
- 1Unet实现眼底图像血管分割(二)_n_subimgs是什么意思
- 2Linux离线安装JDK1.8_linux 离线安装jdk1.8
- 3DNN深度神经网络模型做多输入单输出的拟合预测建模_dnn网络预测 多输入单输出
- 4自练题目c++
- 5demonstration记忆_新手学习雅思的基础, 雅思单词记忆技巧法
- 6BP神经网络实例及代码分析(python+tensorflow实现)_bp神经网络python代码tensorflow
- 7Java中获取Exception的详细信息_java获取exception的错误信息
- 8机器学习——卷积基础
- 9自然语言处理(NLP)实验——语言模型应用_自然语言处理实训
- 10数据库系列之OceanBase架构及安装部署_oceanbase部署
文本张量表示方法_model = word2vec(tokenized_texts, vector_size=300,
赞
踩
1. 简介
文本张量表示方法是自然语言处理中的重要技术,用于将文本数据转换成计算机可以处理的张量形式,以便进行后续的机器学习和深度学习任务。本文将介绍几种常用的文本张量表示方法,并给出相应的代码案例。
2. 词袋模型
词袋模型是文本表示方法中最简单的一种。它将文本看作是一个由词语构成的集合,忽略了词语之间的顺序和语法结构。在词袋模型中,每个文档都可以表示为一个向量,向量的每个元素对应于一个词语在文档中出现的次数。下面是使用Python实现词袋模型的代码示例:
| from sklearn.feature_extraction.text import CountVectorizer # 语料库 corpus = [ 'This is the first document.', 'This document is the second document.', 'And this is the third one.', 'Is this the first document?', ] # 创建词袋模型 vectorizer = CountVectorizer() X = vectorizer.fit_transform(corpus) # 打印词袋模型的结果 print(vectorizer.get_feature_names()) print(X.toarray()) |
3. TF-IDF模型
TF-IDF模型是基于词袋模型的改进,它考虑了词语在整个语料库中的重要程度。TF-IDF模型将每个词语的重要性表示为TF(词频)与IDF(逆文档频率)的乘积。下面是使用Python实现TF-IDF模型的代码示例:
| from sklearn.feature_extraction.text import TfidfVectorizer # 创建TF-IDF模型 vectorizer = TfidfVectorizer() X = vectorizer.fit_transform(corpus) # 打印TF-IDF模型的结果 print(vectorizer.get_feature_names()) print(X.toarray()) |
4. Word2Vec模型
Word2Vec是一种基于神经网络的词向量表示方法,它可以将每个词语表示为一个固定长度的向量。Word2Vec模型可以捕捉词语之间的语义关系,使得相似含义的词语在向量空间中距离较近。下面是使用Python实现Word2Vec模型的代码示例:
| from gensim.models import Word2Vec from nltk.tokenize import word_tokenize # 分词 tokenized_corpus = [word_tokenize(doc) for doc in corpus] # 训练Word2Vec模型 model = Word2Vec(tokenized_corpus, vector_size=100, window=5, min_count=1, sg=0) # 获取词向量 word_vectors = model.wv print(word_vectors['document']) |
5. GloVe模型
GloVe(Global Vectors for Word Representation)是一种基于全局词频统计的词向量表示方法,它在Word2Vec的基础上引入了全局语料库的统计信息。GloVe模型可以更好地捕捉词语之间的语义关系和语法关系。下面是使用Python实现GloVe模型的代码示例:
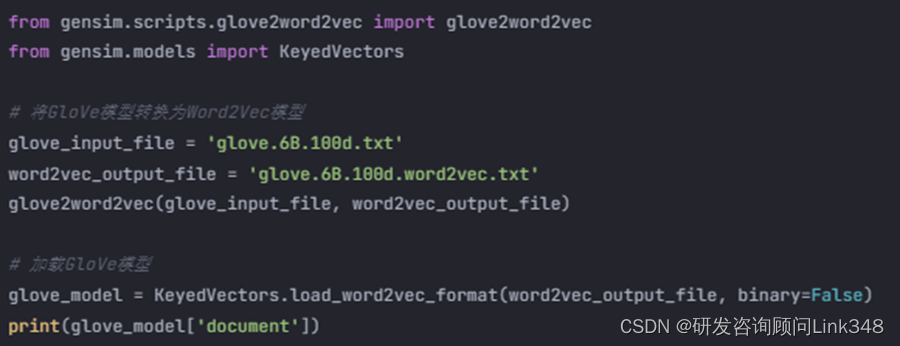
| from gensim.scripts.glove2word2vec import glove2word2vec from gensim.models import KeyedVectors # 将GloVe模型转换为Word2Vec模型 glove_input_file = 'glove.6B.100d.txt' word2vec_output_file = 'glove.6B.100d.word2vec.txt' glove2word2vec(glove_input_file, word2vec_output_file) # 加载GloVe模型 glove_model = KeyedVectors.load_word2vec_format(word2vec_output_file, binary=False) print(glove_model['document']) |
6. 结论
本文介绍了几种常用的文本张量表示方法,包括词袋模型、TF-IDF模型、Word2Vec模型和GloVe模型,并给出了相应的代码案例。这些方法在自然语言处理领域有着广泛的应用,可以帮助我们更好地理解和处理文本数据

