
热门标签
热门文章
- 1如何用NLP辅助投资分析?三大海外机构落地案例详解
- 2Python基于深度学习的车辆特征分析系统(V2.0),附源码
- 3NLP中任务总结_cloze task
- 4常见的cuda出错及解决方法_cuda异常
- 5国产具身人形机器人征服复杂场景: 实时感知规划,动态运动告别“盲走”
- 6鸿蒙Harmony应用开发—ArkTS声明式开发(基础组件:AlphabetIndexer)_鸿蒙 private arr: a[] = [] 添加值
- 7vs2010最佳配色选择_2010年代35部最佳电影
- 8NLP学习笔记——BERT的一些应用(简记)_bertlmheadmodel
- 9直播预告|Sora 会怎样驱动视频编解码领域的突破与革新
- 10【python】之pyautogui库,实现自动化办公!_pyautogui办公
当前位置: article > 正文
LLM - Hugging Face 工程 BERT base model (uncased) 配置_bert-base-uncased网盘
作者:Cpp五条 | 2024-04-01 05:02:18
赞
踩
bert-base-uncased网盘
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/131400428
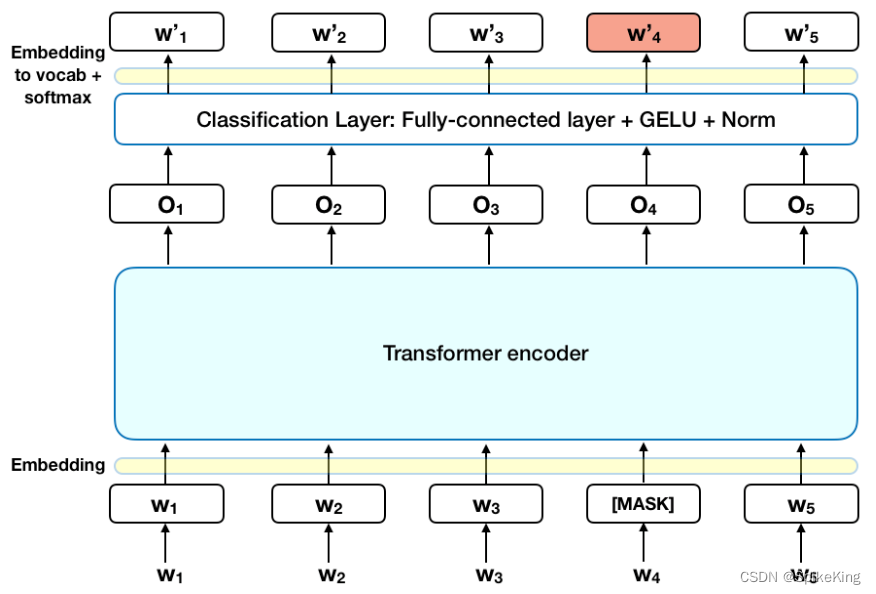
BERT是一个在大量英文数据上以自监督的方式预训练的变换器模型。这意味着它只是在原始文本上进行预训练,没有人以任何方式对它们进行标注(这就是为什么它可以使用大量公开可用的数据),而是用一个自动的过程来从这些文本中生成输入和标签。更准确地说,它是用两个目标进行预训练的:
- 掩码语言建模 (Masked Language Modeling,MLM) :给定一个句子,模型随机地掩盖输入中的15%的词,然后将整个掩盖的句子通过模型,并且必须预测掩盖的词。这与传统的循环神经网络(RNN)不同,它们通常是一个接一个地看词,或者与像GPT这样的自回归模型不同,它们内部地掩盖未来的词。这使得模型能够学习句子的双向表示。
- 下一句预测 (Next Sentence Prediction,NSP):模型在预训练期间将两个掩盖的句子作为输入拼接起来。有时它们对应于原始文本中相邻的句子,有时不是。然后模型必须预测这两个句子是否是相互跟随的。
uncased 表示不区分大小写
Hugging Face:bert-base-uncased
配置 ssh 之后,使用 git 下载工程,模型使用占位符:
git clone git@hf.co:bert-base-uncased
- 1
从 Hugging Face 网站,下载 5 个大文件:
flax_model.msgpack # 417M
model.safetensors # 420M
pytorch_model.bin # 420M
rust_model.ot # 509M
tf_model.h5 # 511M
- 1
- 2
- 3
- 4
- 5
使用 bypy 下载文件,参考:CSDN - 使用网盘快速下载 Hugging Face 大模型
bypy info
bypy downdir /bert-base-uncased/ ./bert-base-uncased/
- 1
- 2
完成更新 5 个文件。
测试脚本:
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained("bert-base-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
print(f"output.last_hidden_state: {output.last_hidden_state.shape}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出:
output.last_hidden_state: torch.Size([1, 12, 768])
- 1
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/347520
推荐阅读
相关标签

