
hadoop集群搭建(二)之集群配置_apache hadoop : core-site.xml 在那?
赞
踩
hadoop集群搭建(二)之集群配置
一、集群部署规划
1.NameNode和SecoundNameNode不要安装在同一台服务器
2.ResourceManager也很消耗内存,不要和NameNode、SecoundNameNode配置在同一台机器上
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecoundNameNode DataNode |
| yarn | NodeManager | ResourceManager NodeManager | NodeManager |
二、修改配置文件
1. /opt/module/hadoop-3.3.1/etc/hadoop/core-site.xml
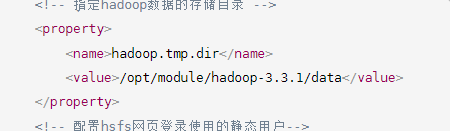
<configuration> <!--指定nodename地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop102:8020</value> </property> <!-- ָ指定hadoop数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.3.1/data</value> </property> <!-- 配置hsfs网页登录使用的静态用户--> <!-- <property> --> <!-- <name>hadoop.http.staticuser.user</name> --> <!-- <value>howey</value> --> <!-- </property> --> </configuration>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2. /opt/module/hadoop-3.3.1/etc/hadoop/hdfs-site.xml
<configuration>
<!-- nn 外部访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn 外部访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3. /opt/module/hadoop-3.3.1/etc/hadoop/yarn-site.xml
<configuration> <!-- nn 指定mr走shuffle--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定resourcemanager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property> <!-- 指定环境变量的继承--> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <!-- 开启日志聚集功能--> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志聚集服务器地址 --> <property> <name>yarn.log-server.url</name> <value>http://hadoop102:19888/jobhistory/logs</value> </property> <!-- 设置日志保留时间为7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
4.历史服务器配置
/opt/module/hadoop-3.3.1/etc/hadoop/mapred-site.xml
<configuration> <!-- 指定MapReduce程序运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop102:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop102:19888</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
4.配置works 文件:
/opt/module/hadoop-3.3.1/etc/hadoop/workers
5.进行集群配置文件分发
三、启动
注意:第一次启动需要格式化,一定要注意自己使用的那个账号在操作,不要一会root 一会普通账号
检查/opt/module/hadoop-3.3.1/data文件夹的文件所属
格式化之前先删除/opt/module/hadoop-3.3.1/logs和/opt/module/hadoop-3.3.1/data
格式化:
hdfs namenode -format
启动:
/opt/module/hadoop-3.3.1/sbin/start-dfs.sh
停止:
/opt/module/hadoop-3.3.1/sbin/stop-dfs.sh
检查:
jps
根据顶部图可判断需要在服务器103上启动yarn
/opt/module/hadoop-3.3.1/sbin/start-yarn.sh
mapred --daemon start historyserver
开启停止各服务组件(kill -9 进程号)
hdfs --daemon start/stop namenode/datanode/secondarynamenode
yarn的重启服务
yarn --daemon start/stop resourcemanager/nodemanager
web端查看
HDFS存储信息
http://hadoop102:9870/
yarn的resourcemanager
http://hadoop103:8088/
四、测试
hadoop fs -mkdir /wcinput
hadoop fs -put /opt/software/jdk-8u331-linux-x64.tar.gz /wcinput
查看web
http://hadoop102:9870/explorer.html#/
文件存储位置 core-site.xml
ll data/dfs/data/current/BP-15966323-192.168.10.102-1650898590994/current/finalized/subdir0/subdir0/
表示三个副本

五、集群崩溃处理
- 停止yarn服务
- 停止hdfs服务
- 删除所有服务器节点 /opt/module/hadoop-3.3.1/logs和/opt/module/hadoop-3.3.1/data 文件夹
- 格式化
hdfs namenode -format - 开启hdfs服务
- 开启yarn服务
六、hadoop常用脚本
#!/bin/bash #集群启停脚本 if [ $# -lt 1 ] then echo "no args input..." exit; fi case $1 in "start" ) echo "============================启动hadoop集群=================" echo "============================启动hdfs======================" ssh hadoop102 "/opt/module/hadoop-3.3.1/sbin/start-dfs.sh" echo "============================启动yarn======================" ssh hadoop103 "/opt/module/hadoop-3.3.1/sbin/start-yarn.sh" echo "======================启动historyserver======================" ssh hadoop102 "/opt/module/hadoop-3.3.1/bin/mapred --daemon start historyserver" ;; "stop" ) echo "=========================关闭hadoop集群=================" echo "======================关闭historyserver===================" ssh hadoop102 "/opt/module/hadoop-3.3.1/bin/mapred --daemon stop historyserver" echo "============================关闭yarn======================" ssh hadoop103 "/opt/module/hadoop-3.3.1/sbin/stop-yarn.sh" echo "============================关闭hdfs======================" ssh hadoop102 "/opt/module/hadoop-3.3.1/sbin/stop-dfs.sh" ;; * ) echo "input args error...." ;; esac
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
#!/bin/bash
#查看集群是否启动成功
for host in hadoop102 hadoop103 hadoop104
do
echo =========================$host================
ssh $host jps
done
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
七、hadoop常用端口号
hadoop3.x
hdfs namenode 内部常用端口:8020/9000/9820
hdfs namenode 对用户的查询端口:9870
yarn查看任务运行情况的端口:8088
历史服务器:19888
hadoop2.x
hdfs namenode 内部常用端口:8020/9000
hdfs namenode 对用户的查询端口:50070
yarn查看任务运行情况的端口:8088
历史服务器:19888
常用配置文件
hadoop3.x
core-site.xml hdfs-site.xml yran-site.xml mapred-site.xml workers
hadoop2.x
core-site.xml hdfs-site.xml yran-site.xml mapred-site.xml slaves
八、集群时间同步
注意
生产环境:如果服务器能连接外网,不需要时间同步,会同步外网的时间
生产环境:如果服务器不能连接外网,需要时间同步
(1)102机器配置(选择一个作为时间同步的主机)
切换root账号
su root
查看状态
systemctl status ntpd
开启
systemctl start ntpd
查看开机自启状态
systemctl is-enabled ntpd
修改配置文件
vim /etc/ntp.conf

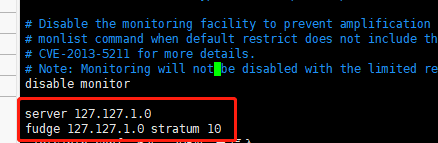
在最后追加
server 127.127.1.0
fudge 127.127.1.0 stratum 10
- 1
- 2
修改/etc/sysconfig/ntpd文件
vim /etc/sysconfig/ntpd
增加以下内容(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
重启ntpd服务
systemctl start ntpd
设置ntpd服务开机自启
systemctl enable ntpd
(2)其他机器配置
1.关闭所有节点的ntp服务和自启动
systemctl stop ntpd
systemctl disable ntpd
2.一分钟与时间服务器选择的主机做一次时间同步
crontab -e
* * * * * 从左到右依次是 分时日月周
添加定时任务如下
*/1 * * * * /usr/sbin/ntpdate hadoop102
- 1
测试:
date -s "2022-02-22 22:22:22"
一分钟后查看是否同步
date

