- 1Navicat实现 MYSQL数据库备份图文教程_navicat备份数据库
- 2【FPGA】用Verilog语言实现呼吸灯实验_fpga呼吸灯verilog
- 3Spring Boot打jar包趟过的坑_awd 修复jar
- 4Python爬虫实战(四):利用代理IP爬取某瓣电影排行榜并写入Excel(附上完整源码)_ip代理
- 5Stable Diffusion_为啥尺寸会影响生图是否畸形?
- 6分布式锁全面总结_分布式锁机制
- 7CSS中的动画效果
- 82024抖音矩阵云混剪系统源码 短视频矩阵营销系统_2024抖音矩阵云混剪系统 源码短视频矩阵营销系统
- 9测试用例编写_用例编号怎么写
- 10根本上解决mysql启动失败问题Job for mysqld.service failed because the control process exited with error code_job for dmservicedmserver.service failed because t
redis(二)_--latency-history
赞
踩
一、慢查询
1、介绍说明
许多存储系统(例如mysql)都会提供慢查询日志帮助开发和运维人员定位系统存在的慢操作。而所谓的慢查询日志就是系统在命令执行前后计算每条命令的执行时间,当超过预设阀值就会将这条命令的相关信息记录下来。
一般redis客户端要执行一条命令分为下面四步:
其中慢查询只统计第三步的执行时间,所以没有慢查询并不代表客户端没有超时问题(可能因为其他三步导致的超时)
2、慢查询的两个配置参数
对于慢查询功能,我们需要明确两件事:预设的阀值怎么设置? 慢查询记录存放在那里?
redis提供slowlog-log-slower-than 和 slowlog-max-len 来配置这两个值。
1)、slowlog-log-slower-than就是配置预设阀值的,单位是微妙(1秒=1000毫秒=1000000微妙),其默认值是10000(即10毫秒)。(如果slowlog-log-slower-than=0会记录所有的命令,slowlog-log-slower-than<0对于任何命令都不会进行记录)
2)、slowlog-max-len是说明慢查询日志最多查询多少条,那不是没说明日志存放在哪里吗?
实际上redis使用一个列表来存储慢查询日志,其中slowlog-max-len就是该列表的最长长度。一个新的命令满足慢查询条件时被插入到这个列表中,当慢查询日志列表已处于其最大长度时,最早插入的一个命令将从列表中移出,例如slowlog-max-len设置为5,当有第6条慢查询
插入的话,那么队头的第一条数据就出列,第6条慢查询就会入列。而对于获取日志方式是用命令来获取的。
redis修改配置可以通过修改配置文件,也可以通过config set命令去动态修改。例如:
最后的config rewrite是将配置持久化到本地配置文件中。
我们获取慢查询日志是,可以通过几组命令:
1)、slowlog get 【n】
n表示返回几条。
可以看出返回的每个慢查询日志由四个属性组成,分别是:
(1)慢查询日志的标志id
(2)发生时间戳
(3)命令耗时
(4)执行命令和参数
2)、获取慢查询日志当前的长度
slowlog len
3)、慢查询日志重置(会清空)
slowlog reset
配置参数的建议:
(1)slowlog-max-len配置建议:线上建议调大慢查询列表,记录慢查询时Redis会对长命令做截断操作,并不会占用大量内存。增大慢查询列表可以减缓慢查询被剔除的可能,例如线上可设置为1000以上。
(2)·slowlog-log-slower-than配置建议:默认值超过10毫秒判定为慢查询,需要根据Redis并发量调整该值。由于Redis采用单线程响应命令,对于高流量的场景,如果命令执行时间在1毫秒以上,那么Redis最多可支撑OPS不到1000。因此对于高OPS场景的Redis建议设置为1毫秒。(3)慢查询只记录命令执行时间,并不包括命令排队和网络传输时间。因此客户端执行命令的时间会大于命令实际执行时间。因为命令执行排队机制,慢查询会导致其他命令级联阻塞,因此当客户端出现请求超时,需要检查该时间点是否有对应的慢查询,从而分析出是否为慢查询导致的命令级联阻塞。
(4)由于慢查询日志是一个先进先出的队列,也就是说如果慢查询比较多的情况下,可能会丢失部分慢查询命令,为了防止这种情况发生,可以定期执行slow get命令将慢查询日志持久化到其他存储中(例如MySQL),然后可以制作可视化界面进行查询,


二、redis shell
一、说明
redis中提供了redis-cli、redis-server、redis-benchmark等shell工具,这些工具有时候可以巧妙地解决一些问题。
二、redis-cli
之前连接客户端时,就使用过 redis-cli -h -p的命令。但在redis-cli中还有其他的有用的参数,可以使用redis-cli -help查看其所有参数。下面对于一些重要的参数进行说明。
1、 -r
repeat表示将命令执行多次,例如redis-cli -r 3 ping 则表示将ping这个命令执行三次
2、 -i
interval表示每隔几秒执行一次命令,但是-i和-r必须一起使用。例如
redis-cli -r 5 -i 1 ping 表示每秒执行一次(单位为秒),一共执行5次。
又如:每隔1秒输出内存的使用量,一共输出100次
3、-x
-x选项代表从标准输入(stdin)读取数据作为redis-cli的最后一个参数,例如下面的操作会将字符串world作为set hello的值:
4、-c
-c(cluster)选项是连接Redis Cluster节点时需要使用的,-c选项可以防止moved和ask异常
5.-a
如果Redis配置了密码,可以用-a(auth)选项,有了这个选项就不需要手动输入auth命令。
6.--scan和--pattern
--scan选项和--pattern选项用于扫描指定模式的键,相当于使用scan命令。7.--slave
--slave选项是把当前客户端模拟成当前Redis节点的从节点,可以用来获取当前Redis节点的更新操作。合理的利用这个选项可以记录当前连接Redis节点的一些更新操作,这些更新操作很可能是实际开发业务时需要的数据。
案例:
开启第一个客户端,使用--slave选项,看到同步已完成:
再开启另一个客户端做一些更新操作:
第一个客户端会收到Redis节点的更新操作:
其中ping命令是由于主从复制产生的,后面再说明。
8、--rdb
--rdb选项会请求Redis实例生成并发送RDB持久化文件,保存在本地。可使用它做持久化文件的定期备份。(有关备份的后面会说明)
9.--pipe
--pipe选项用于将命令封装成Redis通信协议定义的数据格式,批量发送给Redis执行,有关Redis通信协议将在后面讲,例如下面操作同时执行了set hello world和incrcounter两条命令:
10.--bigkeys
--bigkeys选项使用scan命令对Redis的键进行采样,从中找到内存占用比较大的键值,这些键可能是系统的瓶颈。
11.--eval
--eval选项用于执行指定Lua脚本,有关Lua脚本的使用后面再讲。12、--latency
latency有三个选项,分别是--latency、--latency-history、--latency-dist。它们都可以检测网络延迟,对于Redis的开发和运维非常有帮助。
(1)--latency
该选项可以测试客户端到目标redis的网络延迟:例如
此时客户端B到redis的网络延迟:
客户端A到redis的网络延迟:
(2)--latency-history
--latency的执行结果只有一条,如果想以分时段的形式了解延迟信息,可以使用--latency-history选项:
可以看到延时信息每15秒输出一次,可以通过-i参数控制间隔时间
(3)--latency-dist
该选项会使用统计图表的形式从控制台输出延迟统计信息。13.--stat
--stat选项可以实时获取Redis的重要统计信息,虽然info命令中的统计信息更全,但是能实时看到一些增量的数据(例如requests)对于Redis的运维还是有一定帮助的,如下所示:
14.--raw和--no-raw
--no-raw选项是要求命令的返回结果必须是原始的格式,--raw恰恰相反,返回格式化后的结果。
在Redis中设置一个中文的value:
如果正常执行get或者使用--no-raw选项,那么返回的结果是二进制格式:
如果使用了--raw选项,将会返回中文:
$redis-cli --raw get hello 你好三、redis-server
之前说过redis-server可以用来开启redis服务,而redis-server除了可以用来启动redis外,还有一个--test-memory选项。 该选项可以用来检测当前操作系统能否稳定的分配指定容量给redis,通过这种检测可以有效避免因为内存问题造成Redis崩溃,例如下面操作检测当前操作系统能否提供1G的内存给Redis:
redis-server --test-memory 1024整个内存检测的时间比较长。当输出passed this test时说明内存检测完毕,最后会提示--test-memory只是简单检测,如果有质疑可以使用更加专业的内存检测工具:
通常无需每次开启Redis实例时都执行--test-memory选项,该功能更偏向于调试和测试,例如,想快速占满机器内存做一些极端条件的测试,这个功能是一个不错的选择。
四、redis-benchmark(用于性能测试)
redis-benchmark可以为Redis做基准性能测试,它提供了很多选项帮助开发和运维人员测试Redis的相关性能,下面分别介绍这些选项。
1.-c
-c(clients)选项代表客户端的并发数量(默认是50)。
2.-n<requests>
-n(num)选项代表客户端请求总量(默认是100000)。
例如redis-benchmark -c 100 -n 20000代表100个客户端同时请求Redis,一共执行20000次。redis-benchmark会对各类数据结构的命令进行测试,并给出性能指标:
例如上面一共执行了20000次get操作,在0.27秒完成,每个请求数据量是3个字节,99.11%的命令执行时间小于1毫秒,Redis每秒可以处理73529.41次get请求。
3.-q
-q选项仅仅显示redis-benchmark的requests per second信息,例如:
4.-r
在一个空的Redis上执行了redis-benchmark会发现只有3个键:
如果想向Redis插入更多的键,可以执行使用-r(random)选项,可以向Redis插入更多随机的键。$redis-benchmark -c 100 -n 20000 -r 10000-r选项会在key、counter键上加一个12位的后缀,-r10000代表只对后四位做随机处理(-r不是随机数的个数)。例如上面操作后,key的数量和结果结构如下:
5.-P
-P选项代表每个请求pipeline的数据量(默认为1)。
6.-k<boolean>
-k选项代表客户端是否使用keepalive,1为使用,0为不使用,默认值为1。
7.-t
-t选项可以对指定命令进行基准测试。
8.--csv
--csv选项会将结果按照csv格式输出,便于后续处理,如导出到Excel
等。

三、Pipeline
一、概念
redis客户端执行一条任务分为四个过程:
1、发送命令。2、命令排队。3、命令执行。4、返回结果其中1+4称为Round Trip Time(RTT,往返时间)
redis中提供的批量操作命令能有效的节约RTT,但大部分命令是不支持批量操作的,例如执行n次的hgetall,此时就需要消耗n次RTT。客户端和服务端远程情况下也会增大RTT的消耗。
Pipeline(流水线)机制可以改善上面的问题,该机制会将一组redis命令(多个命令)进行组装,通过一次RTT传输给redis,然后再将这组redis命令的执行结果按顺序返回给客户端。(不用该机制的话多条命令会出现多次RTT,而如果一次进行组装后一起发给redis则只需要一次RTT)
RTT在不同网络环境下会有不同,例如同机房和同机器会比较快,跨机房跨地区会比较慢。Redis命令真正执行的时间通常在微秒级别,所以才会有Redis性能瓶颈是网络这样的说法。
redis-cli的--pipe选项实际上就是使用Pipeline机制,例如下面操作将set hello world和incr counter两条命令组装:
但大部分开发人员更倾向于使用高级语言客户端中的Pipeline,目前大部分Redis客户端都支持Pipeline,我们将介绍如何通过Java的Redis客户端Jedis使用Pipeline功能。
二、性能测试
三、原生批量命令与Pipeline对比
1、原生批量命令是原子的,Pipeline是非原子的。
2、原生批量命令是一个命令对应多个key,Pipeline支持多个命令。
3、原生批量命令是Redis服务端支持实现的,而Pipeline需要服务端和客户端的共同实现。四、实践
Pipeline虽然好用,但是每次Pipeline组装的命令个数不能没有节制,否则一次组装Pipeline数据量过大,一方面会增加客户端的等待时间,另一方面会造成一定的网络阻塞,可以将一次包含大量命令的Pipeline拆分成多次较小的Pipeline来完成。
Pipeline只能操作一个Redis实例,但是即使在分布式Redis场景中,也可以作为批量操作的重要优化手段。后面会讲。

四、事务和Lua
为了保证多条命令组合的原子性,redis提供了简单的事务功能以及集成Lua脚本来解决这个问题。
一、事务
redis提供了简单的事务功能,将一组需要一起执行的命令放到multi和exec两个命令之间。
其中multi代表事务开始,exec代表事务结束。在他们之间的命令是原子顺序执行的。
案例:我们开启一个事务,然后继续sadd操作,发现返回的都是QUEUED,这个代表命令并没有真正执行,而是暂存在redis中。
如果此时另一个客户端查看没执行的数据,会发现返回的是0
而我们此时将这个事务提交,提交后再次查看内容,就会发现内容已经存在了。
如果我不想提交事务,则可以用discard来代替exec命令去停止事务,停止后去查看数据就发现返回的是0.
我们上面的结果都是假设事务中的命令可以正常执行,那么如果此时有部分命令是错误的,redis的处理机制是怎样的?
1、命令错误时(语法错误)
只要有一个命令语法错误,会造成整个事务无法执行。(例如set写错sset)
2、运行时错误(例如list类型的添加原本是sadd,现在被当成zset写成zadd命令)
此时因为语法是对的,那么此时事务中会执行可以执行的命令。
我们在一些场景中,希望执行事务前,事务中的ke没有被其他客户端修改,没被修改才能执行事务,否则不执行(类似乐观锁),redis也提供了watch命令来解决这类问题,
例如下面的这个案例事务就没执行成功:
客户端1在事务前先对key进行watch监听,然后开启事务,在事务执行前,监听到客户端2对key进行了修改。所以这就会导致客户端1的事务执行不成功。
之所以说redis的事务简单,就是他不支持事务中的回滚特性,同时无法实现命令之间的逻辑关系计算,当然也体现了Redis的“keep it simple”的特性。
而redis中支持的lua脚本通用可以实现事务相关的功能。
二、Lua
lua的设计目标就是作为嵌入式程序移植到其他应用程序中,他是由c语言实现的,很多游戏领域都使用过lua脚本(魔兽世界、愤怒的小鸟),nginx、redis都将lua作为扩展增强自身的功能。
1、数据类型及逻辑处理
lua提供booleans(布尔)、numbers(数值)、strings(字符串)、tables(表格)。
1)、定义一个字符串,local代表是局部变量,没有local则表示全局变量。print可以大于变量值
2)、定义一个数组,redis的数组用tables类型,和其他语言不同的是lua的数组下标从1开始计算的。
local tables myArray = {"redis", "jedis", true, 88.0}如果我们此时想遍历这个数组,则可以用for和while。
3)、for
for遍历计算1到100的和,其中end为结束符,do为开始。for i=1,100 表示从1开始递增循环。--为注释符
for遍历数组:遍历数组时,需要将数组的长度,而#myArray就是返回tables的长度。
除此外,lua还提供了内置函数ipairs,可以使用该函数(for index,value in ipairs(tables))进行遍历tables的所有索引下标和值。
4)、while
同样计算1到100的和,同样while以do开始,end结束。
5)、if else
案例:确定数组中是否包含了jedis,有则打印true。其中if else以end结尾,if的执行语句以then开头。
6)、哈希
要使用类似hash的功能,同样可以用到tables类型(tables本身就是表格,可以一列数据对应数组,也可以两列数据对应hash),例如下面定义了一个tables,每个元素包含了key和value,其中strings1..string2是将两个字符串进行连接。
如果要遍历这个hash,可以使用之前的pairs函数
7)、函数定义
以function开头,以end结尾,funcName是函数名,中间部分是函数体。
如果想要知道其他的lua语法可以看其官网。
三、redis中怎么使用Lua
1、在redis中使用Lua
在redis中执行Lua脚本有两种方法:eval 和 evalsha
1)、eval
eval 脚本内容 key 个数 key 列表 参数列表例如:
其中KEYS[1]会赋值为redis,ARGV[1]被赋值为world,所以最终输出的结果是hello redisworld。
如果lua脚本比较长,此时可以用redis-cli --eval 命令去执行脚本文件。(eval命令和--eval参数本质是一样的,执行脚本文件也是将脚本文件的内容传给服务端进行执行)。
2)、evalsha
除了eval外,redis还提供了evalsha来执行lua脚本。
首先会将lua脚本加载到redis服务端(使用redis-cli script load命令进行加载),客户端会得到该脚本的SHA1校验和,然后客户端执行evalsha命令会使用HSA1作为参数直接去执行相应的lua脚本(脚本会常驻服务端),这样就不会出现同样的脚本内容,多次发送的消耗(做到了脚本的复用)。
例如:将脚本lua_get.lua加载到redis中,得到对应的SHA1
根据得到的SHA1,使用evalsha命令进行执行。
evalsha 脚本 SHA1 值 key 个数 key 列表 参数列表
2、lua的redis API
lua脚本可以使用redis.call函数实现对redis的访问,例如:对redis进行set、get操作
除此之外Lua还可以使用redis.pcall函数实现对Redis的调用,redis.call和redis.pcall的不同在于,如果redis.call执行失败,那么脚本执行结束会直接返回错误,而redis.pcall会忽略错误继续执行脚本,所以在实际开发中要根据具体的应用场景进行函数的选择。
注意:
Lua可以使用redis.log函数将Lua脚本的日志输出到Redis的日志文件中,但是一定要控制日志级别。
Redis3.2提供了Lua Script Debugger功能用来调试复杂的Lua脚本,具体可以参考:http://redis.io/topics/ldb。
3、案例
lua脚本在redis的执行是原子执行的,执行过程不受其他影响。
lua脚本可以让开发人员创造自定义的命令,然后将这些命令常驻redis内存中,实现复用的效果。
lua脚本可以一次将多条命令进行打包,可以减少网络开销。
下面列举一个简单的例子进行说明:
先假如redis中存在一个用户列表list,列表有5个元素如下:
其中在redis中又存在String类型的key——user:{id}:ratio,value——用户热度。如下:
现在我们要做的就是将所有用户的热度进行加1操作,并且保证过程是原子执行,此时就可以用lua脚本进行实现。
1)、先将用户列表取出并赋值给mylist。(KEYS[1]是用来执行redis-cli --eval时接收外部参数的)
local mylist = redis.call("lrange", KEYS[1], 0, -1)2)、定义一个局部遍历count,用来统计incr的总次数
local count = 03)、遍历得到的mylist,并进行+1操作。最后返回count。
这时将上面的三步都写入lrange_and_mincr.lua文件中,然后执行该脚本文件(给第一句传个参hot:user:list)。然后会得到执行结果为5。
脚本执行后我们再去发现这些用户的热度都实现了自增1:
4、redis如何管理lua脚本
redis提供了4个命令进行管理lua脚本。
1)、script load
script load “脚本内容”
前面就是用这个将脚本内容加载到redis中的。
2)、script exists
script exists sha1编码 判断该sha1是否已经加载到redis中了
3)、script flush
用于清除redis内存已经加载了的lua脚本。
4)、script kill
用于杀死正在执行的lua脚本(一般用于脚本执行时间长,脚本存在问题,长时间阻塞)
案例:现在我们执行一个会产生死循环的脚本内容:
127.0.0.1:6379> eval 'while 1==1 do end' 0在redis中有一个lus-time-limit参数,默认是5秒,当一个lua脚本执行超过这个时间时,客户端再进行命令调用时,就会提示“Busy Redis is busy running a script”错误,并且提示使用script kill或者shutdown nosave命令来杀掉这个busy的脚本:
如果你想杀掉这个正在运行的脚本,此时使用shutdown save显然不太优雅,就可以直接执行script kill命令进行中断lua脚本执行。此时客户端就会恢复调用。
注意:
如果此时的lua脚本执行的是写操作,此时script kill是不生效的,这个时候就只能使用shutdown save强行停掉redis的服务。(但是随意的关闭redis是有一定风险的,所以虽然lua脚本强大,但有时候还是具有一定的破坏性的)
例如我们模拟一个写操作:
此时执行script kill会收到如下异常信息:


五、Bitmaps
1、数据结构模型
现在计算机中使用二进制(位)作为信息的基础单位,一个字节等于8位。
许多语言都提供了操作位的功能,合理的使用位可以有效的提高内存使用率和开发效率。redis中也提供了bitmaps这个数据结构实现对位的操作。
其实bitmaps本身并不是一种数据结构,而是字符串,但是他可以对字符串的位进行操作。
bitmaps自己单独的提供一套命令,所以其用法和字符串不太一样。其实可以把他看出一个以位为单位的数组,数组的元素只能存0或1,数组的下标再bitmap是中被叫做偏移量。
2、命令
这里以一个案例来讲解bitmaps的命令。
案例:我们使用Bitmaps来存储用户是否登录过该网站,访问过的用户记为1,没访问过的用户记为0,用户的id作为偏移量offset。
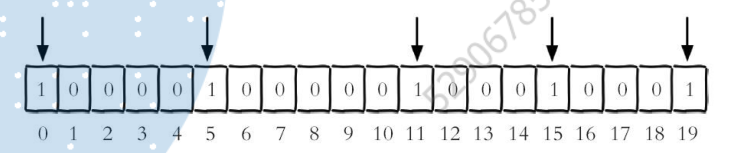
1)、设置值
setbit key offset value假设我们有20个用户,userid为0、5、11、15、19的用户对网站访问过了,那么此时的Bitmaps结果如下:
那如果此时用户id都是1000起步,那此时0-999都没人使用,此时势必会造成一定的浪费,对于这种情况一般可以让每个id的值减掉某个特定的值,从而减少0-999的空间浪费。
2)、获取值
getbit key offset获取指定offset位的值(从0开始算起),返回0代表没访问过。
3)、获取指定范围且值1的个数
bitcount [start][end]start表示开始字节数(每个字节8位),end表示结束字节数
例如:计算2016-04-05这天的独立访问用户数量:
例如:计算用户id在第1个字节到第3个字节之间的独立访问用户数
4)、Bitmaps间的运算
bitop op destkey key[key....]其中op代表and、or、not、xor等操作,destkey表示操作后的结果(结果Bitmaps),key[key....]表示被操作的多个bitmaps。bitop是一个复合操作,它可以做多个Bitmaps的and(交集)、or(并集)、not(非)、xor(异或)操作并将结果保存在destkey中
例如:计算出2016-04-04和2016-04-03两天都访问过网站的用户数
如果想算出2016-04-04和2016-04-03任意一天都访问过网站的用户数量(例如月活跃就是类似这种),可以使用or求并集,命令如下:
5)、查找bitmaps中某个值第一次出现的偏移量
targetBit表示某个值例如1或者0,start和end表示开始和结尾的字节位置(限制范围)。
bitpos key targetBit [start] [end]3、Bitmaps分析
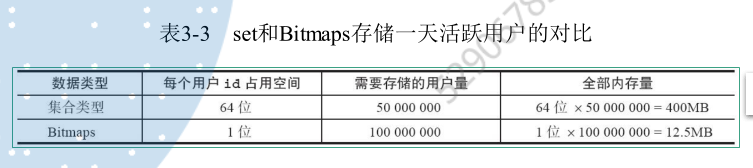
我们现在假设有1亿用户,每条访问的用户有5千万,如果用集合类型和Bitmaps分别存储会有以下对比:
由此可见,Bitmaps可以节省很多内存空间。
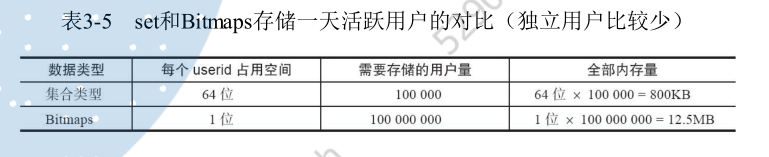
但是如果每天访问的用户很少,例如只有10万,那么·此时对比:
此时bitMaps明显不太适应。


六、HyperLogLog
HyperLoglog并不是一种新的数据结构(实际类型是字符串类型),而是一种计数算法,HyperLoglog可以利用极小的内存空间完成独立总数的统计,数据集可以是IP、Email、ID等。
HyperLoglog提供了3个命令:pfadd、pfcount、pfmerge。
1、pfadd(添加数据)
pfadd key element [element … ]可以添加多个element。例如添加多个元素
2、pfcount(计数数量)
计算一个或多个HyperLoglog的数量
例如:
我们比较一些集合类型和HperLogLog再存储百万级别的用户时占用空间对比:
可以看出HyperLogLog的内存占用非常少,但是他存在一个弊端就是用如此小的内存来估算如此巨大的数据,是会存在一定的误差,也就是是不可能100%正确,redis官方给出的数字是0.81%的失误率。
3、pfmerge(合并)
多个目标key合并到一个目标key
pfmerge destkey sourcekey [sourcekey ...]例如:要计算2016年3月5日和3月6日的访问独立用户数。
HyperLogLog内存占用量非常小,但是存在错误率,开发者在进行数据结构选型时只需要确认如下两条即可:
1)、只为了计算独立总数,不需要获取单条数据。(只是用来统计大概的总数)
2)、可以容忍一定误差率,毕竟HyperLogLog在内存的占用量上有很大的优势。

七、发布订阅
在redis中提供了“发布/订阅”模式的消息机制,这种模式下消息发布者和订阅者不进行直接通信,他们之间通过频道(channel)来发布和订阅消息。客户端可以向该channel发布消息,然后其他客户端可以去订阅这个channel,
一、命令
1、发布消息
publish channel message例如向名为channel:sports的channel频道发布提条信息。返回结果是订阅者个数。
2、订阅消息
可以订阅多个频道。
subscribe channel [channel ...]例如订阅channel:sports频道
此时往这个频道发送消息:
此时订阅者就会接收到这个信息
有关订阅命令有两点需要注意:
(1)客户端在执行订阅命令之后进入了订阅状态,只能接收subscribe、psubscribe、unsubscribe、punsubscribe的四个命令。
(2)新开启的订阅客户端,无法收到该频道之前的消息,因为Redis不会对发布的消息进行持久化。3、取消订阅
unsubscribe [channel [channel ...]]4、按照模式的订阅和取消订阅
redis除了上面的订阅和取消订阅的命令,还提供了另一对支持glob风格(可以进行模糊匹配)的订阅和取消订阅的命令(订阅命令psubscribe和取消订阅命令punsubscribe)。
如下:订阅it开头的频道:
5、查询订阅
(1)查看活跃的频道
pubsub channels [pattern]
所谓活跃的频道是指当前频道至少有一个订阅者,其中[pattern]是可以指定具体的模式:
(2)查看频道订阅数
pubsub numsub [channel ...]
当前channel:sports频道的订阅数为2:
(3)查看模式订阅数
pubsub numpat
当前只有一个客户端通过模式来订阅:
二、使用场景
和很多专业的消息队列系统(例如Kafka、RocketMQ)相比,Redis的发布订阅略显粗糙,例如无法实现消息堆积和回溯。但胜在足够简单,如果当前场景可以容忍的这些缺点,也不失为一个不错的选择。

八、GEO
redis3.2版本提供了GEO(地理位置定位)功能,支持存储地理位置信息来实现诸如附近位置、摇一摇这类依赖地理位置信息的功能。
1、增加地理位置信息
longitude、latitude、member分别是该地理位置的经度、纬度、成员(可以增加多个)
geoadd key longitude latitude member [longitude latitude member ...]
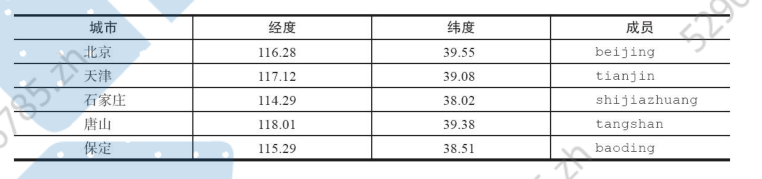
例如我们假如如北京的地理信息
2、获取地理位置信息
geopos key member [member ...]例如获取天津的经纬度:
3、获取两个地理位置的距离:
geodist key member1 member2 [unit]其中unit代表返回结果的单位,包含以下四种:
m(meters)代表米。km(kilometers)代表公里。mi(miles)代表英里。ft(feet)代表尺。例如计数天津到北京的距离,以公里为单位:
4.获取指定位置范围内的地理信息位置集合
georadius和georadiusbymember两个命令的作用是一样的,都是以一个地理位置为中心算出指定半径内的其他地理信息位置,不同的是georadius命令的中心位置给出了具体的经纬度,georadiusbymember只需给出成员即可。其中radiusm|km|ft|mi是必需参数,指定了半径(带单位),这两个命令有很多
可选参数,如下所示:
·withcoord:返回结果中包含经纬度。
·withdist:返回结果中包含离中心节点位置的距离。
·withhash:返回结果中包含geohash,有关geohash后面介绍。
·COUNT count:指定返回结果的数量。
·asc|desc:返回结果按照离中心节点的距离做升序或者降序。
·store key:将返回结果的地理位置信息保存到指定键。
·storedist key:将返回结果离中心节点的距离保存到指定键。
下面操作计算五座城市中,距离北京150公里以内的城市:
5.获取geohash
geohash key member [member ...]将经纬度转化为一维字符串,例如获取北京的:
geohash有如下特点:
·GEO的数据类型为zset,Redis将所有地理位置信息的geohash存放在zset中。
字符串越长,表示的位置更精确,表3-8给出了字符串长度对应的精度,例如geohash长度为9时,精度在2米左右。
两个字符串越相似,它们之间的距离越近,Redis利用字符串前缀匹配算法实现相关的命令。
·geohash编码和经纬度是可以相互转换的。
Redis正是使用有序集合并结合geohash的特性实现了GEO的若干命令。6、删除地理位置信息
zrem key memberGEO没有提供删除成员的命令,但是因为GEO的底层实现是zset,所以可以借用zrem命令实现对地理位置信息的删除。