
- 1Windows 11 - 打开操作安全中心提示 “需要使用新应用以打开此 Windowsdefender 链接“ 解决方案(电脑更新了 Win11 系统版本后,想关闭病毒防护盾牌的时候提示打不开)_win11获取打开此windowsdefender链接的应用
- 2python 栈的基本操作_python栈的基本语法
- 3从CVE-2024-6387 OpenSSH Server 漏洞谈谈企业安全运营与应急响应_应急响应 saas化
- 4机器学习---迁移学习
- 5一文带你了解深度相机中的全局快门与卷帘快门!
- 6大数据人工智能的实践:成功案例与经验分享
- 7Spring Boot中的Profile:原理、用法与示例_springboot profile
- 82023,软件测试人的未来在哪里?_软件测试985硕士
- 9背包问题——“0-1背包”,“完全背包”(这样讲,还能不会?)_0-1背包问题
- 10python-重点!!序列:列表、元组、集合、字典、字符串_字符串、列表、元组和集合都是序列,其中每个元素都有编号,因此都可以通过索引
Flink|问题处理记录:数据倾斜导致 checkpoint 失败问题处理【v2】_kafka checkpoint
赞
踩
问题现象
当前问题
任务上游为 40 个 Kafka TOPIC,下游为 OTS。
当前配置:
- 每 3 分钟执行一次 checkpoint
- 使用对齐 checkpoint
- 两次 checkpoint 之间间隔 180 秒
- Checkpoint 超时时间为 6000 秒(100 分钟)
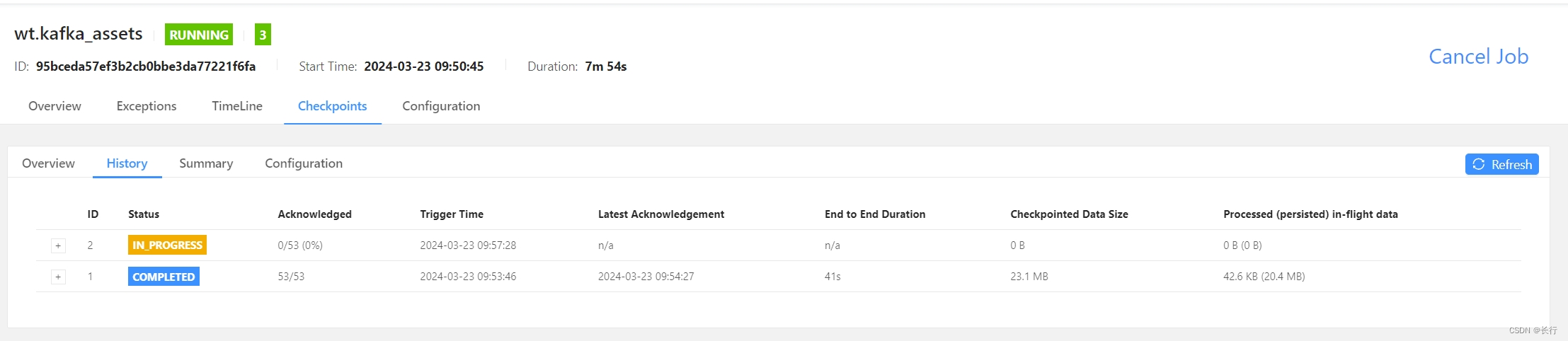
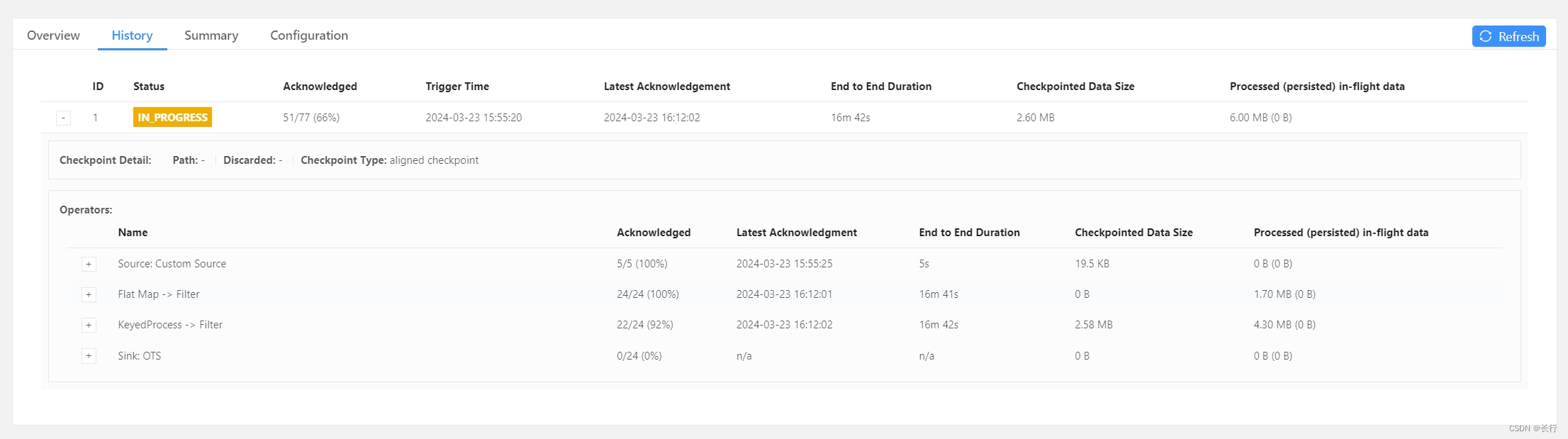
在 2024.03.23 04:13 的 checkpoint 突然无法在 100 分钟内完成,两次 checkpoint 均失败,第 3 次 checkpoint 已可以预支仍会失败。
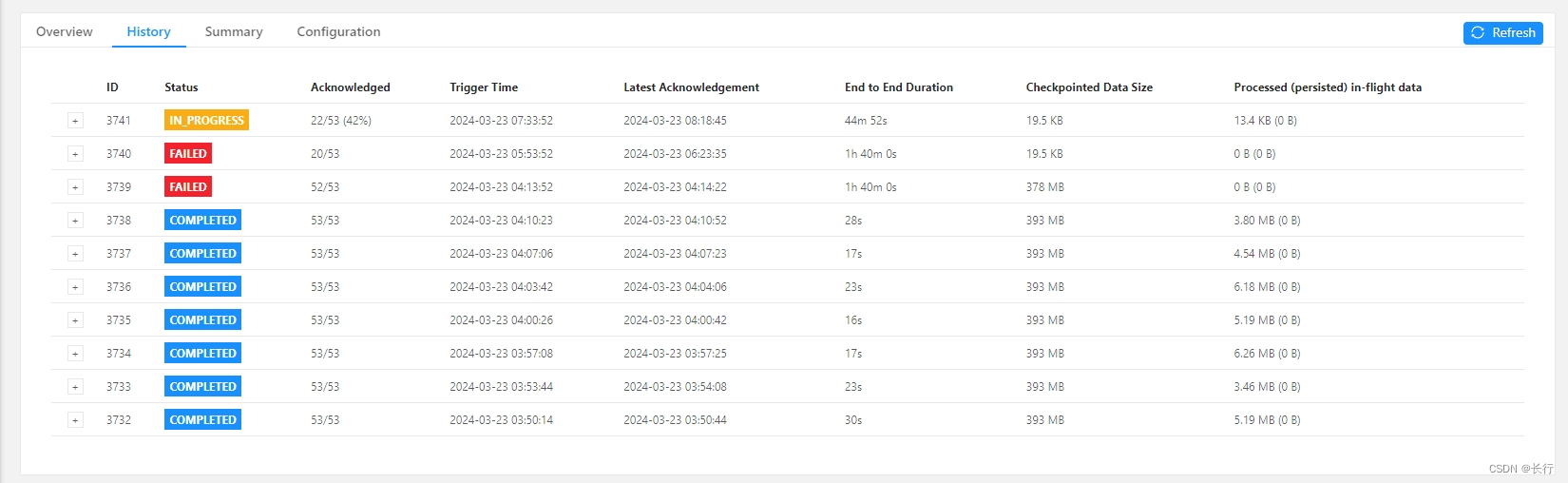
两次失败的 checkpoint(3739 和 3740)的详细信息如下:

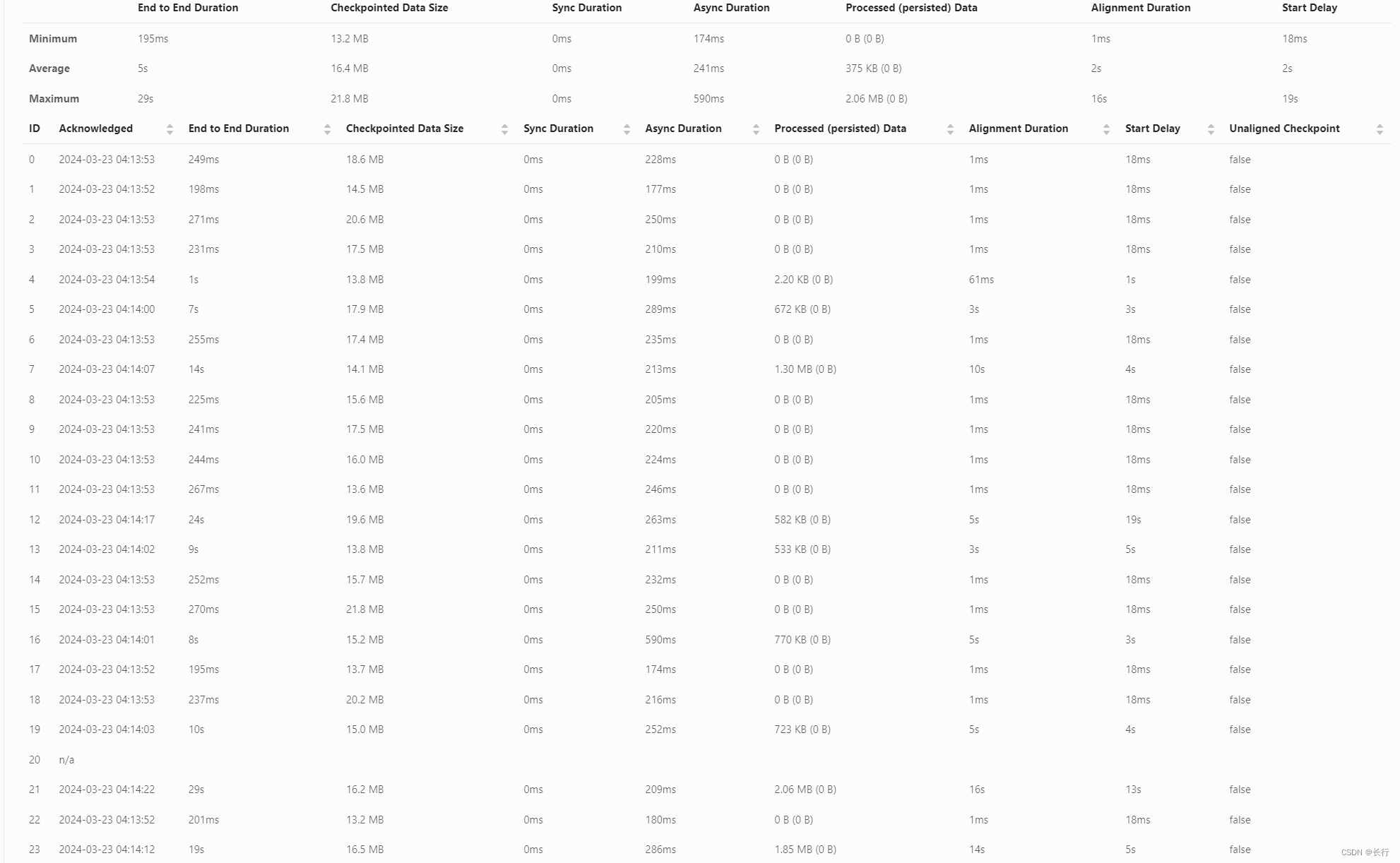

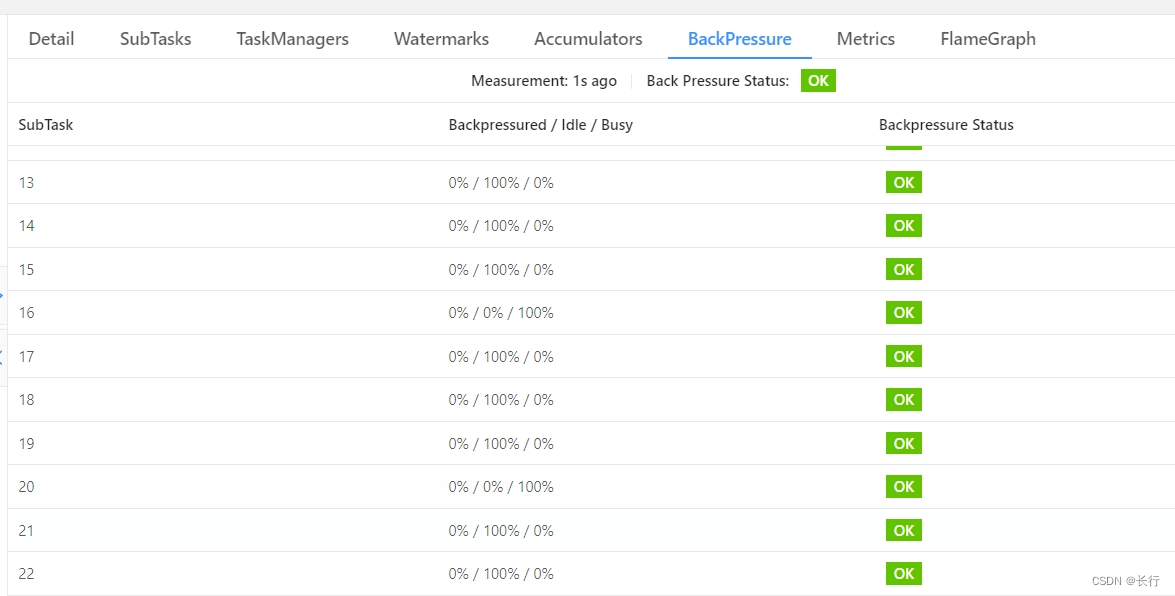
可以看到,在两次 checkpoint 中,subtask 20 均没有完成 checkpoint 的确认。
历史情况
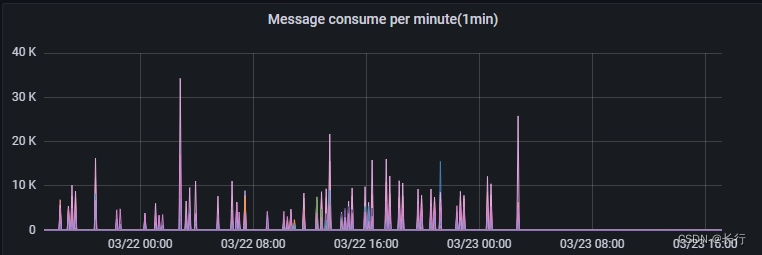
观察最近 2 天上游 Kafka TOPIC 消费情况,可以看到之前的消费也是断断续续,经常出现近一个小时无法消费的情况,也就是经常需要一个小时的时间才可以完成 checkpoint 确认。说明之前也可能也存在类似问题,只是这一次的情况更加严重导致 checkpoint 失败了。
问题定位
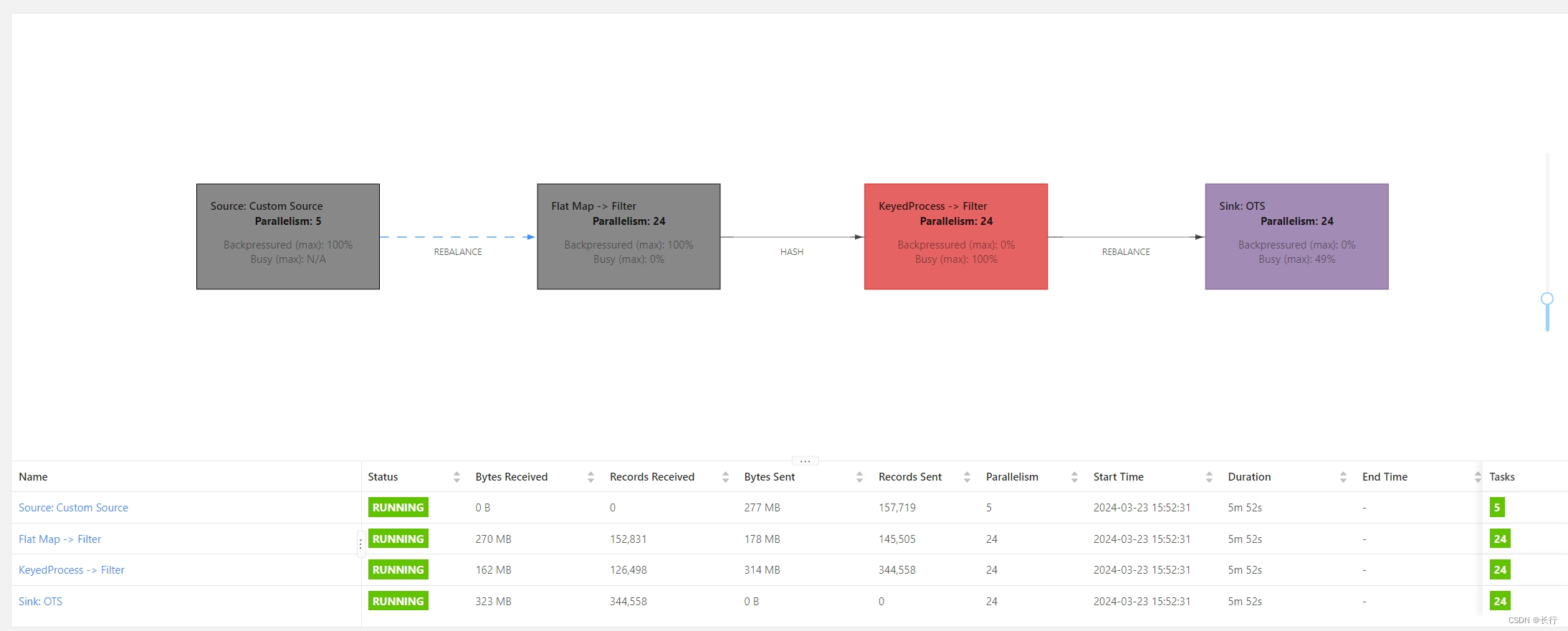
当前 DAG
当前任务 DAG 如下:
- Kafka source:当前为 5 并行度
- FlatMap > Filter:其中没有反查数据库的逻辑,运行速度较快,当前为 24 并行度
- KeyedProcess > Filter > Sink:在 KeyedProcess 中包含反查数据库的逻辑,Sink 是直接写入 OTS 的,当前为 24 并行度

可以看到,当前瓶颈是 “KeyedProcess > Filter > Sink” 算子链。
数据倾斜原因:部分记录处理更慢
重启作业,发现在 “KeyedProcess > Filter > Sink” 算子链中,SubTask 16 和 SubTask 20 明显比其他 SubTask 要慢得多,这与 Checkpoint 3739 中无法确认 checkpoint 的 SubTask 20 是一致的。
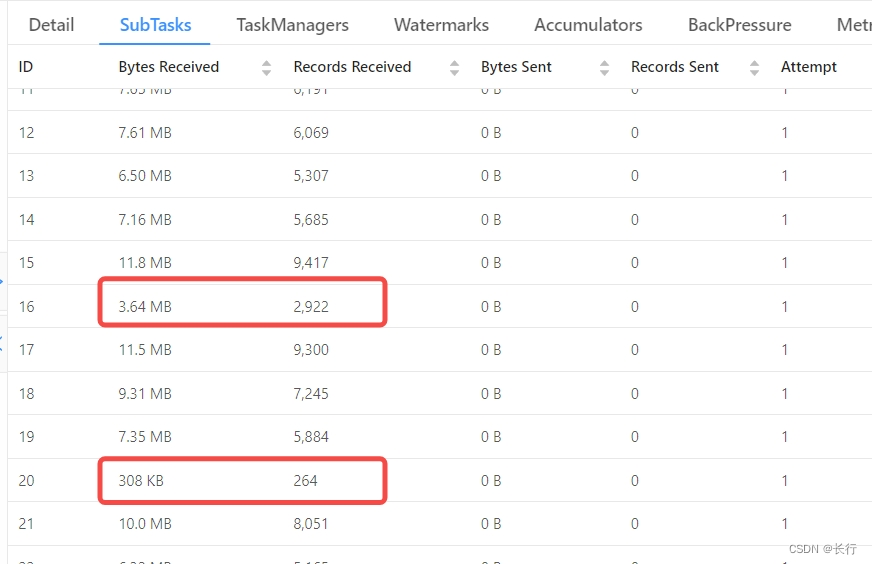
“KeyedProcess > Filter > Sink” 算子链之前是根据键 HASH 分组的。具体观察这个算子链的 SubTask,发现 SubTask 16 和 SubTask 20 实际接收到的记录数是很少的。也就是说,并不是因为它们接收到了更多的记录导致数据倾斜,而是因为它们处理记录的速度更慢导致的。
因为集群上其他 Flink 任务运行正常,所以不需要预测执行即可排除是集群中异常节点导致的性能问题。因此,基本可以断定是这两个节点接收的任务的处理速度更慢。
定位:部分上游记录会生产多条下游记录
分析代码逻辑,发现在 KeyedProcess 的处理逻辑中,有的 TOPIC 一条上游记录会生产多条下游记录,有的需要反查数据库。推测可能是 SubTask 16 和 SubTask 20 分配到了更多这些 Kafka TOPIC 的记录。
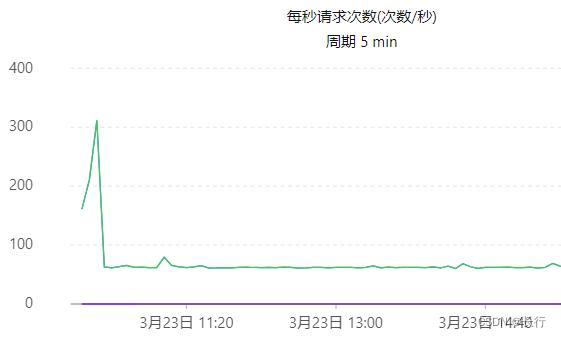
观察下游 OTS 的 PutRow 事件的监控,可以看到,除在作业刚启动时之外,写入速度非常稳定,几乎完全没有波动地维持在 70 QPS 左右。因此,推测当前瓶颈可能发生在 Sink 环节,其中部分上游记录产生了大量需要 Sink 的记录,导致这些 subtask 的 Sink 速度非常慢。
此时有如下 3 种方法:
- 使用非对齐的 checkpoint,避免 checkpoint 失败,让数据维持在倾斜的状态下继续跑。但是,非对齐的 checkpoint 是用来解决端到端时间较长,即因为处理缓冲中数据的速度过慢,导致 barrier 从 source 流动到 sink 的时间过长的;而不是用来解决数据倾斜的,使用非对齐 checkpoint 后数据倾斜仍会存在,计算效率仍然很低。
- 在当前疑似瓶颈的 sink 之前增加 rebalance,缩短数据倾斜的算子链长度
- 修改分组键的选择方法,将当前 SubTask 16 和 SubTask 20 中的处理速度更慢的记录均匀地分配给其他 SubTask
问题解决
方法 1(无效):使用非对齐 checkpoint
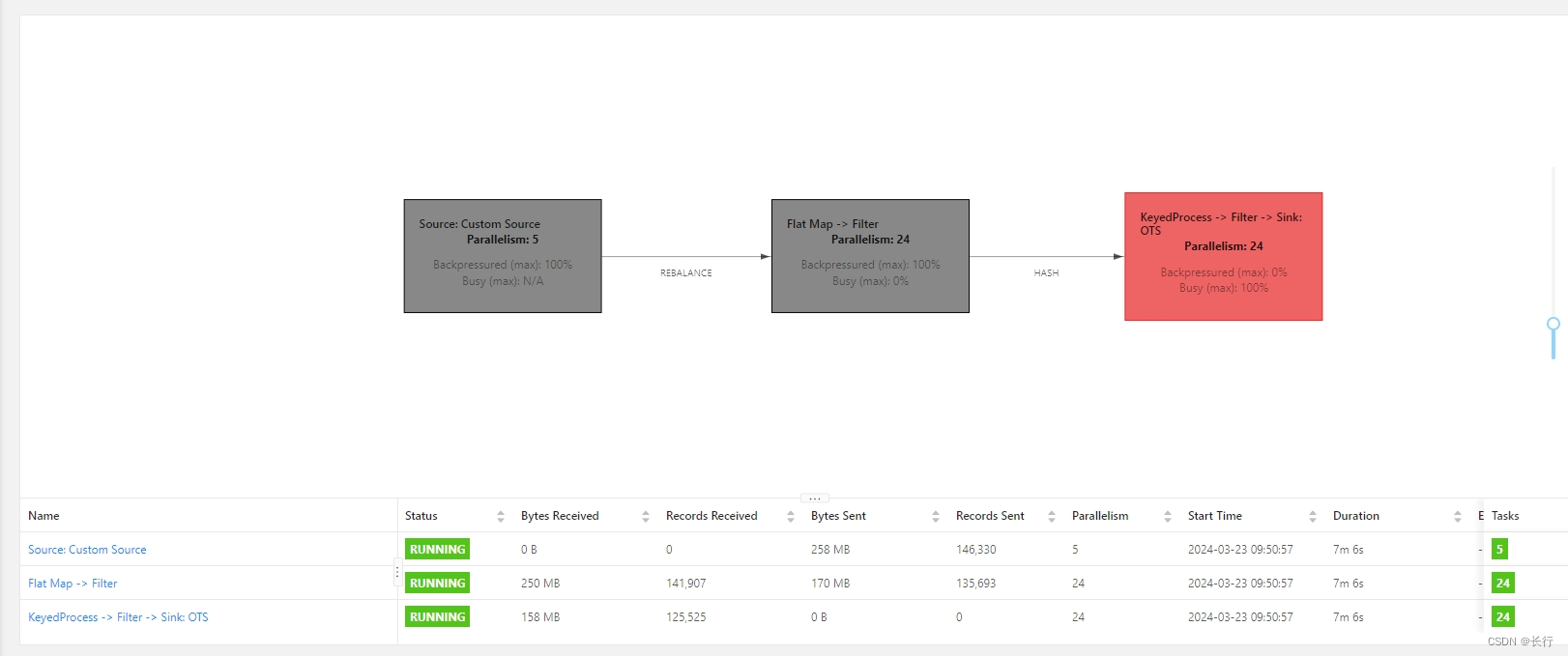
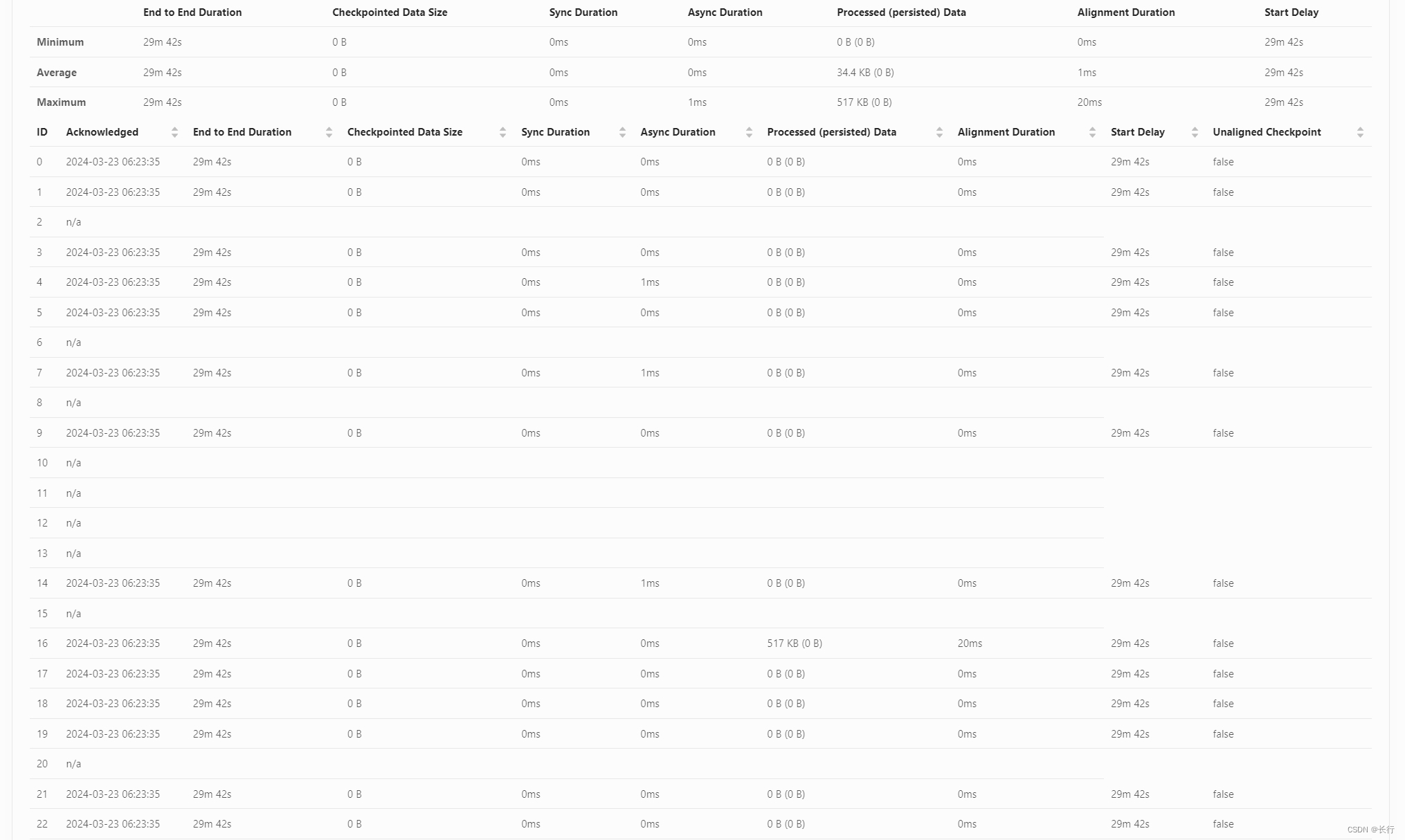
使用非对齐 checkpoint 后,checkpoint 间隔时间仍然使用 180 秒,可以成功 checkpoint 了,但是记录处理速度仍然非常慢,且 “KeyedProcess > Filter > Sink” 算子链中只有 SubTask 16 和 SubTask 18 在运行,其他 SubTask 完全空闲,资源浪费严重。
此外,如果将非对齐 checkpoint 超时时间设置为 90 秒的话,checkpoint 仍然会存在超时失败情况,说明存在处理时间超过 90 秒的记录,会导致。

方法 2(有效):在 sink 之前增加 rebalance
在处理逻辑和 sink 之前,增加了一次 rebalance。修改后的 DAG 如下图:
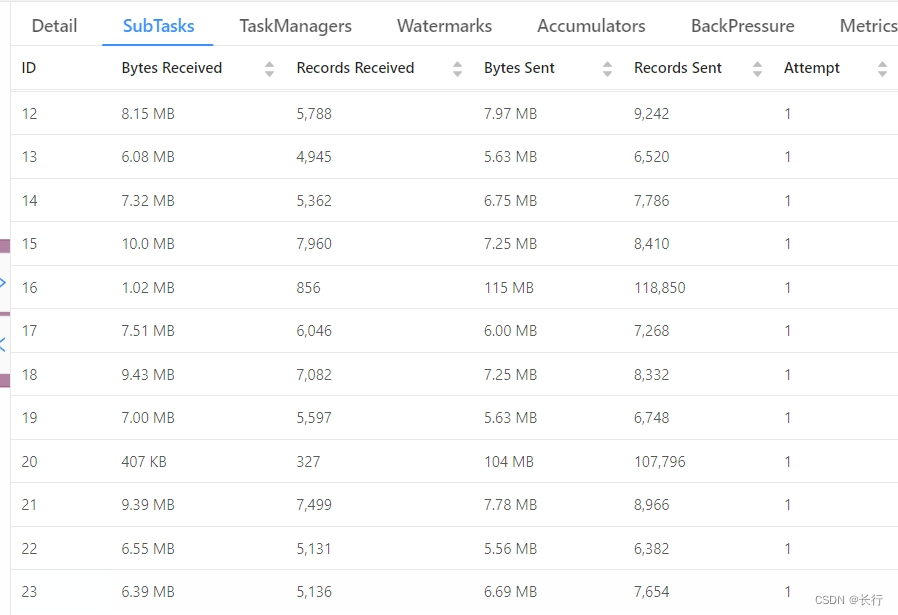
拆分后可以看到,subtask 16 和 subtask 20 的 Records Received 较低,但是 Records Sent 要明显高于其他 SubTask。它们之所以处理速度慢,就是因为有大量会产出多条下游记录的上游记录,这与之前的推断一致。
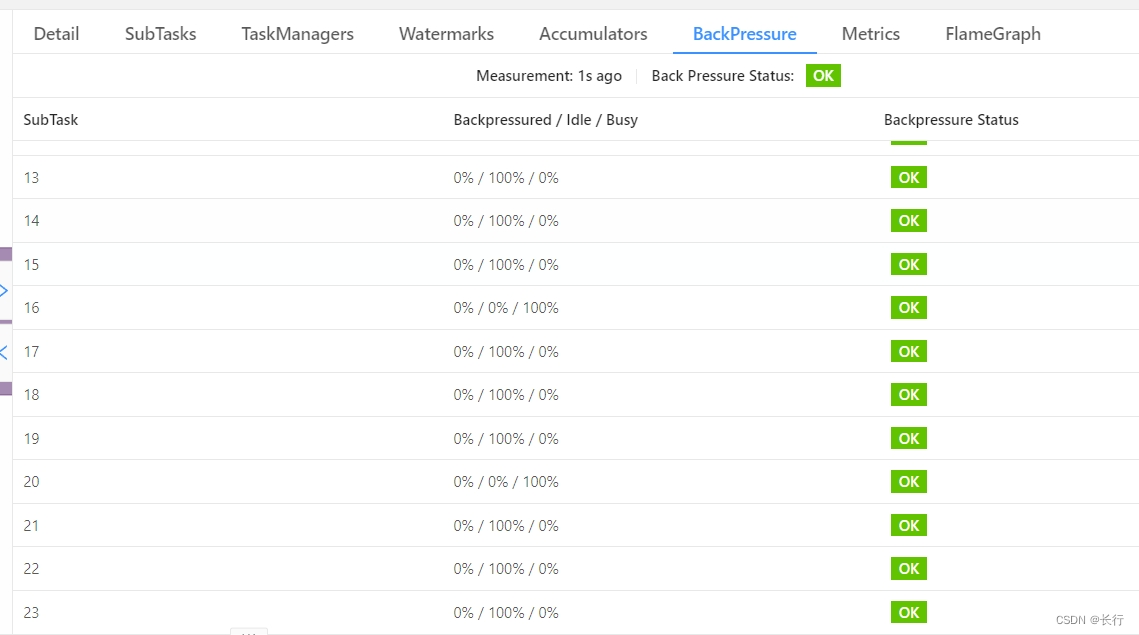
但是,Subtask 16 和 Subtask 20 仍然很慢。说明仅 “KeyedProcess > Filter” 算子链中处理这些记录的速度仍然与其他记录存在明显差距,数据倾斜仍然存在。

查看下游 OTS 监控,可以看到当只剩下 Subtask 16 和 Subtask 20 在运行时,下游吞吐量为 400 QPS 左右,是之前的 6 倍,但仍然明显低于 800 QPS 左右的峰值,说明之前推断 sink 为瓶颈是正确的。
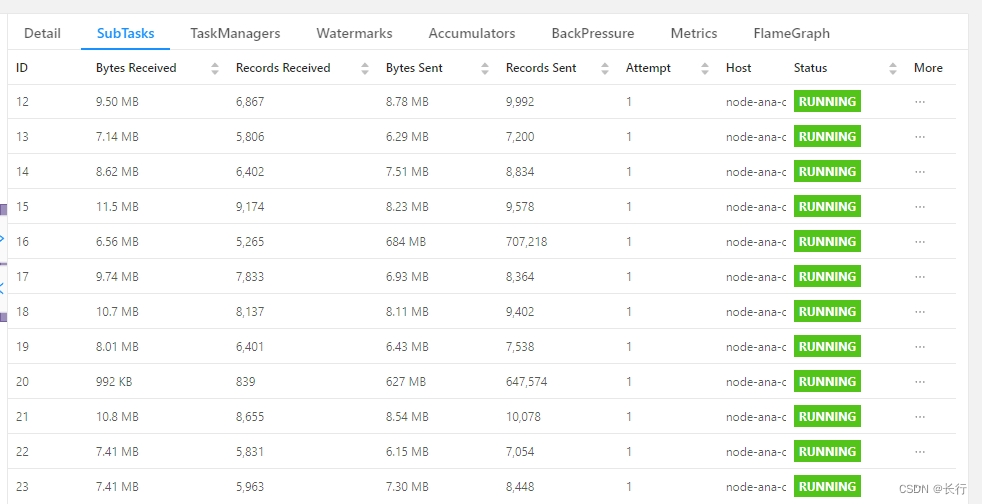
在运行 30 分钟时,各 Subtask 处理的记录数如上图,Subtask 20 仍然很难在 100 分钟的 checkpoint 超时时间中完成,且其他 SubTask 一直空闲,计算效率非常差。
分析代码逻辑,发现 Subtask 16 和 Subtask 20 的接收的部分记录,在 KeyedProcess 算子逻辑中,每产出一条下游记录都需要进行一次反查数据库,导致 KeyedProcess 环节成为当前的瓶颈。
在 KeyedProcess 处理逻辑中增加的日志,看到大部分记录的处理时间在 100 毫秒以内,但部分记录的处理时间超过了 10 秒。
方法 3(解决):将 KeyedProcess 的分组键改为更不具有共性的主键 ID
分析代码逻辑,发现当前使用上游记录的毫秒级时间戳来进行分区,之所以出现数据倾斜,可能是因为这些 Subtask 20 的记录可能是在相同时间戳更新的大量数据,例如使用同一条 update 语句更新了大量记录。
检查键控流处理逻辑,发现没有使用窗口函数,使用状态的场景中,也没有不同记录之间的相互影响。因此,推断在这里之所以进行分组,是为了使用状态,并且保证相同记录可以稳定进入相同 subtask 才这么分组的。
因此,改为使用上游 Canal 监听的 MySQL 表的主键作为分组键,从而将这些相同时间戳的记录拆分到不同Subtask 之中。修改后作业图如下:可以看到整体的瓶颈为 OTS,KeyedProcess 的 Subtask 接收、发布记录数之比变得相对均匀。
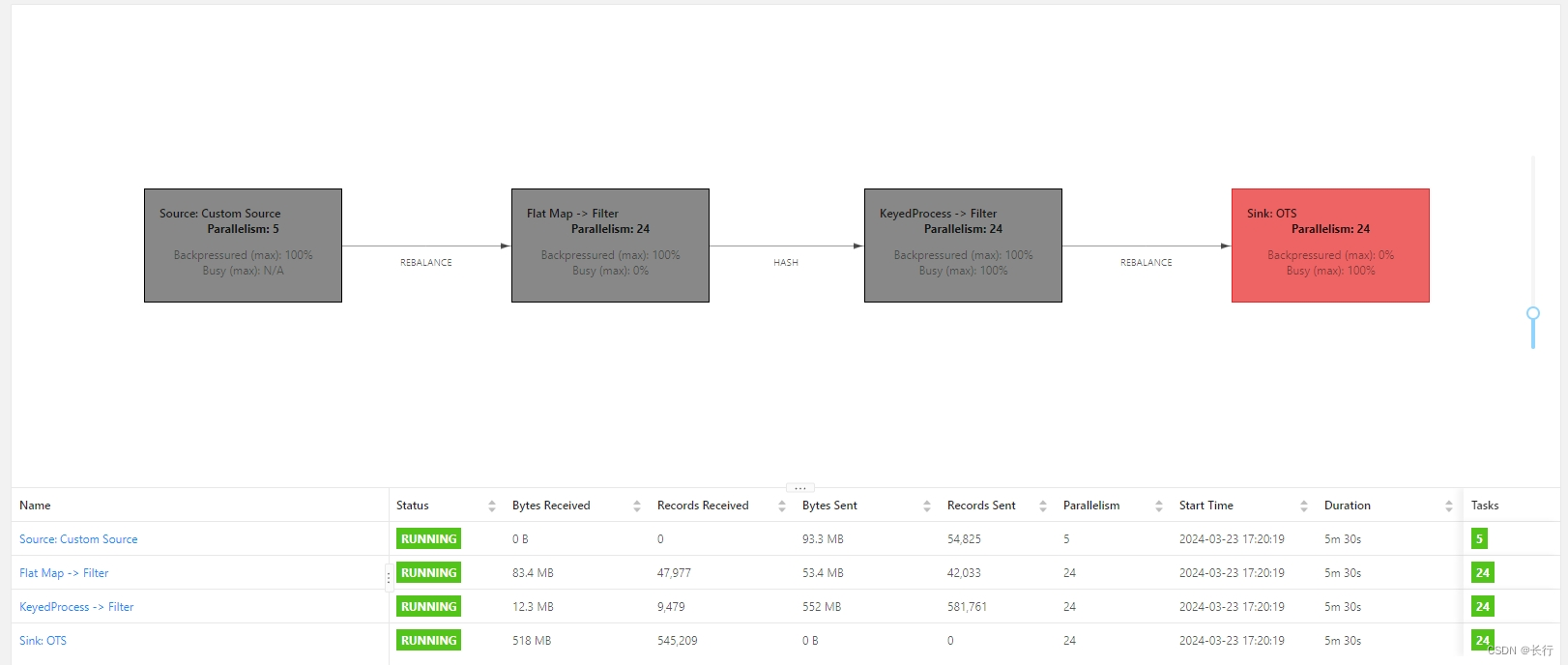
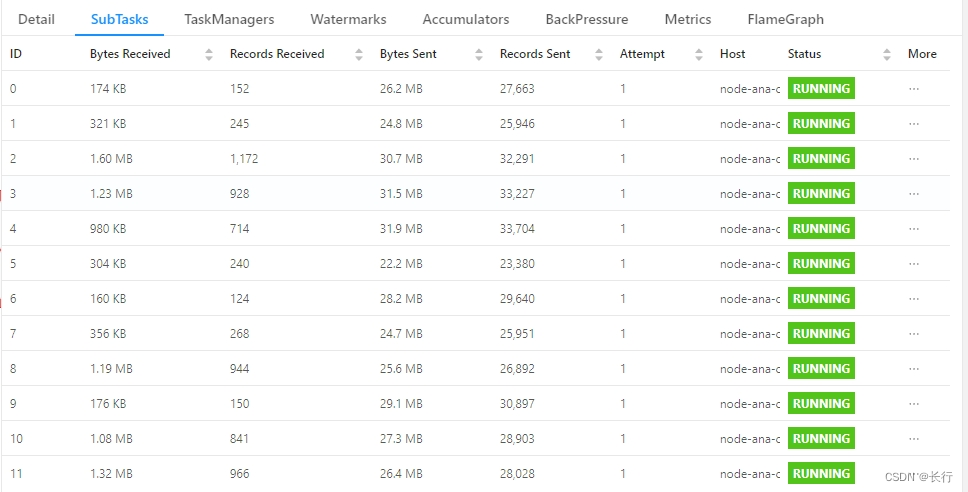
查看下游 OTS 监控,作为瓶颈的 Sink 速度一直稳定在 800 QPS 左右,已不存在因为数据倾斜导致无法到达速度 Sink 吞吐上限的问题。

同时,观察 checkpoint 的情况,因为数据倾斜被缓解,所以 checkpoint 已可以成功确认。时间 checkpoint 仍然很长,但这主要是因为 KeyedProcess 处理缓存中记录的速度仍然很慢,处理缓存数据的速度较慢,导致 barrier 从 source 移动到 sink 的时间较长。
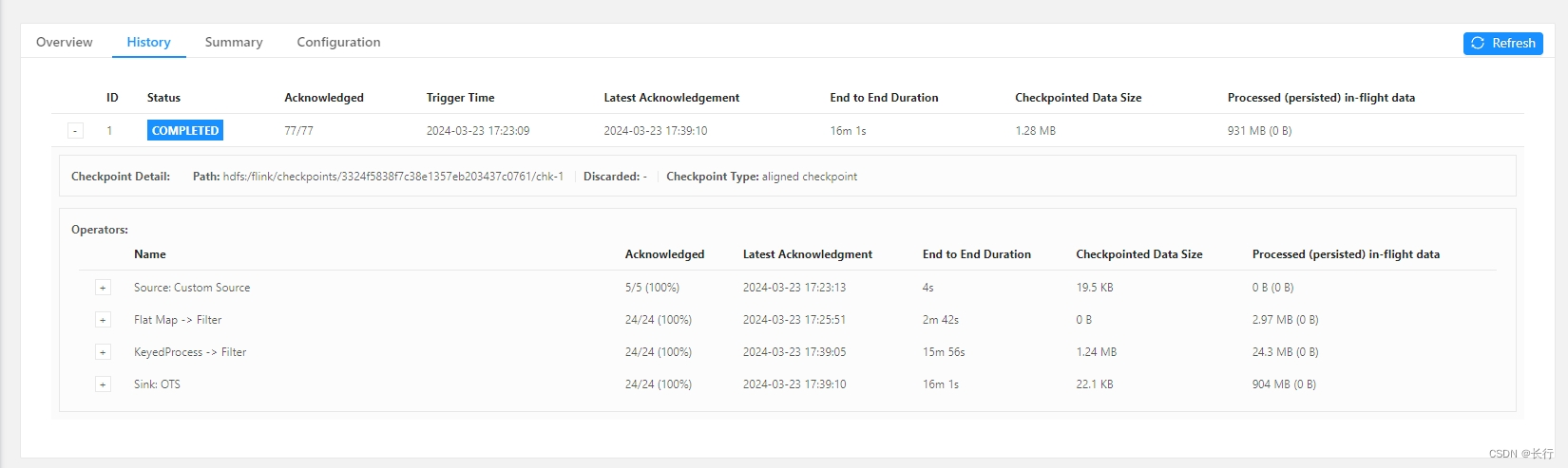
50 分钟后检查下游监控,发现 checkpoint 可以在 20 分钟内稳定完成,并基本可以保持最高速度持续写出了。
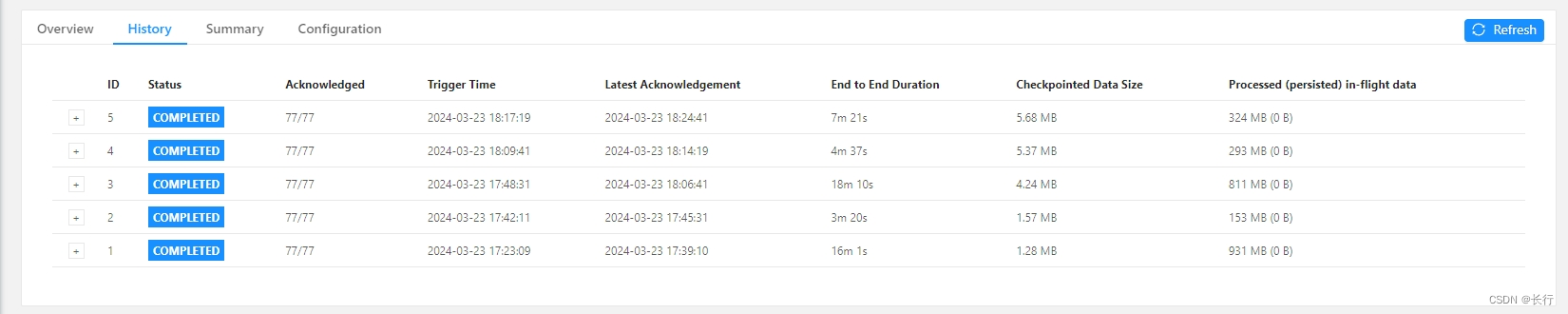
此时,数据倾斜导致 checkpoint 失败的问题已经修复。如果还需要保证 checkpoint 的时间,可以考虑使用非对齐的 checkpoint 来避免因端到端的时间导致 checkpoint 时间较长的问题。
方法 4(优化):使用非对齐 checkpoint
两天后再次观察上游 Kafka TOPIC 的积压,发现仍然会出现很长时间无法确认 checkpoint 的情况。
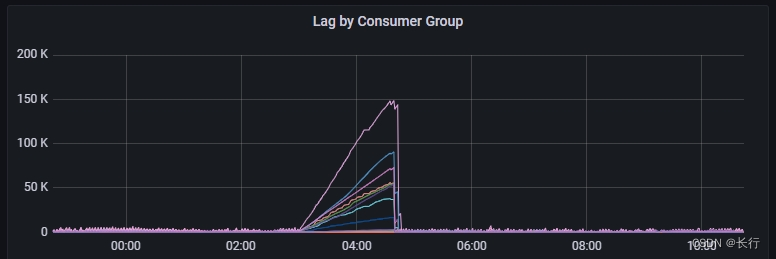
时间已过去比较久,无法查看当时的 Flink checkpoint 详情。观察 OTS 日志,发现对应时段的 OTS 写入一直维持在最大速度。
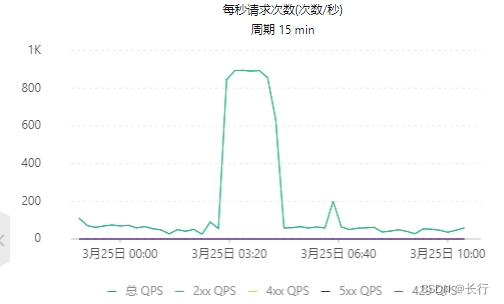
结合之前的处理,我们在 “KeyedProcess > Filter” 算子链和 Sink 之前增加了 rebalance;而根据之前的分析,我们知道每个 “KeyedProcess > Filter” 算子可以提供 200 QPS 左右的 OTS 写出速度。因此,可以推断在 checkpoint 对齐过程中的绝大多数时间,都没有出现严重的数据倾斜(即 24 个 SubTask 中至少有 5 个在运行),且没有遇到单挑记录处理时间过长的情况。
因为这个 checkpoint 的时间看起来已接近 100 分钟,存在 checkpoint 超时的风险。所以,我们考虑使用非对齐 checkpoint,来缩短 checkpoint 时间,以避免出现 checkpoint 超时。因为存在部分记录需要处理较长时间,所以我们仍保留 100 分钟的 checkpoint 最大超时时间不变。

