
- 1ubuntu 22.04 安装redis并设置远程连接_ubuntu redis 远程连接
- 2基于SpringBoot的“外卖点餐系统”的设计与实现(源码+数据库+文档+PPT)_基于springboot的外卖管理系统的设计与实现
- 3git本地更新远程新分支_本地更新远程分支
- 4设置程序默认以管理员身份打开(vs2010)_vc2010 打开项目是管理员,双击项目打开没有管理员
- 5XML解析_xerces2使用
- 6使用 git 提交到指定远程分支_git 提交代码到指定分支
- 7群晖Nas通过jellyfin搭建本地影音库详细全过程(二):jellyfin影音库信息手动刮削和相关设置(100%扫库成功)_jellyfin刮削工具
- 8springcloud光速入门(一) 服务的注册与发现_springcloud:服务注册与发现,负载均衡,服务限流熔断,服务网关,服务配置
- 9OpenCV如何以指定分辨率打开摄像头(C++ / Python代码演示)_opencv摄像头分辨率
- 10【论文阅读】图像修复 - NAFNet
Python列表,元组,集合,字典详解一篇搞懂_python 列表 集合 元组 字典
赞
踩
目录
介绍
在Python中,列表(List)、集合(Set)、字典(Dict)和元组(Tuple)是四种基础且重要的数据结构,它们各有特点和适用场景:
列表(List)
优点:
- 有序性:列表中的元素按照插入的顺序排列,支持索引访问。
- 灵活性:可以动态添加、修改或删除元素,适合用于需要频繁变更的数据集合。
- 异构性:可以容纳不同类型的元素,如整数、字符串、对象等。
区别: 与其他三种相比,列表的主要区别在于其可变性和异构性,但这也使得它在某些情况下不如集合或字典高效。
集合(Set)
优点:
- 唯一性:自动去除重复元素,适合用于需要确保元素唯一性的场景。
- 高效查找:基于哈希表实现,提供了快速的成员测试和交、并、差等集合运算。
- 无序性:不保证元素的顺序,适合于对顺序不敏感的数据处理。
区别: 集合的独特之处在于其唯一性和无序性,适用于需要快速查找和处理无序数据集合的情况。
字典(Dict)
优点:
- 键值对:通过键(必须唯一)快速访问值,提供高效的映射关系存储。
- 灵活性:键可以是几乎任何不可变类型,支持动态添加、修改键值对。
- 无序性:虽然Python 3.7+中字典保持了插入顺序,但本质上字典是无序的。
区别: 字典的核心优势在于键值映射,适合构建复杂的数据结构,如缓存、配置等。
元组(Tuple)
优点:
- 不可变性:一旦创建,元素便不可更改,这有助于保护数据免受意外修改。
- 轻量级:相比于列表,元组在内存占用上更小,因为它是静态数据结构。
- 可作为字典键:由于其不可变性,元组可以直接作为字典的键使用。
区别: 元组的主要特征是不可变性和轻量级,适用于不需要修改的固定数据集合,如函数返回多个值的场景。
列表
列表定义
python的列表使用[] 进行数据定义,列表有序并且可以包含不同的数据类型

进行for循环打印元素

还可以使用列表推导式进行比较优雅的打印
 列表索引是从0开始的
列表索引是从0开始的


或者倒序取最后一个元素,倒序取最后一个元素是以-1,-2,-3这样进行排序

 列表切片
列表切片
python支持使用列表切片进行数据拿取
左侧闭区间,右侧是开区间
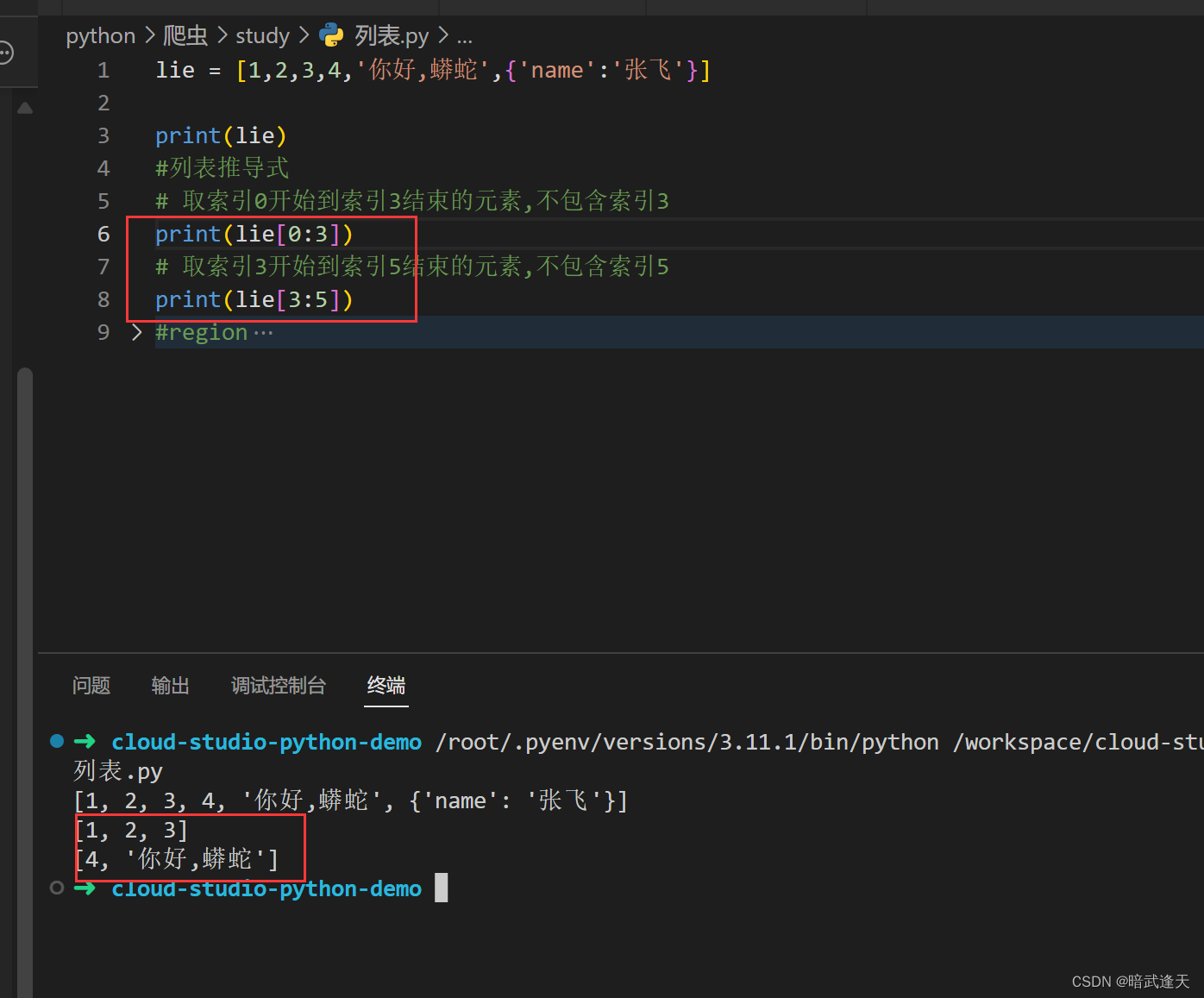
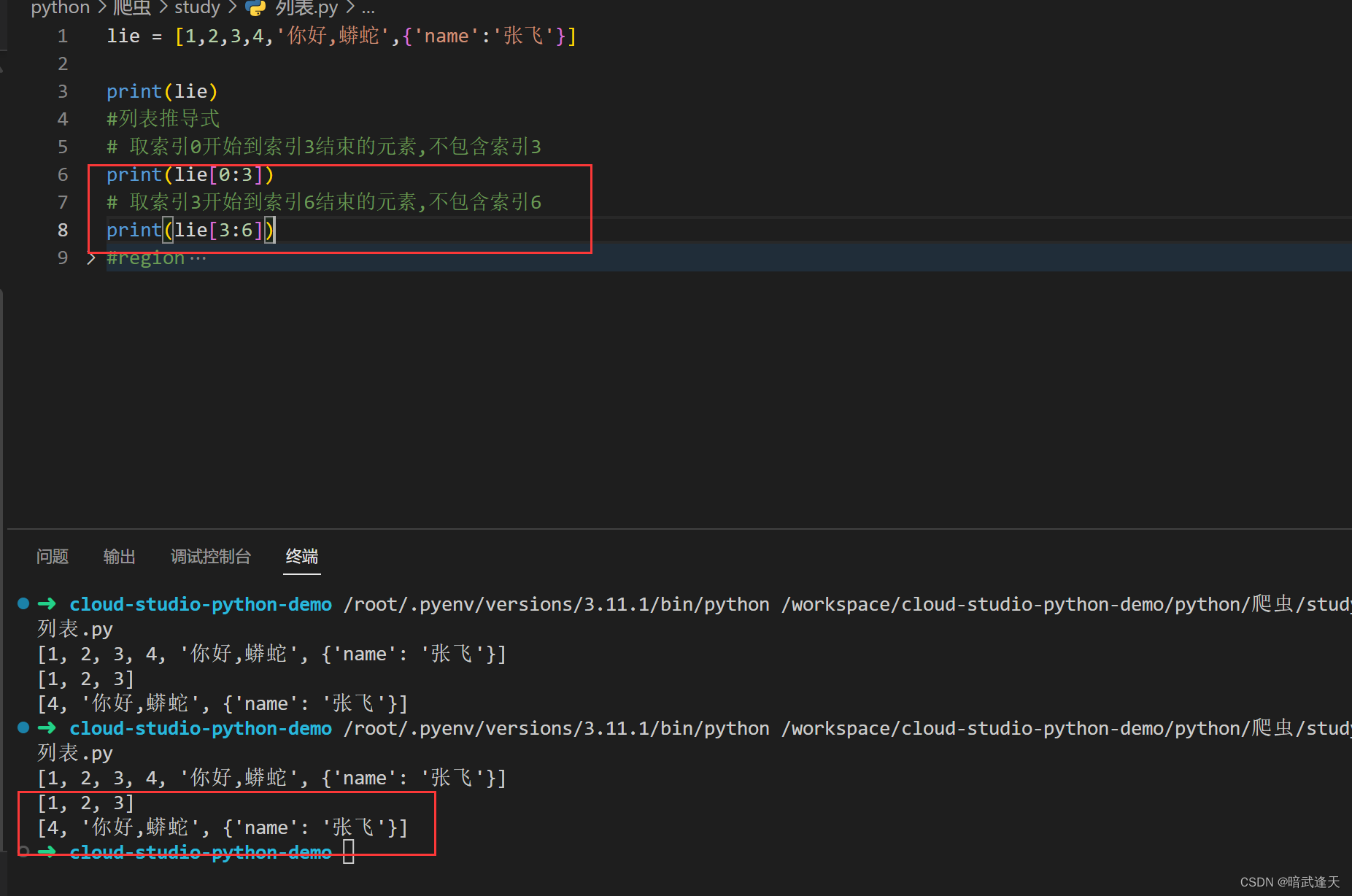
还可以进一步进行化简,从头开始那么头可以省略,到结尾结束,那么结尾也可以省略
 还可以进行跨度取值 再添加一个冒号,冒号后设置跨度步长
还可以进行跨度取值 再添加一个冒号,冒号后设置跨度步长

前面是从开始到结尾那么开始到结尾也可以省略

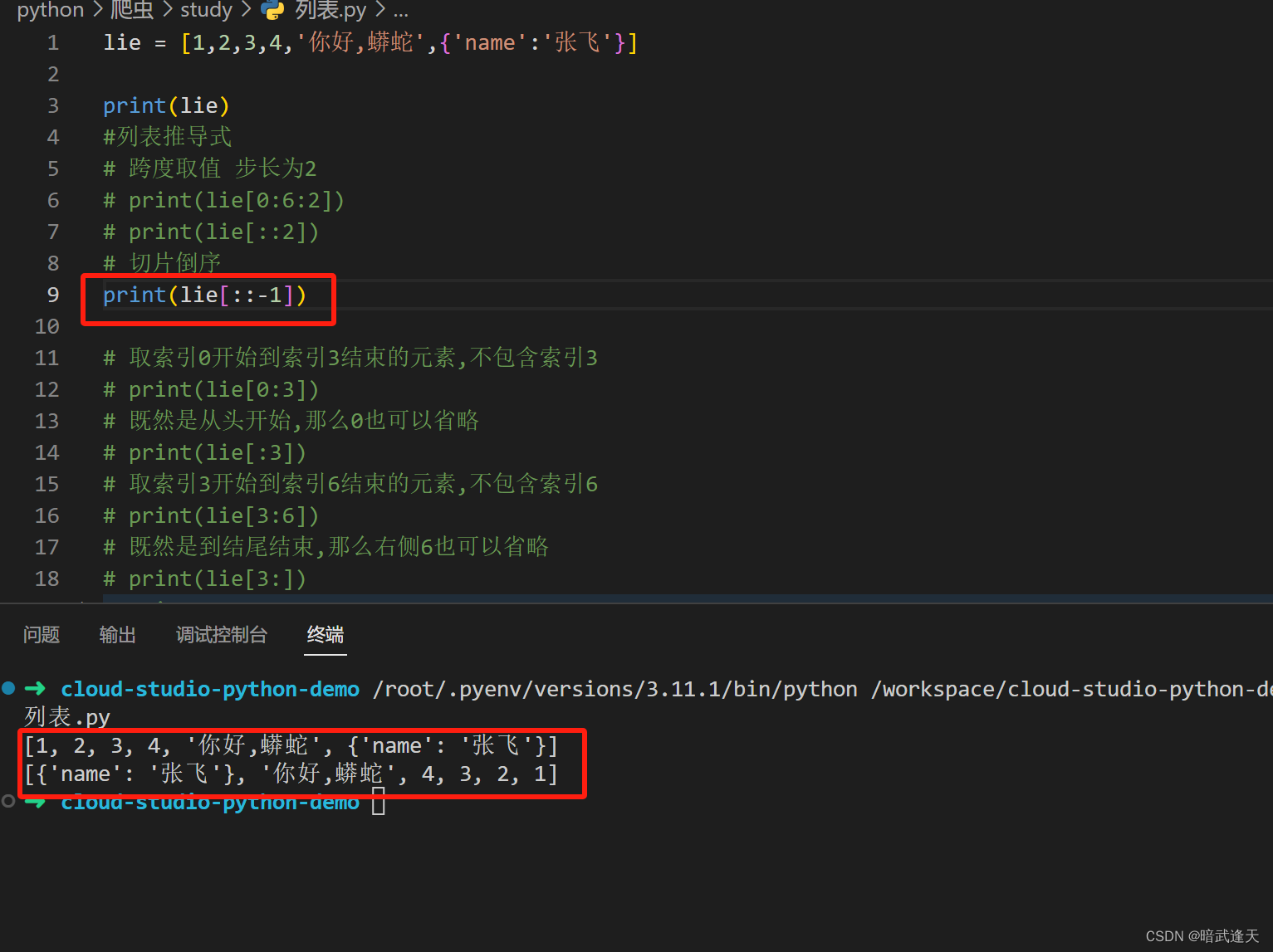
还可以使用切片进行倒序输出
列表常用方法

append
添加一个元素到列表末尾
列表名.append(元素)

当然也可以使用切片来进行元素添加

注意 append方法每次只能添加一个元素 当我们想要一次性添加多个元素时可以使用extend方法
extend
一次性添加多个元素到列表末尾
列表名.extend(可迭代对象)


extend当然也可以使用切片优雅的实现
 insert
insert
在列表的任意位置插入数据
列表名.insert(插入的索引,元素)
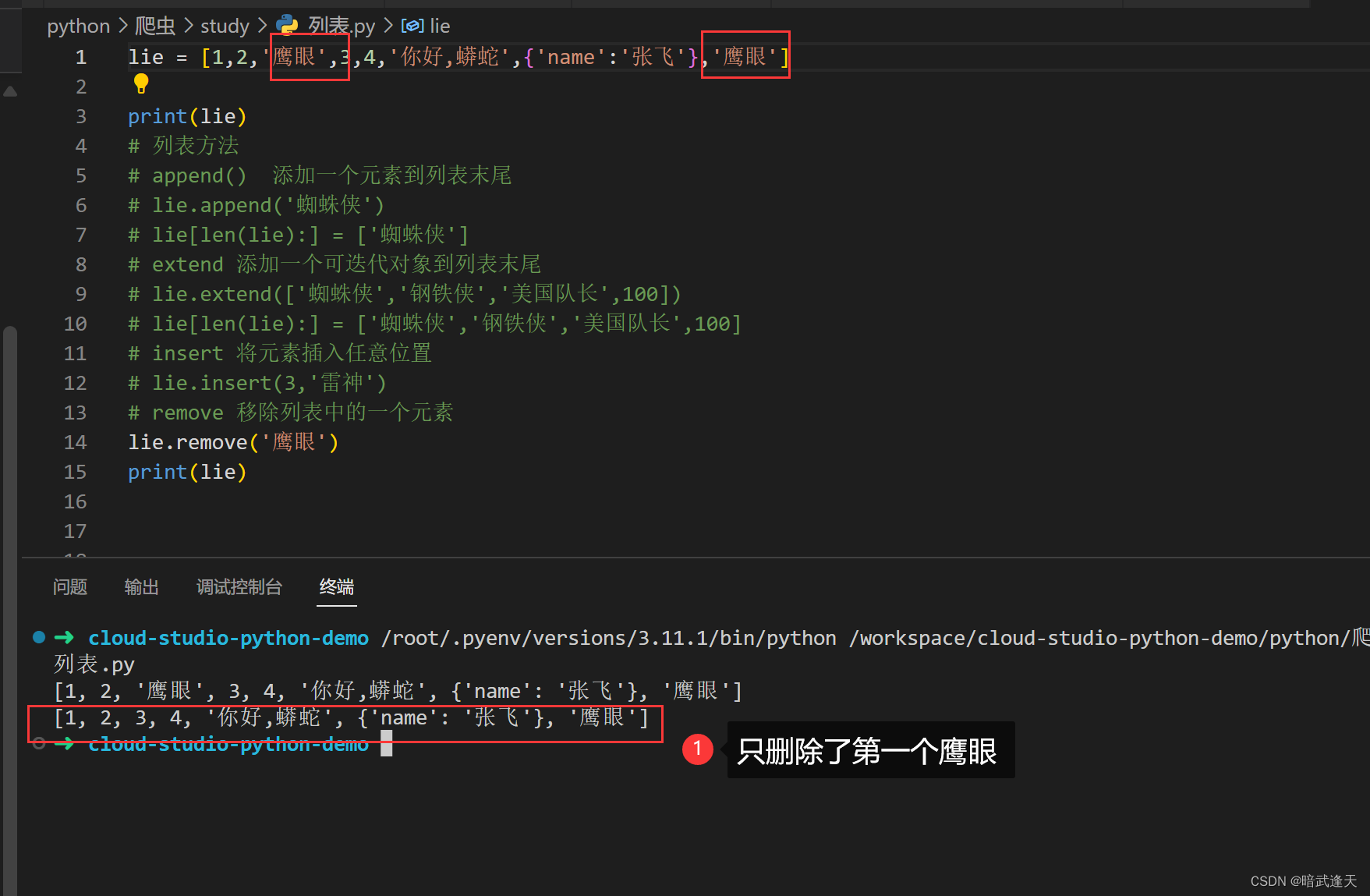
 remove
remove
删除列表中第一个符合条件的元素
列表名.remove(元素)
 注意
注意



pop
删除指定下标元素
列表名.pop(下标索引)
 clear
clear
清空列表元素
列表名.clear()
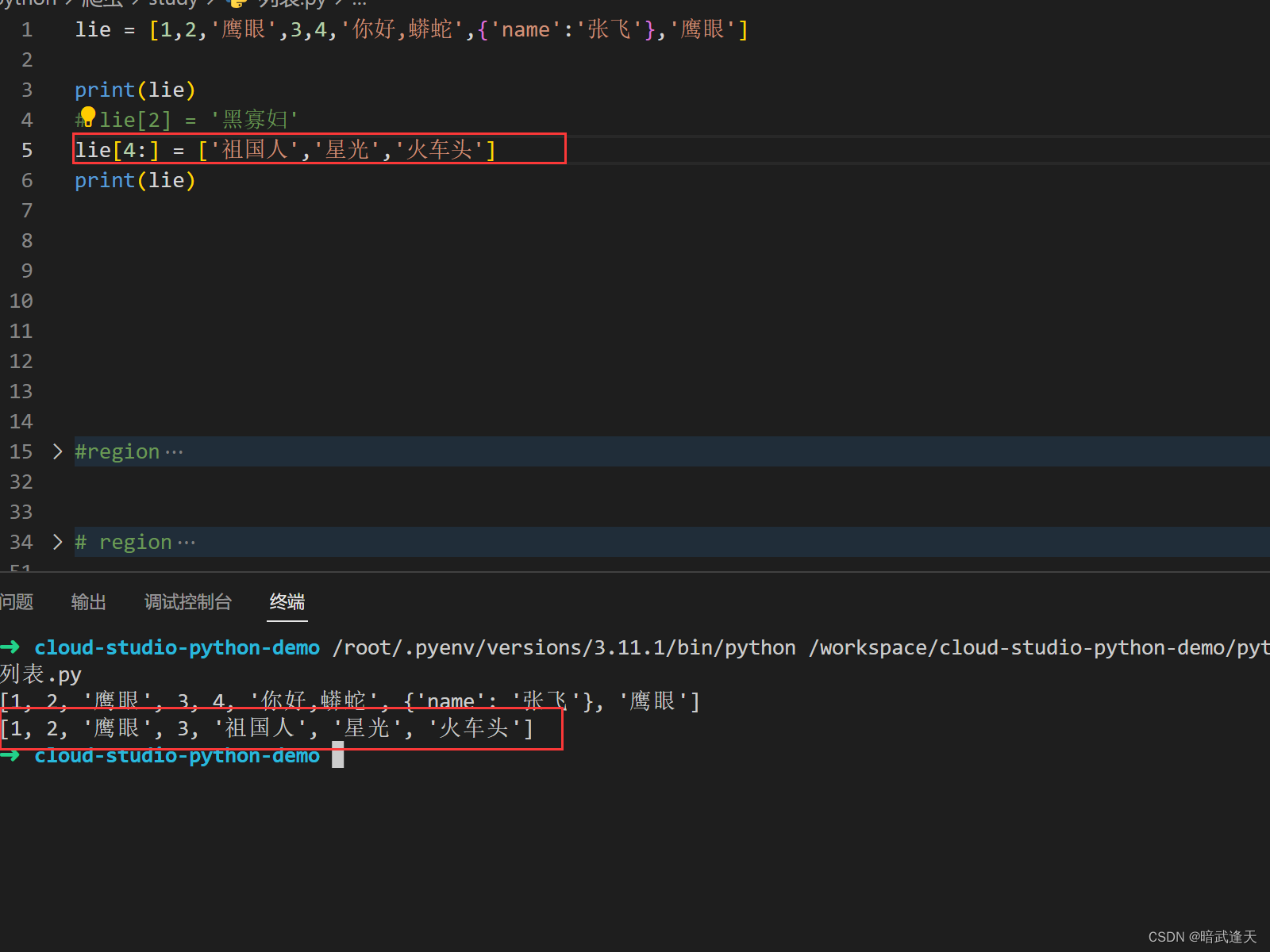
 列表修改元素
列表修改元素
列表是可变的,可以进行任意元素的修改
列表名[下标索引] = 重新赋值元素
 或者使用切片进行多个元素修改,左侧闭区间(包含)
或者使用切片进行多个元素修改,左侧闭区间(包含)

sort

升序
列表数字元素默认升序排列

倒序
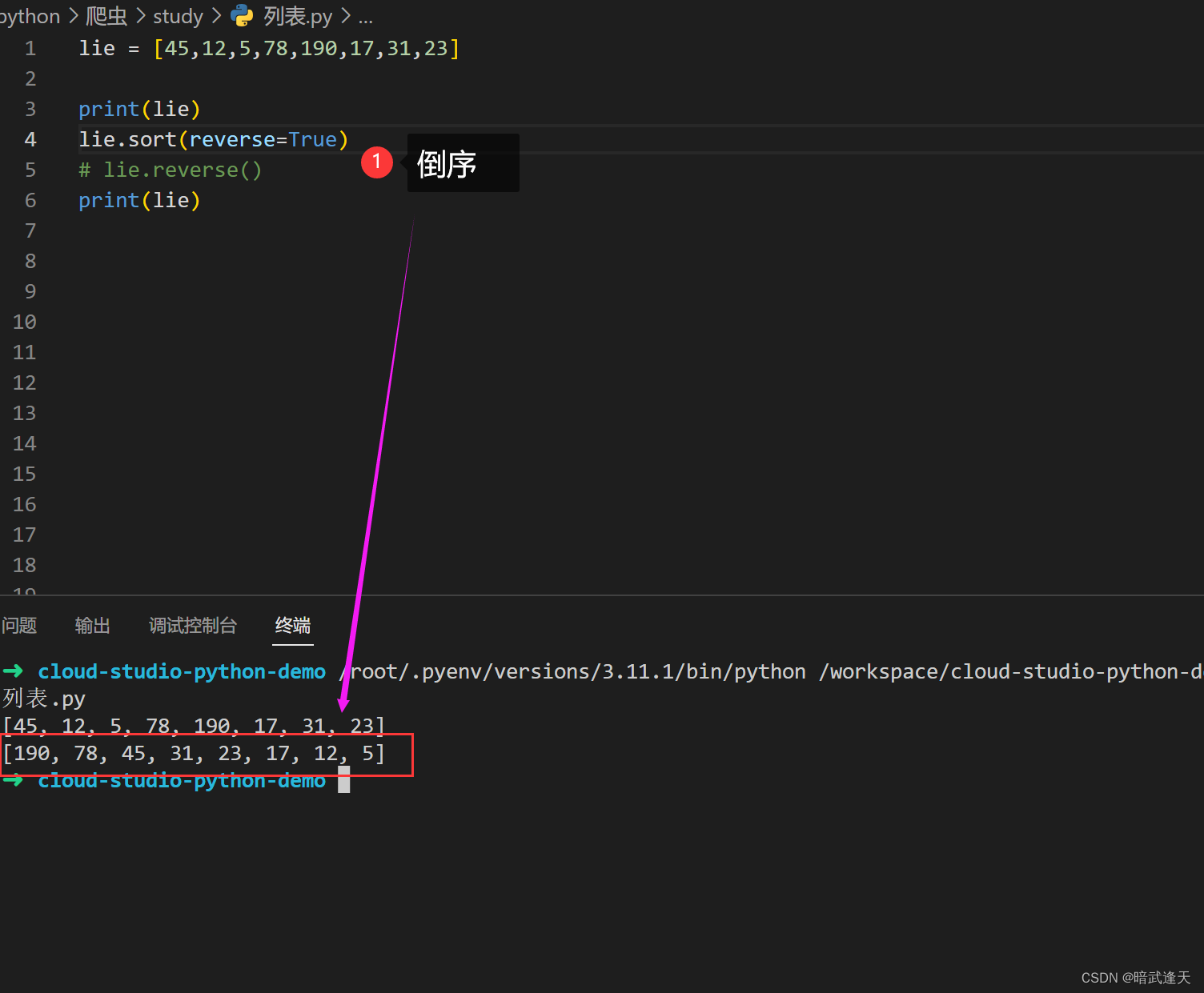
reverse
列表数字元素倒序排列
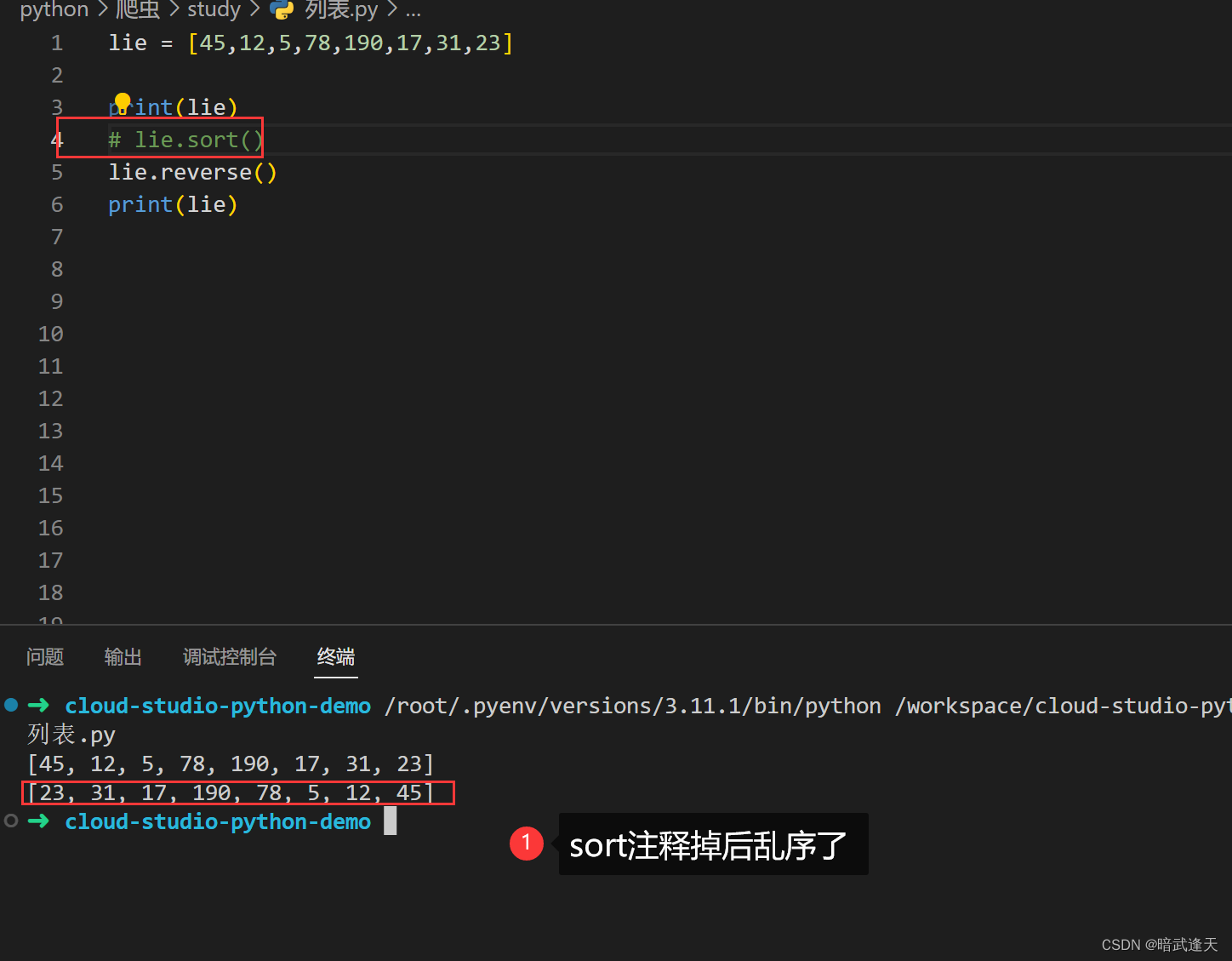
踩坑注意 reverse倒序必须在sort方法先升序排列后再调用倒序,不然会乱序:
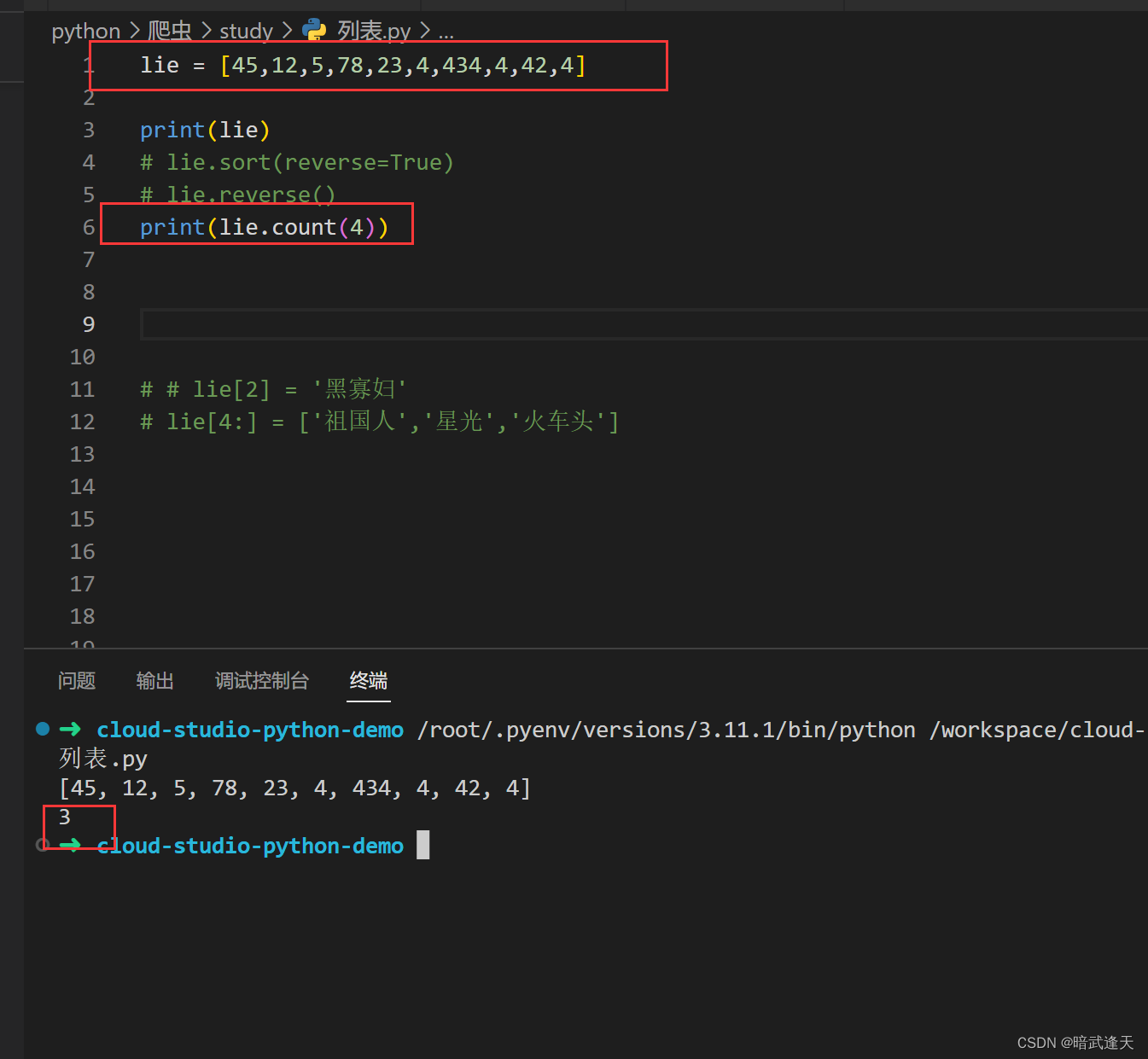
count
返回列表中指定元素的数量
列表名.count(元素)
 index
index
返回指定元素的索引

浅拷贝和深拷贝
在Python中,列表的浅拷贝和深拷贝是两种不同的复制列表数据结构的方式,它们在处理嵌套列表(即列表中包含其他列表)时表现出不同的行为。
浅拷贝
浅拷贝会创建原列表的一个副本,但是这个副本中的元素如果本身是可变对象(如子列表),那么这些元素不会被真正复制,新列表中的这些元素会引用原列表中相同对象的内存地址。换句话说,浅拷贝只拷贝一层,子对象仍然是引用。
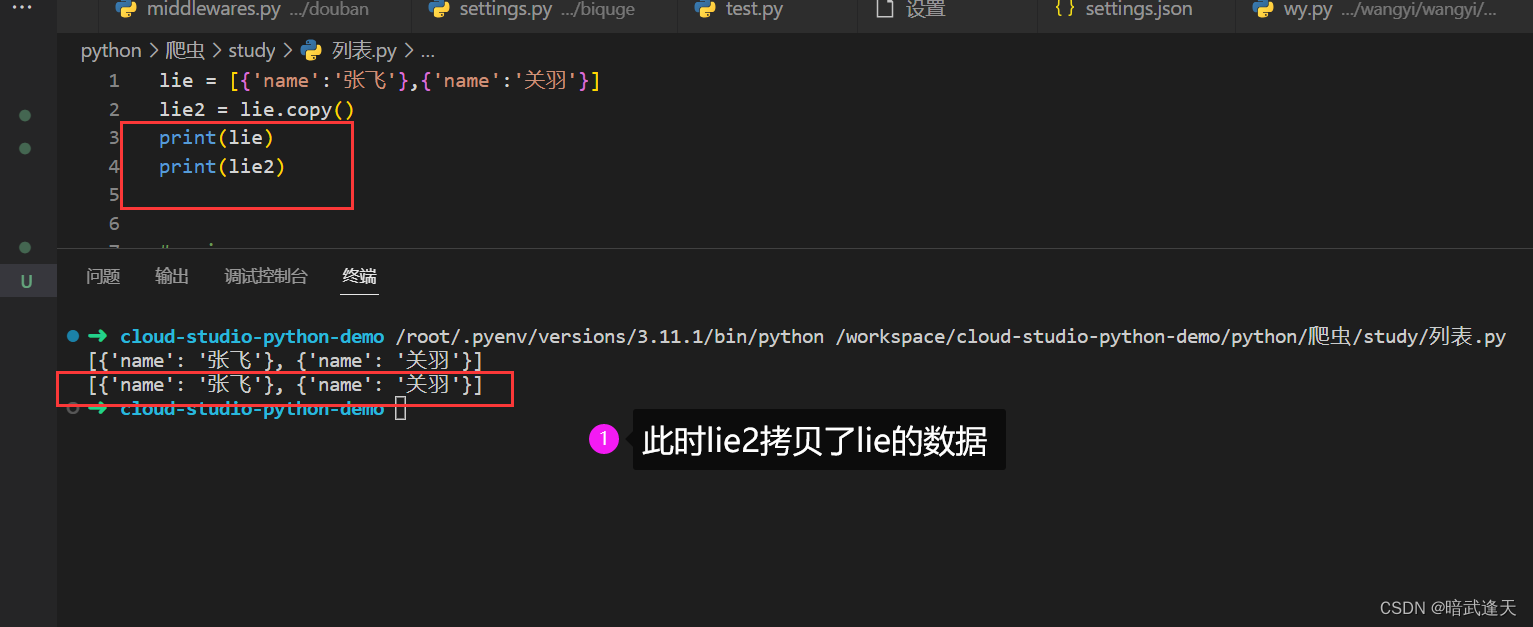
然后我们更改lie的元素数据,查看lie2会有什么变化

说明lie2此时的拷贝是引用拷贝的浅拷贝
深拷贝
深拷贝则会递归地复制列表及其所有子对象,创建一个完全独立的新列表。这意味着修改原列表或其子列表不会影响到通过深拷贝得到的新列表。

两者区别
- 浅拷贝仅复制顶级元素,如果元素是可变对象(如列表、字典等),则拷贝的是这些对象的引用而非实际对象的内容。
- 深拷贝不仅复制顶级元素,还会递归地复制所有子元素,确保原列表和拷贝的列表在内存中是完全独立的,修改一个不会影响另一个。
根据实际需求选择合适的拷贝方式:如果列表中不包含或者不需要关心可变对象的独立性,浅拷贝可能更高效;反之,如果需要完全独立的复制品,应使用深拷贝。
列表的加法和乘法
加法
两个列表之间可以直接进行相加从而形成一个整体

乘法
列表的乘法是直接将列表中的元素进行乘法复制

列表推导式
 列表在书写时可以使用列表推导式来替代原先的for循环写法,且执行速度比for循环更快,因为列表推导式是使用底层c语言来执行的
列表在书写时可以使用列表推导式来替代原先的for循环写法,且执行速度比for循环更快,因为列表推导式是使用底层c语言来执行的
左侧是表达式,右侧是循环元素

循环右侧还可以进行筛选条件的书写

元组
Python的元组(Tuple)是一种不可变的序列类型,它与列表(List)相似,可以存储多个有序的数据项,但元组一旦创建后就不能修改其内容。元组通常用于存储一些固定的数据集合,比如日期、坐标点等,当不需要改变这些数据时,使用元组可以提供更好的性能和安全性。
元组与列表的区别
-
可变性:
- 列表是可变的,意味着你可以对列表进行增删改操作,如
append(),extend(),insert(),remove()等方法。 - 元组是不可变的,一旦创建,你不能更改或删除其中的元素。这使得元组更加安全,因为它们的值不会意外改变。
- 列表是可变的,意味着你可以对列表进行增删改操作,如
-
性能:
- 因为元组的不可变性,访问元组的速度通常比列表快,尤其是在大数据量的情况下,元组的处理更加高效。
-
语法:
- 列表用方括号
[]表示,如[1, 2, 3]。 - 元组用圆括号
()表示,如(1, 2, 3)。
- 列表用方括号
举例

元组的逗号非常重要,两边的括号可以省略

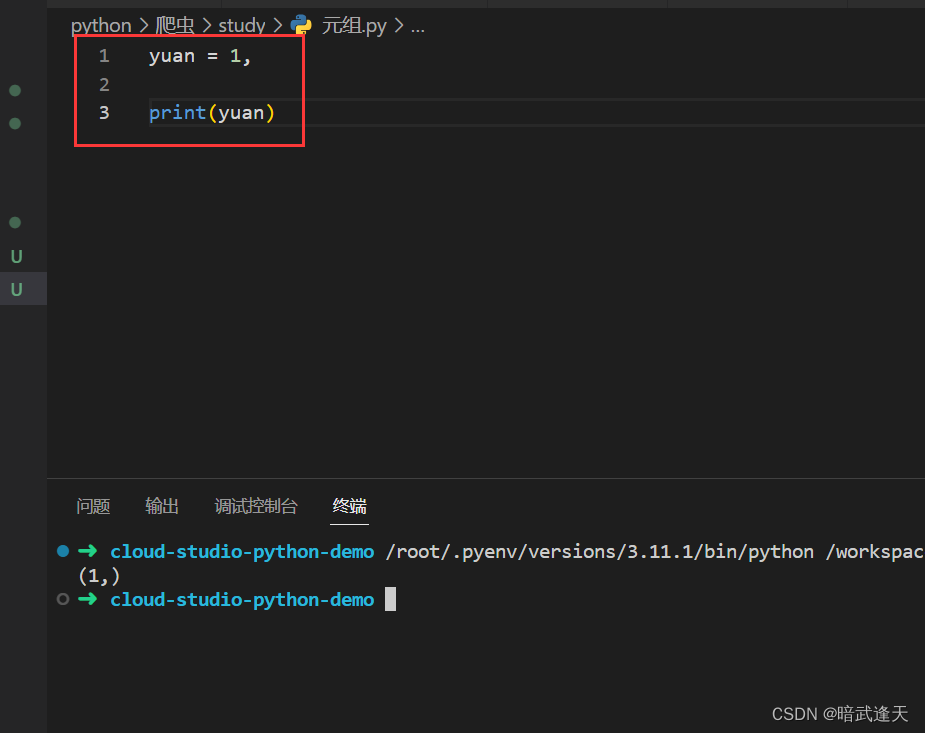
创建只有一个元素的元组

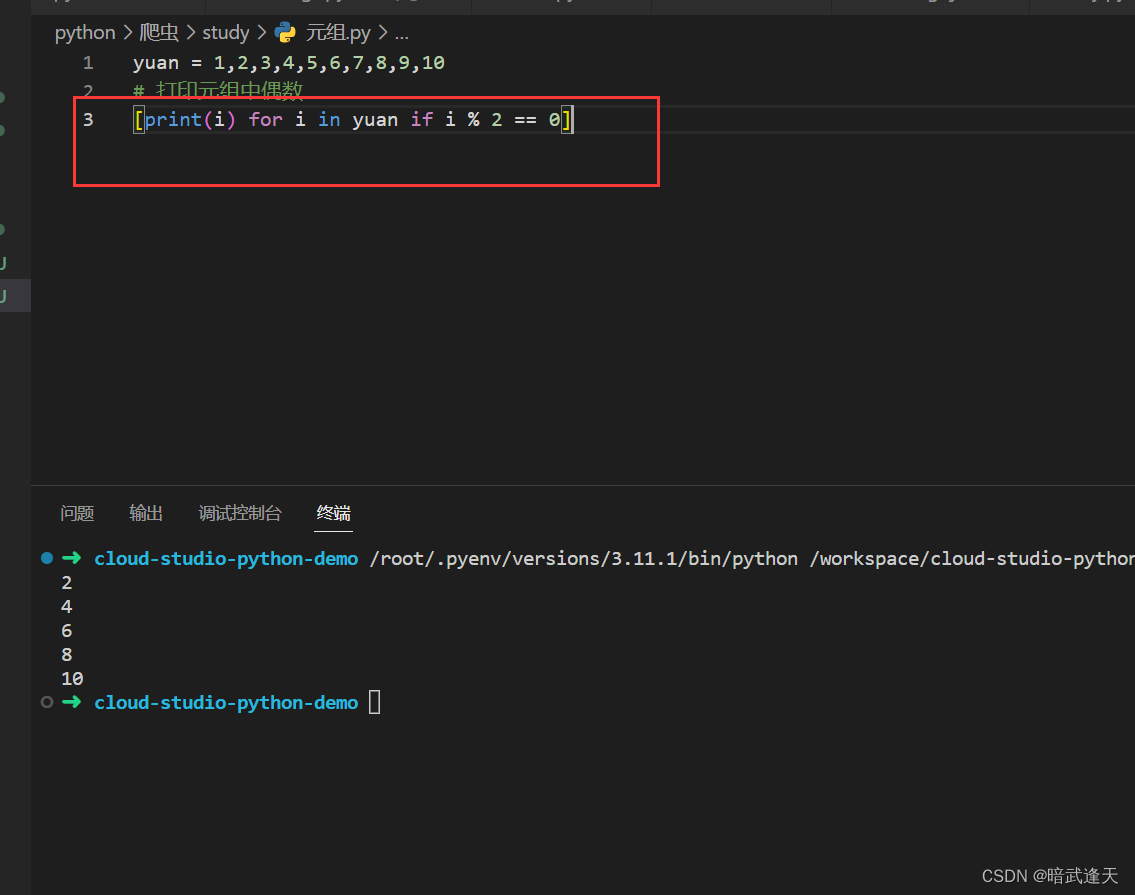
 元组也可以使用列表推导式和切片
元组也可以使用列表推导式和切片

打包和解包
在Python中,元组的“打包”(packing)和“解包”(unpacking)是处理元组时的两个重要概念,它们帮助我们更灵活地操作数据。
元组打包
打包是指将多个值合并成一个元组的过程。实际上,当你直接列出一系列由逗号分隔的值,并用圆括号包围它们时,就已经在进行元组打包了。例如:
Python
1coordinates = (3, 4) # 这里,3和4被"打包"成一个元组在这个例子中,数字3和4通过逗号连接并用圆括号包围,形成了一个包含两个元素的元组。
元组解包
解包则是将元组中的元素分配给单独的变量的过程。这可以通过将元组放在等号左侧,然后是一系列与元组元素数量相等的变量名来实现,每个变量接收元组中的一个元素。例如:
Python
1x, y = coordinates # 这里,元组"coordinates"被"解包"到变量x和y中上面的代码中,coordinates元组的两个元素分别被赋值给了变量x和y,这就是元组解包。
扩展解包
Python还支持一种称为“扩展解包”的操作,使用星号*来收集多余的项为一个新的元组(或列表)。这对于处理不定长的参数列表特别有用。例如:
Python
a, b, c = (1, 2, 3) # 这里,a=1, b=2, c=3,在这个例子中,a接收第一个元素,b接受第二个元素。 c接收最后一个元素,
1a, *b, c = (1, 2, 3, 4, 5) # 这里,a=1, c=5, b=(2, 3, 4)在这个例子中,a接收第一个元素,c接收最后一个元素,而b作为一个新的元组接收剩余的所有元素。
注意 赋值号左边的变亮名数量和右侧序列的数量一定要一致,不然会报错
元组的打包和解包机制为Python编程提供了强大的灵活性,特别是在处理函数参数、返回值以及数据交换等方面。
字典
定义
Python的字典(Dictionary)是一种可变的、无序的、键-值对(key-value pair)的数据结构。字典中的每个元素都是一个键值对,其中键(key)是唯一的,不可变的(通常为字符串、数字或元组),用于快速查找对应的值(value),值可以是任何类型的对象。字典用花括号{}表示,键值对之间用逗号,分隔。
创建字典的六种方式
直接使用{}进行定义
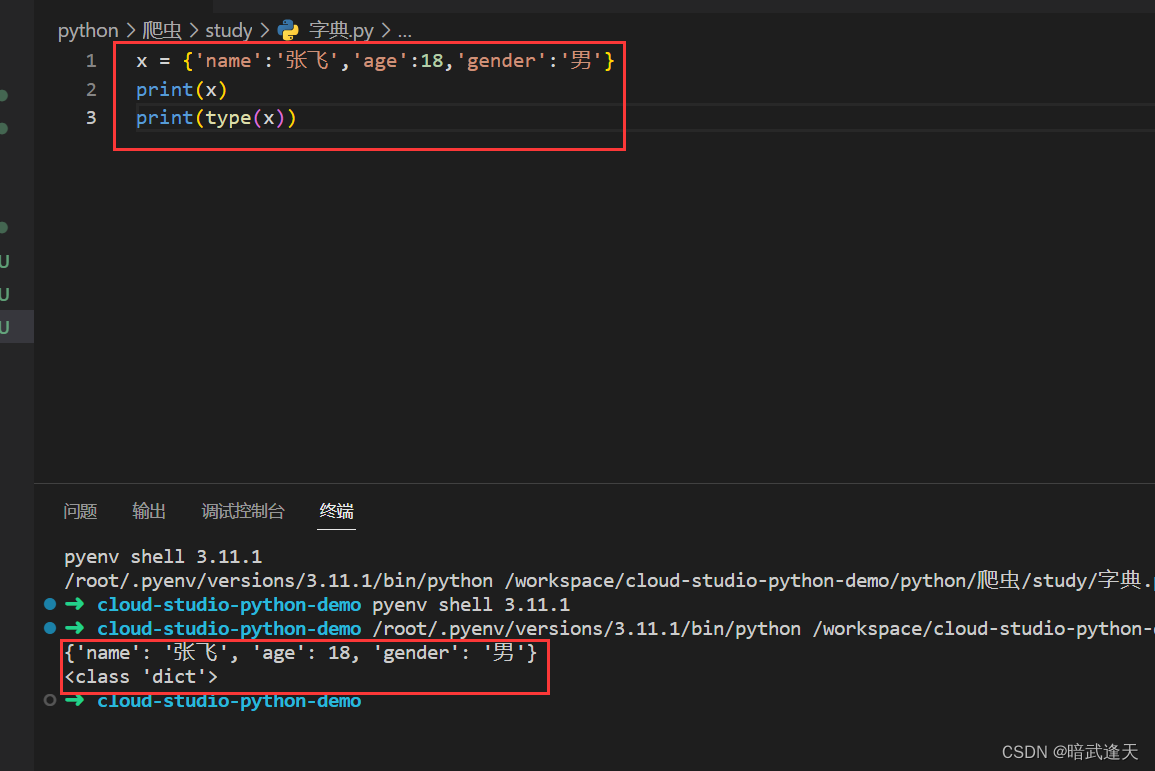
dict定义
注意dict进行定义字典时,字典的key不要加引号

列表元组方式定义

不知道怎么描述的定义╮(╯▽╰)╭
感觉有点脱裤子放屁的味道
混合定义
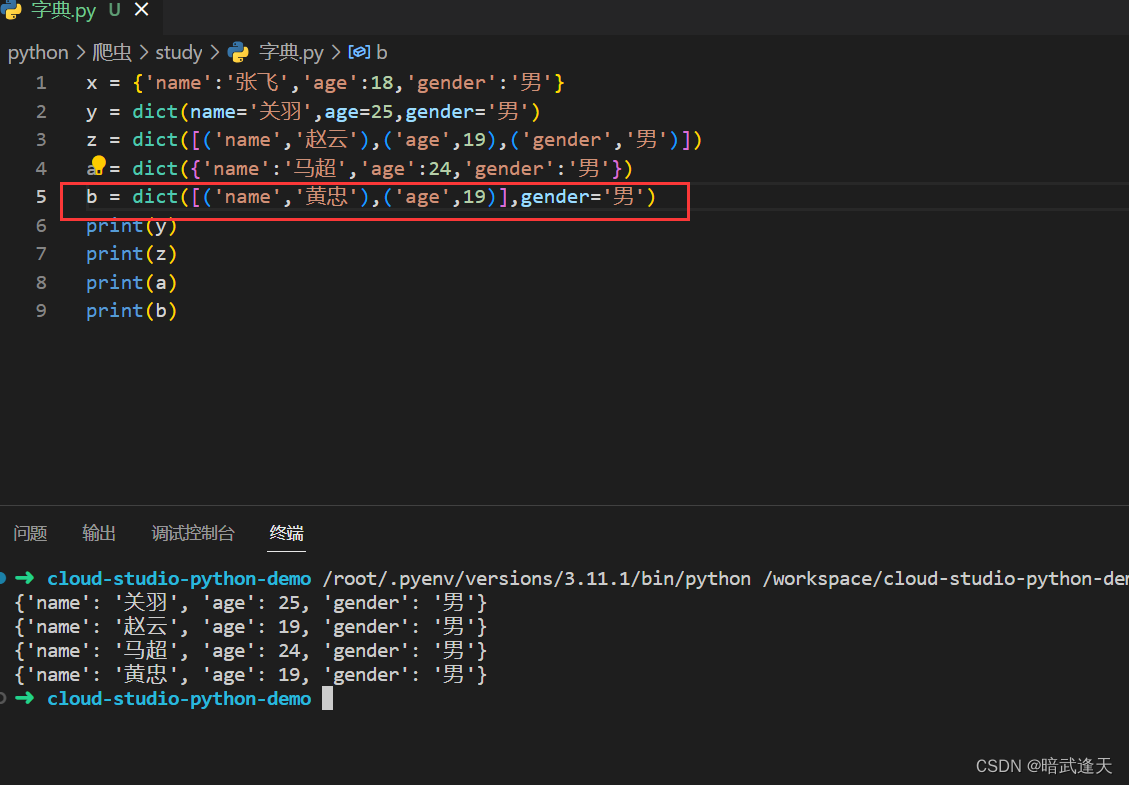
zip定义
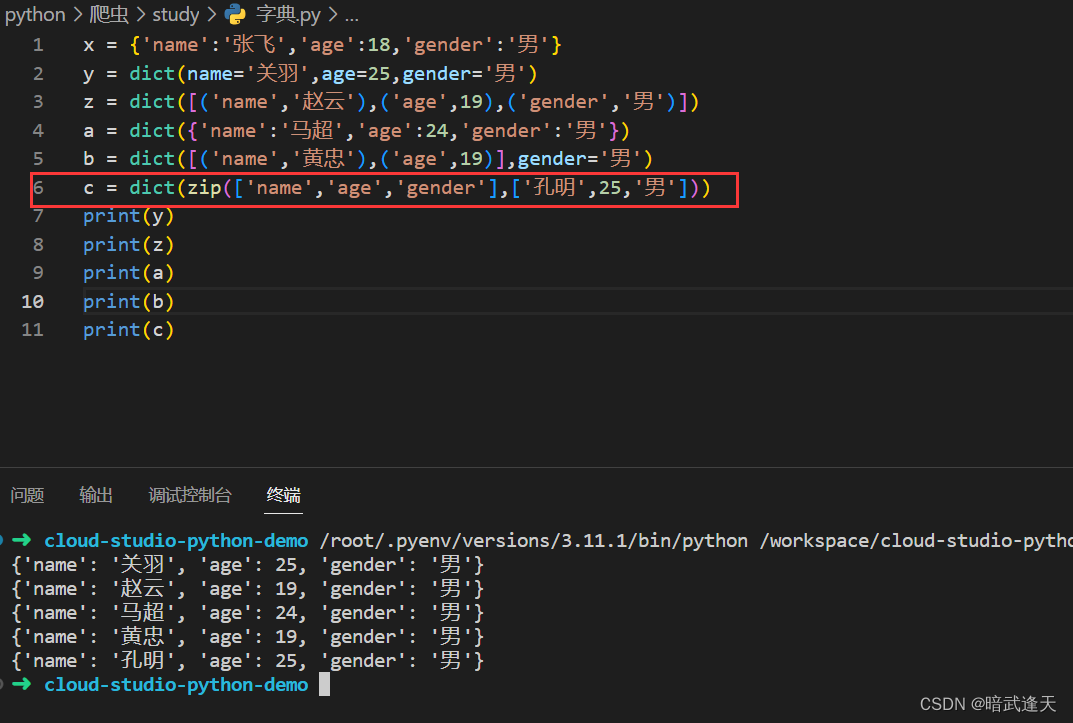
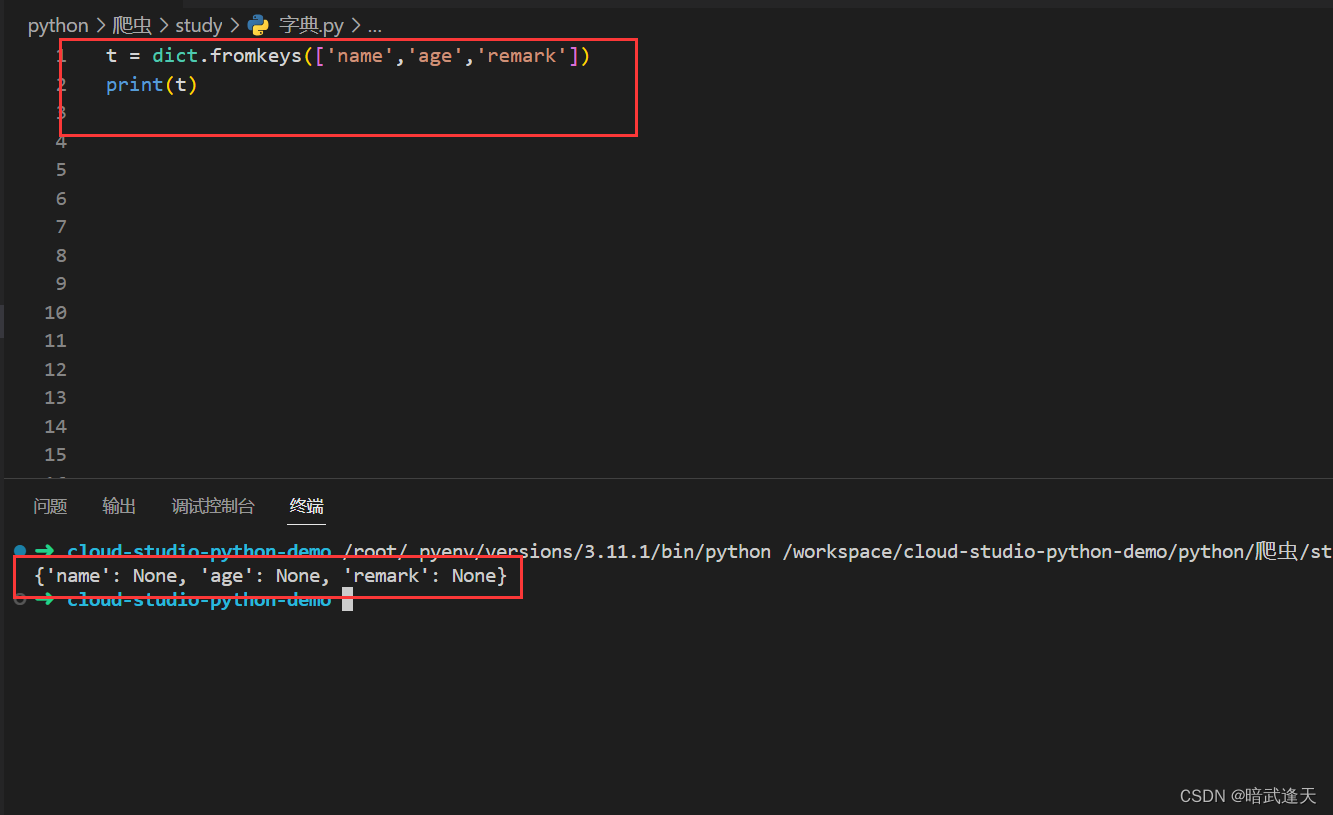
formkeys增加字典键值对
创建一个初始化键值的value都相同的字典
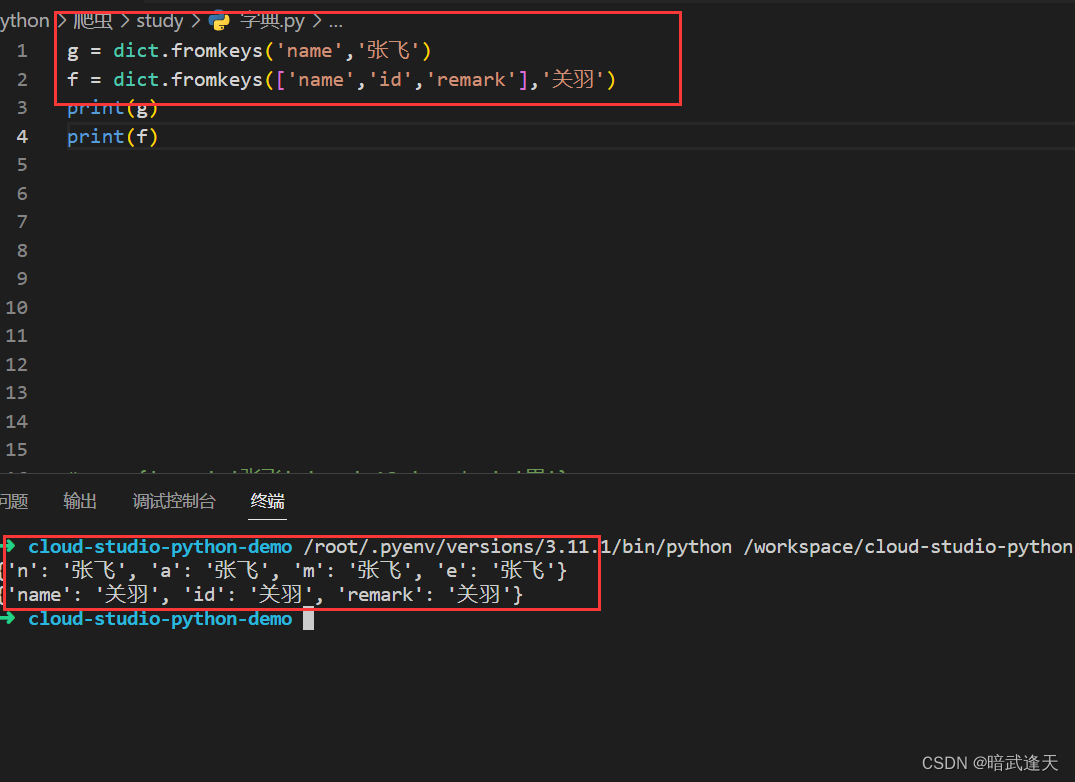
第一个参数传入可迭代对象,第二个参数传入value值,就可以初始化这个字典所有的键的value值都相同的字典
当想要修改字典的值时可以直接使用 下面的方式进行修改
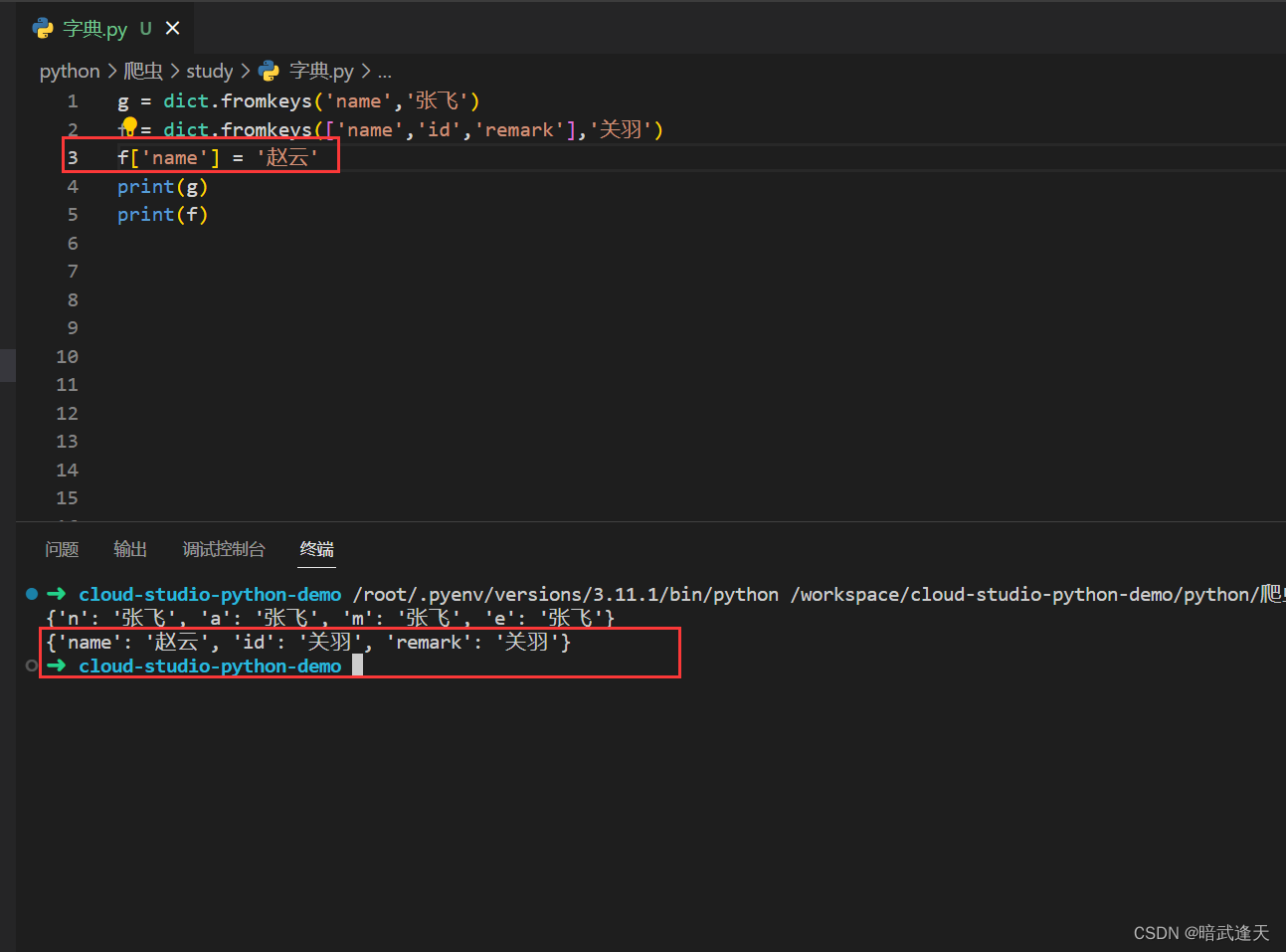
或者初始化一个没有vaule的字典
pop删除字典元素
pop可以对字典值进行弹出删除

如果删除一个字典中本就不存在的键会报错

避免这样的错误可以传入第二个参数进行默认提示
 popitems 删除字典中最后一个键值对
popitems 删除字典中最后一个键值对
python3.7之前字典是无序的,popitems是随机删除一个字典的键值,在3.7之后是删除最后一个键值对
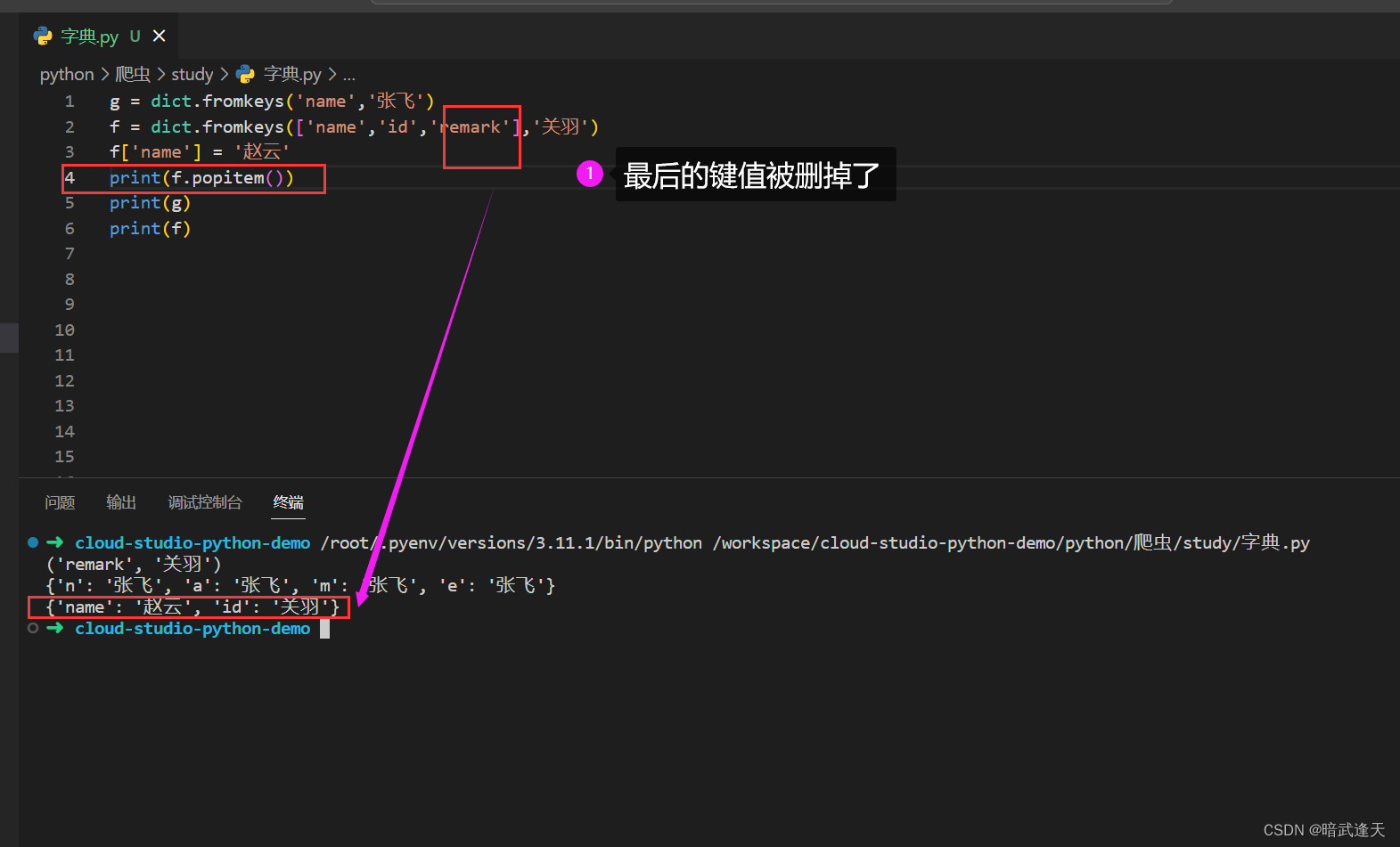
del 删除键值
或者可以使用del来对字典键值进行删除

clear 清空字典
使用clear方法对字典键值进行清空
 get 获取键值元素
get 获取键值元素
之前可以直接使用 字典名['键名'] 来获取value值,但是当键值不存在字典里面的时候就会报错

get可以获取键值元素,当字典中没有要获取的键值时,可以传入一个默认值来进行value的获取

可以看到获取的键值是不存在的但并没有报错,还可以传入一个默认值,当键值不存在的时候返回传入的默认值 
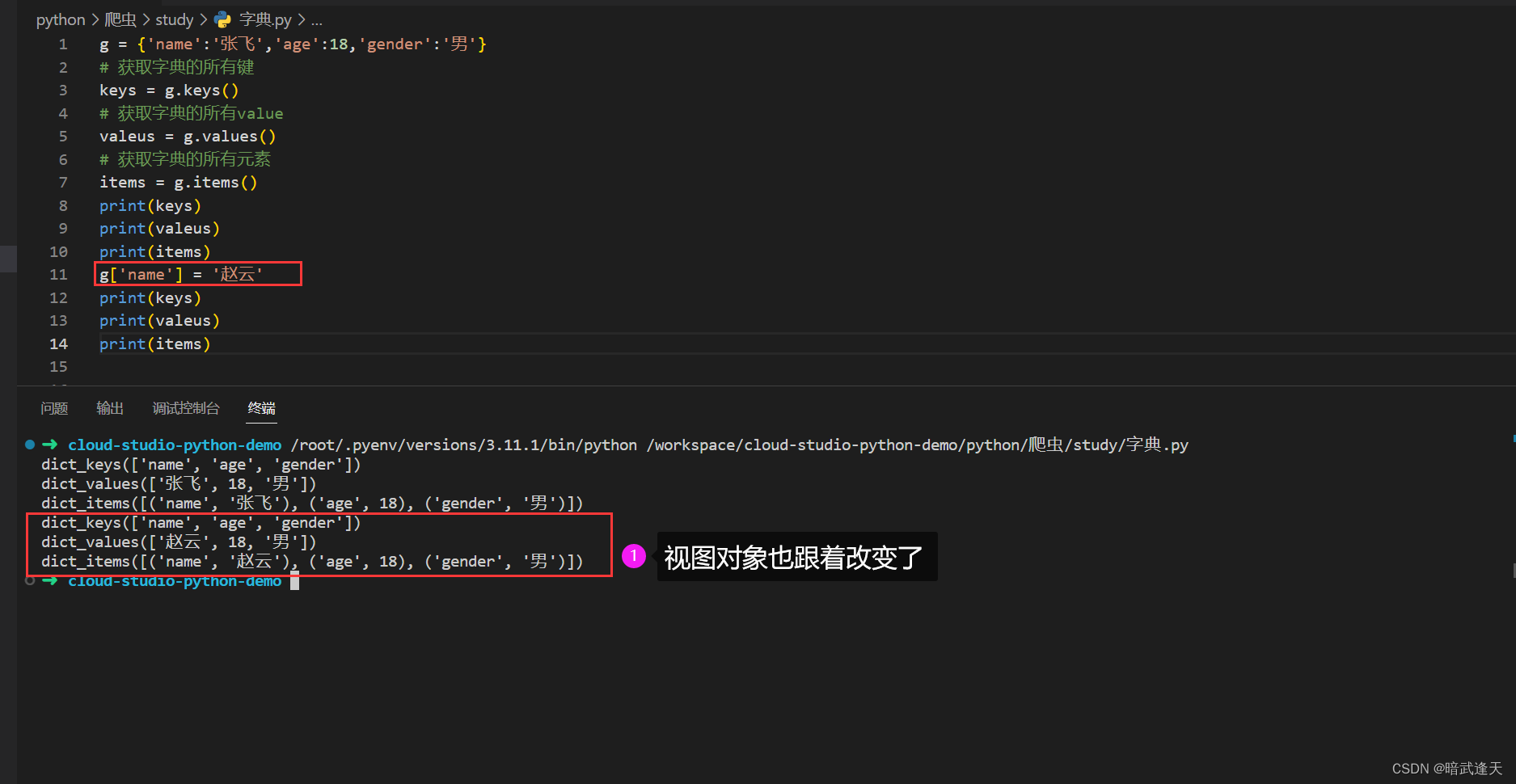
获取字典的视图对象


当我们修改字典的键值value时观察视图对象的变化
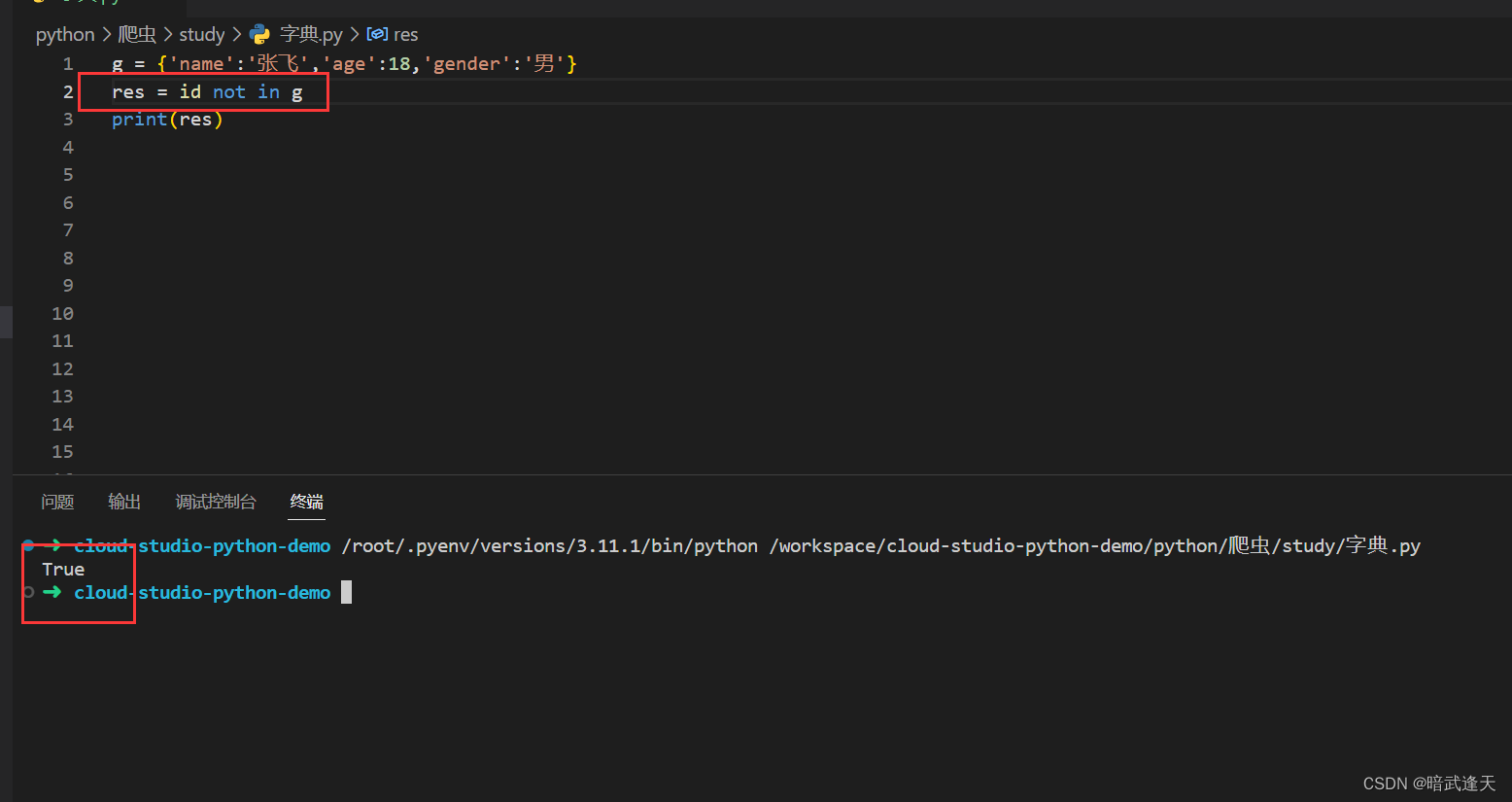
拿取字典键值长度和判断键值是否存在
可以通过len函数来拿取字典的长度

使用in和not in来判断字典是否包含某个键
字典推导式
字典也可以使用字典推导式
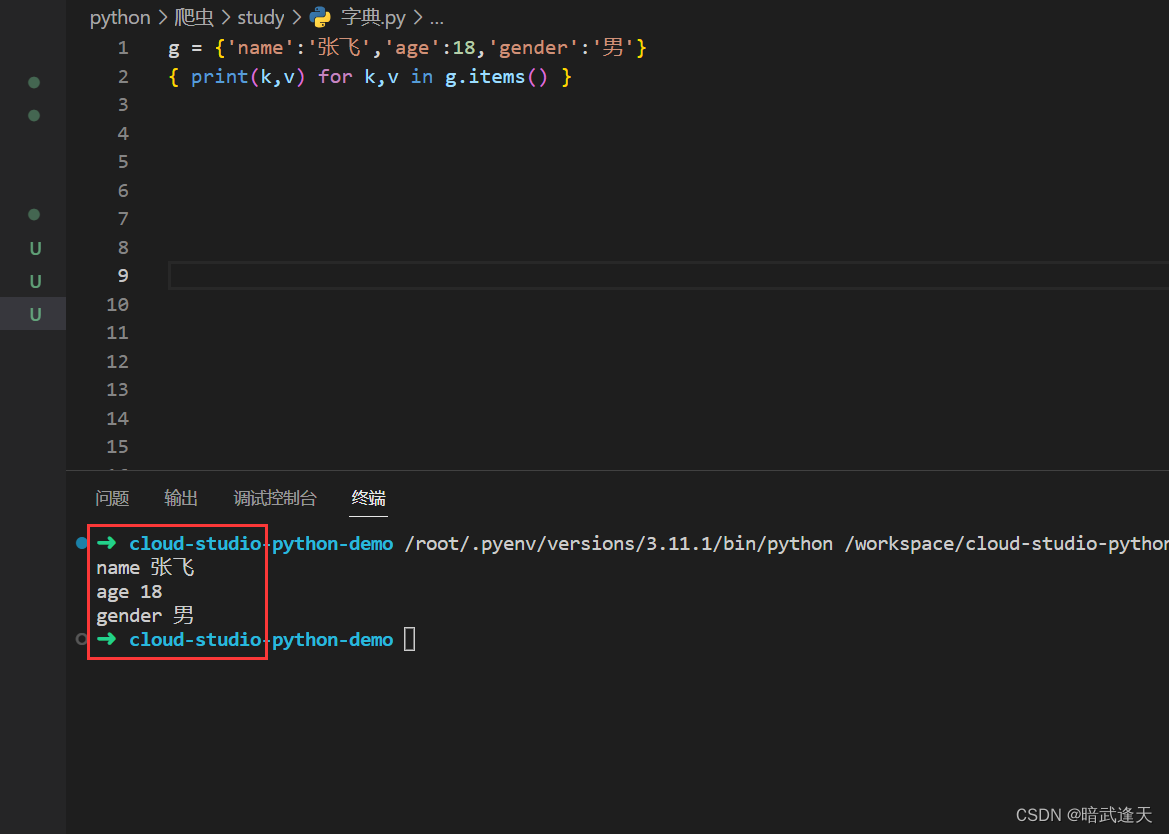
使用字典推导式可以很方便地将key和value进行反转
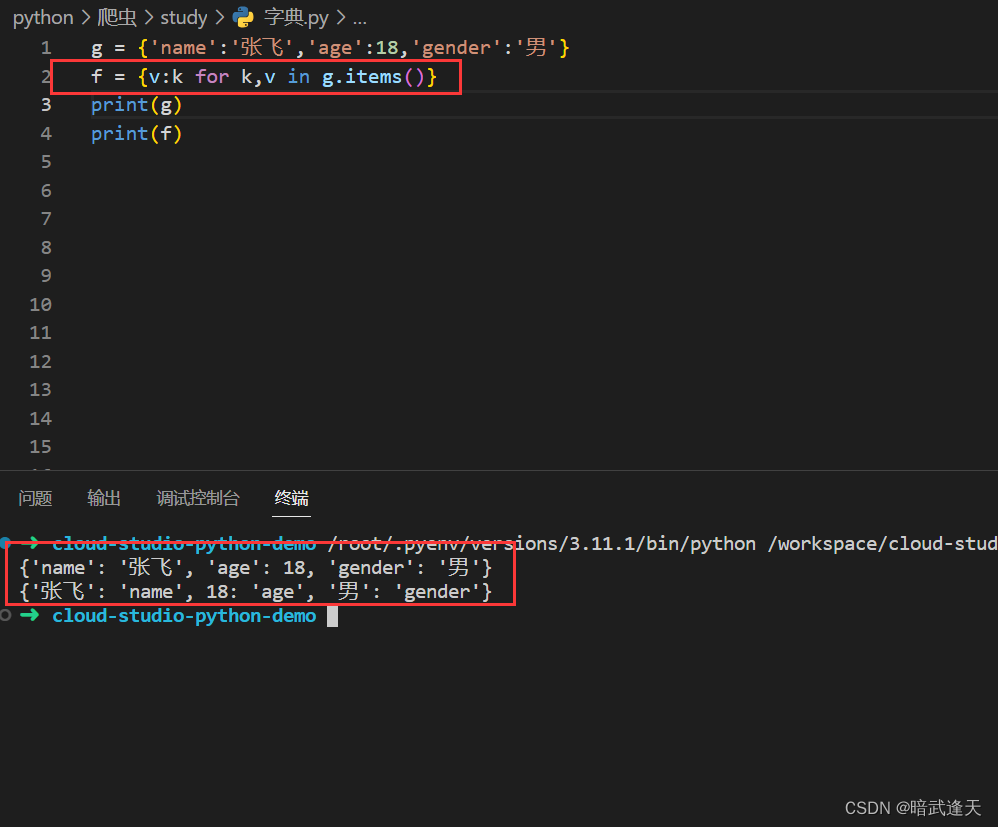
或者加上筛选条件,当value值大于100时才进行反转
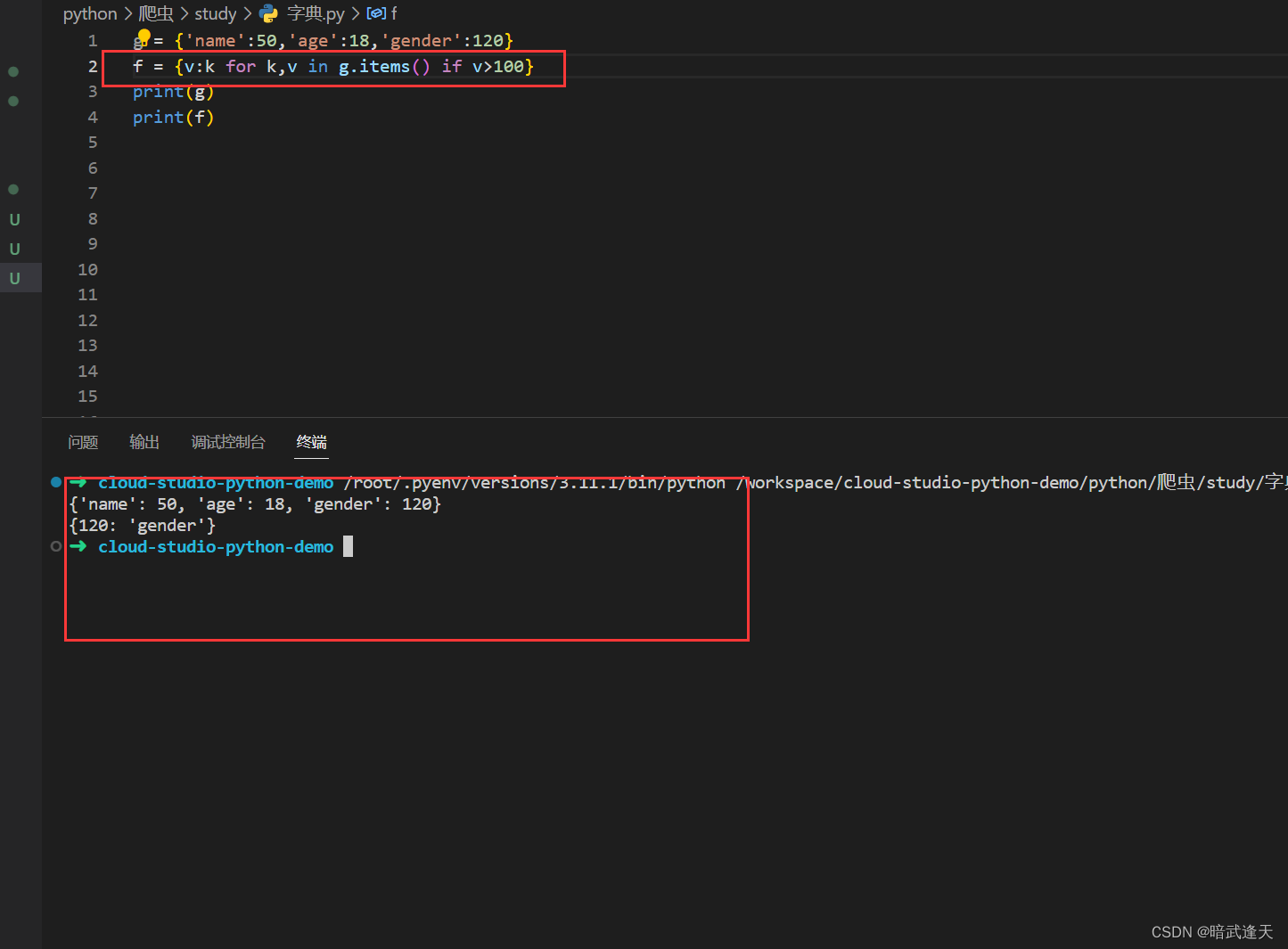
集合
set 可变集合
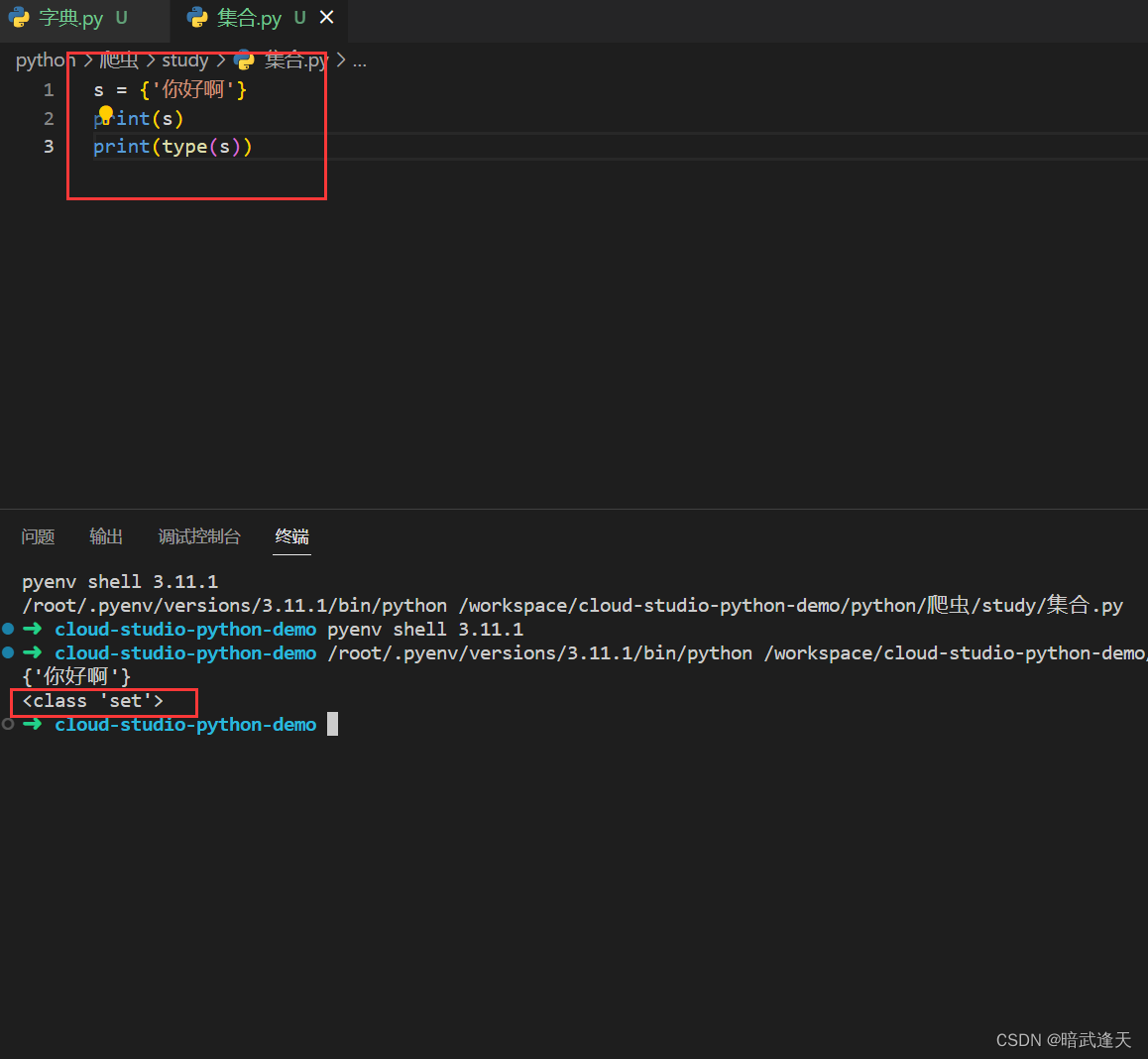
Python的集合(Set)是一种无序的、不重复的数据结构,用于存储不同类型的唯一元素,如整数、浮点数、字符串等。集合支持数学集合运算,如并集、交集、差集等。集合用花括号{}或内置函数set()来创建,但当使用花括号时,如果元素之间没有逗号分隔,会被解释为字典的键值对。
创建集合
-
使用花括号:
1my_set = {1, 2, 3} # 创建一个集合 -
使用set函数:
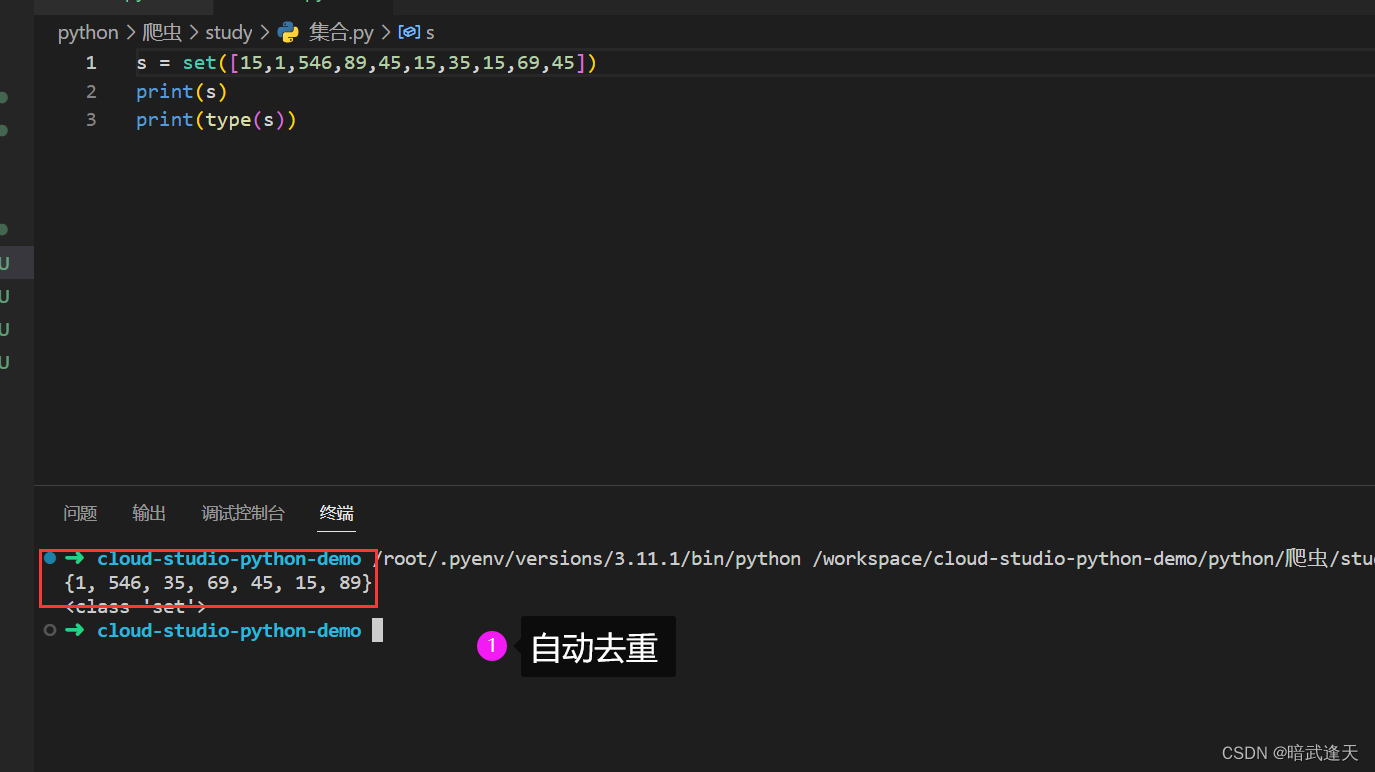
1my_set = set([1, 2, 3]) # 从列表转换成集合,自动去重 -
空集合:特别注意,空集合应该用
set()而不是{},因为后者实际上创建的是一个空字典。1empty_set = set()
集合的基本操作
-
添加元素:使用
add()方法。1my_set.add(4) -
删除元素:使用
remove()方法(如果元素不存在会抛出错误),或者discard()方法(不会抛错)。- 1my_set.remove(7) # 如果7不存在,则抛出KeyError
- 2my_set.discard(7) # 如果7不存在,也不会报错
-
集合的并集:使用
union()方法或|操作符。- 1set1 = {1, 2, 3}
- 2set2 = {3, 4, 5}
- 3union_set = set1.union(set2) # 或者 set1 | set2
-
集合的交集:使用
intersection()方法或&操作符。1intersection_set = set1.intersection(set2) # 或者 set1 & set2 -
集合的差集:使用
difference()方法或-操作符。1difference_set = set1.difference(set2) # 或者 set1 - set2 -
集合的对称差集(不同时存在于两个集合的元素):使用
symmetric_difference()方法或^操作符。1symmetric_diff_set = set1.symmetric_difference(set2) # 或者 set1 ^ set2

集合的去重示例
集合的一个重要特性就是自动去重,因此,如果你想去除一个列表中的重复元素,转换为集合是一个非常简便的方法。
- 1my_list = [1, 2, 2, 3, 4, 4, 5]
- 2unique_set = set(my_list) # 转换为集合自动去重
- 3print(unique_set) # 输出集合,元素顺序可能与原列表不同
集合是Python中处理唯一元素集合时非常有用的数据结构,特别是涉及到集合运算和去重场景。
集合推导式
集合也可以直接使用推导式

frozenset 不可变集合
frozenset 是 Python 中的一个不可变集合类型,它是集合 set 的不可变版本。与普通集合相比,frozenset 的元素一旦创建后就不能被修改,这意味着你不能向其中添加或删除元素,也不能对集合进行更新。正因为它的不可变性,frozenset 可以作为字典的键或者作为其他集合的元素,这是普通集合做不到的。
创建 frozenset
- 1my_frozenset = frozenset([1, 2, 3])
- 2# 或者直接用花括号,但需确保元素间有逗号以区分
- 3my_frozenset = frozenset({1, 2, 3})
特点
- 不可变性:一旦创建,其内容就不能被改变。
- 哈希性:由于其不可变性,
frozenset是可哈希的,这意味着它可以作为字典的键或作为其他集合的元素。 - 集合操作:虽然不能直接修改,但仍支持并集、交集、差集等集合运算。
应用场景
- 当你需要将一个集合用作字典的键或其他集合的成员时,使用
frozenset是必要的。 - 在多线程环境中,使用
frozenset可以避免因集合内容突变而引发的并发问题。 - 当集合的内容需要作为常量或者在算法中作为不变的部分时,使用
frozenset更为合适。
示例
- 1# 创建 frozenset
- 2fs1 = frozenset([1, 2, 3])
- 3fs2 = frozenset([3, 4, 5])
- 4
- 5# 集合运算依然可行
- 6union_fs = fs1.union(fs2)
- 7intersection_fs = fs1.intersection(fs2)
- 8
- 9print("Union:", union_fs) # 输出: Union: frozenset({1, 2, 3, 4, 5})
- 10print("Intersection:", intersection_fs) # 输出: Intersection: frozenset({3})
- 11
- 12# 尝试修改 frozenset(会失败,因为它是不可变的)
- 13# fs1.add(4) # 这会引发 AttributeError,因为 'frozenset' object has no attribute 'add'
总之,frozenset 提供了一种安全的方式来表示不可更改的集合数据,适用于那些需要集合特性的场景但又要求数据不可变的情景。

