
热门标签
热门文章
- 1人工智能三要素之算法Transformer_transformers算法
- 2计算机毕业设计-基于Spring Boot的高校毕业生离校管理系统_基于ssm的毕业设计
- 3设备仪器仪表盘读数识别算法 yolov5_yolo检测仪表盘
- 4手把手教你搭建YOLOv8环境,并进行训练、测试_配置 yolov8
- 5德里克文:GPT入门经验及提示词速查整理_gpt 改英语论文 promot词
- 6如何通过 Hardhat 来验证智能合约_hardhat verify
- 7NLP-基础任务-中文分词算法(4)-评价指标:精确率(“模型分词结果集”与“标准答案集”的交集/“模型分词结果集”)、召回率(“模型分词结果集”与“标准答案集”的交集/“标准答案集”)、F1_评估分词算法的指标
- 8SpringBoot-实现搜索功能_springboot实现搜索功能
- 9探索在GIS中使用ChatGPT_gisgpt
- 10web课程设计——仿小米商城(10个页面)HTML+CSS+JavaScript web前端课程设计 web前端课程设计代码 web课程设计 HTML网页制作代码
当前位置: article > 正文
Transformer中position encoding实践_transformer position
作者:我家小花儿 | 2024-04-06 10:54:11
赞
踩
transformer position
近年来,transformer由于其可以实现并行计算且可以解决长序列的依赖问题在nlp领域和cv领域大放异彩。
原理图如下所示:
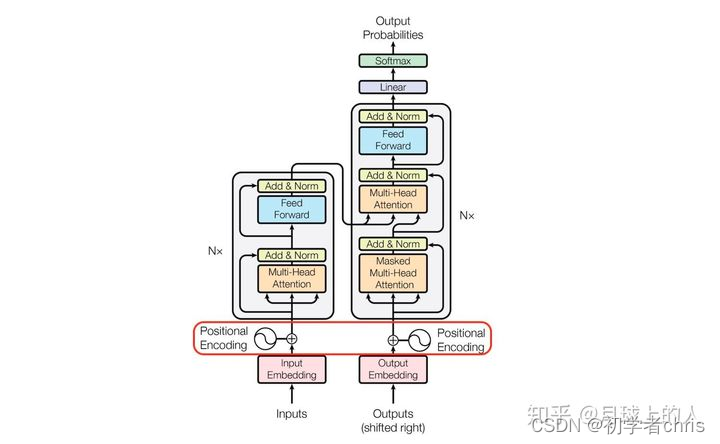
这里我们主要关注一个小部分,即position encoding部分,因为transformer取消了循环依赖,为了体现位置属性,所以给每个元素进行位置编码。
代码如下所示,至于为什么会这么写,可以参考作者原文,或者参考一下文章。https://zhuanlan.zhihu.com/p/338592312
代码如下:
class PositionalEncoding(torch.nn.Module): def __init__(self, d_model, max_len=5000): super(PositionalEncoding, self).__init__() pe = torch.zeros(max_len, d_model) position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) pe = pe.unsqueeze(0).transpose(0, 1)#(max-len,1,d_model) self.register_buffer('pe', pe) def forward(self, x): x = x + self.pe[:x.size(1), :].squeeze(1) #x = x + self.pe[:x.size(1), :] return x

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
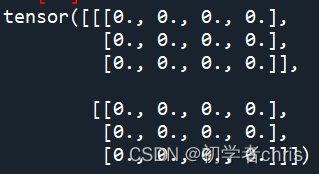
为了测试,我们定义两个输入矩阵,分别为全0、全1tensor。
d_model = 4
a=torch.zeros(2,3,4)
pos=PositionalEncoding(d_model)
b=pos(a)
c=torch.ones(2,3,4)
b1=pos(c)
- 1
- 2
- 3
- 4
- 5
- 6
很明显,输入矩阵为
输出为b,b1,如下所示:;
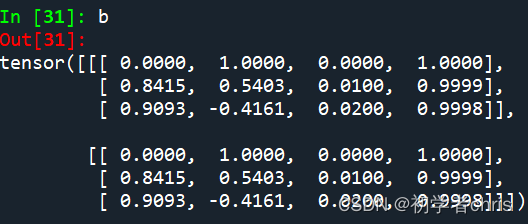
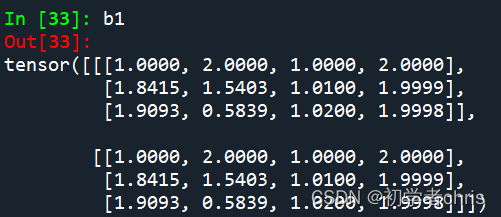
可以看出,都是在输入的基础之上,加上了固定值,而那些固定值就是编码得到的,与输入无关,与d_model有关,d_model可以理解为单词的embedding大小。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/371480
推荐阅读
相关标签

