
- 1数据挖掘之决策树归纳算法的Python实现_python 决策树算法 相近问题归纳
- 2Verilog RTL新手实验分析总结_rtl-p实验
- 3win10安装misql8_win10 安装mysql 8.0.12
- 45-在Linux上部署各类软件_linux 部署root应用程序
- 5C语言的内存知识_c语言程序内存空间结构存储
- 6【JAVA毕设|课设】基于SpringBoot+Vue的进销存(库存)管理系统-附下载方式_vue+springboot进销存系统csdn下载
- 7安卓 onActivityResult 废弃,registerForActivityResult 使用详解
- 8pytorch 状态字典:state_dict_torch模型适配state dict
- 9探秘BERT语义相似度计算:BertSimilarity开源项目解析与应用
- 10注意力模块
LLMs之LLaMA-3:Llama-3-70B-Gradient-1048k-adapter的简介、源代码解读merge_adapters.py(仅需58行代码)合并多个PEFT模型(LoRA技术)_llama3-gradient
赞
踩
LLMs之LLaMA-3:Llama-3-70B-Gradient-1048k-adapter的简介、源代码解读merge_adapters.py(仅需58行代码)合并多个PEFT模型(LoRA技术)将LLaMA-3扩展到100万/1048k上下文——解析命令行参数→在基础模型上循环加载LoRA模型→加载分词器模型→将合并后的模型以及分词器保存到指定目录或推送到模型中心
目录
Llama-3-70B-Gradient-1048k-adapter的简介
Llama-3-70B-Gradient-1048k-adapter的简介
Llama-3 70B Gradient 1048K Adapter是一个从语言模型中提取的LoRA。它是使用mergekit提取的。此适配器可以与任何基于Llama3-70b的模型一起运行(或与之合并),以赋予它1048k的上下文。
| LoRA | LoRA详情 此LoRA适配器是从gradientai/Llama-3-70B-Instruct-Gradient-1048k中提取的,并使用meta-llama/Meta-Llama-3-70B-Instruct作为基础。 |
| 参数 | 使用以下命令提取此LoRA适配器: mergekit-extract-lora meta-llama/Meta-Llama-3-70B-Instruct gradientai/Llama-3-70B-Instruct-Gradient-1048k OUTPUT_PATH --rank=32 |
| 语言 | en pipeline_tag: text-generation tags: meta llama-3 license: llama3 |
| 细节 | 这个模型扩展了LLama-3 8B的上下文长度,从8k到> 1040K,由Gradient开发,由Crusoe Energy提供计算支持。它证明了SOTA LLM可以通过适当调整RoPE theta,仅用极少的训练即可学会在长上下文中运行。我们在这一阶段使用了830M个令牌进行训练,所有阶段总共使用了1.4B个令牌,这还不到Llama-3原始预训练数据的< 0.01%。 |
| 方法 | 方法: >> 以meta-llama/Meta-Llama-3-8B-Instruct为基线 >> 使用NTK感知插值[1]来初始化RoPE theta的最佳调度,然后进行实证RoPE theta优化 >> 在增加上下文长度的渐进式训练,类似于Large World Model[2](见下文详情) |
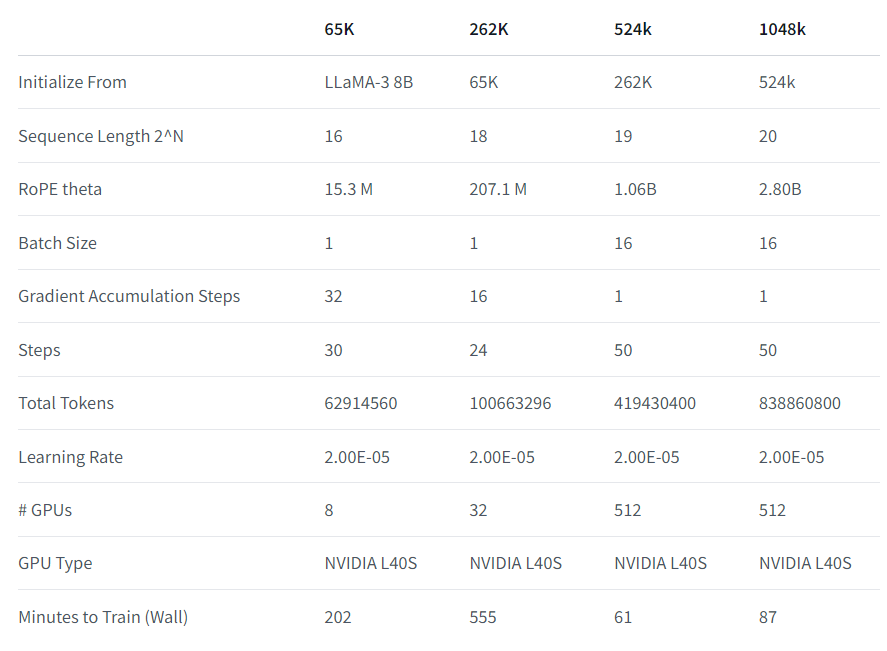
| 基础设施 | 基础设施: 我们在EasyContext Blockwise RingAttention库[3]的基础上构建,以在Crusoe Energy高性能L40S集群上可扩展且高效地训练多达1048k令牌的上下文。 值得注意的是,我们在Ring Attention之上叠加了并行性,并采用了自定义网络拓扑结构,以便在面临由于在设备间传递许多KV块而导致的网络瓶颈时更好地利用大型GPU集群。这使我们在模型训练中获得了33倍的速度提升(比较下表中的524k和1048k与65k和262k)。 |
| 数据 | 数据: 对于训练数据,我们通过增强SlimPajama来生成长上下文。我们还使用基于UltraChat[4]的聊天数据集进行了微调,遵循了与[2]类似的数据增强方法。 |
地址:https://huggingface.co/cognitivecomputations/Llama-3-70B-Gradient-1048k-adapter
1、渐进式训练细节
源代码解读merge_adapters.py(仅需58行代码)合并多个PEFT模型(LoRA技术)将LLaMA-3扩展到100万/1048k上下文——解析命令行参数→在基础模型上循环加载LoRA模型→加载分词器模型→将合并后的模型以及分词器保存到指定目录或推送到模型中心
脚本命令
python merge_adapters.py --base_model_name_or_path <base_model> --peft_model_paths <adapter1> <adapter2> <adapter3> --output_dir <merged_model>Python脚本的命令行调用示例,如上所示,用于执行一个名为merge_adapters.py的脚本。该脚本接受一系列命令行参数,这些参数指定了基础模型和要合并的PEFT模型的路径,以及合并后模型的输出目录。以下是每个参数的解释:
-
--base_model_name_or_path <base_model>:这个参数指定了基础模型的名称或路径。基础模型是合并操作的起点,通常是一个预训练的语言模型。 -
--peft_model_paths <adapter1> <adapter2> <adapter3>:这个参数接受一个或多个PEFT模型的路径。PEFT模型通常包含了在特定任务上对基础模型进行微调的参数。在这个例子中,有三个PEFT模型<adapter1>、<adapter2>和<adapter3>将被合并到基础模型上。 -
--output_dir <merged_model>:这个参数指定了合并后的模型应该保存的目录。<merged_model>是输出目录的路径。
当这行代码在命令行中执行时,merge_adapters.py脚本将被调用,并且使用提供的参数来加载基础模型和PEFT模型,将它们合并,然后将合并后的模型保存到指定的输出目录。这个过程允许用户创建一个包含多个微调任务知识的单一模型,而无需对整个模型进行完全微调。
实现代码
-
- '''
- LLMs之LLaMA-3:源代码解读merge_adapters.py(仅需58行代码)合并多个PEFT模型(LoRA技术)将LLaMA-3扩展到100万/1048k上下文——解析命令行参数→在基础模型上循环加载LoRA模型→加载分词器模型→将合并后的模型以及分词器保存到指定目录或推送到模型中心
- 源代码地址:https://gist.github.com/ehartford/731e3f7079db234fa1b79a01e09859ac
- 这段代码提供了一个工具,允许用户将多个PEFT模型合并到一个基础模型上,从而实现模型能力的扩展。
- PEFT是一种参数高效的微调方法,它允许在不修改基础模型参数的情况下,通过添加少量的参数来适应新的任务。
- 这个脚本简化了合并过程,并提供了将合并后的模型保存到本地或推送到模型中心的功能。通过这种方式,用户可以轻松地在不同的微调任务之间迁移和组合模型改进。
- '''
-
- # This supports merging as many adapters as you want.
- # python merge_adapters.py --base_model_name_or_path <base_model> --peft_model_paths <adapter1> <adapter2> <adapter3> --output_dir <merged_model>
-
- from transformers import AutoModelForCausalLM, AutoTokenizer
- from peft import PeftModel
- import torch
- import os
- import argparse
-
- def get_args():
- parser = argparse.ArgumentParser()
- parser.add_argument("--base_model_name_or_path", type=str)
- parser.add_argument("--peft_model_paths", type=str, nargs='+', help="List of paths to PEFT models")
- parser.add_argument("--output_dir", type=str)
- parser.add_argument("--device", type=str, default="cpu")
- parser.add_argument("--push_to_hub", action="store_true")
- parser.add_argument("--trust_remote_code", action="store_true")
- return parser.parse_args()
-
- def main():
- # 1、解析命令行参数,包括基础模型路径、PEFT 模型路径、输出目录等。
- args = get_args()
-
- # 2、加载基础模型并进行合并
- # 2.1、加载基础模型base_model可以指定模型的数据类型和是否信任远程代码
- # 根据参数选择加载到CPU或自动选择设备
- if args.device == 'auto':
- device_arg = {'device_map': 'auto'}
- else:
- device_arg = {'device_map': {"": args.device}}
- print(f"Loading base model: {args.base_model_name_or_path}")
- base_model = AutoModelForCausalLM.from_pretrained(
- args.base_model_name_or_path,
- return_dict=True,
- torch_dtype=torch.float16,
- trust_remote_code=args.trust_remote_code,
- **device_arg
- )
-
- # 2.2、循环加载并合并PEFT模型:遍历PEFT模型路径列表,加载每个PEFT模型,并将其合并到基础模型上。每次合并后,都会调用merge_and_unload方法释放资源
- model = base_model
- for peft_model_path in args.peft_model_paths:
- print(f"Loading PEFT: {peft_model_path}")
- model = PeftModel.from_pretrained(model, peft_model_path, **device_arg)
- print(f"Running merge_and_unload for {peft_model_path}")
- model = model.merge_and_unload()
-
- # 3、加载与基础模型对应的分词器tokenizer
- tokenizer = AutoTokenizer.from_pretrained(args.base_model_name_or_path)
-
- # 4、根据参数选择将合并后的模型和分词器保存到指定目录或推送到模型中心
- # 如果指定了 --push_to_hub 参数,则将模型和 tokenizer 推送到 Hugging Face Hub。否则,调用 save_pretrained() 方法将模型和 tokenizer 保存到指定的输出目录。
- if args.push_to_hub:
- print(f"Saving to hub ...")
- model.push_to_hub(f"{args.output_dir}", use_temp_dir=False)
- tokenizer.push_to_hub(f"{args.output_dir}", use_temp_dir=False)
- else:
- model.save_pretrained(f"{args.output_dir}")
- tokenizer.save_pretrained(f"{args.output_dir}")
- # 输出保存模型的信息
- print(f"Model saved to {args.output_dir}")
-
- if __name__ == "__main__":
- main()

