- 1BUUCTF做题Upload-Labs记录pass-01~pass-10_buuctf uploads-labs
- 2揭秘Kimi+:官方智能体提示词泄露_kimi 提示词泄露
- 3【论文笔记】Digital Twin in Industry: State-of-the-Art——Tao Fei
- 4IPC之 - C#中用Socket 实现进程间通信_c# ipc通讯
- 5Anaconda基本教程及常用命令(介绍、安装、基本操作、管理环境、管理包、conda和pip以及借助pqi换源)_anacondar的有关命令
- 6计算机网络网络层之层次化路由_层次化算力路由
- 7基于Hadoop与Spark大数据平台的个性化图书推荐系统搭建学习总结_基于spark的图书推荐系统实验报告
- 8dify-on-wechat中涉及企业微信几个函数解析_dify集成企业微信
- 9OpenSSL补丁安装(二)_openssl补丁怎么打
- 10【版本控制-TortoiseSVN】_svn删除分支
【Python笔记】基础篇(七)_python ret.write
赞
踩
参考视频和资料:第一阶段-第七章-01-函数的多返回值_哔哩哔哩_bilibili
Day07
对应视频:第一阶段第七章
第七章 函数进阶
目录
一、函数的多返回值
1.分析

只会执行第一个return,因为当代码运行到第一个return的时候,就代表该函数执行完毕,直接退出了
2.语法
return 返回值1,返回值2,...
支持不同类型的数据return
【注意】:接收时按照返回值的顺序进行接收
变量1,变量2 = 函数()
- def fun():
- return 1,"Hello",True
-
- x,y,z = fun()
- print(x)
- print(y)
- print(z)
- # 结果:
- # 1
- # Hello
- # True
二、函数多种传参方式
1.位置参数
def 函数名(形参1,形参2,...)
函数体
调用:
函数名(实参1,实参2,...)
调用函数时,根据函数定义的参数位置来传递参数
【注意】:传递的参数和定义的参数的顺序及个数必须一致
- def fun(name,age,gender):
- print(f"姓名:{name},年龄:{age},性别:{gender}")
-
- # 位置参数
- fun("张三",18,"男")
- # 结果:姓名:张三,年龄:18,性别:男
2.关键字参数
函数调用通过“键=值”的形式传递参数
(1)关键字传参
def 函数名(形参1,形参2,...)
函数体
调用:
函数名(形参1=XXX,形参2=XXX,...)
- def fun(name,age,gender):
- print(f"姓名:{name},年龄:{age},性别:{gender}")
- # 关键字参数
- fun(name="李四",age=20,gender="女")
- fun(age=20,gender="女",name="李四")
- fun("张三",gender="男",age=23)
- # 结果:
- # 姓名:李四,年龄:20,性别:女
- # 姓名:李四,年龄:20,性别:女
- # 姓名:张三,年龄:23,性别:男
(2)可以不按照固定顺序
(3)可以和位置参数混用,但是位置参数必须在前,并且传参要按照顺序;而关键字参数不存在先后顺序
3.缺省参数
也称为默认参数,用于定义函数,为参数提供默认值
调用函数时可不传该默认参数的值,此时就使用默认值
调用函数时,如果为缺省参数传参,则表示此时修改默认参数值,不使用默认参数
【注意】:所有位置参数必须出现在默认参数前,包括函数定义和调用
- def fun(name,age,gender="女"):
- print(f"姓名:{name},年龄:{age},性别:{gender}")
-
- fun("张三",18,"男")
- # 结果:姓名:张三,年龄:18,性别:男
- fun("李四",18)
- # 结果:姓名:李四,年龄:18,性别:女
- def fun(name,age=18,gender):
- print(f"姓名:{name},年龄:{age},性别:{gender}")
- # 报错:SyntaxError: non-default argument follows default argument
4.不定长参数
(1)定义
也称为可变参数,用于不确定调用的时候会传递多少个参数(也可以不传参)的场景
当调用函数时不确定参数个数时, 可以使用不定长参数
(2)类型
位置传递
def 函数名(*形参)——一般形参写成args
传进的所有参数都会被形参变量收集,它会根据传进参数的位置合并为一个元组(tuple)
- def fun(*args):
- print(f"参数的类型是:{type(args)}内容是:{args}")
-
- fun(1,True,"Hello")
- # 结果:参数的类型是:<class 'tuple'>内容是:(1, True, 'Hello')
关键字传递
def 函数名(**形参)——一般形参写成kwargs
传进去的参数应为“键=值”的形式, 所有的“键=值”都会被形参接受, 同时会根据“键=值”组成字典
- def fun(**kwargs):
- print(f"参数的类型是:{type(kwargs)}内容是:{kwargs}")
-
- fun(name="张三",age=20,gender="男")
- # 结果:参数的类型是:<class 'dict'>内容是:{'name': '张三', 'age': 20, 'gender': '男'}
三、匿名函数
1.函数作为参数传递
属于计算逻辑的传递,而非数据的传递。
一个函数相当于是一串代码的封装,一般表达了一种功能,比如两数相加。而将函数作为参数传递,就相当于将这种功能进行了传递,也就是代码执行逻辑的传递。
【例如】:加减乘除等任何逻辑都可以自行定义并作为函数传入。
数据传递就相当于是传入数字和字符串等数据
- # 函数作为参数进行传递
- def fun(compute):
- result = compute(1,2)
- print(f"compute参数的类型是:{type(compute)},结果是:{result}")
-
- def add(x,y):
- return x + y
-
- def fun2(x,y):
- return (x * y) + y
-
- fun(add)
- fun(fun2)
- # 结果:
- # compute参数的类型是:<class 'function'>,结果是:3
- # compute参数的类型是:<class 'function'>,结果是:4
 '运行
'运行
2.lambda匿名函数
(1)基本知识点
def关键字:可以定义带有名称的函数
可以基于名称重复使用
lambda关键字:可以定义匿名函数(无名称)
【注意】:只可临时使用一次
就是写一句可以被执行的逻辑(功能)
(2)语法
lambda 传入参数:函数体————(函数体都是一行的代码)
传入参数表示匿名函数的参数形式,如:x,y表示接收2个形式参数
- def fun(compute):
- result = compute(1,2)
- print(f"compute参数的类型是:{type(compute)},结果是:{result}")
-
- fun(lambda x,y:x + y)
- fun(lambda x,y:(x * y) + y)
- # 结果:
- # compute参数的类型是:<class 'function'>,结果是:3
- # compute参数的类型是:<class 'function'>,结果是:4
第八章 文件操作
一、文件的编码
计算机只认识0和1,这就使得需要将文件转换为0和1才能保存在计算机中;同时在读取的时候,也需要将0和1反向翻译回原来的文本
文本文件的内容是使用编码技术(密码本)将内容翻译成0和1供计算机识别和存入硬盘的
1.编码技术
翻译的规则,记录了如何将内容翻译成二进制,以及如何将二进制翻译回可识别内容
2.可用编码
UTF-8、GBK、Big5等
【注意】:不同的编码,对同一内容翻译成的二进制也不同
3.查看文件编码
用windows自带的记事本打开,右下角就会显示编码格式
UTF-8是目前全球通用的编码格式,一般以它进行编码
二、文件的读取
1.基本知识点
内存中存放的数据在计算机关机后就会消失
若需要长久保存数据,就要使用硬盘、光盘、U 盘等设备
为了便于数据的管理和检索,引入了“文件”的概念
2.文件
(1)一篇文章、一段视频、一个可执行程序,都可以被保存为一个文件,并赋予一个文件名。
(2)操作系统以文件为单位管理磁盘中的数据。
(3)分类:文本文件、视频文件、音频文件、图像文件、可执行文件等
3.文件的操作
打开、读写和关闭等
(1)open()打开函数
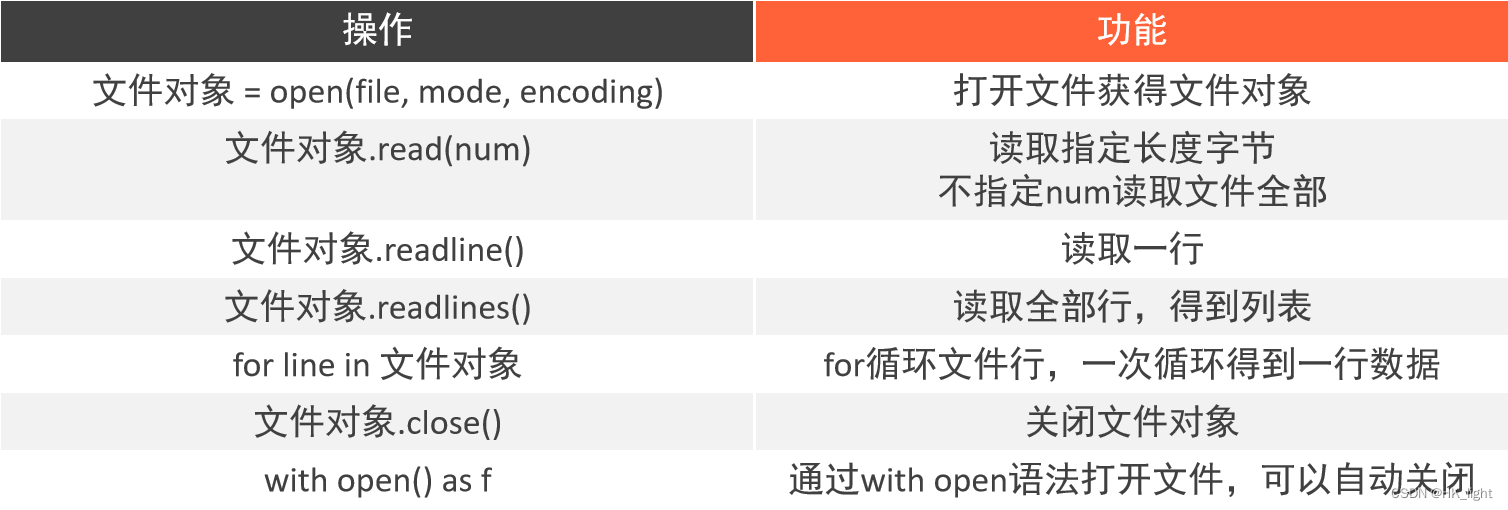
open(name,mode,encoding)
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。
mode:设置打开文件的模式(访问模式):只读(r)、写入(w)、追加(a)等。
encoding:编码格式(一般为UTF-8)
- # 打开
- f = open("D:/studydata/python/basis/practice/test.txt","r",encoding="UTF-8")
- print(type(f))
- # 结果:<class '_io.TextIOWrapper'>
此时的’f‘是‘open’函数的文件对象,对象是Python中一种特殊的数据类型,拥有属性和方法,可以使用"对象.属性"或"对象.方法"对其进行访问
【注意】:encoding实际上并不是形参中的第三位,要用关键字传参的方式(该函数总共有七个参数,encoding在第四位)
【小技巧】:可以用ctrl键加鼠标点击open,点进去就能看到open里的参数了

对象就是类被实例化之后所得到的一个实例
(2)mode常用的基础访问模式

(3)read()
文件对象.read(num)
num表示要从文件中读取的数据的长度,单位:字节
如果没有传入num,表示读取文件中所有的数据
- # 读取 read()
- print(f"读取十个字节的结果是:{f.read(10)}")
- # 结果:读取十个字节的结果是:你好,python
- print(f"接着上次读取,在这之后后的全部内容是:{f.read()}")
- # 结果:
- # 接着上次读取,在这之后后的全部内容是:好好学习
- # 天天向上
- # 冲冲冲
- # 加油加油
【注意】:当连续读取字节时,读取的内容是从上一个读取结束的位置开始的
(4)readlines()
按照行的方式把整个文件中的内容进行一次性读取,并封装到一个列表中返回,其中每一行的数据为一个元素
换行符也会以\n的形式读出
- # readlines()
- list1 = f.readlines()
- print(f"使用readlines读取的结果是:{list1},类型是:{type(list1)}")
- # 结果:使用readlines读取的结果是:['你好,python\n', '好好学习\n', '天天向上\n', '冲冲冲\n', '加油加油'],类型是:<class 'list'>
(5)readline()
一次读取一行内容
- # readline()
- line1 = f.readline()
- line2 = f.readline()
- print(line1)
- # 结果:你好,python
- print(line2)
- # 结果:好好学习
(6)for循环读取文件行
for 临时变量 in open("python.txt", "r"):
# for line in 文件对象:
print(临时变量)
- # for循环读取
- for line in f:
- print(line)
- # 结果:你好,python
- #
- # 好好学习
- #
- # 天天向上
- #
- # 冲冲冲
- #
- # 加油加油
(7)close()关闭文件对象
f = open("python.txt", "r")
f.close()
通过close关闭文件对象,就是关闭对文件的占用
【注意】:如果不调用close关闭,并且程序没有停止运行,那么这个文件将一直被Python程序占用
(8)with open
with open("python.txt", "r",encoding="UTF-8") as f:
对文件的操作
可以在操作完成后自动关闭文件,避免遗忘掉close方法
- # with open
- with open("D:/studydata/python/basis/practice/test.txt","r",encoding="UTF-8") as f:
- print(f.read())
- # 结果:
- # 你好,python
- # 好好学习
- # 天天向上
- # 冲冲冲
- # 加油加油
三、文件的写入
1.文件写入
传入的mode值为w
f.write(输入的内容)
该语句并没有直接将数据写到硬盘中,而是将其写到内存的某一块区域中(缓冲区),只有当用flush语句或者close语句时,才会写入——close方法中内置了一个flush。这样避免了频繁的操作硬盘,导致效率下降(攒一堆,一次性写硬盘。可以结合操作系统理解)

- # 对不存在的文件进行写操作
- f = open("D:/studydata/python/basis/practice/Hello.txt","w")
- f.write("Hello World")
- f.flush()
- f.close()
【注意】:在使用w权限打开不存在的文件时,会自动新建一个
当使用w权限打开已存在文件的时候,写入的内容会将以前的内容全部覆盖掉
- # 对存在的文件进行写操作
- f = open("D:/studydata/python/basis/practice/Hello.txt","w")
- f.write("你好")
- f.flush()
- f.close()
2. 内容刷新
f.flush()
四、文件的追加
传入的mode值为a
文件不存在会创建文件
文件存在会在最后,追加写入文件
想要换行输入"\n"
1.对已存在的文件进行内容的追加
- # 对存在的文件进行追加操作
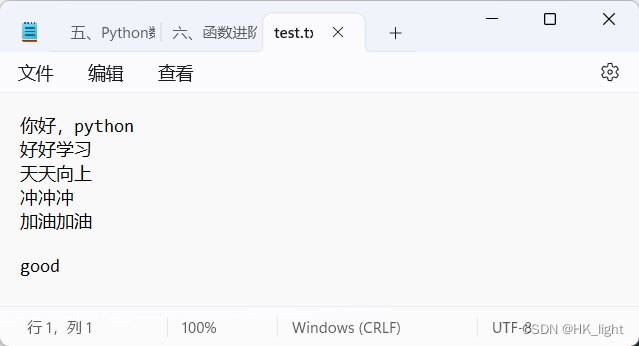
- f = open("D:/studydata/python/basis/practice/test.txt","a")
- f.write("\ngood")
- f.flush()
- f.close()
2.对不存在的文件进行内容的追加
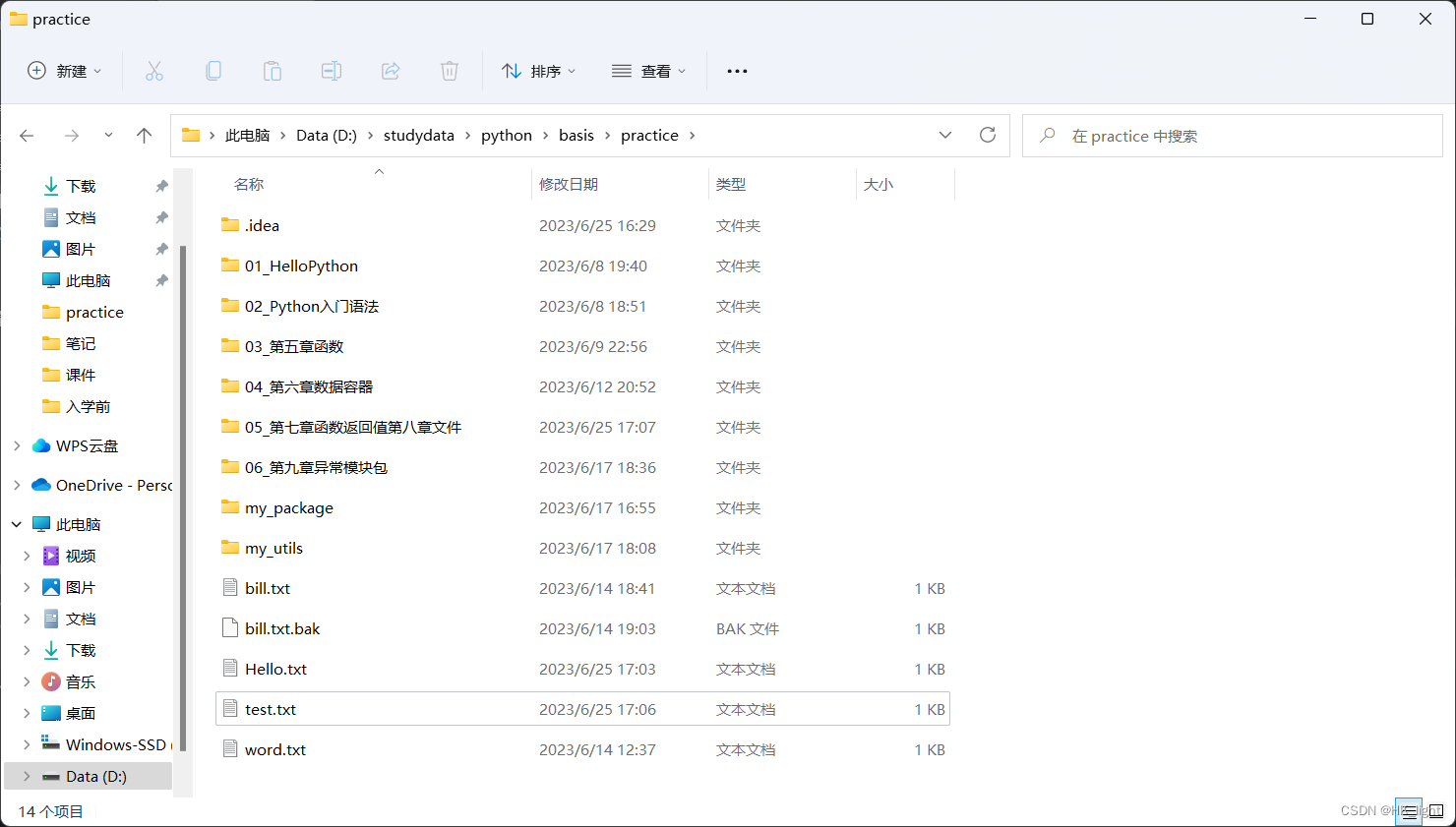
- # 对不存在的文件进行写操作
- f = open("D:/studydata/python/basis/practice/test1.txt","a")
- f.write("Hello World")
- f.flush()
- f.close()
五、文件操作综合案例
1.单词计数小练习

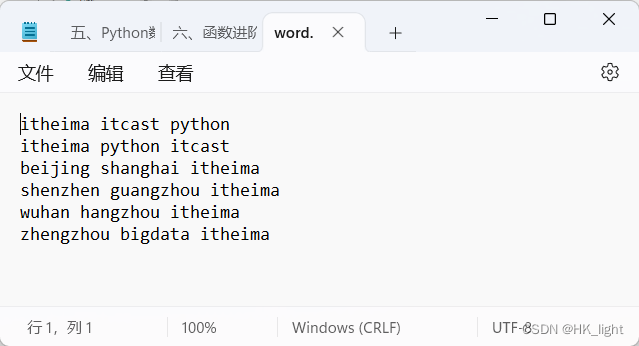
- """
- 对word文件进行读取,并且统计itheima出现的次数
- """
- f = open("D:/studydata/python/basis/practice/word.txt","r",encoding="UTF-8")
- # 方法一
- # 读取全部内容,同一计数
- content = f.read()
- num = content.count("itheima")
- print(num)
- # 结果:6
-
- # 方法二
- # 一行一行累加计数
- sum = 0
- for line in f:
- num = line.count("itheima")
- sum += num
- print(sum)
- # 结果:6
-
- # 方法三
- # 每行计数,采用==的方法
- i = 0
- for line in f:
- # 去掉换行符
- line = line.strip()
- # 分割对象,存入列表中
- list1 = line.split(" ")
- for word in list1:
- if word == "itheima":
- i += 1
- print(i)
- # 结果:6
- f.close()
【注意】:以上代码不能一次性执行,不然得到的结果会是6、0、0。因为多次读取同一文件会从上次读取的地方开始
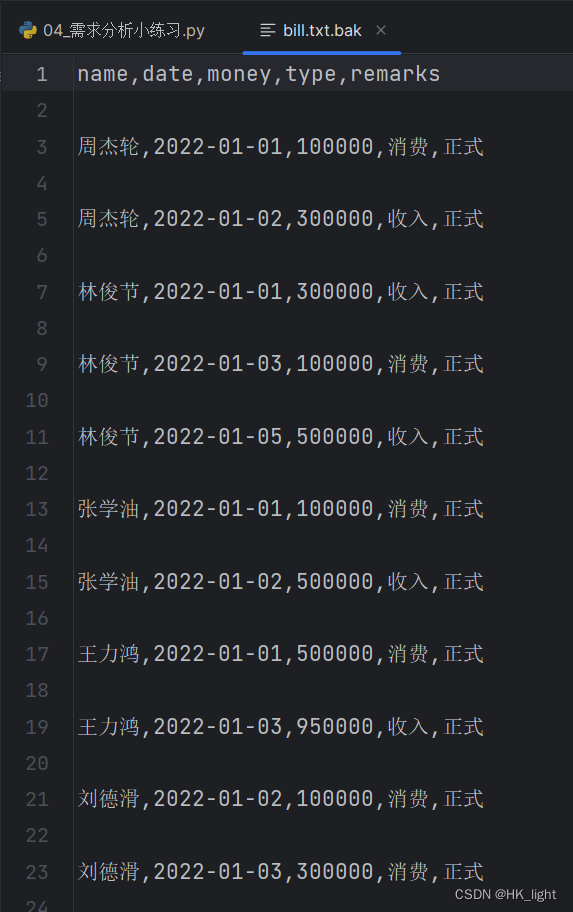
2.需求分析小练习


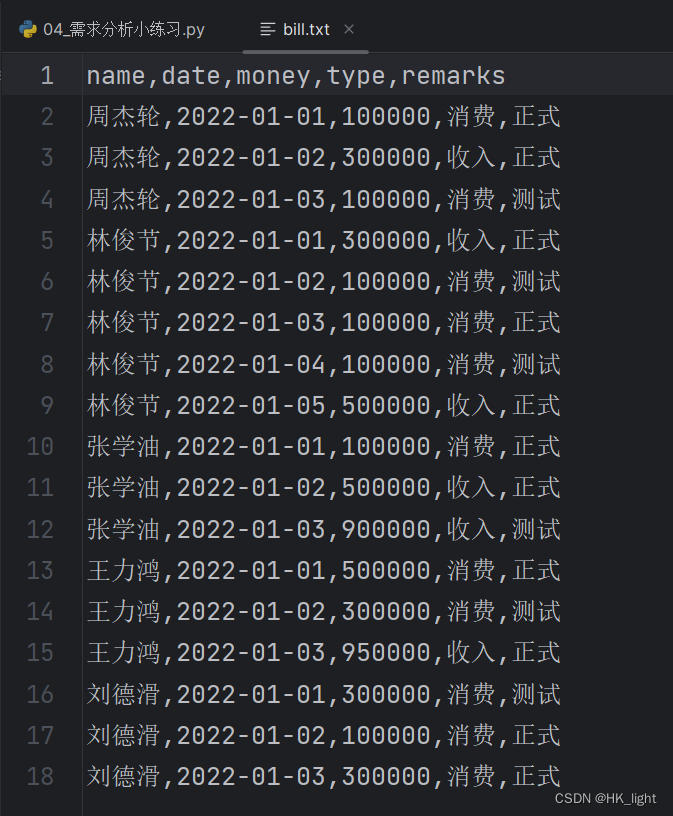
- # 方法一
- f1 = open("D:/studydata/python/basis/practice/bill.txt","r",encoding="UTF-8")
- f2 = open("D:/studydata/python/basis/practice/bill.txt.bak","w",encoding="UTF-8")
-
- for line in f1:
- i = 0
- # 去掉首位空格换行符
- words = line.strip()
- # 以逗号分隔存入列表
- words = words.split(",")
- # 用循环语句找到“测试”字符串,当存在测试字符串的时候用i作为标记,当i等于0时才写入新文档中
- for word in words:
- if word == "测试":
- i += 1
- if not i:
- f2.write(line)
- f2.write("\n")
-
- f1.close()
- f2.close()
-
- # 方法二
- # f1 = open("D:/studydata/python/basis/practice/bill.txt","r",encoding="UTF-8")
- # f2 = open("D:/studydata/python/basis/practice/bill.txt.bak","w",encoding="UTF-8")
- #
- # for line in f1:
- # words = line.strip()
- # if words.split(",")[4] == "测试":
- # continue
- #
- # f2.write(line)
- # f2.write("\n")
- #
- # f1.close()
- # f2.close()
第九章 异常、模块和包
一、异常
1.定义
程序运行过程中出现了错误,也就是bug
当python运行检测到一个错误时,Python解释器就无法继续执行,会出现了一些错误的提示
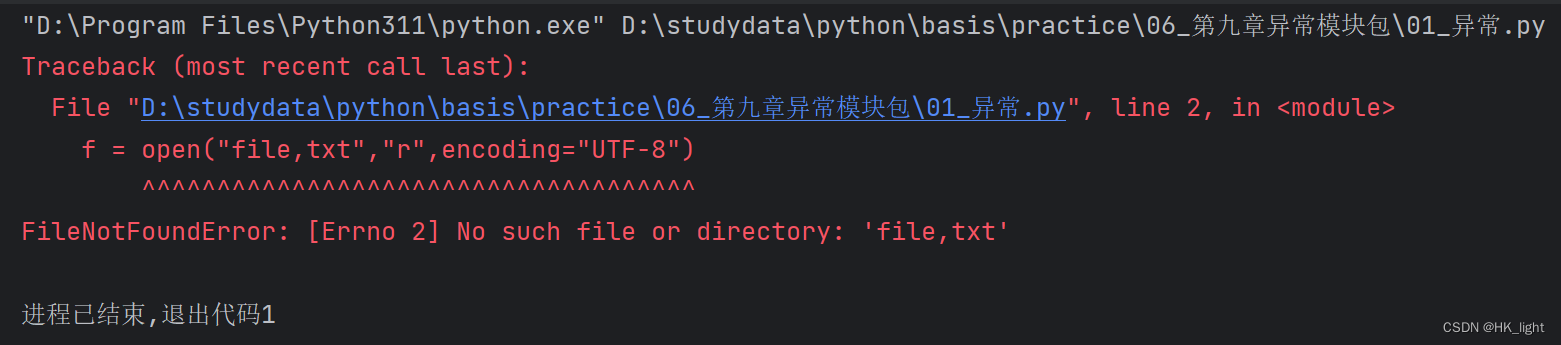
【例如】:1用读的方式打开一个不存在的文件,就会出现异常提示
- # 打开不存在文件出现异常
- f = open("file,txt","r",encoding="UTF-8")
- # 结果:FileNotFoundError: [Errno 2] No such file or directory: 'file,txt'
2.异常处理(捕获异常)
(1)定义
对可能出现的bug,进行提前准备、提前处理
(2)程序遇到bug的两种情况
整个程序因为一个BUG停止运行
对BUG进行提醒, 整个程序继续运行
(3)语法

a.捕获出现的异常
try:
可能发生错误的代码
except:
如果出现异常执行的代码
- # 捕获异常
- # 当读的Linux文件不存在的时候,就会以写的形式打开
- try:
- f = open('D:/studydata/python/basis/practice/file.txt', 'r')
- print("读取正常")
- except:
- print("程序出现异常,读的文件不存在,将以写的形式打开")
- f = open('D:/studydata/python/basis/practice/file.txt', 'w')
- # 结果:程序出现异常,读的文件不存在,将以写的形式打开
b.捕获指定异常
try:
可能发生错误的代码
except 异常的类型 as 别名:
如果出现异常执行的代码
(别名记录了异常的具体信息)
只会处理指定的异常,对于其他类型的异常并不会处理
- # 捕获指定异常
- try:
- print(name)
- except NameError as e:
- print(f"出现了变量未定义的异常,异常内容是:{e}")
- # 结果:出现了变量未定义的异常,异常内容是:name 'name' is not defined
一般try下方只放一行尝试执行的代码。
c.捕获多个异常
try:
可能发生错误的代码
except (异常类型1,异常类型2,..):
异常出现执行的代码
- # 捕获多个异常
- try:
- print(name)
- # print(1/0)
- except (NameError, ZeroDivisionError) as e:
- print(f"出现了变量未定义,或者出现了除以0的异常")
- print(f"异常的内容是{e}")
- # 结果1:
- # 出现了变量未定义,或者出现了除以0的异常
- # 异常的内容是name 'name' is not defined
- # 结果2:
- # 出现了变量未定义,或者出现了除以0的异常
- # 异常的内容是division by zero
d.捕获全部异常
try:
可能发生错误的代码
except Exception as 别名:
如果出现异常执行的代码
- # 捕获所有异常
- try:
- # 1/0
- print(name)
- except Exception as e:
- print(f"出现异常了,异常的内容是{e}")
- # 结果1:出现异常了,异常的内容是division by zero
- # 结果2:出现异常了,异常的内容是name 'name' is not defined
a方法也可以捕获所有异常,但是d方法更常用
e.异常的else
try:
可能发生错误的代码
except Exception as e:
异常出现执行的代码
else:
异常未出现执行的代码
- # 异常的else
- try:
- print("Hello")
- 1/0
- print(name)
- except Exception as e:
- print(f"出现异常了,异常的内容是:{e}")
- else:
- print("没有出现异常")
- # 结果:
- # Hello
- # 出现异常了,异常的内容是:division by zero
f.异常而finally
try:
可能发生错误的代码
except Exception as e:
异常出现执行的代码
else:
异常未出现执行的代码
finally:
无论异常出不出现都要执行的代码
- # 异常的finally
- try:
- f = open('D:/studydata/python/basis/practice/error.txt', 'r')
- print("读取文件")
- except Exception as e:
- print(f"出现异常了,异常的内容是:{e}")
- f = open('D:/studydata/python/basis/practice/error.txt', 'w')
- else:
- print('没有异常')
- finally:
- print("有没有异常都要执行")
- f.close()
- # 没有对应的文件时:
- # 出现异常了,异常的内容是:[Errno 2] No such file or directory: 'D:/studydata/python/basis/practice/error.txt'
- # 有没有异常都要执行
-
- # 有对应的文件时:
- # 读取文件
- # 没有异常
- # 有没有异常都要执行
3.异常的传递

(1)定义
当函数func01中发生异常, 并且没有捕获处理这个异常的时候, 异常会传递到函数func02, 当func02也没有捕获处理这个异常的时候,main函数会捕获这个异常, 这就是异常的传递性.
异常的传递性可以使我们不需要到正真出现异常的那段代码中,直接在它的上一层或者顶层处理异常
【注意】:当所有函数都没有捕获异常的时候,程序就会报错
- """
- 异常的传递
- """
- def fun1():
- print("fun1开始")
- 1/0
- print("fun1结束")
-
- def fun2():
- print("fun2开始")
- 1/0
- print("fun2结束")
-
- def main():
- fun2()
-
- def main():
- try:
- fun2()
- except Exception as e:
- print(f"出现异常了,异常的内容是:{e}")
-
- main()
- # 结果:
- # fun2开始
- # 出现异常了,异常的内容是:division by zero
(2)小技巧
利用异常的传递性, 当我们想要保证程序不会因为异常崩溃的时候, 就可以在main函数中设置异常捕获, 由于无论在整个程序哪里发生异常, 最终都会传递到main函数中, 这样就可以确保所有的异常都会被捕获
二、模块
1.定义
Python 模块(Module),是一个 Python 文件,以 .py 结尾。
模块能定义函数,类和变量,模块里也能包含可执行的代码
2.模块的作用
python中有很多各种不同的模块, 每一个模块都可以帮助我们快速的实现一些功能
【例如】:实现和时间相关的功能就可以使用time模块
可以认为一个模块就是一个工具包, 每一个工具包中都有各种不同的工具供我们使用,从而实现各种不同的功能。
可以将模块导入,然后去使用模块里定义好的函数或者变量等
3.语法
(1)导入方式
[from模块名] import[模块|类|变量|函数|*] [as 别名]
[]中的内容可选,*表示导入模块的全部内容
其中,导入模块相当于导入.py代码文件
常用组合形式
a.import 模块名
import 模块名1,模块名2
(按住Ctrl+鼠标左键点击,可以看跳转模块内容;Ctrl+f可以搜索函数)
使用:
模块名.功能名()
通过.可以使用模块内部的全部功能,包括:类、函数和变量等,确定层级关系
- # 使用python自带time模块
- import time
- print("Hello")
- time.sleep(2)
- print("python")
- # 结果:
- # Hello————在此后面停顿了两秒钟
- # python
b.from 模块名 import 功能名
使用:
功能名()
表示导入模块的某项功能
- from time import sleep
- print("Hello")
- sleep(2)
- print("python")
- # 结果:
- # Hello————在此后面停顿了两秒钟
- # python
c.from 模块名 import *
使用:
功能名()
表示将模块中的内容全部导入
与a的区别在于使用时的语句
- from time import *
- print("Hello")
- sleep(2)
- print("python")
- # 结果:
- # Hello————在此后面停顿了两秒钟
- # python
d.import 模块名 as 别名
- import time as t
- print("Hello")
- t.sleep(2)
- print("python")
- # 结果:
- # Hello————在此后面停顿了两秒钟
- # python
time.sleep(秒)
表示程序运行到该代码行的时候暂停执行设定的秒数
e.from 模块名 import 功能名 as 别名
- from time import sleep as sl
- print("Hello")
- sl(2)
- print("python")
- # 结果:
- # Hello————在此后面停顿了两秒钟
- # python
d和e相当于给具体的模块或者功能起一个别名
【注意】:模块的导入一般写在代码文件的开头位置(规范)
4.自定义模块
(1)按正常的方式创建python文件写代码,需要的时候import就可以了
每个Python文件都可以作为一个模块,模块的名字就是文件的名字
自定义模块名必须要符合标识符命名规则
- # 自定义的my_module1模块
- def add(x,y):
- print(x + y)
- # 自定义模块
- import my_module1
- my_module1.add(1,2)
- # 结果:3
-
- from my_module1 import add
- add(1,4)
- # 结果:5
(2)__name__
解决导入方法内部的测试被调用的问题
(当完成一个大的工程的时候,会分为好几个功能去逐一实现,每当完成一个功能就会测试一下功能的实现情况,为了防止测试的结果也被调用,通常就会采用这种方法)
__name__是一个内置变量,当运行代码的时候这个变量名字就会自动标记为__main__
而导入的模块的时候不会标记为__main__
a.未使用__name__
- # 自定义的my_module2模块
- def test(a, b):
- print(a + b)
-
- test(1, 1)
- import my_module2
- my_module2.test(2,3)
- # 结果:
- # 2
- # 5
b.使用__name__
- def test(a, b):
- print(a + b)
-
- # __name__是一个内置变量,当运行代码的时候这个变量名字就会自动标记为__main__
- # 而导入的模块的时候不会标记为__main__
- # 只在当前文件中条件结果是True,如果是导入到其他的则是False
- if __name__ == '__main__':
- test (1, 1)
- import my_module2
- my_module2.test(2,3)
- # 结果:
- # 5
(3)当导入多个模块,且模块内有同名的功能. 当调用这个同名功能的时候,调用到的是后面导入的模块的功能
from的时候就相当于把导入的模块执行了一遍
- # 自定义的my_module1模块
- def add(x,y):
- print(x + y)
- # 自定义的my_module3模块
- def add(x,y):
- print(x * y)
- # 不同模块中的同名函数
- from my_module1 import add
- from my_module3 import add
- add(1,2)
- # 结果:2
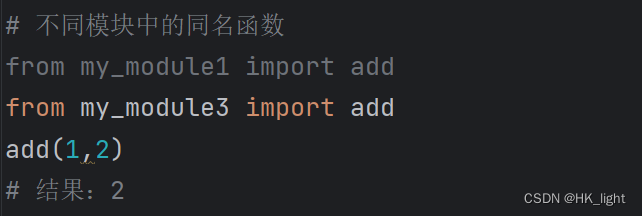
(被使用的模块会在pycharm中会亮起来)
(4)__all__变量
语法:
__all__ = ["需要导入的内容"]
控制了import可以导入的内容
*表示所有,此时表示所有都来自_all_这个变量
【注意】:*的范围受all控制,如果是手动写要导出的方法,是可以用的
- # 自定义的my_module4模块
- __all__ = ["add_1"]
-
- def add_1(x,y):
- print(x - y)
-
- def add_2(x, y):
- print(x + y)
- # *导入指定函数
- from my_module4 import *
- add_1(1,2)
- # 结果:-1
- add_2(1,2)
- # 结果:NameError: name 'add_2' is not defined. Did you mean: 'add_1'?
-
- from my_module4 import add_2
- add_2(1,2)
- # 结果:3
三、包
1.定义
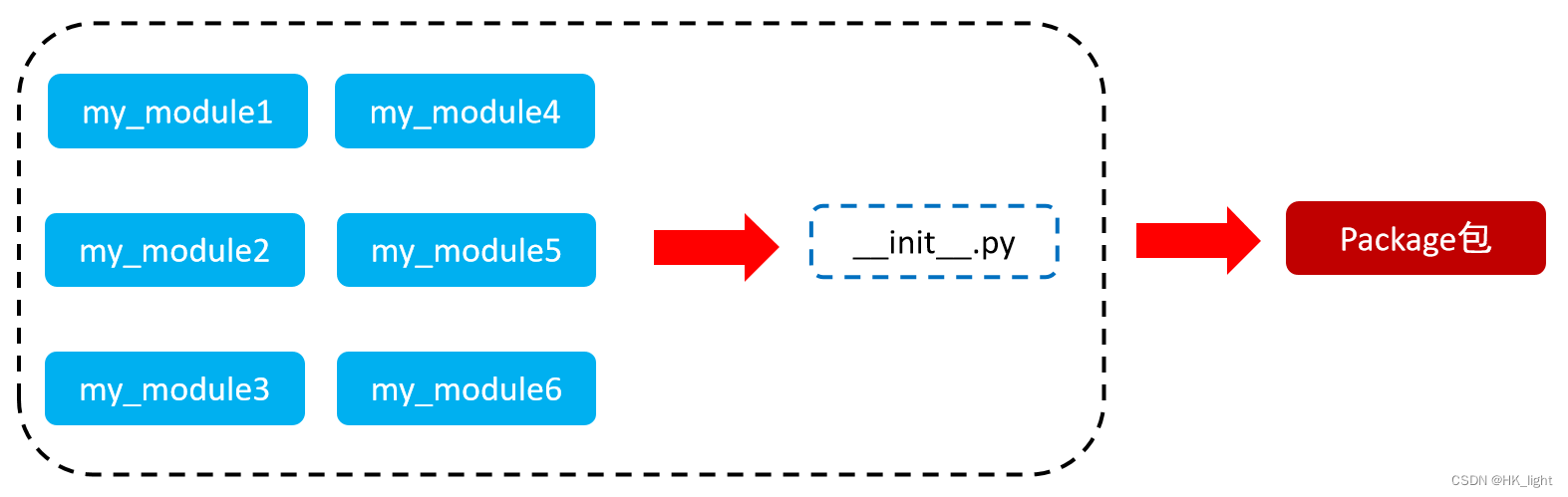
从物理上看,包就是一个文件夹,在该文件夹下包含了一个 __init__.py文件,该文件夹可用于包含多个python模块文件
【注意】:当不包含__init__.py文件的时候就是一个普通的文件夹
从逻辑上看,包的本质依然是模块,一个包相当于同类模块的结合体
在pycharm中,包和文件夹图标不太一样,包的图标中含有一个圆点
2.作用
管理多个模块文件,防止混乱
3.创建方法
Pycharm中的基本步骤:
[New]——[Python Package]——输入包名——[OK]——新建功能模块(有联系的模块)

【注意】:新建包后,包内部会自动创建`__init__.py`文件,这个文件控制着包的导入行为
先创建包
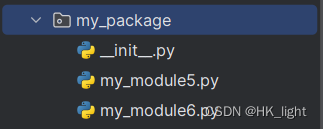
- # 自定义my_package包中的my_module5模块
- def print1():
- print("包中的模块1")
- # 自定义my_package包中的my_module6模块
- def print2():
- print("包中的模块2")
4.导入包
(1)方法一
import 包名.模块名
使用:
包名.模块名.目标
- # 包中的模块
- import my_package.my_module5
- import my_package.my_module6
-
- my_package.my_module5.print1()
- # 结果:包中的模块1
- my_package.my_module6.print2()
- # 结果:包中的模块2
(2)方法二
from 包名 import 模块名1,模块名2,...
使用:
模块名.目标
- from my_package import my_module5,my_module6
- my_module5.print1()
- # 结果:包中的模块1

(3)方法三
from 包名.模块名 import 目标名
使用:
目标名
- from my_package.my_module5 import print1
- print1()
- # 结果:包中的模块1
(4)控制可导入的模块列表
from 包名 import *
在`__init__.py`文件中添加`__all__ = []`,控制允许导入的模块列表
同样,all控制了*的范围
- # __init__.py文件中添加限制
- _all_ = ["my_module6"]
- from my_package import *
- my_module6.print2()
- # 结果:包中的模块2
- my_module5.print1()
- # 结果:NameError: name 'my_module5' is not defined. Did you mean: 'my_module2'?
5.自定义包小练习

test.txt中的内容:
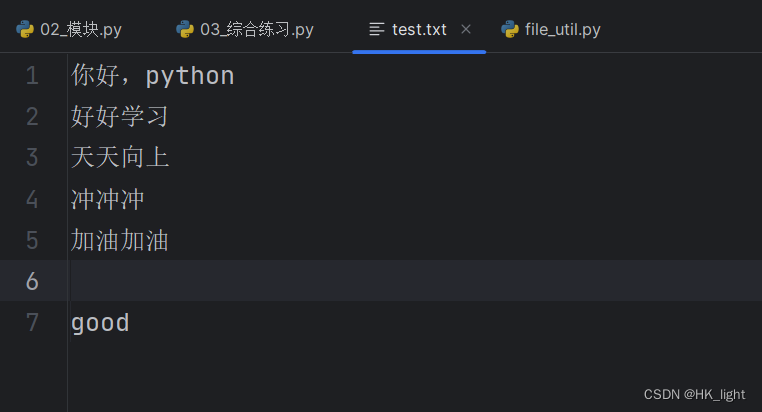
- # my_utils中的file_util.py文件
- def print_file_info(file_name):
- """
- 读取文件内容
- :param file_name: 需要读取的文件路径
- :return: None
- """
- f = None
- try:
- f = open(file_name,"r",encoding="UTF-8")
- except Exception as e:
- print(f"文件不存在,出错的原因:{e}")
- else:
- content = f.read()
- print("文件的内容是:")
- print(content)
- finally:
- # 当try中文件读取失败的时候,不会给f赋值,此时f还是空。
- # 如果没有如下的判断条件,f.close出现问题,毕竟空内容不是文件,不可以被关闭
- if f:
- f.close()
-
- def append_to_file(file_name,data):
- """
- 追加指定内容到指定文件中
- :param file_name: 需要追加内容的文件路径
- :param data: 追加的内容
- :return: None
- """
- f = open(file_name,"a",encoding="UTF-8")
- f.write(data)
- f.write("\n")
- f.close()
-
- if __name__ == '__main__':
- print_file_info("D:/studydata/python/basis/practice/test.txt")
- print_file_info("test.txt")
- append_to_file("/studydata/python/basis/practice/test.txt","yes")
- # 测试的结果:
- # 文件的内容是:
- # 你好,python
- # 好好学习
- # 天天向上
- # 冲冲冲
- # 加油加油
- #
- # good
- #
- # 文件不存在,出错的原因:[Errno 2] No such file or directory: 'test.txt'
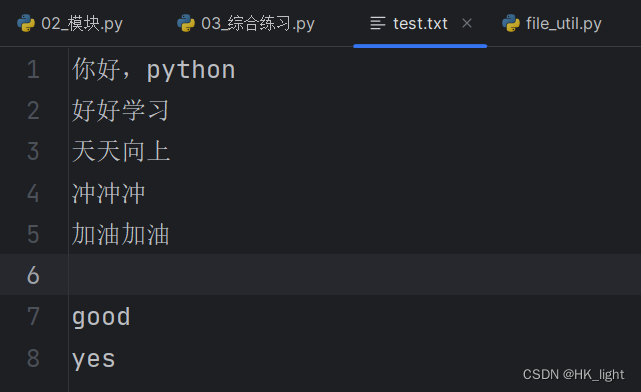
测试后test.txt中的内容 :
- # my_utils中的str_util.py文件
- def str_reverse(s):
- """
- 将传入的字符串反转
- :param s: 传入的字符串
- :return: 返回反转后的值
- """
- str = s[::-1]
- return str
-
- def substr(s,x,y):
- """
- 对指定下标的字符串进行切片
- :param s: 需要切片的字符串
- :param x: 起始下标
- :param y: 结束下标
- :return: 返回切片结果
- """
- str = s[x:y]
- return str
-
- if __name__ == '__main__':
- print(str_reverse("hello"))
- print(substr("hellopython",5,11))
- # 测试的结果:
- # olleh
- # python
- from my_utils import str_util
- import my_utils.file_util
-
- print(str_util.str_reverse("python"))
- print(str_util.substr("python",0,2))
- # 结果:
- # nohtyp
- # py
-
- my_utils.file_util.print_file_info("D:/studydata/python/basis/practice/test.txt")
- # 结果:
- # 文件的内容是:
- # 你好,python
- # 好好学习
- # 天天向上
- # 冲冲冲
- # 加油加油
- #
- # good
- my_utils.file_util.append_to_file("D:/studydata/python/basis/practice/test.txt","good")
- my_utils.file_util.print_file_info("D:/studydata/python/basis/practice/test.txt")
- # 结果:
- # 文件的内容是:
- # 你好,python
- # 好好学习
- # 天天向上
- # 冲冲冲
- # 加油加油
- #
- # good
- # good
6.第三方包
(1)定义
非python官方发布的包,安装可以扩展功能,提高开发效率
(2)pip(python内置安装第三方包)
在命令提示符中输入
pip install 包名
默认链接国外的网站,下载会比较慢
可以选择在国内的网站安装(清华大学提供的一个镜像网站)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名称
pip install -i 网址 包名称

【小技巧】:Ctrl+C:命令提示符中将正在运行的程序停下来
(3)使用pycharm安装
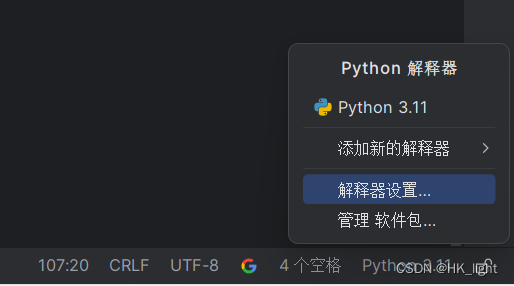
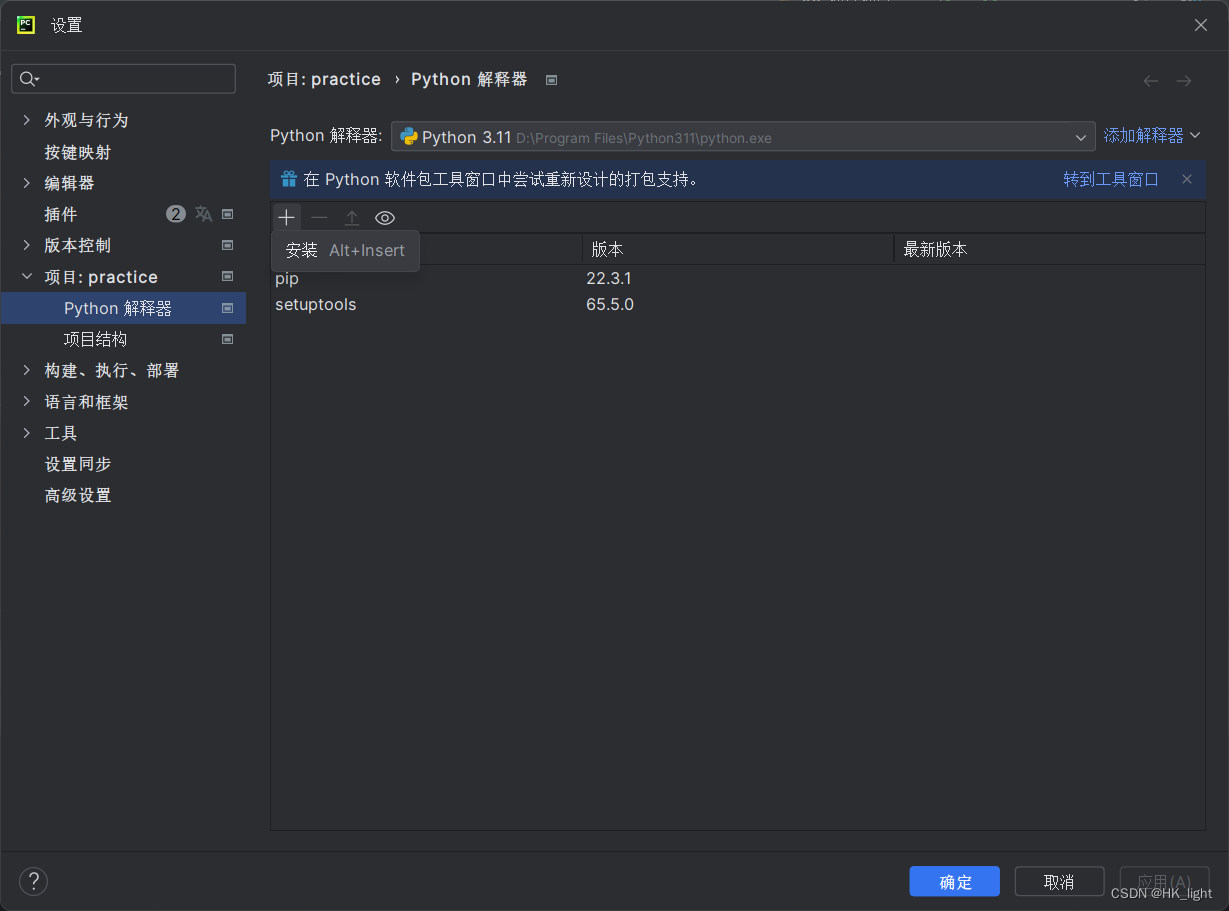
右下角点击python——解释器设置:会显示目前已经安装的包,点左上角的加号就可以寻找下载了
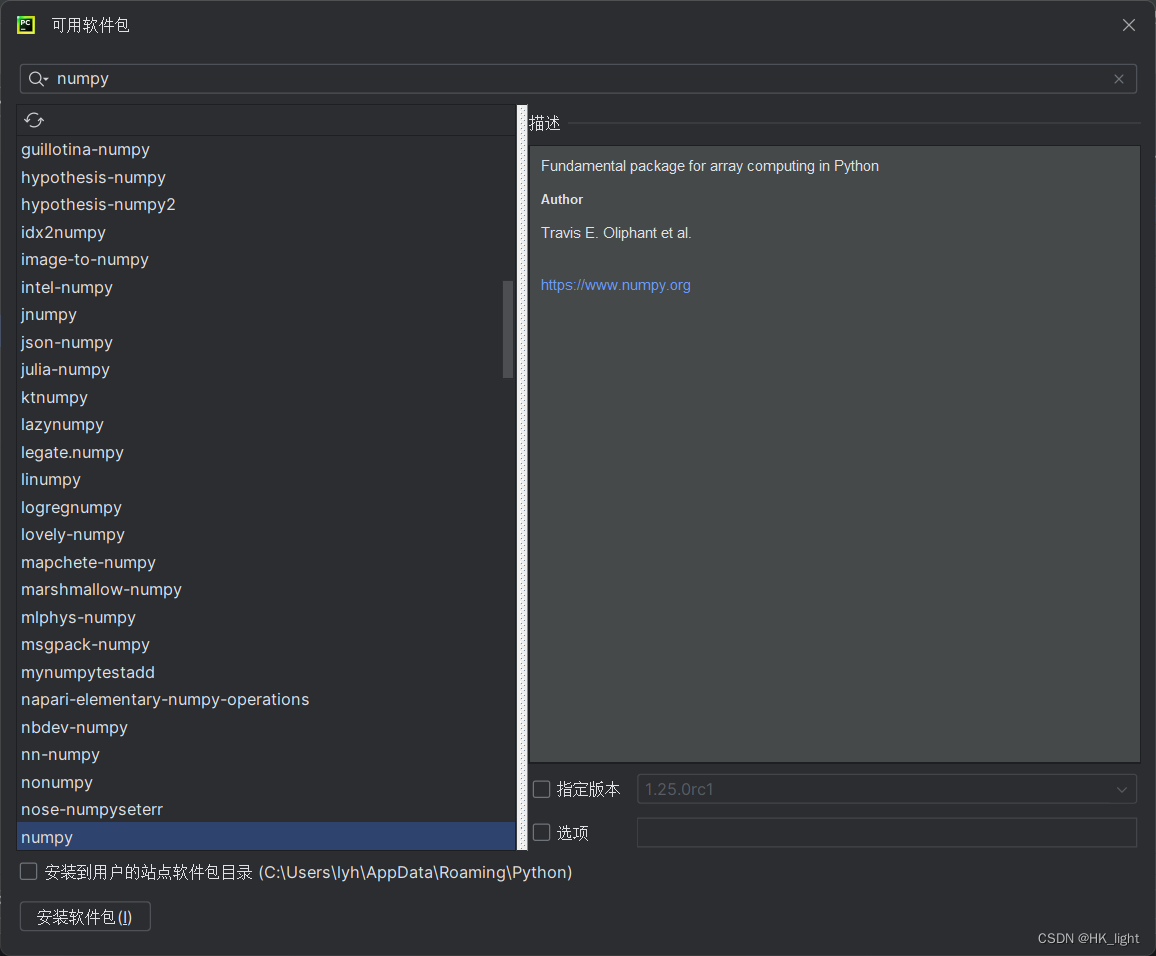
同样是默认去国外下载,想改下载地址就将options选项勾上,输入-i 地址