
热门标签
热门文章
- 1解决更新Android Studio后下载Gradle超时_android studio下载grade超时
- 2电商交易数据分析_电商平台交易数据
- 3为什么有了MAC还需要IP?
- 4掌握简单有效的被动加好友技巧,让你24小时轻松引流!_被动加人
- 5你想在本地部署大模型吗?本地部署大模型的三种工具_怎么部署大模型
- 6PostgreSQL的安装和卸载,远程连接_pgsql数据库的卸载与安装
- 7大模型学习路线(10)——模型评测指标_大模型评测指标
- 8Java使用Hutool工具类轻松生成验证码_hutool 验证码
- 9解决Class com.sun.tools.javac.tree.JCTree$JCImport does not have member field ‘com.sun.tools.javac.tre
- 10Python 使用pyecharts生成echarts图像_pyecharts生成图片
当前位置: article > 正文
大语言模型 LLM book 笔记(二)第四章 数据准备
作者:寸_铁 | 2024-08-17 15:35:14
赞
踩
大语言模型 LLM book 笔记(二)第四章 数据准备
第二部分 预训练
第四章 数据准备
4.1 数据来源
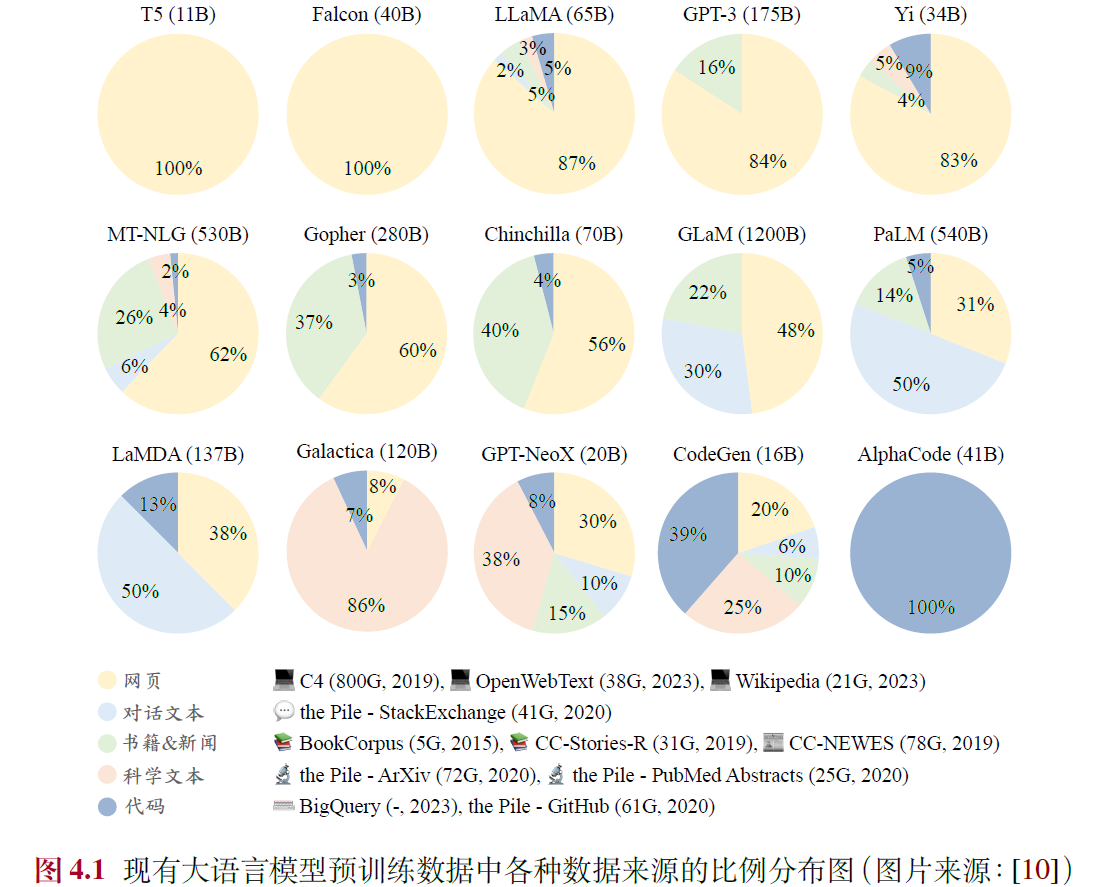
4.1.1 通用文本数据
- 网页 + 书籍
4.1.2 专用文本数据
- 多语文本 + 科学文本 + 代码
4.2 数据预处理

4.2.1 质量过滤
- 基于启发式规则的方法
- 基于语种的过滤:语言识别器筛选中英文,对于多语的维基百科由于数据规模小可直接训
- 基于简单统计指标的过滤

- 基于关键词的过滤

- 基于分类器的方法
- 轻量级模型:效率高,受限于模型能力,FastText
- 可微调的预训练语言模型:可针对性微调,通用性和泛化性不足,BERT、BART、LLaMA
- 闭源大语言模型API:能力较强,成本高,不够灵活,GPT-4、Claude 3
- 可用方案:先用规则再用分类器,分类器可用多种集成
4.2.2 敏感内容过滤
- 过滤有毒内容:毒性文本分类器
- 过滤隐私内容:使用启发式方法,如关键字识别,用特定词元替换
4.2.3 数据去重
- 计算粒度:首先针对数据集和文档级别进行去重,进一步在句子级别实现更为精细的去重
- 用于去重的匹配方法
- 精确匹配算法:后缀数组来匹配最小长度的完全相同子串
- 近似匹配算法:局部敏感哈希(Locality-Sensitive Hashing, LSH),如最小哈希(MinHash)
4.2.4 数据对预训练效果的影响
- 数据数量的影响:训练数据数量越大,模型性能越好,未达到极限
- 数据质量的影响
- 整体质量:质量不好导致不稳定不收敛,同数量下质量越高越好,能减少“幻想”
- 重复数据:可能导致“双下降现象”(训练损失先经历下降然后出现升高再下降的现象),降低利用上下文信息的能力,如果要使用高质量数据重复训练,可以进行改写或针对性生成
- 有偏、有毒、隐私内容:严重不良影响,容易被攻击和诱使生成
- 数据集污染:也称为基准泄漏,尽量不要包含评估测试集
4.2.5 数据预处理实践
- 质量过滤
- 加载预训练好的FastText 语言分类器,为每个输入文本生成一个语言标签,不符合配置文件中语言类别的文本将被过滤。
from utils.evaluator import LangIdentifier class FilterPassageByLangs(): def __init__(self) -> None: # 使用LangIdentifier 模块加载已经训练好的fasttext 模型 self.language_identifier = LangIdentifier(model_path="utils/models/fasttext/lid.176.bin") self.reject_threshold = 0.5 def filter_single_text(self, text: str, accept_lang_list: list) -> bool: # 使用fasttext 模型给text 打分,每种语言生成一个置信分数 labels, scores = self.language_identifier.evaluate_single_text(text) # 如果text 所有语言的分数均比reject_threshold 要低,则直接定义为未知语言 if any(score < self.reject_threshold for score in scores): labels = ["uk"] accept_lang_list = [each.lower() for each in accept_lang_list] # 如果分数最高的语言标签不在配置文件期望的语言列表中,则丢弃该文本 if labels[0] not in accept_lang_list: return True return False

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 去重
- 句子级去重:对文本包含的所有句子(每行对应一个句子)计算声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/寸_铁/article/detail/993350
- 句子级去重:对文本包含的所有句子(每行对应一个句子)计算
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

