
- 1词向量模型Word2Vec_word2vec模型
- 2Pacemaker
- 3python入门--Vscode创建python项目_vscode如何创建python项目
- 4python tokenize_python – 滥用nltk的word_tokenize(已发送)的后果
- 5OpenHarmony之分布式软总线_openharmony 软总线 测试代码
- 6【深度学习】基于BERT模型的情感分类(附实战代码)_bert模型情感分析
- 7【Python】paddleocr快速使用及参数详解_paddleocr 详细参数
- 8NLP中的采样理解_下采样nlp
- 9363页PPT带你拆解胖东来的幸福之路!
- 10全网最全的Kali工具介绍大全_kali各组件工具介绍
自然语言处理:词向量之连续词袋模型(The Continuous Bag-of-Words Model,CBOW)_continuous bag of words
赞
踩
翻译自《Word2Vec Tutorial Part II: The Continuous Bag-of-Words Model》
(本文章矩阵相乘输入写在点乘右侧)
在前一篇文章推导了跳字模型并解释了什么是词向量,本篇探究词向量的另一个模型:连续词袋模型(CBOW)。如果理解了跳字模型,词袋模型也很直观,因为两者有很多相似点。例如词袋模型的结构图:

看起来就像跳字模型将输入输出翻转了。对于窗口大小为C,词典词汇数 V,输入层由单词![]() 的独热编码组成,隐层是N维向量h,最终的输出层是训练样本中的单词y的独热编码。独特编码的输入向量通过V×N的权重矩阵W与隐层连接,隐层通过N×V的权重矩阵W′与输出层连接
的独热编码组成,隐层是N维向量h,最终的输出层是训练样本中的单词y的独热编码。独特编码的输入向量通过V×N的权重矩阵W与隐层连接,隐层通过N×V的权重矩阵W′与输出层连接
前向传播
我们先来理解输出是怎么从输入计算得到的。假设我们已经得到了权重矩阵(下一节介绍是怎么训练的)。第一步是计算隐层的输出h,公式如下:
![]()
是输入向量与矩阵W加权后的平均。 隐层输出的计算时跳字模型和连续词袋模型的区别之一。然后计算输出层每个节点的输出:
![]()
![]() 是输出权重矩阵W′的第j列. 输出
是输出权重矩阵W′的第j列. 输出![]() 是将
是将 ![]() 经过softmax函数获得
经过softmax函数获得

(感觉这个式子分子和分母的exp的指数都应该改成对输出层每个节点求和)
知道前向传播的工作原理,现在可以学习权重矩阵:W 和 W′.
通过反向传播学习权重矩阵
在学习权重矩阵 W 和 W′的过程中,我们先随机初始化,然后不断使用训练样本来计算预测输出与实际输出的误差,并计算误差对权重矩阵元素的梯度,然后沿着梯度方向来纠正参数,这就是一般的随机梯度下降(SGD)。
首先定义损失函数,目标是在给定的上下文,最大化输出单词的条件概率,因此损失函数为(这里对上式softmax取对数的相反数):

(感觉这个公式最后的第二项应该为正而不是负)
这里 ![]() 是实际输出单词的下标。下一步是推导隐层-输出层的权重W′的更新公式,然后是推导输入-隐层的权重W的更新公式
是实际输出单词的下标。下一步是推导隐层-输出层的权重W′的更新公式,然后是推导输入-隐层的权重W的更新公式
隐层-输出层的权重更新
首先计算损失函数 E 对输出层第 j 个节点的输入![]() 的导数
的导数
![]()
(yj就是上面的softmax了)
这里![]() 若
若 ![]() 否则
否则![]() .
.
这是输出层节点 j 的估计误差。然后用链式法则求E对输出层权重![]() 的导数
的导数
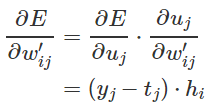
这里已经得到对任意输出权重![]() 的导数,可以定义随机梯度下降的公式:
的导数,可以定义随机梯度下降的公式:
![]()
或者:![]()
η>0是学习率.
更新输入-隐层的权重
现在尝试对输入权重wij做类似推导。
首先计算E对任意隐层节点hi的导数(同样利用链式法则)
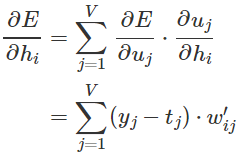
这里求和是由于 隐层节点hi 与输出层每个节点都有连接,因此预测误差需要合并。然后计算E对任意输入权重![]() 的导数
的导数
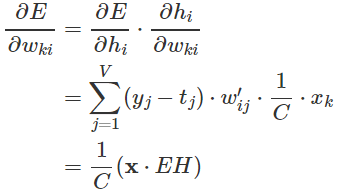
(这个公式,结果![]() 是矩阵,应该是E对整个W求导)
是矩阵,应该是E对整个W求导)
![]() 表示输入向量第k个元素,EH是N维向量, 元素是
表示输入向量第k个元素,EH是N维向量, 元素是![]() ,
,![]() .
.
然而由于输入x是独热编码,所以N×V矩阵![]() 只有一行非0,所以对于输入权重最终的随机梯度下降公式是:
只有一行非0,所以对于输入权重最终的随机梯度下降公式是:
![]()
![]() 是输入文本的第c个词(第几个词都一样计算) .
是输入文本的第c个词(第几个词都一样计算) .

