
- 1云游戏是大厂的“游戏”之腾讯云<云游戏指南>
- 2stringstream_stringstream 析构
- 3vscode中使用GitHub Copilot Chat_vscode github copilot chat
- 4Embedding的理解_tcn中的embedding是什么意思
- 5Nginx代理长连接(Socket连接)_nginx socket
- 6fatal: could not create work tree dir ‘xxx’: Permission denied解决办法
- 7Python基础教程(二十二):XML解析
- 8【杭州游戏业:创业热土,政策先行】_乐港 绝地
- 9【Vue】vue项目中使用tinymce富文本组件(@tinymce/tinymce-vue)_vue tinymce
- 10springboot集成neo4j_org.neo4j.ogm是哪个依赖
图生成数据集_分子生成数据集
赞
踩
数据集来源
从各个方法实现图生成的论文中找
一篇图生成和转换的数据集综述文章:GraphGT:Machine Learning Datasets for Graph
Generation and Transformation
paper with code
1 分子数据集
对于所有的分子数据集,我们存储邻接矩阵、节点特征(即原子)、边缘特征(即键)、空间特征(即几何)和SMILES(即字符串表示)(SMILES)
QM9:QM9-paper with code
ZINC:ZINC-paper with code
Molecular Sets (MOSES):MOSES-paper with code
ChEMBL:ChEMBL v.27-paper with code
分子图生成指标
- 新颖性novelty:所有生成的分子中不属于原数据集并且满足化学有效性的分子数与数据集所含分子数之比
- 效度validity:有效性是指化学上有效的分子。化学有效分子在所有生成的分子中的百分比
- 唯一性uniqueness:唯一性是指在生成的池中唯一分子的百分比。唯一性高度依赖于池的大小,对于生成的大型库,大小可能会显著下降。所有生成的分子中不属于原数据集并且满足化学有效性的分子数与生成的分子数之比
- 内部多样性internal diversity:如MOSES基准,是生成库丰富度的定量度量,计算为库中所有分子对之间的平均成对距离。
综合可及性评分synthetic accessibility score(SA评分):SA评分是对合成给定分子难度的估计,这也反映了其结构的复杂性。得分越高的分子会更复杂,也更难合成。然而,分数很低的分子可能还不够复杂,不足以具有所需的性质。这个度量的兴趣值在2到4的范围之间。 - 药物相似性评分 drug-likeness score(QED):QED是一种从0到1范围内的药物相似性的测量方法。越高越好
- 重建度reconstruction:原数据集中能够完全被模型重建的分子数与数据集所含分子数之比
- N.U.V.:生成的分子中满足:Validity,Uniqueness,Novelty分子的数量与生成的分子数之比
- plogp:说明了环尺寸和分子合成的可能性。越高越好
- 无检查有效率Validity w/o check:禁用此化合价校正时的有效百分比
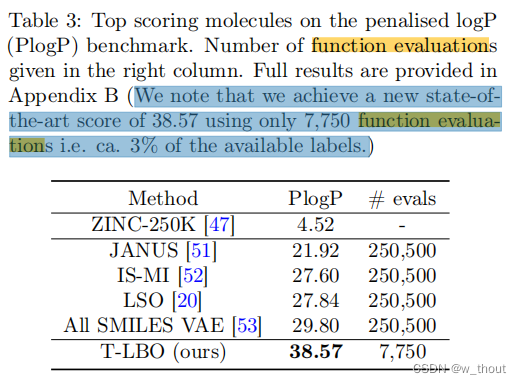
- function evaluations:训练的样本数量?(如下图)
2 蛋白质数据集
Protein
Enzyme:ENZYMES-paper with code
ProFold
3 脑网络
Brain
4 物理模拟
N-body-charged
N-body-spring
5 协作网络
DBLP(引文网络数据集):DBLP-paper with code
(CollabNet collected from)
6 交通网络
METR-LA:METR-LA-paper with code
PeMS-BAY:PEMS-BAY-paper with code
7 身份验证网络
AuthNet collected from DBLP
8 物联网网络
IoTNet
9 骨骼图
Kinetics:Kinetics (Kinetics Human Action Video Dataset)-paper with code
NTU-RGB+D:NTU RGB+D 2D-paper with code
10 社交网络
Ego collected from Citeseer
Citeseer:Citeseer-paper with code
11 场景图
CLEVR:CLEVR-paper with code
12 合成图形
Barab’asi-Albert Graphs
Community
Erdos-Renyi Graphs
Scale-free
Waxman Graphs
Random Geometric Graphs
其他paper with code上找到的
MuMiN:MuMiN
LSEC (Live Stream E-Commerce):LSEC (Live Stream E-Commerce)
4D-OR:4D-OR
Identity Access Management dataset:Identity Access Management dataset

