
- 1powermockito测试私有方法_Spring的Mock测试你用上了吗?
- 2Android include 使用注意事项E/AndroidRuntime: FATAL EXCEPTION: main Process: com.example_fatal exception: main process: com.example.address
- 3荣誉 | 人大金仓连续三年入选“金融信创优秀解决方案”
- 4【Hadoop生态圈】1.Hadoop入门教程及集群环境搭建_hadoop开发教程
- 5详细功能描述及代码带您快速接入百度大脑通用文字识别_百度大脑代码库是什么
- 62024最新AI系统【OSAIGC】pc+小程序+app,chatgpt商业源码/文心一言/星火/知识库/aippt/ai问答/ai绘画/mj+sd/ AI思维导图 商业运营版系统源码带分销 AIGC_os-aigc
- 7中小微企业经营状况与数字化转型调研报告
- 8基于深度学习的RGBD深度图补全算法文章鉴赏
- 9低代码与数智化OA:重塑企业办公新生态
- 10【力扣】2810. 故障键盘 <模拟>_当他在键盘上敲下字符串 s 后, 屏幕上会出现什么。
李宏毅《深度学习》- Transformer_transformer回归预测
赞
踩
一、Seq2seq
1. 简介
Transformer 就是一个 Seq2seq (Sequence-to-sequence) 的模型
输入一个序列,输出长度由模型决定。例如语音识别,输入的语音信号就是一串向量,输出就是语音信号对应的文字。但是语音信号的长度和输出的文字个数并无直接联系,因此需要机器自行决定:

对于世界上没有文字的语言,我们可以对其直接做语音翻译。另外,Seq2seq 还可以用来训练聊天机器人:输入输出都是文字(向量序列),训练集示例如下图:

各式各样的NLP问题,往往都可以看作QA问题,例如问答系统(QA),让机器读一篇文章,读入一个问题,就输出一个答案。而该问题就可以用 Seq2seq 的模型来解决:
2. 应用示例
(1)语法分析 (Syntactic Parsing)
输入一段文字,机器要做的就是产生一个语法的解析树,告诉我们哪些文字或单词组合起来是名词,哪些组合是形容词等,具体参考 《Grammar as a Foreign Language》。

(2)多标签分类 (Multi-label Classification)
定义:同一个事物可以属于多个类别。
举例:一篇文章可以对应多种领域。
多标签分类的问题不能当作多类别分类来解,例如给机器输入一篇文章分析其类别,但现在需要输出分数最高的前三名,然而每一篇文章对应的分类数目不一样,有些文章对应的分类数目小于三个,显然这不能得到预期结果。

利用Seq2seq,输入一篇文章,机器自行决定输出几个类别。
3. 原理

一般Seq2seq会分成两部分:Encoder、Decoder。
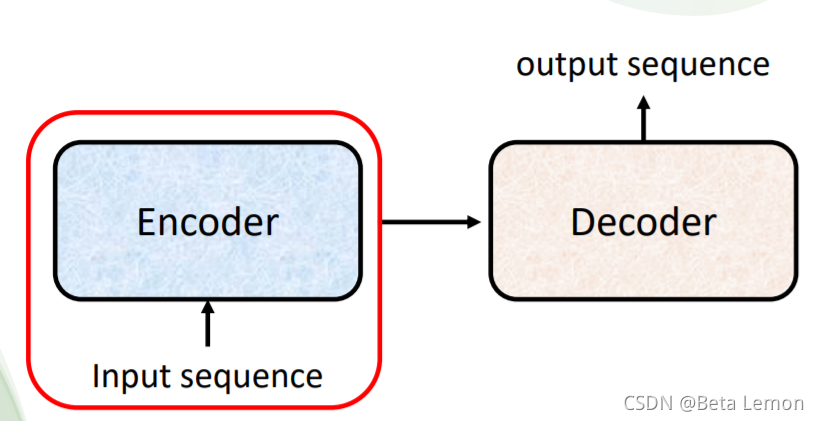
3.1 Encoder
Encoder 要做的事情就是给一排向量,输出一排向量,这可利用多种模型实现,如 CNN, RNN 等。Transformer 中的 Encoder 就是用的 Self-attention。
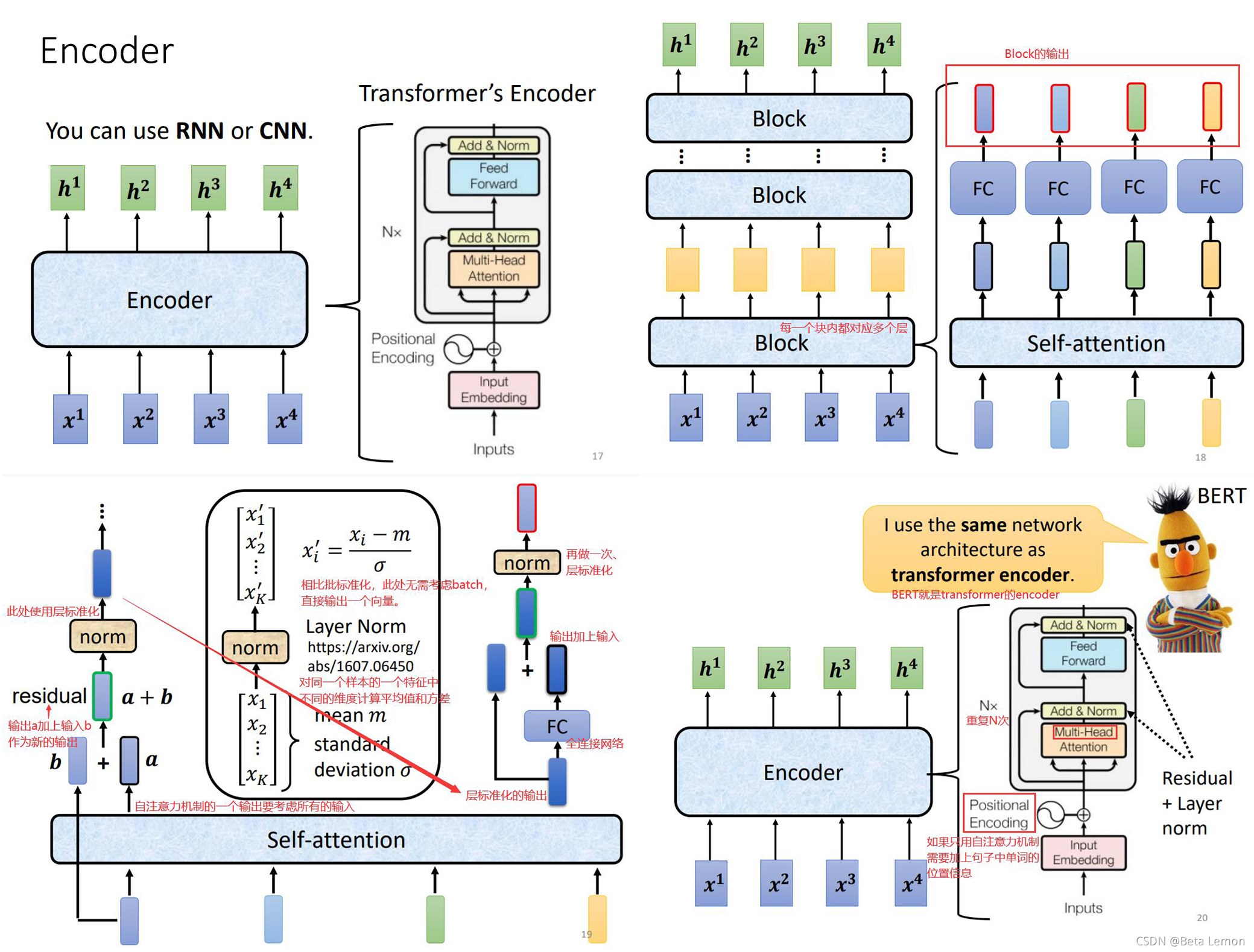
注:Transformer 的Encoder架构不一定要这么设计,此处为原始论文中的架构设计。

3.2 Decoder
(1)自回归 Autoregressive (AT)

当有一个文字输出错误,接下来Decoder就会用这个错误的结果【一步错步步错】:

下图中,Multi-head Attention其实就是多个Self-Attention结构的结合1。Decoder相比Encoder,在Multi-Head Attention上还加了一个 “Masked”(Masked Self-attention):

目前的Decoder的运行中,机器并不知道什么时候停下来,一直重复操作,如同“词语接龙”:机、器、学、习、惯、… 因此需要增加一个终止符号END来结束执行。


(2)非自回归 Non-autoregressive (NAT)

NAT 只需要一次性输入就可以产生整个句子。
-
Q:如何确定NAT decoder的输出长度?
A1:另外学习出一个分类器,它输入Encoder的input,输出Encoder应该输出的长度
A2:输出一个很长的序列,忽略END标识后的token(如上图) -
优点:并行处理,速度快;输出长度可控。
缺点:NAT的表现往往逊色于AT:多模态问题 Multi-modality.
二、Transformer
Transformer位于Decoder内,是连接Encoder和Decoder的桥梁,它有三个输入,其中两个来自于Encoder,一个来自Decoder。

跨越注意力 Cross Attention2
Cross Attention 机制不是 Transformer,其先于 Transformer 出现,后来出现了 Self-attention 才有了 Transformer。

1. 训练
在输入的时候会给Decoder正确答案,这种方式叫做"Teacher Forcing";使用交叉熵对模型进行评估。

训练 Seq2seq 的要点
1. 复制机制 Copy Mechanism
对很多任务而言,也许Decoder无需产生输出,也许是从输出里面“复制”一些东西出来。
例如在聊天机器人中,对于用户输入的某人名字,机器无需进行处理,直接输出即可;或者复述一段不能识别的文字;亦或是提取大量文章中的摘要3。
- User: 你好,我是 Tom。
Machine: Tom 你好,很高兴认识你。- User: 李华写不了作业了!
Machine: 你所谓的“写不了作业”是什么意思?
| 机器翻译 | 聊天机器人 | 摘要提取 |
|---|---|---|
 |  |  |
2. 语音识别应用:Guided Attention
在一些任务中,输入和输出需要有固定的方式。例如:语音识别,语音合成等。

3. 束搜索 Beam Search


Exposure Bias
测试的时候,Decoder会产生错误的输出,但是训练的时候是完全正确的,这种不一致的现象叫做 Exposure Bias4。可以在训练的时候类似“加入扰动”的方式来解决——scheduled sampling(定时采样),这种方式会影响Transformer的并行化。
三、总结

Transformer 分为两部分:Encoder 和 Decoder
1. Encoder
- 以字符作为输入,以状态作为输出
- 由输入字符得到Embedding (d_model=512),加入了位置编码作为输入
- Encoder 由 N(num_encoder_layers=6)个 Block 构成
- 每个 Block 分为两部分:多头注意力(Multi-Head Attention, nhead=8)和 前馈神经网络(FFN, dim_feedforward=2048)
- 在self-attention后做层归一化,FFN后也会经过层归一化。dropout使得网络具备集成学习的特点,即每次 以一定概率丢弃神经元信息,相当于训练多个模型,使得泛化能力更强。
import math import torch import torch.nn as nn import torch.nn.functional as F # 这里没有实现Embedding 和 Positional Encoding class TransformerEncoder(nn.Module): def __init__(self, n_head, d_model, d_ffn, act=F.gelu): """ :param n_head 头的个数 :param d_model 模型维数 :param d_ffn feed-forward networks 输出维数 :param act 激活函数 """ super(TransformerEncoder, self).__init__() self.h = n_head self.d = d_model # Attention self.q = nn.Linear(d_model, d_model) self.k = nn.Linear(d_model, d_model) self.v = nn.Linear(d_model, d_model) self.o = nn.Linear(d_model, d_model) # LayerNorm => Add & Norm self.LN1 = nn.LayerNorm(d_model) self.LN2 = nn.LayerNorm(d_model) # FFN self.ffn1 = nn.Linear(d_model, d_ffn) self.ffn2 = nn.Linear(d_ffn, d_model) self.act = act self.dropout = nn.Dropout(0.2) self.softmax = nn.Softmax(dim=-1) def attn(self, x, mask): Q = self.q(x).view(-1, x.shape[0], x.shape[1], self.d // self.h) # [head_nums, batch_size, seq_len, dim] K = self.k(x).view(-1, x.shape[0], x.shape[1], self.d // self.h) # [head_nums, batch_size, seq_len, dim] V = self.v(x).view(-1, x.shape[0], x.shape[1], self.d // self.h) # [head_nums, batch_size, seq_len, dim] attention = self.softmax(torch.matmul(Q, K.permute(0, 1, 3, 2)) / math.sqrt(self.d) + mask) attention = torch.matmul(attention, V) # multi_attn = torch.cat([_ for _ in attention], dim=-1) multi_attn = attention.view(x.shape[0], x.shape[1], -1) # 合并h个头的结果 out = self.o(multi_attn) return out def ffn(self, x): x = self.dropout(self.act(self.ffn1(x))) x = self.dropout(self.ffn2(x)) return x def forward(self, x, mask): x = self.LN1(x + self.dropout(self.attn(x, mask))) x = self.LN2(x + self.dropout(self.ffn(x))) return x if __name__ == '__main__': model = TransformerEncoder(2, 4, 8) x = torch.randn(2, 3, 4) mask = torch.randn(1, 1, 3, 3) o = model(x, mask) model.eval() traced_model = torch.jit.trace(model, (x, mask)) x = torch.randn(2, 3, 4) mask = torch.randn(1, 1, 3, 3) assert torch.allclose(model(x, mask), traced_model(x, mask))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
2. Decoder
- 以上一时刻的字符作为输入,把Encoder的状态作为输入的一部分,返回字符的预测概率
- Decoder 也由 N (num_decoder_layers=6) 个 Block 构成
- 每个 Block 分为三部分:Masked Multi-Head Attention、Multi-Head Attention和FFN
(1)1. Masked Multi-Head Attention以 输入字符的embedding 和 位置编码 作为输入,对自身序列做表征,Masked 表示预测的字符必须从该被预测的字符之前的字符中得到,即 P(this word | past words)【因果关系】,而 不能把未来的字符作为信息传入来预测。此处的Q, K, V均来自Decoder。
MASK如下图的矩阵乘法所示,将mask的部分用负无穷大表示,经过softmax函数之后就变为0,也就达到了mask的目的


(2)交叉注意力 以Masked Multi-Head Attention的输出作为Query,以Encoder的输出作为Value, 计算出Encoder输出序列和Decoder输入序列之间的关联性以计算出权重,再与Encoder的状态进行加权求和来得到一个新的表征。 此处的Q来自Decoder,K和V来自Encoder。
(3)FFN网络,与 Encoder 的 FFN 一样
(4)最后通过一个线性层来映射到一个概率空间:分类每个单词的得分
注:位置编码
对于全局位置和局部位置不敏感,输入后字符位置信息丢失。因此需要一个带有位置信息的向量加到每一个embedding input上去,使得保留input输入的字符位置信息。每一个block都有残差连接,因此位置信息可以充分传递到上层网络中,所以不会出现随着网络层数增大而抵消位置信息的情况。
P
E
(
p
o
s
,
2
i
)
=
sin
(
p
o
s
1000
0
2
i
/
d
m
o
d
e
l
)
PE_{(pos, 2i)}=\sin(\frac{pos}{10000^{2i/d_{model}}})
PE(pos,2i)=sin(100002i/dmodelpos)
P
E
(
p
o
s
,
2
i
+
1
)
=
cos
(
p
o
s
1000
0
2
i
/
d
m
o
d
e
l
)
PE_{(pos, 2i+1)}=\cos(\frac{pos}{10000^{2i/d_{model}}})
PE(pos,2i+1)=cos(100002i/dmodelpos)
此处 pos 是每个单词在句子中的绝对位置,i 是维数,偶数用
sin
\sin
sin 计算,奇数用
cos
\cos
cos 计算。
关于更多Transformer,参考 Datawhale - 图解transformer

