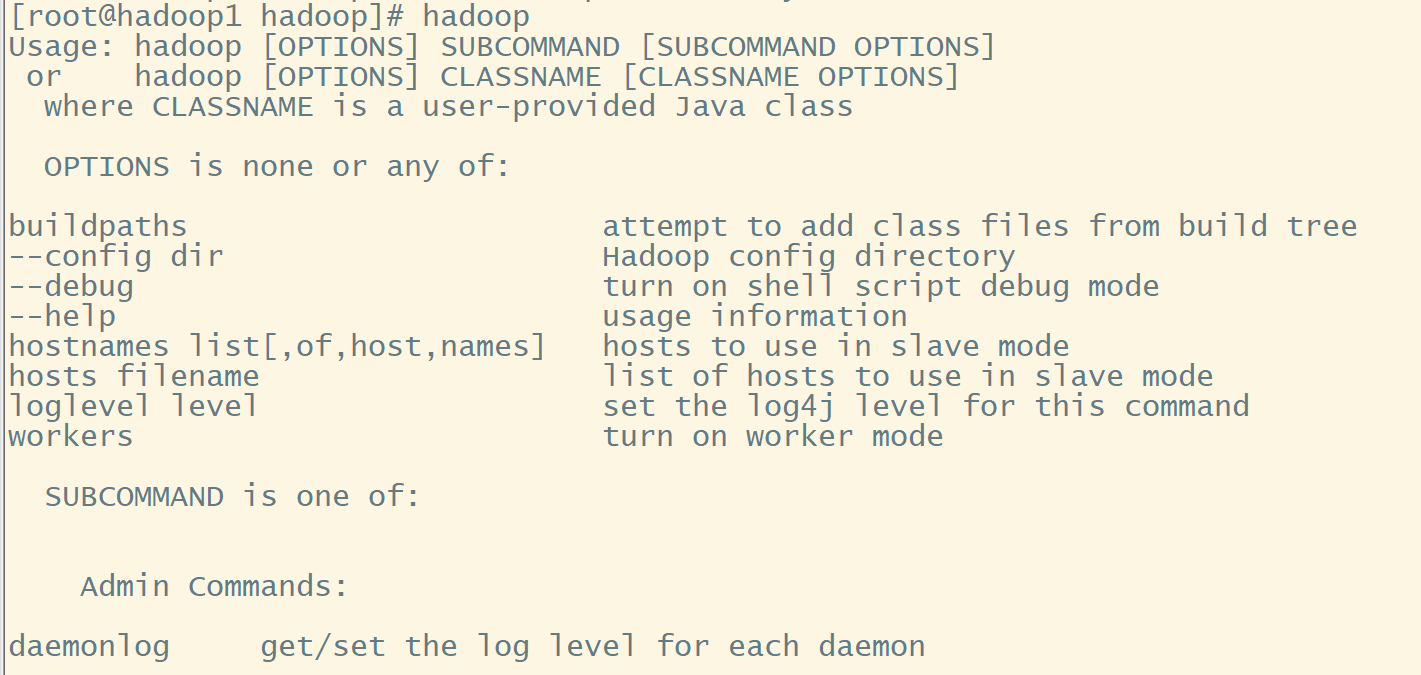
弹出一堆信息则成功!
5. 创建hadoop备用文件夹:
根据自己的安装目录进行
mkdir /opt/hadoop/hadoop_data
mkdir /opt/hadoop/hadoop_data/tmp
mkdir /opt/hadoop/hadoop_data/var
mkdir /opt/hadoop/hadoop_data/dfs
mkdir /opt/hadoop/hadoop_data/dfs/name
mkdir /opt/hadoop/hadoop_data/dfs/data
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
6. 创建分发脚本
功能:进行文件的分发
位置:/root/bin
cd /root/bin
vim xsync
- 1
- 2
- 3
#!/bin/bash if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #注意,如果你的主机名命名和我不一样,下面这三个更换成你自己的主机名 for host in hadoop1 hadoop2 hadoop3 do echo ================= $host ================= for file in $@ do if [ -e $file ] then pdir=$(cd -P $(dirname $file); pwd) fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
7. 克隆虚拟机
根据自己的虚拟机所分配的地址,修改三台虚拟机的/etc/hosts中的ip地址,以及/etc/hostname中的主机名
8. 免密登录
ssh-keygen -t rsa
- 1
一直回车到结束
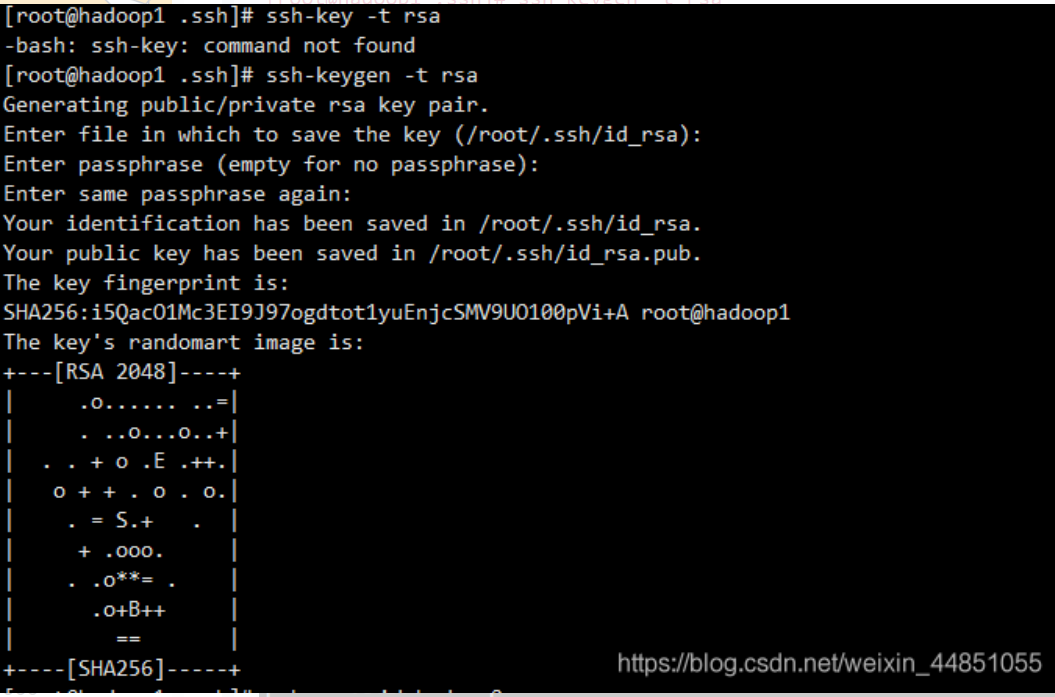
分发公钥:(hostname改为自己的主机命名)
ssh-copy-id hostname
- 1
三台虚拟机都分发。
1.5. hadoop环境配置
所有路径配置都得和自己虚拟机的一致
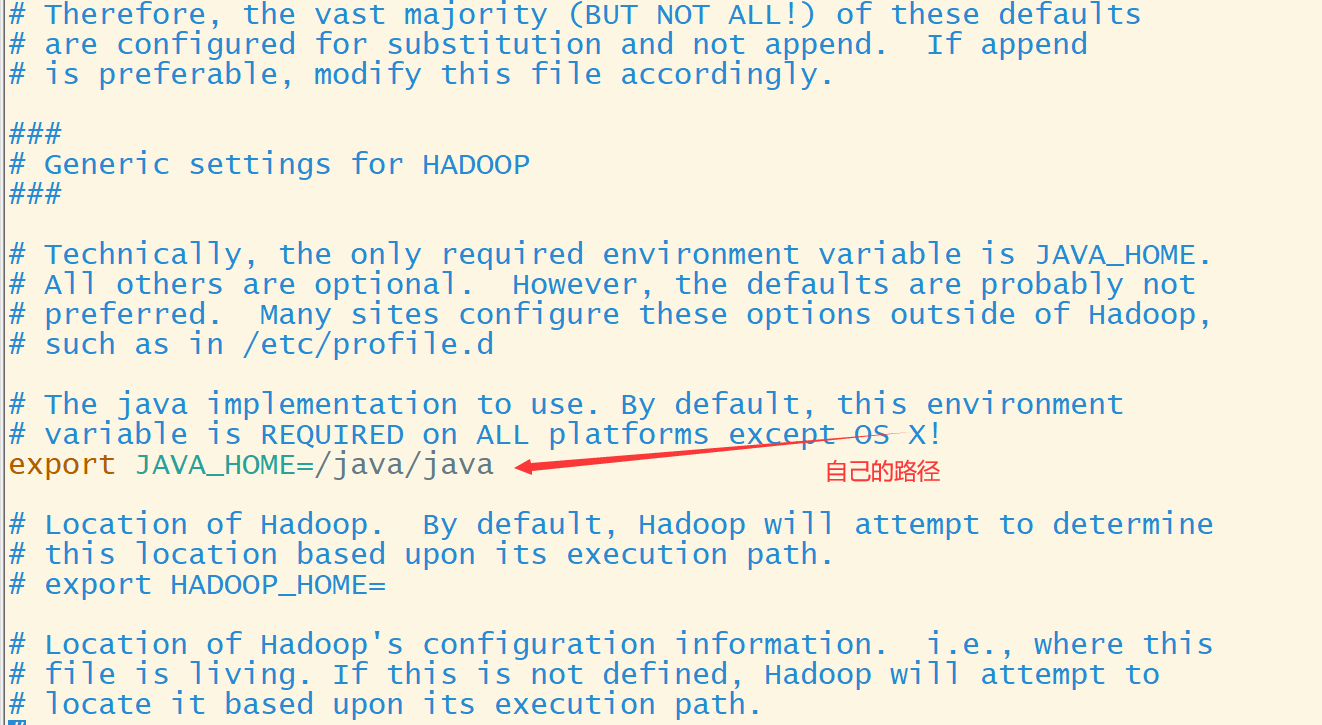
1. 配置jdk路径:
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
- 1
2. 修改hdfs-site.xml
cd $HADOOP_HOME/etc/hadoop/
vim hdfs-site.xml
- 1
- 2
- 3
在 中间添加:
<!-- 指定NameNode的web端访问地址 --> <property> <name>dfs.namenode.http-address</name> <value>hadoop1:9870</value> </property> <!-- 设置SecondaryNameNode(2NN)的web端访问地址 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop3:9868</value> </property> <property> <name>dfs.name.dir</name> <value>/opt/hadoop/hadoop_data/dfs/name</value> <description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description> </property> <property> <name>dfs.data.dir</name> <value>/opt/hadoop/hadoop_data/dfs/data</value> <description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.permissions</name> <value>true</value> <description>need not permissions</description> </property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36

3. 复制,修改mapred-site.xml
cp mapred-site.xml mapred-site.xml.template
vim mapred-site.xml
- 1
- 2
- 3
同样在中添加内容:
<!-- 指定MapReduce程序运行在Yarn上的地址 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hadoop1:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/opt/hadoop/hadoop_data/var</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4. 配置yarn-site.xml
vim yarn-site.xml
- 1
<!-- 指定MapReduce走shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop2</value> </property> <property> <description>The address of the applications manager interface in the RM.</description> <name>yarn.resourcemanager.address</name> <value>${yarn.resourcemanager.hostname}:8032</value> </property> <property> <description>The address of the scheduler interface.</description> <name>yarn.resourcemanager.scheduler.address</name> <value>${yarn.resourcemanager.hostname}:8030</value> </property> <property> <description>The http address of the RM web application.</description> <name>yarn.resourcemanager.webapp.address</name> <value>${yarn.resourcemanager.hostname}:8088</value> </property> <property> <description>The https adddress of the RM web application.</description> <name>yarn.resourcemanager.webapp.https.address</name> <value>${yarn.resourcemanager.hostname}:8090</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>${yarn.resourcemanager.hostname}:8031</value> </property> <property> <description>The address of the RM admin interface.</description> <name>yarn.resourcemanager.admin.address</name> <value>${yarn.resourcemanager.hostname}:8033</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>2048</value> <discription>每个节点可用内存,单位MB,默认8182MB</discription> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>2048</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
5. 配置core-site.xml
vim core-site.xml
- 1
<property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop/hadoop_data/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.default.name</name> <!-- hadoop1的内网IP地址 --> <value>hdfs://hadoop1:9000</value> </property> <!-- 指定NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop1:8020</value> </property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
6. 配置workers
vim workers
- 1
必须和图中格式一致:顶格,换行;主机名称后面不准有空格

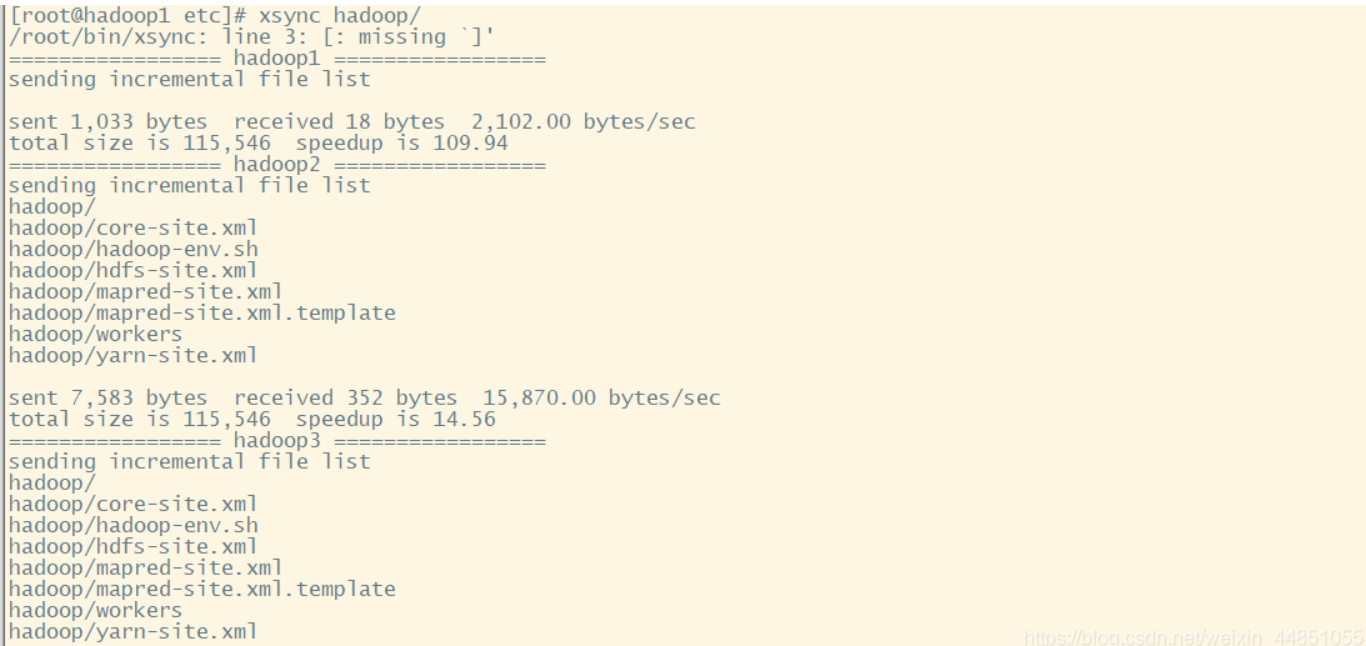
7. 分发配置
cd ..
# 分发的是整个配置文件,这样上述6个步骤就不用去重复两次了
xsync hadoop/
- 1
- 2
- 3
8. 修改sbin配置
cd ../sbin
- 1
修改start-dfs.sh,以及stop-dfs.sh,
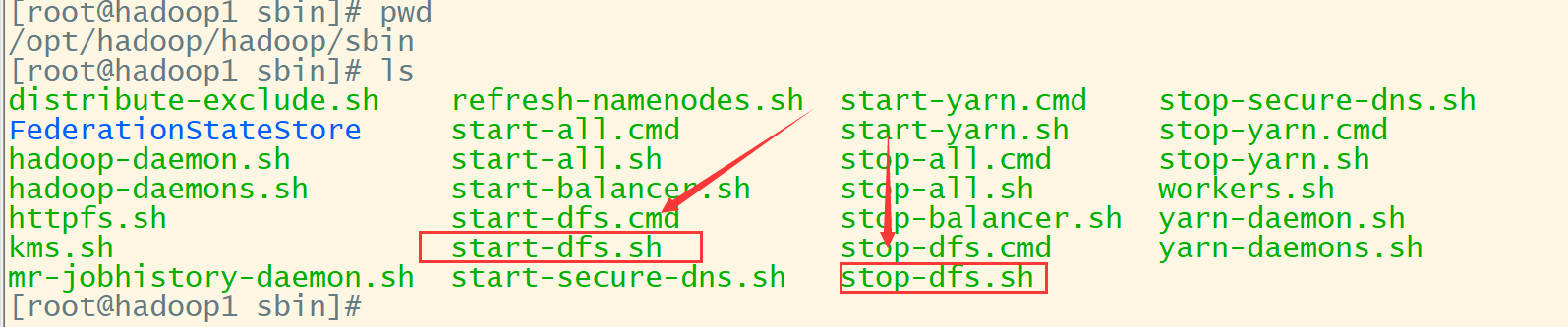
在这两个文件的开头加上以下配置
HDFS_DATANODE_USER=root
HADOOP_SECURE_SECURE_USER=root
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
- 1
- 2
- 3
- 4
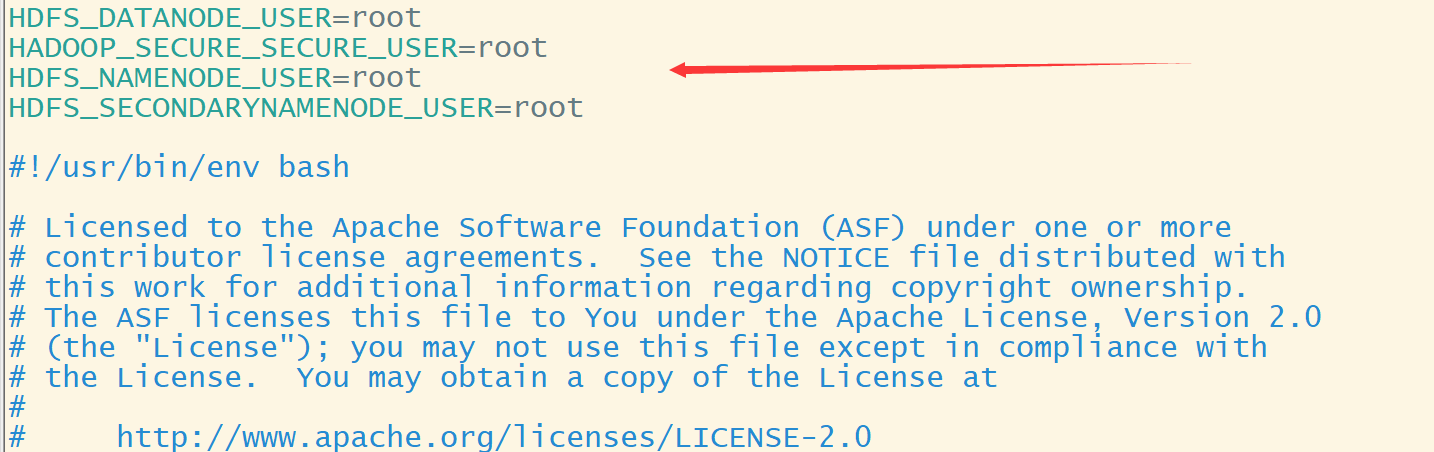
修改start-yarn.sh,以及stop-yarn.sh

同样,在这两个文件的开头加上以下配置
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=root
YARN_NODEMANAGER_USER=root
- 1
- 2
- 3
再次分发
#再次分发已配置的配置文件到hadoop2,hadoop3
cd ..
xsync sbin/
- 1
- 2
- 3
- 4
hadoop集群搭建到此结束!
1.6. 启动
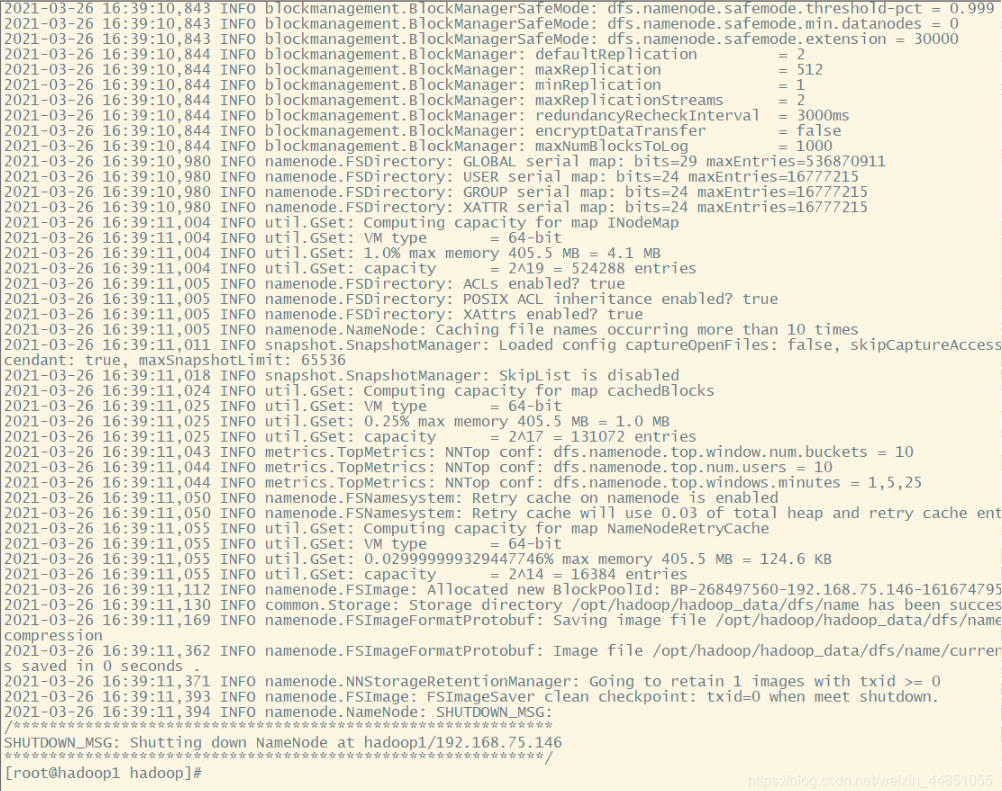
1. 首次启动
需要初始化hadoop的namenode
hadoop namenode -format
- 1
根据开始时的配置
hadoop1—hdfs
hadoop2—yarn
hadoop3----从节点
# 在hadoop1中输入:
start-dfs.sh
# 在hadoop2中输入:
start-yarn.sh
#查看结果
jps
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
hadoop1中:

hadoop2中:

hadooop3中:

如果是用start-all.sh,需要在hadoop1和hadoop2中都输入。
2. 查看网页
如果上述结果都输出成功,就可以到浏览器中查看网页:
浏览器中输入:虚拟机IP地址:9870/ (hdfs所在虚拟机的IP地址,到9870即可,自动跳转)
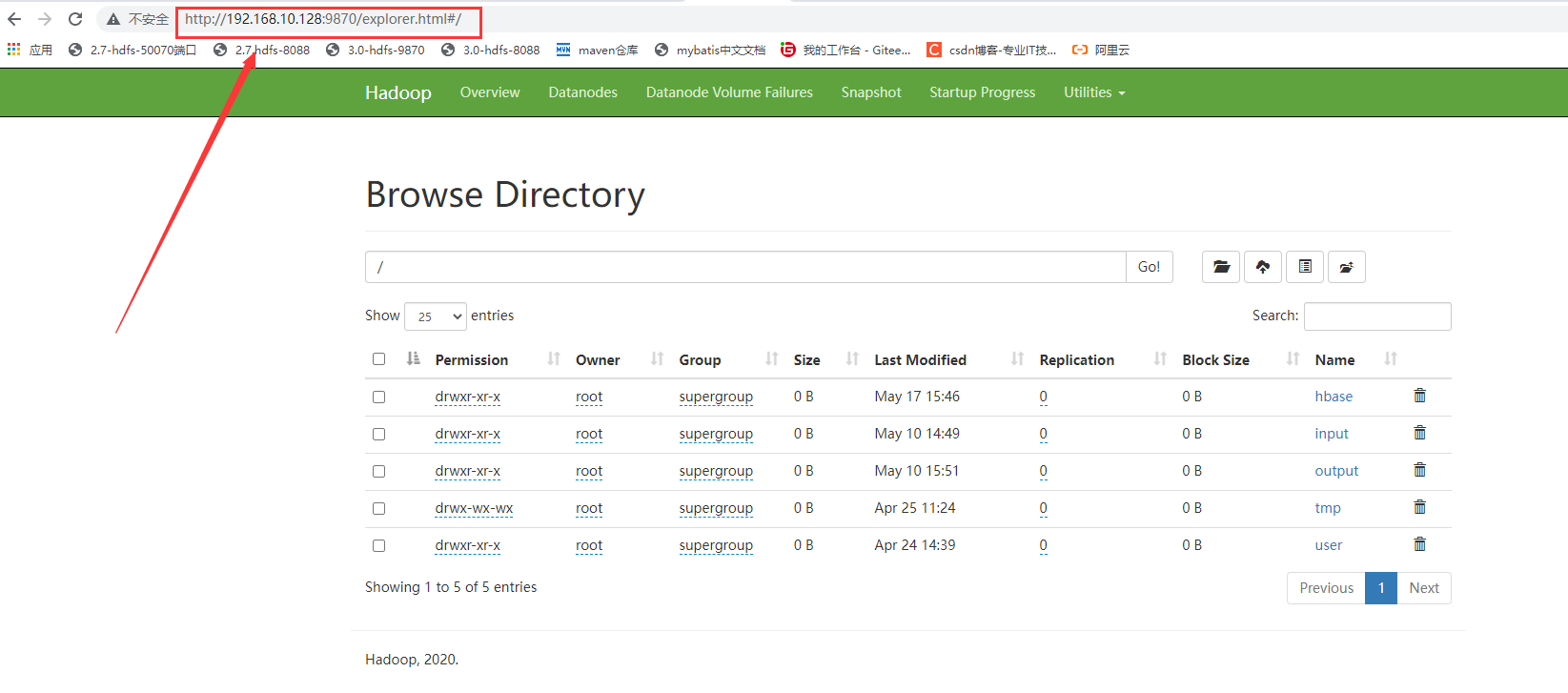
查看8088端口: 虚拟机IP地址:8088/cluster (yarn所在的虚拟机的IP地址)
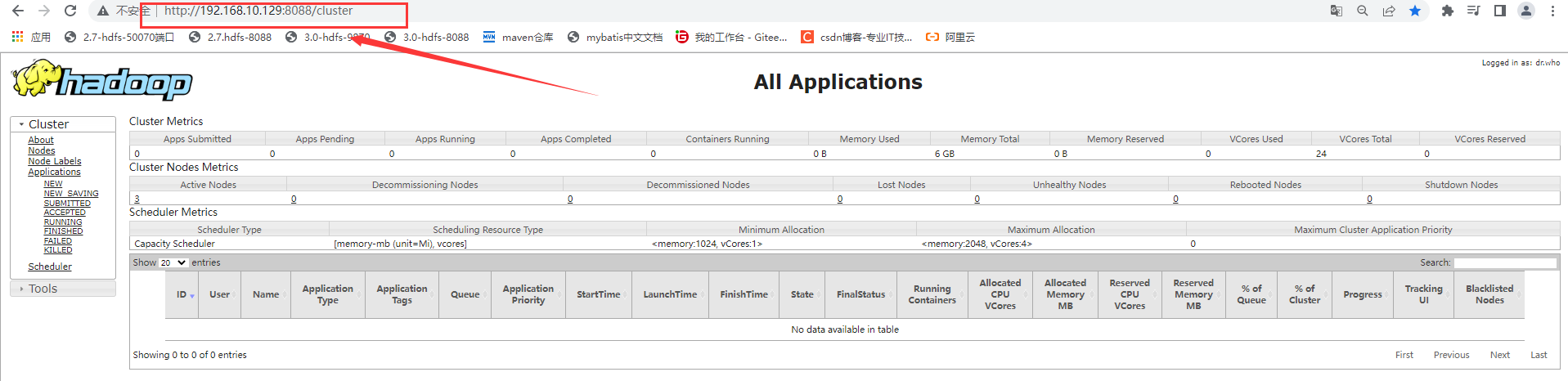
到此,可以正常使用!!!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/911125
推荐阅读
相关标签

