
- 1零成本打造公众号聊天机器人:Cloudflare人工智能免费利用指南_workers cloudflare ai
- 2如何在Git Hub上学习开源项目+社交_git-hub
- 3【专题】2024年3月医药行业报告合集汇总PDF分享(附原数据表)
- 4QTabBar实验
- 5k8s污点去除
- 6spring cloud gateway2 请求和响应处理_spring cloud gateway 请求响应注解
- 7Windows如何远程连接服务器?Linux服务器如何远程登录?远程连接服务器命令_windows连接远程服务器命令端口
- 8qt 打印日志
- 9淘宝小程序 九宫格抽奖_淘宝详情页九宫格代码
- 10原创_海信ip102h_ip103h鸿蒙架构当贝乐家语音安卓9线刷固件包刷机教程可救砖rom刷机包_ip103h刷机包
anchor base和anchor free, 小物体检测, YOLO V1-3 9000 V4 V5 的区别,yolov5-8, yolox创新点_anchor free 和anchor base的优劣
赞
踩
内容整理自网络和书籍,侵删
proposal based方法:RCNN系列(Faster R-CNN,Mask R-CNN,Cascade R-CNN)
anchor based方法:Yolo、Focal loss、
non-anchor based 方法:基于物体中心点(CenterNet、FCOS )
直接预测:DETR、
Anchor base和Anchor Free的区别:
- 检测性能受框的尺度、宽高比、数量、IOU阈值影响比较大;不同检测任务中,由于数据集不同,这些和anchor相关的参数需要重新调整,普适性较差(缺乏泛化能力);在检测差异较大物体时不够灵活
- 为了尽可能精确匹配图像中的物体,需要大量的预设anchor,导致正负样本非常不均衡
- 训练中,对于Box匹配需要计算所有的IOU,计算量较大、参数较多
优点是:收敛快,可操作性强,适合业务场景
Anchor-free算法的优点:
- 去掉产生预设框的过程,不需要调优和anchor相关的超参数,避免大量IOU计算,占用内存更低
•使用类似分割的思想来解决目标检测问题;
•不需要调优与anchor相关的超参数;
•避免大量计算GT boxes和anchor boxes 之间的IoU,使得训练过程占用内存更低。
anchor-free的缺点:收敛慢
复杂的后处理?(使用关键点做目标检测,cornernet,centernet,extremenet)
如何增强模型对小物体的检测效果
- 模型设计:
- 采用特征金字塔、沙漏结构等网络子结构,增强网络多多尺度尤其是小尺度特征的感知能力;
- 尽可能提升网络感受野,使得网络能更多利用上下文信息增强检测效果;
- 减少网络下采样比例,是最后用于检测的特征分辨率更高
- 训练方面:
- 提高小物体在总样本中的比例
- 利用数据增强手段,将图像缩小,生成小物体样本
- 在计算量允许的范围内,尝试更大的输入图像尺寸
https://mp.weixin.qq.com/s/ATVhSI0lFdB5xW1Cqg5evg
Yolo基本思想
使用一个端到端CNN直接预测目标类别和位置。特点:实时性高,精度稍低。
思路:将输入图片划分成SxS网格,用每个网格去检测 中心点位于该网格内的物体。推理时每个网格预测B个Bbox,包含 xywhc 。
网络结构:每个版本不同。
不同版本的Yolo网络差异
一般体现在:
- 网络结构不同
- LOSS不同
- 实现细节不同
YOLO V1
-
网络结构(卷积层、池化层、全连接层):24卷积层+2FC(全连接层)。
-
实现细节:最后两个FC参数冗余、只支持固定分辨率
-
将输入的图片分割成SxS的网格,每个单元格负责去检测那些中心点落在该格子内的目标 (训练时这么去计算loss)
-
每个单元格会预测B个边界框以及边界框的置信度:p*IOU
-
每个边界框表示为(x, y, w, h),即中心点和宽高
YOLO V2
针对V1的两个缺点:低召回和低定位准确率,进行了一系列改进。
- 在卷积层后面加BN层,加快收敛、防止过拟合 【提升速度】
- 在检测前,先在高分辨率图片上finetune 10个batch,使模型提前适应高分辨率图片
- 使用Kmeans聚类生成先验框,聚类没有使用欧式距离,而是 d = 1 - IOU
- 直接在anchor box基础上提取特征,预测偏移和置信度,不使用全连接层预测,更简单和容易学习 【提升速度】
- 输入尺寸从448 * 448改成416 * 416,经过卷积(416/32=13)后,特征图长宽13为奇数,更有效识别中心。真实场景中图片一般以物体为中心
- 在13x13特征图上检测物体,对小物体检测精度不够。改进是:将不同大小的特征图结合起来:最后一个池化层输入 26x26x512 -> 13x13x2048 + 13x13x1024
- 使用不同尺寸图片训练,增强模型鲁棒性,每10个batch就改变输入图片大小
- backbone使用Darknet-19,相比于Vgg,参数更少速度更快,采用3x3卷积核,共:19卷积层+5池化层
–
网络结构(在v1基础上去掉了全连接层,在每一个卷积层后边都添加了一个BN层,这两个改变提升了速度):
22卷积层,
global average pooling替代了FC(全连接层)
实现细节:
对输入数据归一化、每个卷积之后加BN层(把数据限制在相似范围,加快训练速度、防止过拟合)、
支持可变分辨率、
删除dropout(发现没有过拟合)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
–
YOLO9000
- 特点:可以实时检测超过9000种物体
- 主要贡献:使用检测数据集(数据量少、类别少)和分类数据集进行联合训练,提高模型泛化能力。
- 做法:因分类数据集标签粒度小于检测,所以合并了imagenet和coco的标签,构建了字典树
–
检测数据集标签只有粗略的分类,但是分类数据集标签有精细的分类。
在v2基础上,对数据集进行了融合,提出一个实时检测算法,能识别超过9000类对象,因此被称为YOLO9000
利用WordTree(用树形结构对标签进行融合),将分类和检测任务进行联合训练,
对于没有方框标注的物体也能预测出其方框,能够对词典中9000个概念进行预测
- 1
- 2
- 3
- 4
- 5
https://blog.csdn.net/woduitaodong2698/article/details/85566567
YOLO V3
在V2基础上进行一些小的改动来优化模型效果
- 网络结构(采用Darknet-53结构,在v2的基础上每隔两层增加了一个short cut层(残差网络),以训练深层的网络,解决梯度消失或者梯度爆炸的问题): Darknet-53 106个卷积层
- 实现细节:锚框使用kmeans聚类、共9个锚框(每个尺寸3个)、LOSS后三项用二分类交叉熵代替误差和的平方、多尺度预测(更能检测到细粒度物体)、大量使用残差网络(能够更深、避免梯度消失爆炸问题)
yolov3创新点:
- 多尺度预测:引入FPN,结合了3个尺度进行特征融合。使其在小物体上也能有很好的检测效果
- 更深的基础分类网络Darknet-53做为特征提取器,包含53个卷积层。类似ResNet引入了残差结构。
- Softmax层被替换成一个1x1的卷积层+logistic激活函数的结构。
分类损失采用binary cross-entropy loss(二分类交叉损失熵),更好地支持多标签检测。因为检测数据存在语义重叠的标签(如女人和人),但softmax基于一个假设,每个检测框中物体只存在一个类别。 - Tiny-YOLOv3主要区别就是:只结合2个尺度进行特征融合。
https://blog.csdn.net/weixin_43646592/article/details/113826876
import numpy as np
def kmeans(data,num,max_iter,tolerance):
'''
num: 目标聚类中心个数
max_iter:最大迭代次数
tolerance:衡量聚类结果是否已经稳定
'''
# step1 为待聚类的点随机寻找聚类中心
centers = {}
for i in range(num):
centers[i] = data[i]
# step2 计算每个点到聚类中心的距离,将各个点归类到离该点最近的聚类中去
for i in range(max_iter):
clf = {}
for feature in data:
distances = []
for center in centers:
dis = np.linalg.norm(feature - centers[center])
distances.append(dis)
classification = distances.index(min(distances))
clf[classification].append(feature)
# step3 计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心,
# 反复执行 step - 2、3,直到聚类中心不再进行大范围移动或者聚类次数达到要求为止
prev_centers = dic(centers)
for c in clf:
centers[c] = np.average(clf[c], axis=0)
opt = True
for center in centers:
ori_center = prev_centers[center]
curr_center = centers[center]
# 聚类中心在大范围移动 > tolerance
if np.sum((curr_center - ori_center) / ori_center = 100) > tolerance:
opt = False
if opt:
break
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
yolov4
特点:集大成,用了很多tricks;将主流目标检测器分为:input,backbone, neck,head
结构:
Backbone:CSPDarknet53
Neck:SPP,FPN+PAN
Head:YOLOv3
YOLOv4 = CSPDarknet53 + SPP + (FPN+PAN) + YOLOv3
- 1
- 2
- 3
- 4
创新点:
- input:训练时对输入的改进,包括mosaic数据增强,cmBN, SAT自对抗训练
- backbone: 结合各种新的结构,CSPDarknet53, Mish激活函数,Dropblock
- neck:SPP(空间金字塔池化)模块、FPN(自上而下金字塔,将高层语义特征传下来)+PAN(自下而上金字塔,低层定位特征传上去) 结构
- 损失函数:损失函数使用CIOU Loss,nms使用 DIOU nms
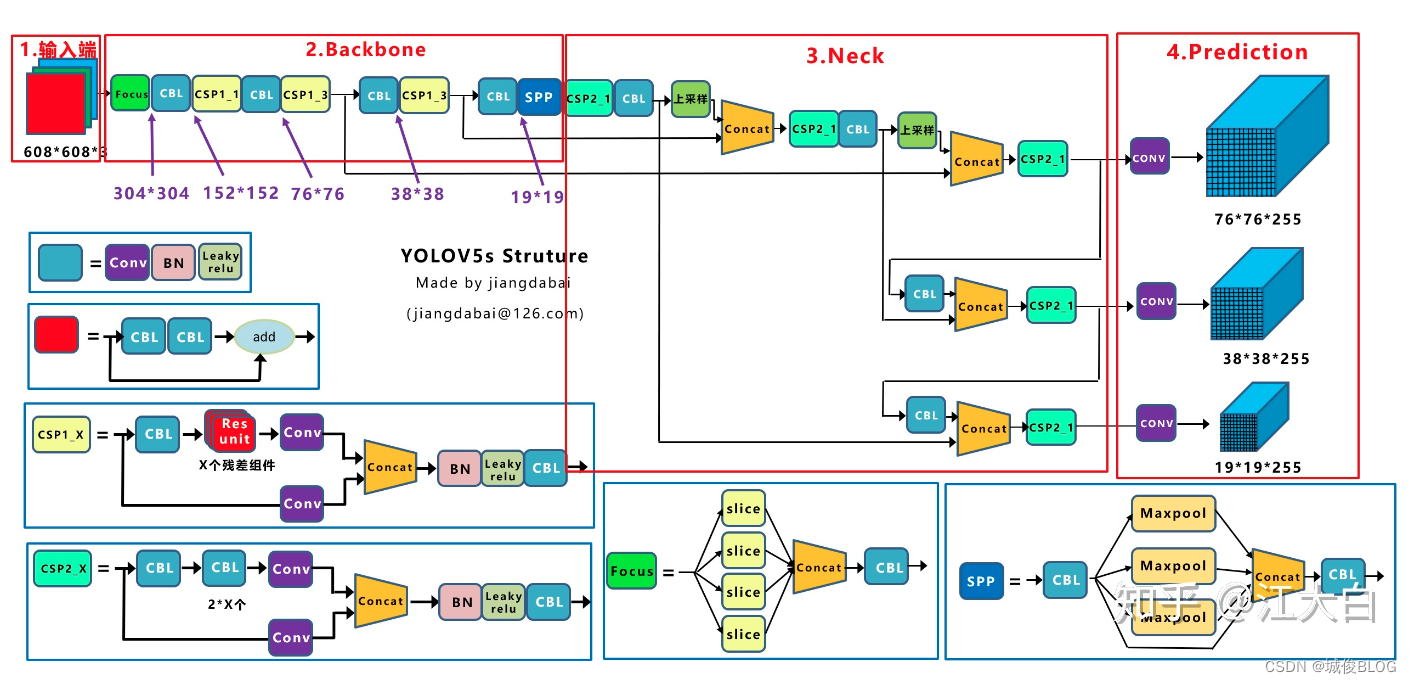
YOLO V5
X: 模型最大,性能最好
L: 表现居中
M: 表现居中
S:速度最快,精度略逊
v5:团队专门维护的开源项目,接口定义完善,
https://www.bilibili.com/video/BV1NA411s7Ba?from=search&seid=12675322693619951568&spm_id_from=333.337.0.0
https://zhuanlan.zhihu.com/p/73606306?from_voters_page=true
创新点:
(1)输入端:数据增强(Mosaic、Copy paste、Random affine、MixUp)、自适应锚框计算
(2)Backbone:Focus结构,New CSP-Darknet53
(3)Neck:FPN+PAN结构 New CSP-PAN
(4)Prediction:GIOU_Loss 损失函数
其他改进之处:消除Grid敏感度 匹配正样本(Build Targets)
- 1
- 2
- 3
- 4
- 5
关于(1):在Yolov3、Yolov4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。当然,如果觉得计算的锚框效果不是很好,也可以在代码中将自动计算锚框功能关闭。
自适应图片缩放:目标检测算法中常见的是将不同尺寸的图片统一缩放到一个标准尺寸,再送入检测网络中。但Yolov5代码中对此进行了改进,也是Yolov5推理速度能够很快的一个不错的trick。作者认为,在项目实际使用时,很多图片的长宽比不同,因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。因此在Yolov5的代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。图像高度上两端的黑边变少了,在推理时,计算量也会减少,即目标检测速度会得到提升。通过这种简单的改进,推理速度得到了37%的提升,可以说效果很明显。(只在测试时使用、填充灰边和黑边是一样的)
关于(2):YOLOv4 和 YOLOv5 都使用 CSP(Cross Stage Partial Network,跨阶段局部网络)结构,解决了其他大型卷积网络结构中的重复梯度问题,减少模型参数和FLOPS。这对 YOLO 有重要的意义,即保证了推理速度和准确率,又减小了模型尺寸。区别:YOLOv4只有主干网络中使用了CSP结构,而YOLOv5中设计了两种CSP结构,CSP1_X应用于BackBone主干网络,另一种CSP_2X结构则应用于Neck中。
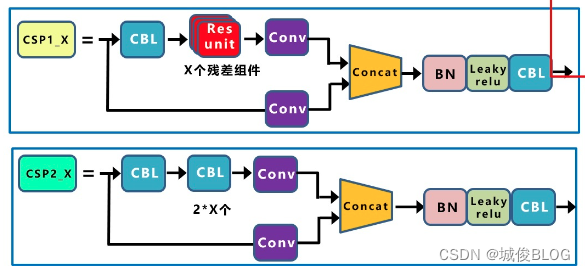
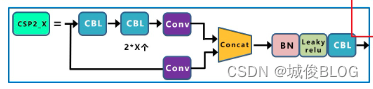
关于(3):Yolov5现在的Neck和Yolov4中一样,都采用FPN+PAN的结构,但在Yolov5刚出来时,只使用了FPN结构,后面才增加了PAN结构,此外网络中其他部分也进行了调整。Yolov4的Neck结构中,采用的都是普通的卷积操作。而Yolov5的Neck结构中,采用借鉴CSPnet设计的CSP2_X结构,加强网络特征融合的能力。
CBL= conv + BN + Leaky Relu
关于(4):Yolov4在DIOU_Loss的基础上采用DIOU_nms的方式,而Yolov5中采用加权nms的方式。采用DIOU_nms,对于遮挡问题,检出效果有所提升。在损失函数和NMS方法上,YOLOv4使用的方法要比v5的方法更有优势。
https://www.jiangdabai.com/2117
https://blog.csdn.net/l641208111/article/details/109286497
https://cloud.tencent.com/developer/article/1843074
其他6 - x 的Yolo版本:http://antkillerfarm.github.io/deep%20object%20detection/2020/12/18/Deep_Object_Detection_9.html
yolov6
改进:
- RepVGG style的Backbone。
- 更简洁高效的Decoupled Head。
yolov7
改进:
- 扩展了高效长程注意力网络,称为Extended-ELAN(E-ELAN)。
- auxiliary head。
yolov8
改进:
- 分类损失为VFL Loss,其回归损失为CIOU Loss+DFL(Distribution Focal Loss)。
- TOOD的TaskAlignedAssigner。
yolox
改进:
- Decoupled Head结构。简单说,分类和回归两个任务的head不再共享参数。
- Mosaic + MixUp的数据增强方法。不过需要注意:在训练的最后15个epoch,这两个数据增强会被关闭掉。
- Anchor Free。基于中心点,预测网格左上角的两个偏移量,以及预测框的高度和宽度。
- SimOTA样本匹配。
附录:
注:
附1: ROI Pooling
ROI Pooling过程
ROI(Region of Interest) :通过不同区域选择方法,从原始图像(original image)得到的候选区域(proposal region)。Fast RCNN中提出
- 得到最后一个卷积层的输出feature map
- 根据feature map与原图的比例,将原图上的ROI映射到feature map对应位置上(图片的尺寸已经下降了16 倍,那么输入的 ROI 也会相应的就行缩小16倍,在代码中 spatio_scale=1/16);
- 将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同);
- 对每个sections进行max pooling操作
ROI Pooling作用
把卷积最后一层输出的feature map上不同大小的候选框(对应原图上的候选框),转换为相同大小的特征,作为下一层全连接的输入
ROI Pooling和SPP区别
- SPP针对同一个输入使用了多个不同尺寸的池化操作,把不同尺度的结果拼接作为输出;
- 而ROI Pooling可看作单尺度的SPP,对于一个输入只进行一次池化操作。
https://blog.csdn.net/qq_35586657/article/details/97885290
ROI Pooling和RPN区别
RPN(Faster RCNN中提出)负责产生候选框,ROI Poorling负责产生固定尺寸的输出特征
- RPN第一次提出是在faster rcnn论文中,对于任意尺寸的输入图像,产生一系列目标矩形框。取代了rcn中采用ss算法生成候选框的方法来产生候选框。
- RoI Pooling层则负责收集proposal,并计算出proposal feature maps,送入后续网络。
- Rol pooling层有2个输入:原始的feature maps,RPN输出的proposal boxes(大小各不相同)
https://blog.csdn.net/phily123/article/details/120273646
ROI Pooling和 ROI Align
ROI Pooling和ROI Align:都是把特征图上不同大小的ROI转换成相同大小的输出特征
ROI Align (Mask RCNN中提出):是对ROI Pooling的改进,主要区别是取消量化操作。使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。具体操作:
- 遍历每一个候选区域,保持浮点数边界不做量化。
- 将候选区域分割成k x k个单元,每个单元的边界也不做量化。
- 在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。(如采样点数是1,那么就是这个单元的中心点。如果采样点数是4,那么就是把这个单元平均分割成四个小方块以后它们分别的中心点)
RoI Align 与 RoI Pooling的区别在于前者在计算过程中会用到所有数据,而后者则会丢失数据。
https://blog.csdn.net/qq_34108497/article/details/129049084
附2: CIOU 和DIOU NMS
GIOU:
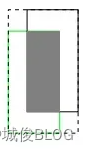

loss = 1 - GIoU,其中Ac是同时包含了预测框和真实框的最小框的面积,U是预测和真实框的并集。GIoU计算公式后半部分是预测和真实框没有重叠的部分。
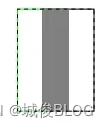
GIoU缺点:1)两个框属于包含关系时会退化成IOU;2)严重依赖IOU,在水平/垂直方向上等式中Ac-U面积小(上图为水平方向示例),退化为IOU,回归效果差,误差较大,难收敛,不稳定。
DIOU
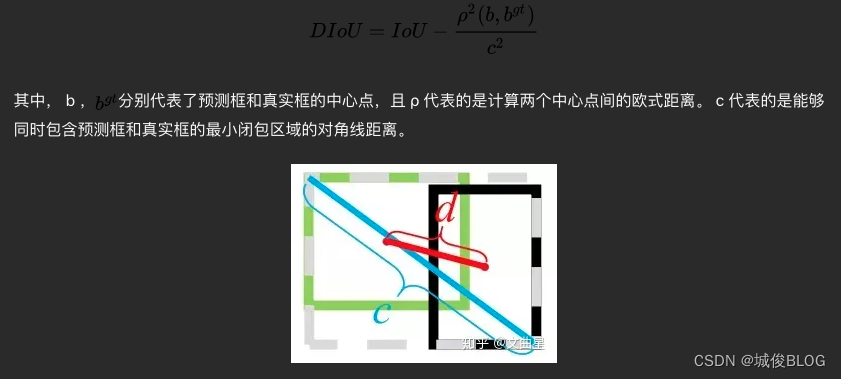
DIOU是对GIOU的改进:将 最小外接框来最大化重叠面积的惩罚项 修改成最小化两个BBox中心点的标准化距离从而加速损失的收敛过程
缺点:未考虑长宽比
CIOU
CIOU是对DIOU的改进:加入长宽比相似性的度量。惩罚项:

https://aitechtogether.com/article/18153.html
附3: Yolov5整体结构图
https://www.jiangdabai.com/2117

