
- 1Android Studio下载各个版本方法_下载旧版as
- 2android studio如何编译运行,Android Studio编辑器教程
- 3docker容器内访问外部mysql_MySQL 进行 Docker 容器化之体验与感悟
- 4舵机工作原理及STM32驱动代码_stm32舵机驱动代码
- 5ffmepg V3.4 中文文档(1)_mmfpeg中文文档
- 6使用OpenCV实现图像增强
- 7Java Excel导出多个工作表(添加多个sheet)_模板导出excel多个sheet java.lang.illegalargumentexceptio
- 8鸿蒙os和安卓哪个快,实测比安卓快60% 华为鸿蒙OS性能这么强?
- 9微信公众号页面调用微信扫一扫_微信公众号 扫条码
- 10win10 开启远程桌面后连接提示内部错误_itrusiis.exe 远程桌面 出现内部错误
【数据结构】树型结构_树表示有序数组
赞
踩
目录
3.1树的基本概念
3.1.1.什么是树及其特点
树是一种抽象的数据类型ADT,特点:
- 每个节点有0个或者多个子节点;
- 没有父节点的节点就是根节点
- 每一个非根节点有且只有一个父亲节点
- 除了根节点外,每个子节点可以分为多个不相交的子树
3.1.2.树的术语
- 节点的度:一个节点含有子树的个数;
- 树的度:一棵树中最大的节点的度就是树的度
- 叶节点:度为0的节点
- 父节点:如果一个节点含有子节点,那么这个节点就是该子节点的父节点
- 子节点:一个节点含有的子树的根节点
- 兄弟节点:具有相同父节点的节点就是兄弟节点;
- 堂兄弟节点:父节点是兄弟节点的节点就是堂兄弟节点
- 节点的祖先:从根节点到该节点所经分支上的所有节点
- 子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
- 森林:由m(m>=0)棵互不相交的树的集合称为森林;
3.1.3.树的种类
树有有序树和无序树,无序树就是任意节点的子节点之间没有顺序关系,也叫自由树,它没有太大的实际意义,因此我们不做讨论,下面主要介绍有序树;有序树
二叉树
- 完全二叉树
- 满二叉树
- 平衡二叉树(AVL)
- 二叉查找树(排序二叉树)
霍夫曼树(最优二叉树)
B树(B-tree)
B+树
B*树
红黑树
3.1.4树的存储与表示
1.顺序存储
将数据结构存储在固定的数组中,然在遍历速度上有一定的优势,但因所占空间比较大,是非主流二叉树。二叉树通常以链式存储。

二叉树一般用链式存储.
2.链式存储

3.1.5应用场景
- xml,html等编写这些东西的解析器用的就是树
- 路由协议就是使用树的算法
- mysql数据库索引
- 文件系统的目录结构
- AI算法中的决策树等
3.2二叉树
3.2.1二叉树基础
1.概念
每个节点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”
2.性质
- 第i层最多有2^(i-1)个结点
- 深度为k的二叉树至多有2^k - 1个结点
- 一棵二叉树,叶节点为N0,度为2的节点数为N2,则N0=N2+1;
- n个结点的完全二叉树深度必为log2(n+1)
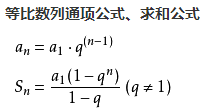
使用等比数列可以进行推导
- 对于完全二叉树,编号为i的节点,左孩子编号必为2i,右孩子编号2i+1
3.二叉树的遍历
广度优先遍历:就是按照从左往右从上往下一次进行遍历
深度优先遍历:包含先序遍历(根左右),中序遍历(左根右),后序遍历(左右根)
代码实现:
- class Node:
- def __init__(self, elem, lchild=None, rchild=None):
- self.elem = elem
- self.lchild = lchild
- self.rchild = rchild
-
-
- class Tree:
- def __init__(self, root=None):
- self.root = root
-
- def add(self, elem):
- node = Node(elem) # 创建节点
- if self.root == None: # 如果根节点为None,就说明当前的树是空,那么我们将传入的节点直接当做根节点就可以了
- self.root=node
- else: # 这时候根节点不是空的
- queue=[] # 创建一个队列用来存储存在的节点
- queue.append(self.root) # 我们将根节点加入到队列中
- while queue: # 如果队列中没有了数据,说明可以退出了
- cur=queue.pop(0) # 将队列中的第一个节点弹出来,并把该节点作为当前节点
- if cur.lchild==None: # 如果当前节点的左孩子是None,我们就把node作为该节点的左孩子,并退出
- cur.lchild=node
- return True
- elif cur.rchild==None: # 如果当前节点的右孩子是None,我们就把node作为该节点的右孩子,并退出
- cur.rchild=node
- return True
- else:
- # 该节点的左孩子和右孩子都不是空的,那么我们可以将它的左孩子和右孩子都加入队列中,重新进行判断
- queue.append(cur.lchild)
- queue.append(cur.rchild)
-
- # 广度优先遍历
- def breadth_traversal(self):
- if self.root==None:
- return None
- else:
- queue=[]
- queue.append(self.root)
- while queue:
- cur=queue.pop(0)
- print(cur.elem,'\t',end='')
- if cur.lchild is not None:
- queue.append(cur.lchild)
- if cur.rchild is not None:
- queue.append(cur.rchild)
-
- # 先序遍历:根 左 右
- # 递归的三个注意点:每次递归携带的参数;递归的退出条件;递归都是逆序的
- def preorder(self,node):
- if node==None:
- return None
- else:
- print(node.elem,'\t',end='')
- self.preorder(node.lchild)
- self.preorder(node.rchild)
-
- # 中序遍历
- def midorder(self,node):
- if node==None:
- return None
- else:
- self.midorder(node.lchild)
- print(node.elem, '\t', end='')
- self.midorder(node.rchild)
-
- # 后序遍历
- def postorder(self,node):
- if node==None:
- return None
- else:
- self.postorder(node.lchild)
- self.postorder(node.rchild)
- print(node.elem, '\t', end='')
-
- if __name__ == '__main__':
- tree=Tree()
- tree.add(1)
- tree.add(2)
- tree.add(7)
- tree.add(4)
- tree.add(5)
- tree.breadth_traversal()
- print()
- tree.preorder(tree.root)
- print()
- tree.midorder(tree.root)
- print()
- tree.postorder(tree.root)

注意:得到当前节点,在队列中就会删除当前节点,下一次取第一个节点的时候就是新的节点,这个新节点没有改变
逆推二叉树

- 广度遍历:1234567
- 先序遍历:1245367
- 中序遍历:4251637
- 后序遍历:4526731
已知先序和中序或者已知后序和中序我们就可以得到二叉树了,技巧:拿先序和中序举例,先序第一个二根节点,根据这个值找到中序中对应的值,通过中序将先序中的值分隔成两份,以此类推,从被分割的两份中找到第一个值,拿着该值去中序中寻找,根据中序中找的位置,我们又可以根据被分割的数量中将先序得到的结果进行分割,....
3.2.2完全二叉树
概念:
设二叉树的深度二k,除第k层外,其他各层节点树都达到了最大值,k层所有的节点都连续集中在最左边

特点:
- 叶子节点只出现在最下层或者次下层
- 最下层的叶子节点几种在左部
- 倒数第二层如果存在叶子节点,一定在右部连续位置
- 如果节点的度为1,该节点只有左孩子没有右孩子
- 同样节点数目的二叉树,完全二叉树深度最小
3.2.3满二叉树
图解:

特点:
- 从外形上来看,满二叉树一个三角形
- 满二叉树的节点总数为2^k-1,且节点数一定为奇数个。满二叉树的第k层节点的个数是2^(k-1)
3.2.4平衡二叉树
图解

特点:
平衡二叉树的左子树和右子树的深度之差的绝对值不超过1.
3.2.5二叉查找树(二叉排序树)
1.概念:
二叉查找树的左孩子小于当前结点的值,右孩子大于当前节点的值.图解:

2.创建二叉查找树:
3.删除二叉查找树节点
- 删除的节点为叶子节点:情况一:删除的节点为根节点,也就是该树只有一个节点,直接将root指针域置为None就可以了.情况二:该树有多个节点,删除的节点正好是叶节点,我们可以将连接该节点的父节点对应的该节点的指针域置为None即可;
- 删除的节点只有左子树:情况一:删除的节点为根节点,将根节点的root指针指向即将删除结点的左孩子,然后将删除结点的leftChild置空;情况二:该节点有父节点,将父节点相应的指针指向删除节点的左孩子,然后将删除节点的左孩子置为None
- 删除的节点只有右子树:情况一:删除的节点为根节点,将根节点对应的root指针指向即将删除的节点的右孩子,然后将删除节点的右孩子置None即可;情况二:删除的节点有父节点,我们将父节点对应的指针指向删除节点的右孩子,然后将删除节点的右孩子置为None;
- 删除节点既有左子树又有右子树:步骤1:查找删除节点右子树中最小的那个值,也就是右子树中最左边的那个节点,将这个节点的父节点记录下来,将该节点的值赋值给我们要删除的节点,即覆盖;步骤2:将右子树最小的那个节点进行删除
4.二叉查找树增加节点
与查找操作相似,由于二叉搜索树的特殊性,待插入的节点也需要从根节点开始进行比较,小于根节点则与根节点左子树比较,反之则与右子树比较,直到左子树为空或右子树为空,则插入到相应为空的位置,在比较的过程中要注意保存父节点的信息 及 待插入的位置是父节点的左子树还是右子树,才能插入到正确的位置。
5.特点
- 若任意结点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若任意结点的右子树不空,则右子树上所有的结点的值均大于它的根结点的值
- 任意结点左右子树分别为二叉查找树
- 对二叉查找树进行中序遍历即可得到有序的数列;
3.2.6霍夫曼树
1.基本概念
- 概念:给定n个权值作为n个叶子结点,构造一棵二叉树,若带权路径长度达到最小.最优二叉树
- 应用:数据的压缩,编码长度的优化
- 路径:从一个结点往下可以达到的孩子或孙子结点之间的通路
- 路径长度:通路中节点的个数,包含目标节点,不包含原始节点;
- 节点的带权路劲长度:从根节点到该节点的路径长度与该节点权的乘积;
- 树的带权路径长度:所有叶子节点的带权路径长度之和.图a:WPL=5*2+7*2+2*2+13*2=54;图b:WPL=5*3+2*3+7*2+13*1=48..左边是普通树,右边是哈夫曼树

2.构造霍夫曼树
霍夫曼编码:编码规则是从根节点出发,向左标记为0,向右标记为1。
构造方式:构造方法详解,在这里感谢这位小哥的解答.此篇博文中出现同权不同构问题,这个问题中尽管他们的构造方式不同,但是他们的权值是相同的,这种情况是不会影响结果的,具体请查看相关资料和书籍.
C++实现构造
- #include <iostream>
- #include <stdlib.h>
- using namespace std;
- const int MaxValue = 10000;//初始设定的权值最大值
- const int MaxBit = 4;//初始设定的最大编码位数
- const int MaxN = 10;//初始设定的最大结点个数
- struct HaffNode//哈夫曼树的结点结构
- {
- int weight;//权值
- int flag;//标记
- int parent;//双亲结点下标
- int leftChild;//左孩子下标
- int rightChild;//右孩子下标
- };
- struct Code//存放哈夫曼编码的数据元素结构
- {
- int bit[MaxBit];//数组
- int start;//编码的起始下标
- int weight;//字符的权值
- };
- void Haffman(int weight[], int n, HaffNode haffTree[])
- //建立叶结点个数为n权值为weight的哈夫曼树haffTree
- {
- int j, m1, m2, x1, x2;
- //哈夫曼树haffTree初始化。n个叶结点的哈夫曼树共有2n-1个结点
- for (int i = 0; i<2 * n - 1; i++)
- {
- if (i<n)
- haffTree[i].weight = weight[i];
- else
- haffTree[i].weight = 0;
- //注意这里没打else那{},故无论是n个叶子节点还是n-1个非叶子节点都会进行下面4步的初始化
- haffTree[i].parent = 0;
- haffTree[i].flag = 0;
- haffTree[i].leftChild = -1;
- haffTree[i].rightChild = -1;
- }
- //构造哈夫曼树haffTree的n-1个非叶结点
- for (int i = 0; i<n - 1; i++)
- {
- m1 = m2 = MaxValue;//Maxvalue=10000;(就是一个相当大的数)
- x1 = x2 = 0;//x1、x2是用来保存最小的两个值在数组对应的下标
-
- for (j = 0; j<n + i; j++)//循环找出所有权重中,最小的二个值--morgan
- {
- if (haffTree[j].weight<m1&&haffTree[j].flag == 0)
- {
- m2 = m1;
- x2 = x1;
- m1 = haffTree[j].weight;
- x1 = j;
- }
- else if(haffTree[j].weight<m2&&haffTree[j].flag == 0)
- {
- m2 = haffTree[j].weight;
- x2 = j;
- }
- }
- //将找出的两棵权值最小的子树合并为一棵子树
- haffTree[x1].parent = n + i;
- haffTree[x2].parent = n + i;
- haffTree[x1].flag = 1;
- haffTree[x2].flag = 1;
- haffTree[n + i].weight = haffTree[x1].weight + haffTree[x2].weight;
- haffTree[n + i].leftChild = x1;
- haffTree[n + i].rightChild = x2;
- }
- }
- void HaffmanCode(HaffNode haffTree[], int n, Code haffCode[])
- //由n个结点的哈夫曼树haffTree构造哈夫曼编码haffCode
- {
- Code *cd = new Code;
- int child, parent;
- //求n个叶结点的哈夫曼编码
- for (int i = 0; i<n; i++)
- {
- //cd->start=n-1;//不等长编码的最后一位为n-1,
- cd->start = 0;//,----修改从0开始计数--morgan
- cd->weight = haffTree[i].weight;//取得编码对应权值的字符
- child = i;
- parent = haffTree[child].parent;
- //由叶结点向上直到根结点
- while (parent != 0)
- {
- if (haffTree[parent].leftChild == child)
- cd->bit[cd->start] = 0;//左孩子结点编码0
- else
- cd->bit[cd->start] = 1;//右孩子结点编码1
- //cd->start--;
- cd->start++;//改成编码自增--morgan
- child = parent;
- parent = haffTree[child].parent;
- }
- //保存叶结点的编码和不等长编码的起始位
- //for(intj=cd->start+1;j<n;j++)
- for (int j = cd->start - 1; j >= 0; j--)//重新修改编码,从根节点开始计数--morgan
- haffCode[i].bit[cd->start - j - 1] = cd->bit[j];
-
- haffCode[i].start = cd->start;
- haffCode[i].weight = cd->weight;//保存编码对应的权值
- }
- }
- int main()
- {
- int i, j, n = 4, m = 0;
- int weight[] = { 2,4,5,7 };
- HaffNode*myHaffTree = new HaffNode[2 * n - 1];
- Code*myHaffCode = new Code[n];
- if (n>MaxN)
- {
- cout << "定义的n越界,修改MaxN!" << endl;
- exit(0);
- }
- Haffman(weight, n, myHaffTree);
- HaffmanCode(myHaffTree, n, myHaffCode);
- //输出每个叶结点的哈夫曼编码
- for (i = 0; i<n; i++)
- {
- cout << "Weight=" << myHaffCode[i].weight << " Code=";
- //for(j=myHaffCode[i].start+1;j<n;j++)
- for (j = 0; j<myHaffCode[i].start; j++)
- cout << myHaffCode[i].bit[j];
- m = m + myHaffCode[i].weight*myHaffCode[i].start;
- cout << endl;
- }
- cout << "huffman's WPL is:";
- cout << m;
- cout << endl;
- return 0;
- }
3.3其他树
3.3.1B树
1.基本介绍
B也是一种搜索树,说到B树,首先我们来复习一下AVL树,平衡二叉树任意结点左右子树的高度之差的绝对值最大为等于1,而且平衡二叉树中每个数据元素只能有一个数据元素一个关键字.但是B树就和平衡二叉树不同了,B树中每个数据元素可以有多个数据元素,多个关键字.B树也称为多路平衡查找树.B树中所有节点的孩子结点数的最大值就是B树的阶.下面我们看看B树有哪些特点:
特征:
- 树中每个节点至多有m棵子树,每棵子树至多含有m-1个关键字.
- 如果跟节点不是叶子节点,B树的至少有两棵子树.
- B树所有的叶子节点都在同一层
- 除根结点之外的所有非叶子结点至少有p个子节点(
(⌈m/2⌉⩽p⩽m,⌈m/2⌉为向上取整。); ceil(m//2)<=m) - 所有的非叶子节点包含以下数据(n,A0,k1,A1,K2,...Kn,An)
ki:关键码,真实的数据,存放作为分割线的数据;Ai:指向孩子的指针;n:关键字的个数
相信很多同学会问二叉搜索树和折半查找的性能已经够高了,难道B树的性能更加高?答案是确定的.从算法逻辑上讲,二叉查找数据的查找速度和比较次数确实是最小的,但是我们不得不考虑一个很现实的问题磁盘的IO操作,数据库的索引是存放在磁盘上的,当数据量非常大的时候索引的大小可能就是几个G甚至更多.当我们使用索引进行查找的时候,难道要把整个索引算不加载到内存中,很明显是不可能的,能做的只能对其进行逐一加载,加载每一个磁盘页,这里的磁盘页我们可以看成是索引树的节点,很容易知道磁盘的IO是由树的高度决定的,既然如此,我们可能把树变的矮胖,这样不就减少了磁盘的读写次数了.这样便需要我们的B树.
2.查询流程
我们来举个例子:查询5这个数:
由图我们可以看出当数据量比较大的时候,B树在查询中比较的次数不比二叉树少,尤其是单一节点的元素数量很多的时候,相比磁盘IO的速度,内存的耗时几乎可以忽略,因此只要树的高度足够低,IO次数就足够少,就可以提升查找性能.
3.插入节点
我们要插入数值4
自顶向下查找4的节点位置,发现4应当插入到节点元素3,5之间。节点3,5已经是两元素节点,无法再增加。父亲节点 2, 6 也是两元素节点,也无法再增加。根节点9是单元素节点,可以升级为两元素节点。于是拆分节点3,5与节点2,6,让根节点9升级为两元素节点4,9。节点6独立为根节点的第二个孩子。
4.删除节点
删除数值11
删除11后,节点12只有一个孩子,不符合B树规范。因此找出12,13,15三个节点的中位数13,取代节点12,而节点12自身下移成为第一个孩子。(这个过程称为左旋)
5.应用
主要应用于文件系统,部分数据库的索引(MongoDB),大部分的关系型数据库一般使用的是B+树
3.3.2B+树
1.基本概念
上面说了B树,下面我们来介绍一下B+树,B+树是B树的一种变体,查询的性能要比B树高.
B+树具有B树的特征,在此之外B+树还具有新的特征.一个m阶的B+树具有下面几个特征:
- k个子树的中间节点包含有k个元素(B树中是K-1个),每个关键字不保存数据,只用来做索引,所有的数据都保存在叶子节点中
- 叶子节点中包含了全部的元素信息(这点和霍夫曼树有点类似),指向含有这些元素记录的指针,且叶子节点本身依关键字的大小自小到大排列.
- 所有中间节点元素都同时存在于子节点中,在子节点元素中属于最大或者最小元素.
图解:
以后无论是增加元素还是修改元素,元素的最大值都在根节点.由于父节点的元素都出现在子节点,因此所有的叶子节点包含了全部的元素信息,并且每个叶子节点都带有指向下一个叶子节点的指针,形成了一个有序链表.B+树还有一个非常重要的特点,那就是卫星数据的定位,下面我们来了解一下:
卫星数据就是索引元素指向的数据记录,eg:在数据库中具体的某一行,在b树中,无论中间节点还是叶子节点都带有卫星数据:
在B+树中只有叶子节点带有卫星数据,其余中间节点都仅仅是索引,没有任何的数据关联,在数据库的聚集索引中,叶子节点直接包含卫星数据,在非聚集索引中,叶子节点带有指向卫星数据的指针.
2.B+树和B树查询的不同
B+树中间的节点没有卫星数据,同样大小的磁盘页可以容纳更多的节点元素,也就意味着数据量相同的情况下B+数据的结构比B-树更加矮胖,因此查询的IO次数也就更加的少.其次B+树查询必须最终查找到叶子节点,而B树只要找到匹配元素就可以了,也因此B-树的查询性能并不是很稳定,但是B+树的确实稳定的.
查询范围的不同.B树只能依靠中序遍历,我们来查询3-11之间的元素:
下面我们看看B+树的查找范围过程:
自顶向下,找到范围的下限,通过链表指针,遍历到元素6, 8;通过链表指针,遍历到元素9, 11,遍历结束:
3.B+树比B树的优势:
- IO次数更加少(单一节点存储更多元素(B树存储k-个数据,B+树存储K个数据),使得查询的IO次数更少)
- 查询性能稳定(所有查询都要找到叶子节点)
- 查询范围简便(所有叶子节点形成有序链表,便于范围查询)
3.3.3B*树
1.基本概念
B树是B+树的变种,而B+树又是B*树的变种,相对于B+树,B树又有他们的不同之处,首先说说他们的特征把:
特征:
- 关键字个数限制问题.B+树初始化关键字个数是ceil(m/2),B*树初始化关键字个数为(ceil(2/3*m)).
- B+树节点满时就会分裂,而B*树节点满时会检查兄弟节点是否满(因为每个节点都有指向兄弟节点的指针),如果兄弟节点未满则向兄弟节点转移关键字,如果兄弟节点已经满了,那么当前结点和兄弟节点各自拿出1/3的数据创建出新的节点出来.
评价:
- 在B+树的基础上因其初始化的容量变大,使得节点空间使用率更高,而又存有兄弟节点的指针,可以向兄弟节点转移关键字的特性使得B*树的分解次数变得更少;
3.3.4红黑树(RB树)
1.基础概念
是一棵BST树,节点是红色或者黑色,根结点和所有叶子节点都是黑色(黑色表示稳定),每个红色节点必须有两个黑色的子节点,从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点
2.为什么要有红黑树?
二叉查找树效率尽管很高,但是还是存在一定的缺陷的.下面我们来看一个例子:
依次插入如下五个节点:7,6,5,4,3;
这样的二叉树不好吧!二叉查找树多次插入新节点导致二叉树不平衡.这样的二叉树性能大打折扣.因此我们需要红黑树来解决这样的问题,红黑树除了具有二叉树的基本特征外,还具有下面特征:
- 节点是红色或者黑色;
- 根节点是黑色(黑色代表稳定)
- 每个叶子节点都是黑色的空格节点
- 从每个叶子到根的所有路径上不能有两个连续的红色节点
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点
红黑树从根到叶子的最长路径不会超过最短路径的两倍,当插入或者删除节点的时候红黑树的规则可能就会别打破.这时候就需要作出一个调整来维持我们的规则.插入21这个值之后打破了上述红黑树的特征4
3.调整方法:变色和旋转
变色:
左旋转:
右旋转:
4.什么情况下变色?什么情况下旋转?
如果情况比较复杂的时候变色和旋转结合使用:变色 -> 左旋转 -> 变色 -> 右旋转 -> 变色,....一般情况下先使用变色,解决不了就使用旋转.
5.应用场景
其应用有很多,比如有JDK的集合类TreeMap和TreeSet底层就是红黑树,在Java8中,HashMap也是用到了红黑树。


