
- 1IDEA快速入门_intellij idea2020.3激活
- 2java实现的经典递归算法三例_经典递归算法java
- 3李德毅 | 人工智能看哲学
- 4手把手教你在云环境炼丹:Stable Diffusion LoRA 模型保姆级炼制教程_炼丹模型训练
- 5使用Python进行机器学习:从基础到实战
- 6[AI]文心一言出圈的同时,NLP处理下的ChatGPT-4.5最新资讯_chtagtp4.5
- 7android edittext显示光标不闪烁_单片机1602液晶屏显示 hello studet come to here
- 8uniapp 使用安卓模拟器运行调试_uniapp 安卓模拟器调试
- 9卡尔曼滤波和互补滤波的区别_互补滤波和卡尔曼滤波
- 10如何短时间通过2022年PMP考试?_pmp考试总结2022
NLTK结合stanfordnlp工具包使用方法总结_corenlptokenizer
赞
踩
简述
NLTK 是一款著名的 Python 自然语言处理(Natural Language Processing, NLP)工具包,在其收集的大量公开数据集、模型上提供了全面、易用的接口,涵盖了分词、词性标注(Part-Of-Speech tag, POS-tag)、命名实体识别(Named Entity Recognition, NER)、句法分析(Syntactic Parse)等各项 NLP 领域的功能。
Stanford NLP 是由斯坦福大学的 NLP 小组开源的 Java 实现的 NLP 工具包,同样对 NLP 领域的各个问题提供了解决办法。斯坦福大学的 NLP 小组是世界知名的研究小组,如果能将 NLTK 和 Stanford NLP 这两个工具包结合起来使用,那自然是极好的!在 2004 年 Steve Bird 在 NLTK 中加上了对 Stanford NLP 工具包的支持,通过调用外部的 jar 文件来使用 Stanford NLP 工具包的功能。现在的 NLTK 中,通过封装提供了 Stanford NLP 中的以下几个功能:
- 分词
- 词性标注
- 命名实体识别
- 句法分析
- 依存句法分析
本文是在Windows7操作系统下的Python 3.6.4和jdk 1.8版本进行配置,具体安装需要注意以下几点:
- Stanford NLP 工具包需要 Java 8 及之后的版本,如果出错请检查 Java 版本(java -version)
- 本文的配置都是以 Stanford NLP 3.9.2 为例,如果使用的是其他版本,请注意替换相应的文件名
- 本文的配置过程以 NLTK 3.2.5 为例,如果使用 NLTK 3.1,需要注意该旧版本中 StanfordSegmenter 未实现,其余大致相同
NLTK安装与配置
1) 安装:打开python编辑器,输入“import nltk”,再输入“nltk.download()”,下载NLTK数据包,在下载界面选中book模块,这个模块包含了许多数据案例和内置函数。修改book下载目的路径建议如下:D:\Users\Administrator\Anaconda3\nltk_data,也就是在Anaconda下创建一个nltk_data的文件夹,将book下载目标路径放在此处便于管理和维护。
2) 环境变量的配置:计算机→属性→高级系统设置→高级→环境变量→系统变量→path,在path中加入刚刚定的路径:D:\Users\Administrator\Anaconda3\nltk_data
3) 配置完成之后,打开python编辑器,输入from nltk.book import *,只要没有输出明显错误且正确显示相关信息,就表示NLTK安装成功了,如下图所示:

Standford NLP必要工具包说明
⊚ 分词依赖:stanford-segmenter.jar、slf4j-api.jar、data 文件夹相关子文件。
⊚ 命名实体识别依赖:classifiers、stanford-ner.jar。
⊚ 词性标注依赖:models、stanford-postagger.jar。
⊚ 句法分析依赖:stanford-parser.jar、stanford-parser-3.9.2-models.jar、classifiers。
⊚ 依存语法分析依赖:stanford-parser.jar、stanford-parser-3.9.2-models.jar、classifiers。
压缩包下载配置和源码分析
⊚ 分词压缩包StanfordSegmenter 和StanfordTokenizer:下载stanford-segmenter-2018-10-16.zip (The Stanford Natural Language Processing Group),解压获取目录中的stanford-segmenter-3.9.2.jar复制为stanford-segmenter.jar 和slf4j-api.jar。
⊚ 词性标注压缩包StanfordPOSTagger:下载stanford-postagger-full-2018-10-16.zip (The Stanford Natural Language Processing Group),解压获取stanford-postagger.jar。
⊚ 命名实体识别压缩包StanfordNERTagger:下载stanford-ner-2018-10-16.zip (The Stanford Natural Language Processing Group),解压获取stanford-ner.jar 和classifiers 文件。
⊚ 句法分析StanfordParser、句法依存分析StanfordDependencyParser:下载stanford-parser-full-2018-10-17.zip(The Stanford Natural Language Processing Group),解压获取stanford-parser.jar 和stanford-parser-3.9.2-models.jar
⊚ 环境变量的配置:计算机→属性→高级系统设置→高级→环境变量→系统变量→CLASSPATH。在classpath中添加上述解压缩包的路径,如下图所示:

其中CLASSPATH对应的变量值为:E:\stanford_nlp\classifiers;E:\stanford_nlp\models;E:\stanford_nlp\slf4j-api.jar;E:\stanford_nlp\stanford-ner.jar;E:\stanford_nlp\stanford-postagger.jar;E:\stanford_nlp\stanford-parser.jar;E:\stanford_nlp\stanford-corenlp-3.9.2.jar;E:\stanford_nlp\stanford-corenlp-3.9.2-models.jar;E:\stanford_nlp\stanford-segmenter.jar;E:\stanford_nlp\stanford-classifier.jar
设置环境变量的目的是为了能随时快速的调用,设置环境变量之后,以后的所有调用都不需要传输绝对路径的参数。
基本功能使用小结
1、分词
(1)中文分词
StanfordSegmenter 是 52nlp 实现的对 Stanford Segmenter 的封装,用来进行中文分词。
- from nltk.tokenize import StanfordSegmenter
- segmenter = StanfordSegmenter(
- path_to_sihan_corpora_dict="E:\stanford_nlp\stanford-segmenter-2018-10-16\data",
- path_to_model="E:\stanford_nlp\stanford-segmenter-2018-10-16\data\pku.gz",
- path_to_dict="E:\stanford_nlp\stanford-segmenter-2018-10-16\data\dict-chris6.ser.gz",
- java_class = 'edu.stanford.nlp.ie.crf.CRFClassifier')
- str=u"语料库是为一个或者多个应用目标而专门收集的,有一定结构的、有代表的、可被计算机程序检索的、具有一定规模的语料集合。语料库以电子计算机为载体承载语言知识的基础资源,但并不等于语言知识。"
- result = segmenter.segment(str)
- print(result)
StanfordSegmenter 的初始化参数说明:
-
path_to_jar: 用来定位 stanford-segmenter.jar ,在设置了 CLASSPATH 的情况下,该参数可留空
注: 其他所有 Stanford NLP 接口都有 path_to_jar 这个参数,在设置了环境变量的情况下可以留空,后面不再另加说明。
- path_to_slf4j: 用来定位 slf4j-api.jar ,在设置了 CLASSPATH 或者 SLF4J 这个环境变量的情况下,该参数可留空
- path_to_sihan_corpora_dict: 设定为 stanford-segmenter-2018-10-16.zip 解压后目录中的 data 目录
- path_to_model: 用来指定用于中文分词的模型,在 stanford-segmenter-2018-10-16 的 data 目录下,有两个可用模型 pkg.gz 和 ctb.gz, 其中ctb.gz是基于宾州中文树库训练的模型,pku.gz是基于北大在2005backoof上提供的人名日报语料库,这里选用了pku.gz方便测试。
- java_class: 在https://github.com/nltk/nltk/blob/develop/nltk/tokenize/stanford_segmenter.py的第153行 self._java_class = 'edu.stanford.nlp.ie.crf.CRFClassifier'指定了中文模型时的java_class参数为edu.stanford.nlp.ie.crf.CRFClassifier。如果是阿拉伯语则为edu.stanford.nlp.international.arabic.process.ArabicSegmenter 如果不传该参数,会报错TypeError: argument of type 'NoneType' is not iterable. 解决方法详见参考文献3和python 3.5 nltk Stanford segmenter windows 10 - Stack Overflow。chinese segment error · Issue #484 · stanfordnlp/CoreNLP · GitHub解决了该问题。
执行结果如下:

需要注意的是,使用 StanfordSegmenter 进行中文分词后,其返回结果并不是 list ,而是一个字符串,各个汉语词汇在其中被空格分隔开。
(2)英文分词
StanfordTokenizer 可以用来进行英文的分词,在NLTK 3.2.5后可改用nltk.parse.corenlp.CoreNLPTokenizer代替它。
- from nltk.tokenize.stanford import StanfordTokenizer
- tokenizer=StanfordTokenizer()
- sent="Good muffins cost $3.88\nin New York. Please buy me\ntwo of them.\nThanks."
- print(tokenizer.tokenize(sent))
注:需要从nltk.tokenize.stanford中导入StanfordTokenizer, 如果只写nltk.tokenize会报错
ImportError: cannot import name 'StanfordTokenizer' 找不到StanfordTokenizer。

执行结果为:
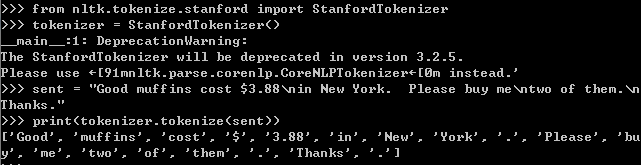
注:StanfordTokenizer will be deprecated in version 3.2.5 Warning 可以通过升级nltk至3.3版本或3.4版本解决这个问题。详见python - StanfordTokenizer will be deprecated in version 3.2.5 Warning - Data Science Stack Exchange
2、命名实体识别
所谓命名实体识别,是用来识别并标注文本中的人名、地名、组织机构名等单元,这些单元既是 "命名实体"。
(1)英文命名实体识别
- from nltk.tag import StanfordNERTagger
- eng_tagger=StanfordNERTagger(model_filename=r'E:\stanford_nlp\classifiers\english.all.3class.distsim.crf.ser.gz')
- print(eng_tagger.tag('In this post we will explore the other Word2Vec model - the continuous bag-of-words (CBOW) model.'.split()))
执行结果为:

(2)中文命名实体识别
StanfordNERTagger 在初始化时需要指定所使用的模型,在 stanford-ner-2018-10-16.zip 解压后的 classifiers 目录(E:\stanford_nlp\stanford-ner-2018-10-16\classifiers)中,有几个可用的英语 NER 模型:

如果要进行中文命名实体识别,则可在 Stanford Named Entity Recognizer(The Stanford Natural Language Processing Group) 页面的 Models 一节找到中文模型的下载链接,下载 stanford-chinese-corenlp-2018-10-05-models.jar,解压后将 edu/stanford/nlp/models/ner/ 目录(E:\stanford_nlp\stanford-chinese-corenlp-2018-10-05-models\edu\stanford\nlp\models\ner)下的 chinese.misc.distsim.crf.ser.gz 和 chinese.misc.distsim.prop 复制到模型目录下(stanford-ner-2018-10-16\classifiers或之前复制的目录stanford_nlp\classifiers)即可。

- from nltk.tag import StanfordNERTagger
- chi_tagger = StanfordNERTagger(model_filename=r'E:\stanford_nlp\classifiers\chinese.misc.distsim.crf.ser.gz')
- result=u'中国 载人 航天 工程 办公室 透露 空间站 飞行 任务 即将 拉开 序幕。'
- for word, tag in chi_tagger.tag(result.split()):
- print(word,tag)
执行结果如下:

3、词性标注
所谓词性标注,是根据句子中的上下文信息,给句中每个词确定一个最为合适的词性标记,比如动词、名词、人称代词等。
(1)英文词性标注
- from nltk.tag import StanfordPOSTagger
- eng_tagger=StanfordPOSTagger(model_filename=r'E:\stanford_nlp\models\english-bidirectional-distsim.tagger')
- print(eng_tagger.tag('Did you know that the word2vec model can also be applied to non-text data for recommender systems and ad targeting?'.split()))
执行结果为:

(2)中文词性标注
- from nltk.tag import StanfordPOSTagger
- chi_tagger=StanfordPOSTagger(model_filename=r'E:\stanford_nlp\models\chinese-distsim.tagger')
- result="语料库 以 电子 计算机 为 载体 承载 语言 知识 的 基础 资源 , 但 并 不 等于 语言 知识 。 \r\n"
- print(chi_tagger.tag(result.split()))
执行结果如下:

4、句法分析
句法分析在分析单个词的词性的基础上,尝试分析词与词之间的关系,并用这种关系来表示句子的结构。实际上,句法结构可以分为两种,一种是短语结构,另一种是依存结构。前者按句子顺序来提取句法结构,后者则按词与词之间的句法关系来提取句子结构。这里说的句法分析得到的是短语结构。
(1)英文句法分析
- from nltk.parse.stanford import StanfordParser
- eng_parser=StanfordParser()
- print(list(eng_parser.parse("In many natural language processing tasks, words are often represented by their tfidf scores.".split())))
执行结果为:
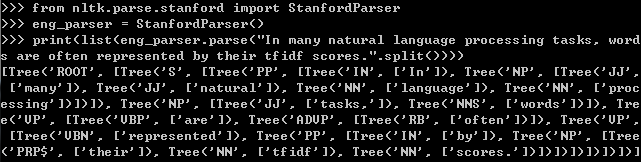
结果返回的是一个list,而且list长度为1,其中元素均为Tree类型,可以调用nltk中Tree的draw()方法绘制出句法树,如下图所示:

(2)中文句法分析
如果要进行中文的句法分析,只要指定好中文的模型就好,可用的中文模型有以下几种,分别是
- 'edu/stanford/nlp/models/lexparser/chinesePCFG.ser.gz'
- 'edu/stanford/nlp/models/lexparser/chineseFactored.ser.gz'
- 'edu/stanford/nlp/models/lexparser/xinhuaPCFG.ser.gz'
- 'edu/stanford/nlp/models/lexparser/xinhuaFactored.ser.gz'
- 'edu/stanford/nlp/models/lexparser/xinhuaFactoredSegmenting.ser.gz'
其中factored包含词汇化信息,PCFG是更快更小的模板,xinhua据说是根据大陆的《新华日报》训练的语料,而chinese同时包含香港和台湾的语料,xinhuaFactoredSegmenting.ser.gz可以对未分词的句子进行句法解析。以下句法分析的代码中用的是chinesePCFG.ser.gz。
- from nltk.parse.stanford import StanfordParser
- chi_parser=StanfordParser(model_path=r'E:\stanford_nlp\stanford-corenlp-3.9.2-models\edu\stanford\nlp\models\lexparser\chinesePCFG.ser.gz')
- sent=u'语料库 以 电子 计算机 为 载体 承载 语言 知识 的 基础 资源 , 但 并 不 等于 语言 知识 。'
- print(list(chi_parser.parse(sent.split())))
执行结果如下:


注意,如果没有改用中文模型会从结果看出中文句法树显然不对,这里使用的是chinesePCFG.ser.gz模型,也可以换其他的模型试试。
5、依存句法分析
依存句法分析得到的是句子的依存结构。
(1)英文依存句法分析
- from nltk.parse.stanford import StanfordDependencyParser
- eng_parser=StanfordDependencyParser()
- res=list(eng_parser.parse("In many natural language processing tasks, words are often represented by their tfidf scores".split()))
- for row in res[0].triples():
- print(row)
执行结果为:


或者用spacy 对英文句子依存分析(Note: 为了跟模型兼容,spacy需首先升级至3.4.0版本), 其中使用的英文模型是en_core_web_sm,下载地址是https://github.com/explosion/spacy-models/releases?q=en_core_web_sm。 也可以使用如下命令行下载en_core_web_sm模型:
pip3 install https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.4.0/en_core_web_sm-3.4.0.tar.gz代码如下所示:
- import spacy
- from spacy import displacy
- from pathlib import Path
-
- parser = spacy.load('en_core_web_sm')
-
- doc = "In many natural language processing tasks, words are often represente
- y their tfidf scores"
-
- doc = parser(doc)
- svg = displacy.render(doc, style='dep', jupyter=False)
- output_path = Path("./spacy_plot.svg")
- output_path.open("w", encoding="utf-8").write(svg)
英文句子的依存分析图:
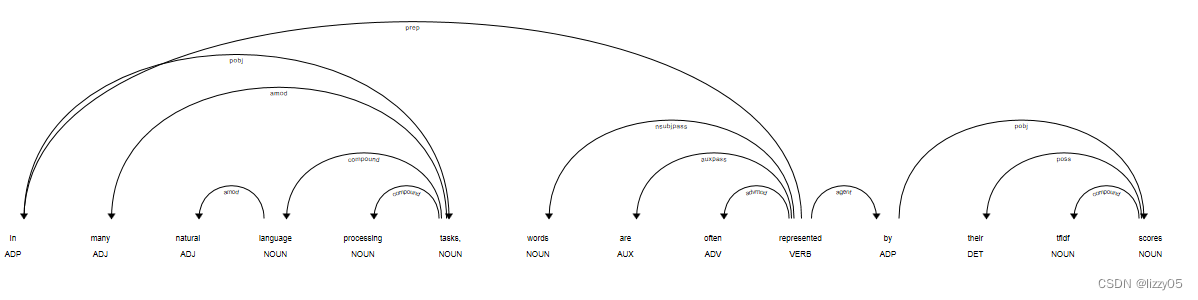
(2)中文依存句法分析
中文的依存句法分析需注意的是初始化时要使用中文模型,这里也用的是chinesePCFG.ser.gz模型。
- from nltk.parse.stanford import StanfordDependencyParser
- chi_parser=StanfordDependencyParser(model_path=r'E:\stanford_nlp\stanford-corenlp-3.9.2-models\edu\stanford\nlp\models\lexparser\chinesePCFG.ser.gz')
- res=list(chi_parser.parse(u'中国 载人 航天 工程 办公室 透露 空间站 飞行 任务 即将 拉开 序幕。'.split()))
- for row in res[0].triples():
- print(row)
执行结果如下:


或者用spacy对中文句子依存分析, 其中使用的中文模型是zh_core_web_sm,下载地址是https://github.com/explosion/spacy-models/releases?q=zh_core_web_sm, 也可以使用命令行下载zh_core_web_sm模型:
pip3 install https://github.com/explosion/spacy-models/releases/download/zh_core_web_sm-3.4.0/zh_core_web_sm-3.4.0.tar.gz代码如下所示:
- import spacy
- from spacy import displacy
- from pathlib import Path
-
- parser = spacy.load('zh_core_web_sm')
- doc = "中国 载人 航天 工程 办公室 透露 空间站 飞行 任务 即将 拉开 序幕。"
- doc = parser(doc)
- svg = displacy.render(doc, style='dep', jupyter=False)
- output_path = Path("./spacy_zh_plot.svg")
- output_path.open("w", encoding="utf-8").write(svg)
中文句子的依存分析图:
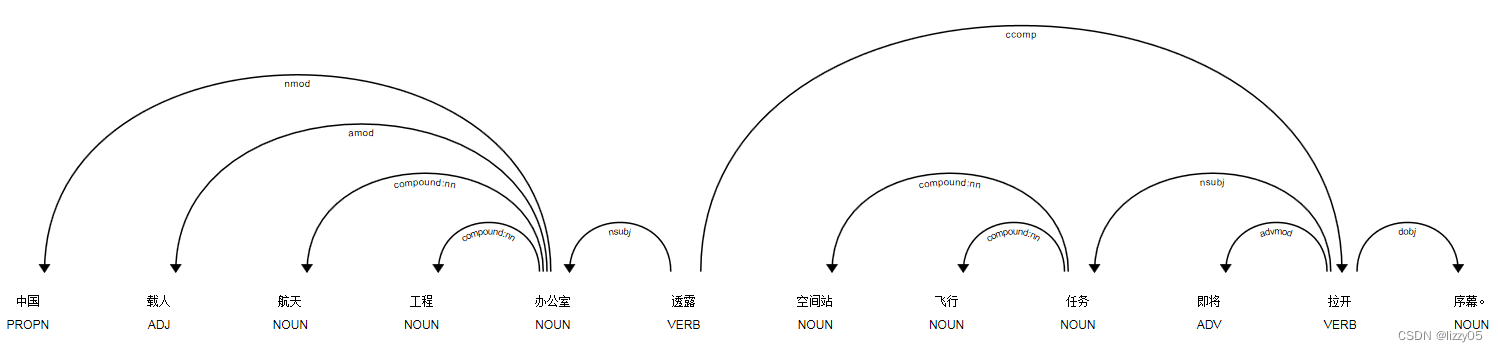
参考文献:
1. 在 NLTK 中使用 Stanford NLP 工具包 · ZMonster's Blog
2. 【NLP】干货!Python NLTK结合stanford NLP工具包进行文本处理 - 伏草惟存 - 博客园
3. 我爱自然语言处理 – I Love Natural Language ProcessingPython自然语言处理实践-在NLTK中使用斯坦福中文分词器

