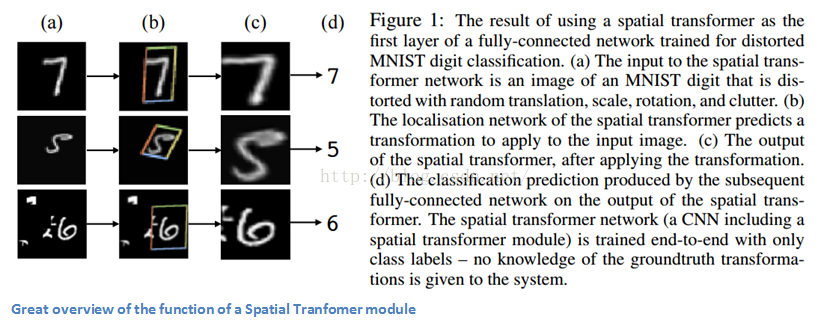
Introduction
本文主要总结了卷积神经网络在机器视觉领域的重要发展及其应用。我们将介绍几篇重要的公开发表的论文,讨论它们为何重要。前一半的论文(AlexNet到ResNet)将主要涉及整体系统架构的发展和演变,后一半论文将主要集中在一些有趣的子领域应用上。
AlexNet (2012)
这篇文章算是深度学习的起源(尽管有些学者认为Yann LeCun在1998年的论文 paper 才是真正的起源)。文章标题是“ImageNet Classification with Deep Convolutional Networks”,已经获得了共6184次引用,并被广泛认为是业内最具深远影响的一篇。Alex Krizhevsky, Ilya Sutskever, 以及Geoffrey Hinton三人创造了一个“大规模、有深度的卷积神经网络”,并用它赢得了2012年度ILSVRC挑战(ImageNet Large-Scale Visual Recognition Challenge)。ILSVRC作为机器视觉领域的奥林匹克,每年都吸引来自全世界的研究小组,他们拿出浑身解数相互竞争,用自己组开发的机器视觉模型/算法解决图像分类、定位、检测等问题。2012年,当CNN第一次登上这个舞台,在前五测试错误率top 5 test error rate项目上达到15.4%的好成绩。(前五错误Top 5 error指的是当输入一幅图像时,模型的预测结果可能性前五中都没有正确答案)。排在它后面的成绩是26.2%,说明CNN相对其它方法具有令人震惊的优势,这在机器视觉领域引起了巨大的震动。可以说,从那时起CNN就变成了业内家喻户晓的名字。
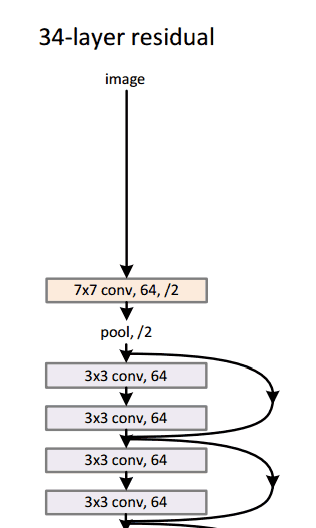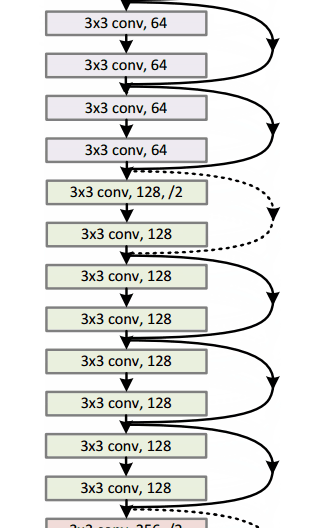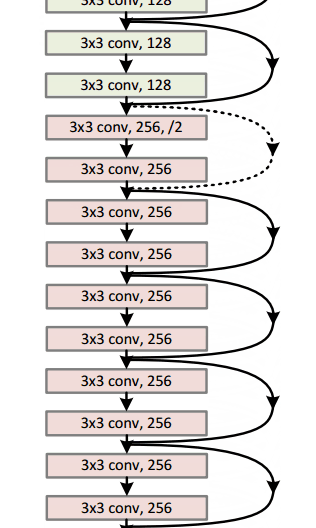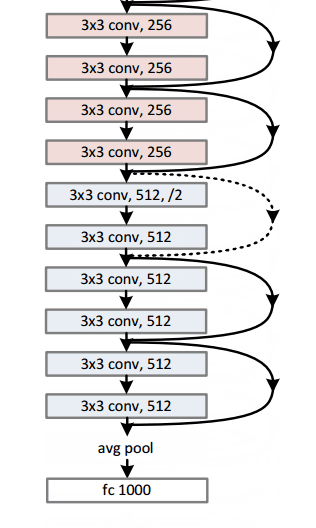
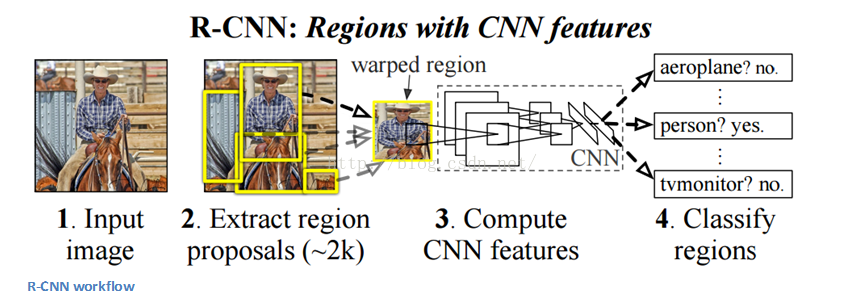
这篇文章主要讨论了一种网络架构的实现(我们称为AlexNet)。相比现在的架构,文中所讨论的布局结构相对简单,主要包括5个卷积层、最大池化层、丢包dropout层,以及3个全连通层。该结构用于针对拥有1000个可能的图像类别进行分类。
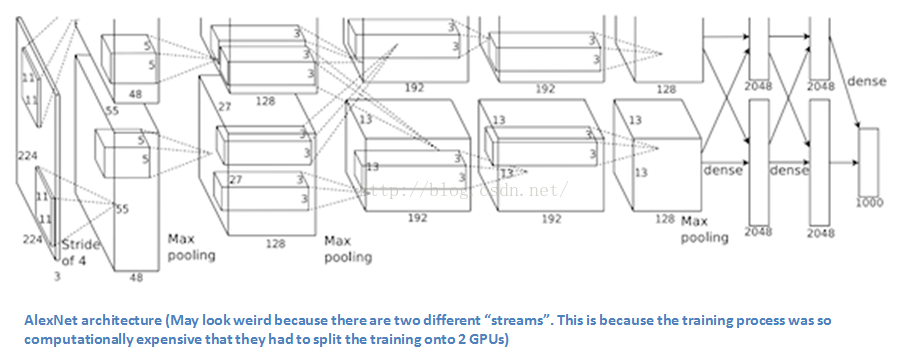
图中文字:AlexNet架构采用两个不同的数据“流”使得它看起来比较奇怪。这是因为训练过程的计算量极大因此需要将步骤分割以应用两块GPU并行计算。
文中要点
- 利用ImageNet数据库进行网络训练,库中包含22000种类的1500万标签数据。
- 利用线性整流层ReLU的非线性函数。(利用线性整流层ReLU后,运行速度比传统双曲正切函数快了几倍)
- 利用了数据扩容方法data augmentation,包括图像变换、水平反射、块提取patch extractions等方法;
- 为解决训练集过拟合问题而引入了丢包层dropout layer。
- 使用批量随机梯度下降法batch stochastic gradient descent进行训练,为动量momentum和权重衰退weight decay设定限定值。
- 使用两块GTX 580 GPU训练了5~6天。
本文重要性
本文的方法是机器视觉领域的深度学习和CNN应用的开山怪。它的建模方法在ImageNet数据训练这一历史性的难题上有着很好的表现。它提出的许多技术目前还在使用,例如数据扩容方法以及丢包dropout层。这篇文章真真切切地用它在竞赛中的突破性表现给业内展示了CNN的巨大优势。
ZF Net (2013)
AlexNet在2012年大出风头之后,2013年随即出现了大量的CNN模型。当年的的ILSVRC比赛胜者是来自纽约大学NYU的Matthew Zeiler以及Rob Fergus设计的模型,叫做ZF Net。它达到了11.2%的错误率。ZF Net的架构不仅对之前的AlexNet进行了进一步的优化,而且引入了一些新的关键技术用于性能改进。另外一点,文章作者用了很长的篇幅讲解了隐藏在卷积网络ConvNet之下的直观含义以及该如何正确地将滤波器及其权重系数可视化。
本文标题是“Visualizing and Understanding Convolutional Neural Networks”。在文章开头,Zeiler和Fergus提出CNN的复兴主要依靠的是大规模训练集以及GPU带来的计算能力飞跃。他们指出,目前短板在于研究人员对模型的内部运行机理知之甚少,若是不能解决这个问题,针对模型的改进就只能依靠试错。“development of better models is reduced to trial and error”. 虽然相较3年前,我们现在对模型有了进一步的了解;然而这依然是一个重要问题。本文的主要贡献是一个改进型AlexNet的细节及其可视化特征图层feature map的表现方式。
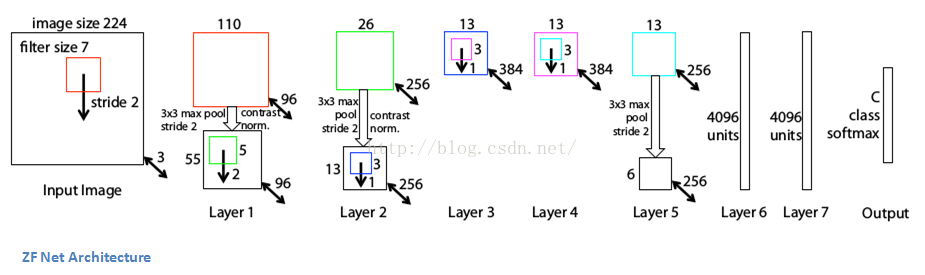
文章要点
- 除了一些微小改进外,模型架构与AlexNet非常相似
- AlexNet训练集规模为1500万张图像,ZF Net仅为130万张
- 相比AlexNet在第一层使用的11*11滤波器,ZF Net使用7*7的滤波器及较小步长。如此改进的深层次原因在于,在第一卷积层中使用较小尺寸的滤波器有助于保留输入数据的原始像素信息。事实证明,在第一卷积层中使用11*11滤波器会忽略大量相关信息。
- 随着网络层数深入,使用的滤波器数量同样增加。
- 激活方法activation function使用了线性整流层ReLUs,误差函数error function(疑为作者笔误,应该是损失函数loss function)使用了交叉熵损失函数cross-entropy loss,训练方法使用了批量随机梯度下降法batch stochastic gradient descent。
- 用1块GTX580 GPU训练了12天
- 发明一种卷积网络可视化技术,名为解卷积网络Deconvolutional Network,有助于检查不同激活特征以及它们与输入空间的关系。命名为“解卷积网络”"deconvnet"是因为它把特征投影为可见的像素点,这跟卷积层把像素投影为特征的过程是刚好相反的。
DeConvNet
解卷积的基本工作原理是,针对训练后的CNN网络中的每一层,都附加一个解卷积层deconvnet用于将感知区回溯path back到图像像素。在CNN的工作流程总,我们把一幅图像输入给CNN,一层一层地计算其激活值activations,这是前向传递。现在,假设我们想要检查第四卷积层中针对某个特征的激活值,我们把这层对应的特征图层中的这个激活值保存起来,并把本层中其它激活值设为0,随后将这个特征图层作为解卷积网络的输入。这个解卷积网络与原先的CNN有相同的滤波器设置。输入的特征图层通过一系列的反池化(最大池化求反),整流(反整流?),以及滤波(反滤波?),随后到达输入端。
隐藏在这整套流程之下的原因是,我们想要知道当给定某个特征图层时,什么样的图像结构能够激活它。下图给出了第一和第二层的解卷积层的可视化结果。

图中文字:第一层与第二层的可视化表示。每层都表示为两幅图片:其一表示为滤波器;另一表示为输入原始图像中的一部分结构,在给定的滤波器和卷积层之下,这些结构能够激发最强的激活信号。图中第二解卷积层的左图,展示了16个不同的滤波器。(跟第一层9个组合起来)
就像我们在Part 1中讨论过的,图中卷积网络ConvNet的第一层通常是由一些用于检测简单边缘、颜色等信息的低阶特征检测子组成。从图中也可以看出,第二层则是更多的圆形特征。让我们看看下图3,4,5层的情形。

图中这几层展示出更进一步的高阶特征,例如狗的脸部特征或是花朵的特征等。也许你还记得,在第一卷积层后,我们应用了一个池化层pooling layer用于图像下采样(例如,将32*32*3的图像转换为16*16*3)。它带来的效果是第二层的滤波器视野(检测范围scope)更宽了。想要获取更多有关解卷积网络以及这篇论文的信息,请参考Zeiler的发表视频presenting。
本文重要性
ZF Net不仅仅是2013年度竞赛的冠军,而且它为CNN提供了更加直观的展示能力,同时提供了更多提升性能的技巧。这种网络可视化的方法有助于研究人员理解CNN的内部工作原理及其网络架构。迷人的解卷积网络可视化以及阻塞实验让这篇文章成了我的最爱。
VGG Net (2014)
简单但有深度。2014年度ILSVRC其中一个模型最好地利用了这两个特点达到了7.3%的错误率(但并不是当年的冠军)。牛津大学的Karen Simonyan以及Andrew Zisserman两位创造了一个19层的CNN,网络中仅使用了3*3尺寸的滤波器,步长stride和填充padding都为1,池化层使用2*2的最大池化函数,步长为2。是不是很简单?
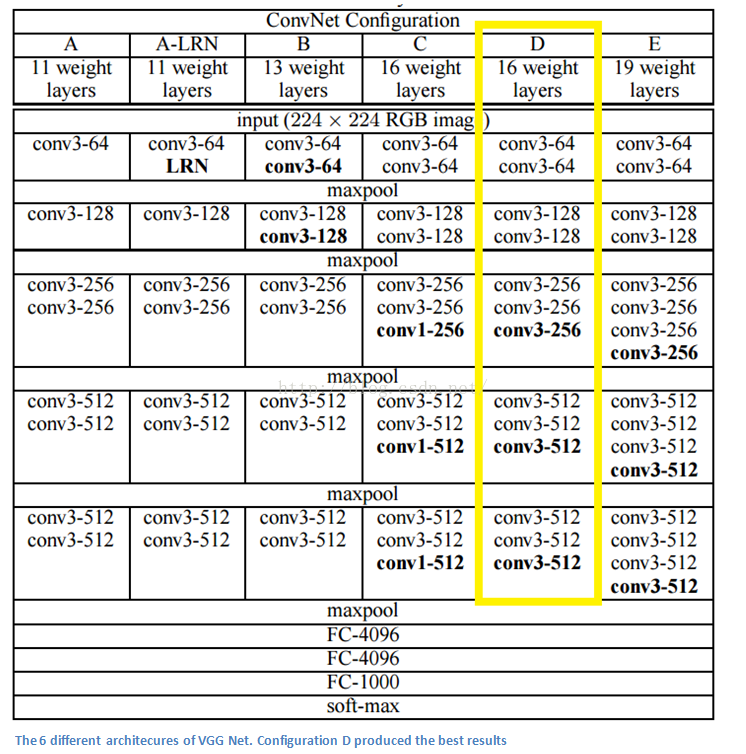
文章要点
- 仅使用3*3滤波器,这与之前的AlexNet的首层11*11滤波器、ZF Net的7*7滤波器都大不相同。作者所阐述的理由是,两个3*3的卷积层结合起来能够生成一个有效的5*5感知区。因此使用小尺寸滤波器既能保持与大尺寸相同的功能又保证了小尺寸的优势。优势其中之一就是参量的减少,另一个优势在于,针对两个卷积网络我们可以使用多一个线性整流层ReLU。(ReLU越多,越能降低系统线性性?)
- 3个3*3卷积层并排起来相当于一个有效的7*7感知区。
- 输入图像的空间尺寸随着层数增加而减少(因为通过每层的卷积或是池化操作),其深度反而随着滤波器越来越多而增加。
- 一个有趣的现象是,每个最大池化层之后,滤波器数量都翻倍,这进一步说明了数据的空间尺寸减少但深度增加。
- 模型不仅对图像分类有效,同样能很好地应用在本地化任务中(翻译任务)。作者在文章中进行了一系列的回归分析说明此事。(论文第10页很好地说明了此事paper)
- 用Caffe工具箱进行建模
- 在训练中使用了尺寸抖动技术scale jittering进行数据扩容data augmentation
- 每卷积层后紧跟一个线性整流层ReLU并使用批量梯度下降法batch gradient descent进行训练
- 用4块Nvidia Titan Black GPU进行训练2~3周。
本文重要性
VGG Net是我印象中影响最为深远的一篇文章,原因在于它强调了卷积网络中的深度,CNN必须保证拥有一个足够深的网络结构才能体现它在处理视觉数据的层次性。保持深度、保持简单。
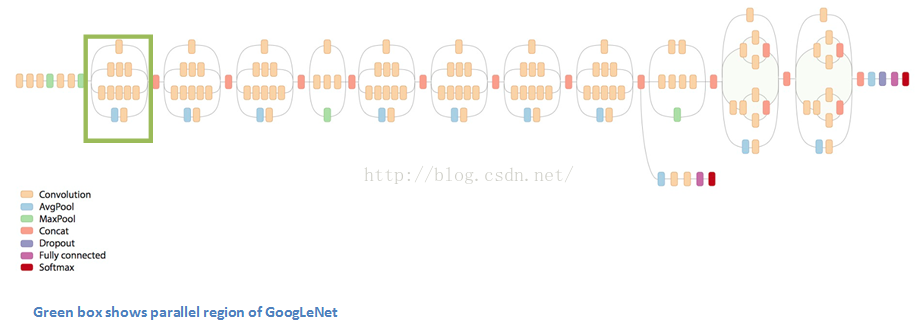
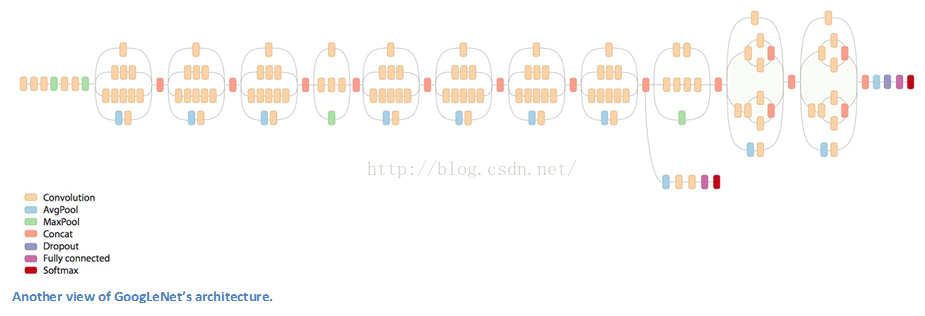
GoogLeNet (2015)
还记得刚才我们所说的简单法则吗?然而Google在自己的架构Inception Module里把这个原则抛到了九霄云外。GoogLeNet是一个22层的CNN,它以6.7%的错误率赢得了2014年度ILSVRC的冠军。据我所知,这是第一个跟传统方法,也就是卷积层与池化层简单叠加以形成序列结构的方法不同的一种CNN的新架构。文章作者强调,他们的新模型也特别重视内存与计算量的使用(这是之前我们没有提到的:多层堆积以及大量滤波器的使用会耗费很多计算与存储资源,同样也会提升过拟合的几率)。
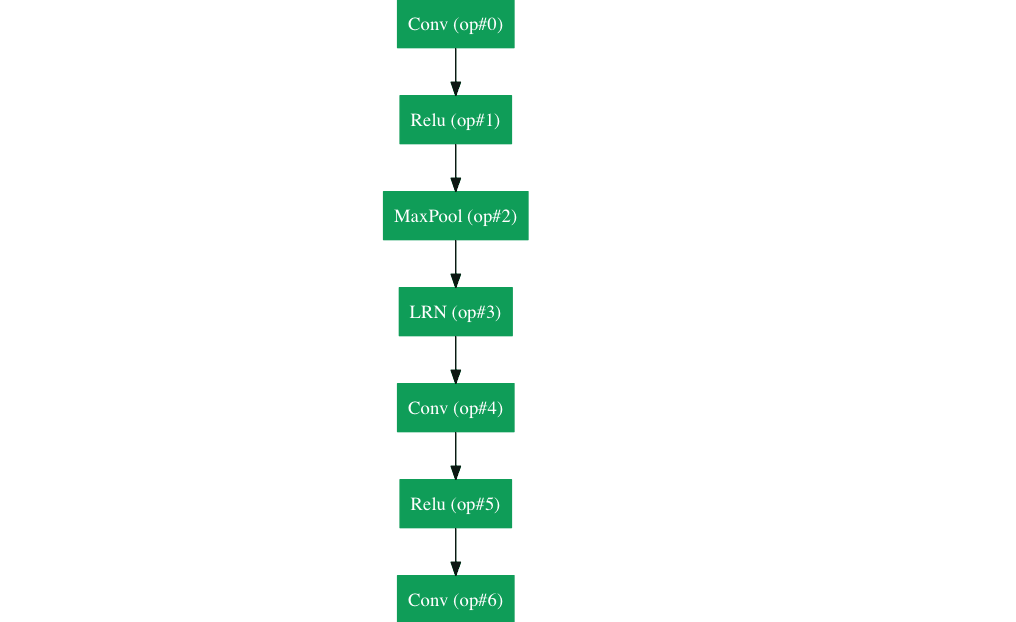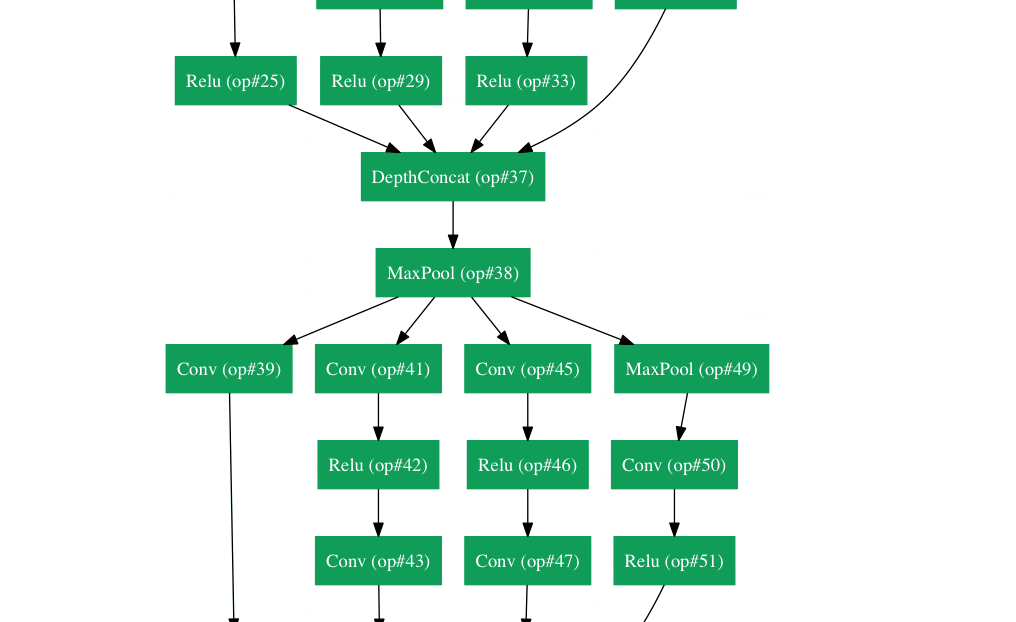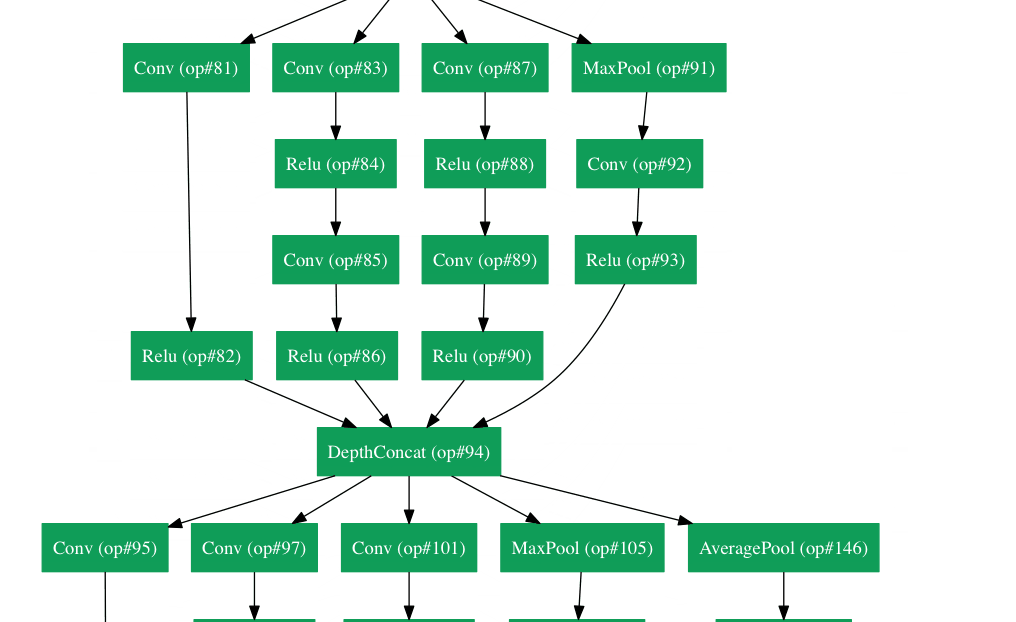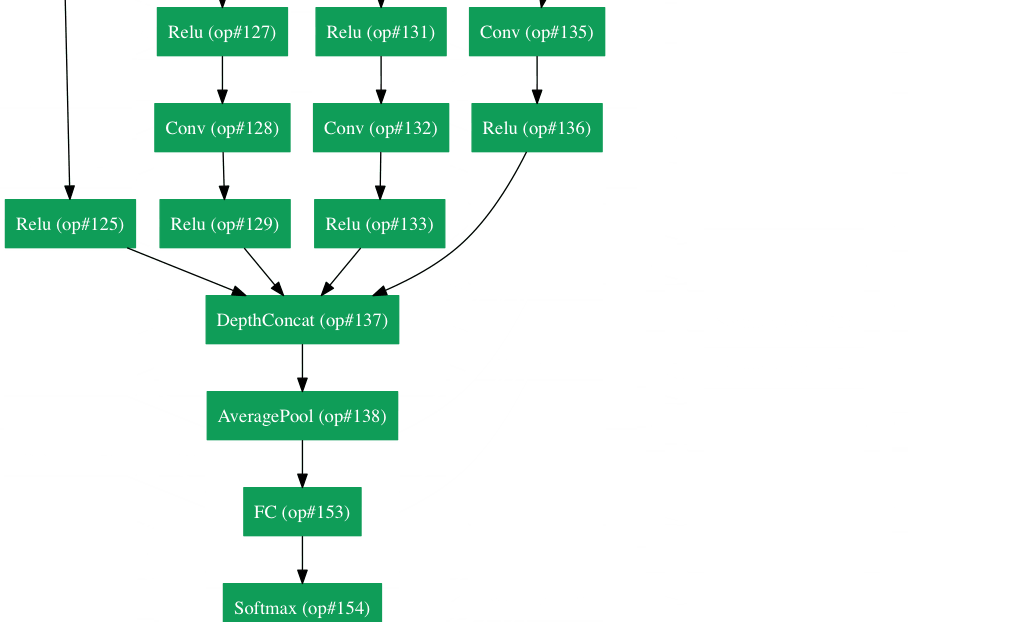
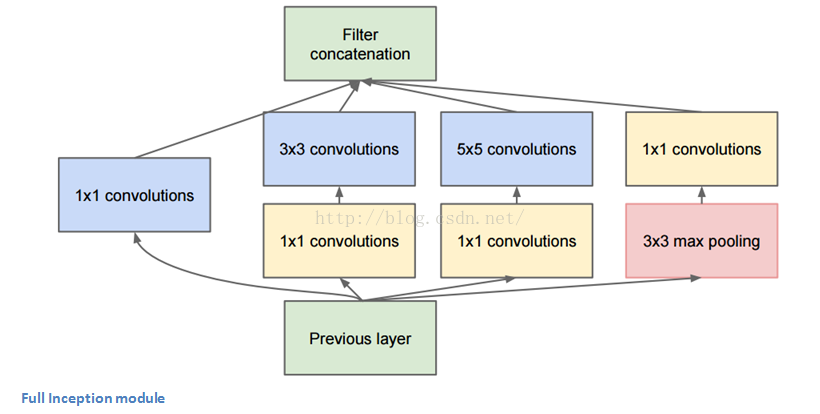
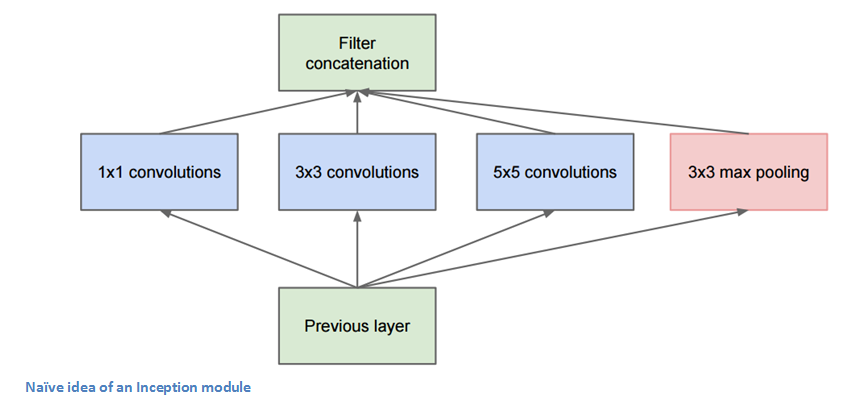
Inception Module
当我们第一眼看到GoogLeNet的架构时,会发现并不是像之前架构那样,所有流程都是顺序执行的。系统的许多部分是并行执行的。