
- 1Sui 线下活动回顾|资管升级与技术革新,探索 Sui 生态发展新风向
- 2搭建Hadoop分布式文件系统HDFS、海量列式存储数据库HBase_海量文件管理用什么数据库
- 3mongodb 之 特殊集合及索引_mongodb特殊之处
- 4爬山法实现 八皇后问题 (Python 实现)_(五)爬山法算法通常在最佳后继的集合中随机选择一个进行扩展。给出上图最佳后继
- 5植物大战僵尸 for Mac(策略游戏)m1_植物大战僵尸for mac m1
- 6论文后面的参考文献格式应该如何写_论文尾注参考文献格式
- 7MVX-net3D算法笔记_mvx net
- 8数字钟设计Verilog代码远程云端平台Quartus_简易数字钟设计verilog
- 9microsoft store下载速度慢怎么办 微软商店游戏下载一键提速方法
- 10[C] 五、异常捕获_c中捕获异常
django可视化_django 将数值百分比显示
赞
踩
学习目标:
提示:这里可以添加学习目标
例如:
- 搞定三种可视化的图
- 搞定爬虫的三种方法
- 自己写爬取豆瓣的250数据
- 自己写三个图
学习内容:
首先,先讲一下可视化
先说条形图,条形图一定要看着excel表格去做
条形图
第一步:
一般导入的包:
- from pyecharts import options as opts
- from pyecharts.charts import Bar
- import pandas as pd
第二步:
我们要去创建一个创建一个文件夹,存储生成的html文件
- df=pd.read_excel('就excel表格的那个名字'xlwt)
- print(df)
第三步:
把excel里面的东西弄出来
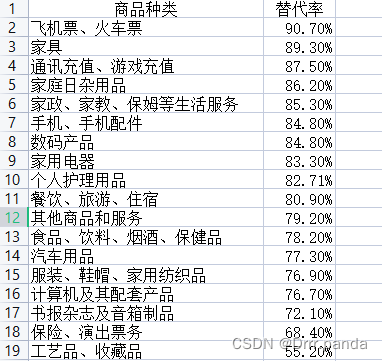
上面的商品种类和替代率要拿出来
上代码!
- zhonglei =df['商品种类']
- lv =df['替代率']*100
如果需要将数组转化成列表的话就要加tolist()
第四步:
就是固定的一个公式
- #先随便定义一个字母
-
- t =(
- Bar()
- .add_xaxis(zhonglei.tolist())
- .add_yaxis("商品名称种类",lv.tolist())
- .reversal_axis()
括号里面的“商品名称种类”就是下面右上角那种标示,然后就是后面的lv在上面的代码里面也定义了 ,也就是替代率。其他的东西就是套话,都一样
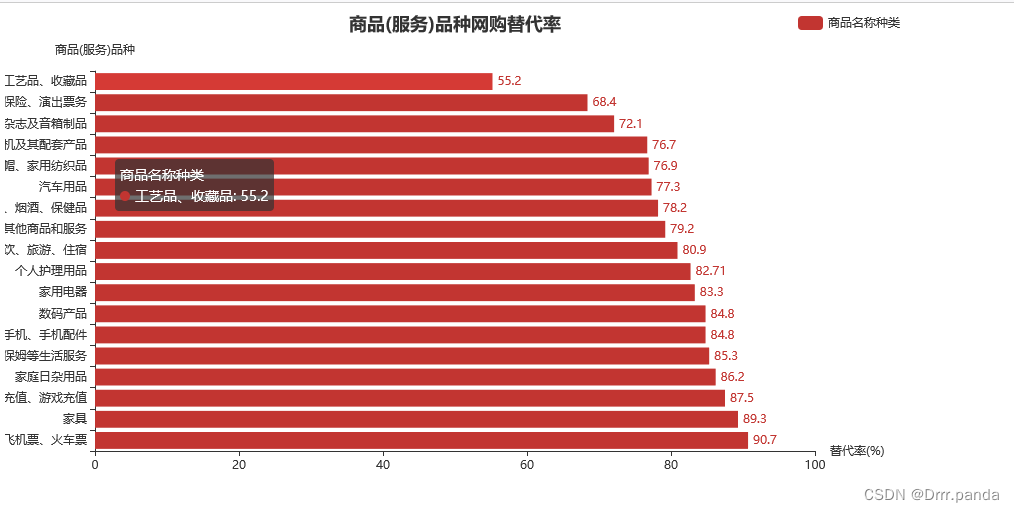
第五步:
这也是最后一步了
- .reversal_axis() #套话
- .set_series_opts(label_opts =opts.LabelOpts(position ="right"))#定义了每一行数据的百分比显示在图例的右边,如果说后面但就是数字的话可以这么写,但如果是百分数的话,就要加一个formatter="{c}%
- .set_global_opts(title_opts=opts.TitleOpts(title ="商品(服务)品种网购替代率",pos_left="center"), # 图表那个网页上面的大名字,后面的那个center是居中
- lengend_opts=opts.LegendOpts(pos_left="right"), #这个是“商品名称种类”在图例中的位置
- xaxis_optsopts.AxisOpts(name="替代率(%)"), #代表的是横轴上显示的单位
- yaxis_opts=opts.AxisOpts(name="商品(服务)品种“) #代表y轴上显示的单位
- ) #设置图列的位置
- .render("商品图.html)
- )
上面有运行的图例
先补充一点知识:
前言:formatter格式化方法。格式化之所以存在,主要是因为我们想把一些不够人性化的内容通过处理让其变成我们想要的样子,便于用户更好地理解内容。
首先ECharts官网API提供了一些formatter格式化参数模板:
1. 字符串模板
模板变量有 {a}, {b},{c},{d},{e},分别表示系列名,数据名,数据值等。 在 trigger 为'axis' 的时候,会有多个系列的数据,此时可以通过{a0}, {a1}, {a2} 这种后面加索引的方式表示系列的索引。 不同图表类型下的{a},{b},{c},{d}含义不一样。 其中变量{a}, {b}, {c}, {d}在不同图表类型下代表数据含义为:
u 折线(区域)图、柱状(条形)图、K线图: {a}(系列名称),{b}(类目值),{c}(数值), {d}(无)
u 散点图(气泡)图 : {a}(系列名称),{b}(数据名称),{c}(数值数组), {d}(无)
u 地图 : {a}(系列名称),{b}(区域名称),{c}(合并数值), {d}(无)
u 饼图、仪表盘、漏斗图: {a}(系列名称),{b}(数据项名称),{c}(数值), {d}(百分比)
下面再放一个条形图的源码和运行图:

- from pyecharts import options as opts
- from pyecharts.charts import Bar
-
- import pandas as pd
-
- df = pd.read_excel("1-3task2原始数据.xlsx")
- print(df)
-
- zl = df['商品服务种类']
- year2107 = df['2017年'] * 100
- year2108 = df['2018年'] * 100
-
- b = (
- Bar()
- .add_xaxis(zl.tolist())
- .add_yaxis("2017年", year2107.tolist())
- .add_yaxis("2018年", year2108.tolist())
- .reversal_axis()
- .set_series_opts(label_opts=opts.LabelOpts(position="right", formatter="{c}%"))
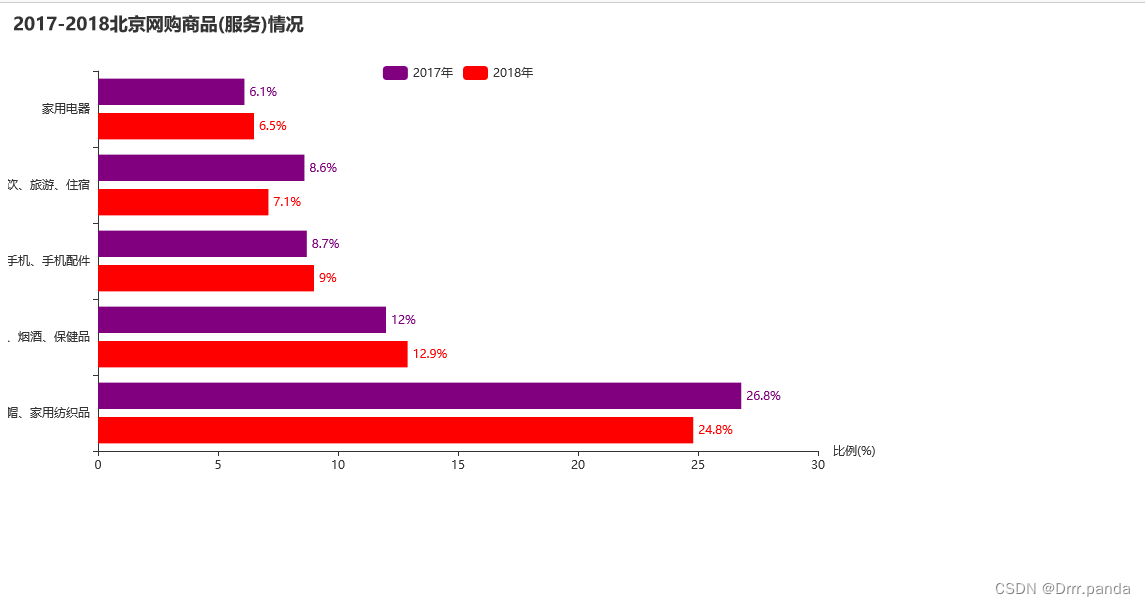
- .set_global_opts(title_opts=opts.TitleOpts(title="2017-2018北京网购商品(服务)情况"),
- legend_opts=opts.LegendOpts(pos_left="center", pos_top="10%"),
- xaxis_opts=opts.AxisOpts(name="比例(%)")
- )
- .set_colors(["purple", "red"]) #这里定义的是条形图两条的颜色
- .render("2017-2018北京网购商品(服务)情况.html")
- )

这里面的formatter={c}%意思是数值类,也就是如果是每条后面要跟着百分比的话就要加这个
再放一个:
- from pyecharts import options as opts
- from pyecharts.charts import Bar, Grid
- import pandas as pd
-
- df = pd.read_excel('1-7task1原始数据.xlsx')
- # print(df)
-
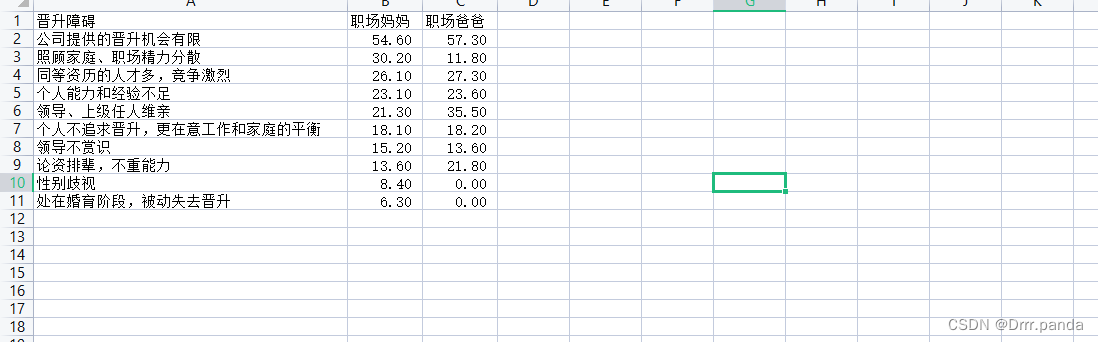
- x = df['晋升障碍'].tolist()
- mother = df['职场妈妈'].tolist()
- father = df['职场爸爸'].tolist()
- print(x, mother, father)
-
- bar = (
- Bar()
- .add_xaxis(x)
- .add_yaxis("职场妈妈", mother)
- .add_yaxis("职场爸爸", father)
- .reversal_axis()
- .set_series_opts(label_opts=opts.LabelOpts(formatter="{c}%", position="right"))
- .set_global_opts(title_opts=opts.TitleOpts(title="职场两性晋升障碍"), xaxis_opts=opts.AxisOpts(name="比例(%)"))
-
- )
-
- g = (
- Grid()
- .add(bar, grid_opts=opts.GridOpts(pos_left="30%"), is_control_axis_index=True)
- .render("题一条形图(职场两性晋升障碍)1.html")
- )
grid指的是表格的意思,就是指下面那个条形图 然后前面一直到pos_left="30%"指的是条形图和左边的距离以及自己的大小,如果改成10%,那么左边的字就会挤到边框里面去一部分,但是图例会变得更大,然后后面的is_control_axis_index=True不知道什么意思,改成false或者删掉都没有什么影响,这里就建议先不用写

条形图就先写到这了,后面讲一下折线图
折线图

第一步还是导入模块:
- from pyecharts import options as opts
- from pyecharts.charts import Line
- import pandas as pd
第二步:
然后引入excel表格的内容
- df = pd.read_excel('1-1task2原始数据.xlsx')
- print(df)
第三步:
把excel表格里面的东西编排一下
- number = df['月均网购次数']
- boy = df['男性'] * 100
- gril = df['女性'] * 100
大家就会发现,上面的三个步骤和条形图的基本完全一样
第四步:
- l = (
- Line()
- .add_xaxis(number.tolist())
- .add_yaxis("男性", boy.tolist())
- .add_yaxis("女性", gril.tolist())
- .set_global_opts(title_opts=opts.TitleOpts(title="2018年浙江网购男性与女性月均网购次数比列", pos_left="center"), #显示大标题以及居中
- legend_opts=opts.LegendOpts(pos_left="center", pos_top="10%"), #这一行是男性和女性那两个标示图表的位置
- yaxis_opts=opts.AxisOpts(name="占比(%)", min_=18), #这一行是标明Y轴上面的标识是占比(%),min_是占比那个线的大小
- )
- .render('网购次数比列.html')
- )
运行结果:
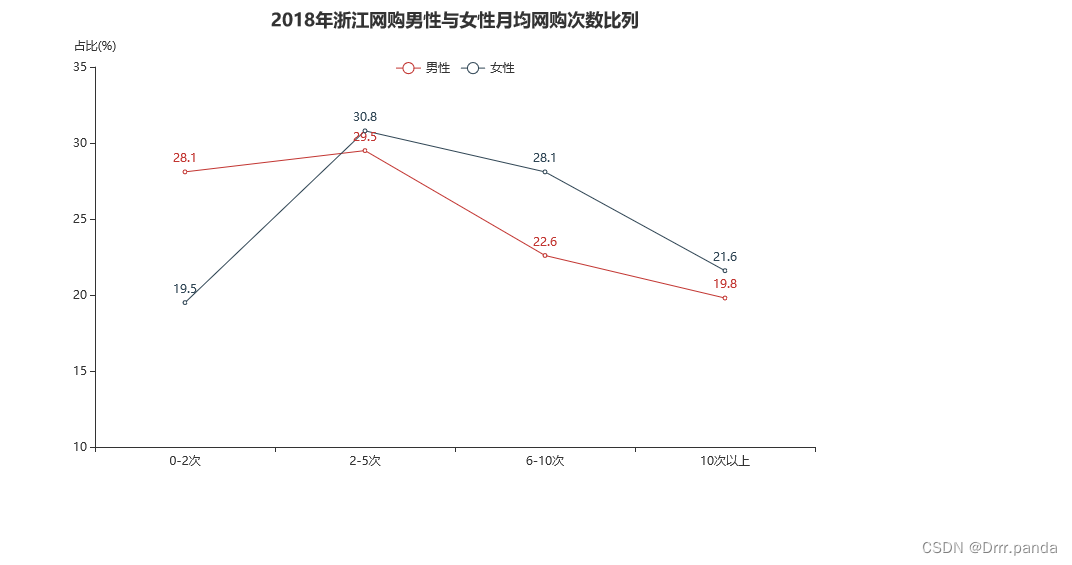
再来一个:
- from pyecharts import options as opts
- from pyecharts.charts import Line
-
- import pandas as pd
-
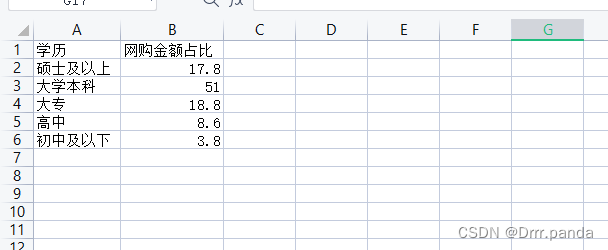
- df = pd.read_excel("1-2task1原始数据.xlsx")
- print(df)
-
- xueli = df['学历'].tolist()
- zhanbi = df['网购金额占比']
- print(xueli)
-
- l = (
- Line()
- .add_xaxis(xueli)
- .add_yaxis("网购金额占比", zhanbi.tolist())
- .set_global_opts(title_opts=opts.TitleOpts(title="2018年北京网购不同学历用户购买金额", pos_left="center"),
- legend_opts=opts.LegendOpts(pos_left="center", pos_top="10%"),
- yaxis_opts=opts.AxisOpts(name="比列(%)"),
- xaxis_opts=opts.AxisOpts(name="学历")
- )
- .render('2018年北京网购不同学历用户购买金额.html')
- )
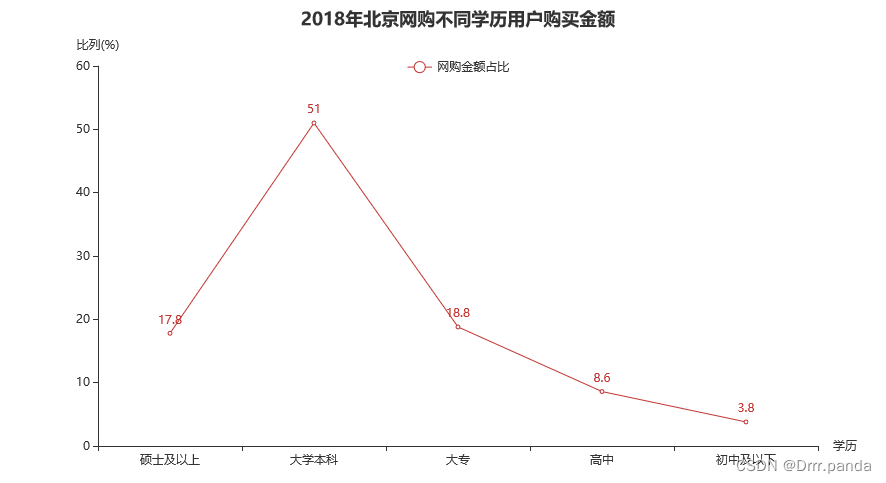
再来一个:
- from pyecharts import options as opts
- from pyecharts.charts import Line
-
- import pandas as pd
-
- df = pd.read_excel("1-4task2原始数据.xlsx")
- print(df)
-
- pp = df["品牌"].tolist()
- sales = df["销售指数"].tolist()
- print(pp, sales)
-
- l = (
- Line()
- .add_xaxis(pp)
- .add_yaxis("销售指数", sales)
- .set_global_opts(title_opts=opts.TitleOpts(title="2018年3C数码类品牌双十一电商销售指数排名", pos_left="center"),
- legend_opts=opts.LegendOpts(pos_left="center", pos_top="10%"),
- xaxis_opts=opts.AxisOpts(name="品牌"),
- yaxis_opts=opts.AxisOpts(name="销售指数", min_=84)
-
- )
- .render("2018年3C数码类品牌双十一电商销售指数排名.html")
-
- )
下面这个"-o-销售指数"这个玩意加一个 legend_opts=opts.LegendOpts(pos_left="center", pos_top="10%"),就有了,加不加都可以


再来一个:

- import pandas as pd
- from pyecharts.charts import Line
- from pyecharts import options as opts
- from pyecharts.commons.utils import JsCode
-
- df = pd.read_excel('1-6task3原始数据.xlsx')
- print(df)
-
- status = df["婚育状态"].tolist()
- money = (df["实现财务自由"] * 100).tolist()
- wending = (df["职业趋稳定、侧重家庭"] * 100).tolist()
- cy = (df["退出职场去创业"] * 100).tolist()
- print(status, money, wending, cy)
-
- line = (
- Line()
- .add_xaxis(status)
- .add_yaxis("实现财务自由", money)
- .add_yaxis("职业趋稳定、侧重家庭", wending)
- .add_yaxis("退出职场去创业", cy)
- .set_global_opts(
- title_opts=opts.TitleOpts(title="不同婚育状态女性未来三年的职业规划", pos_left="center"),
- yaxis_opts=opts.AxisOpts(name="%"),
- legend_opts=opts.LegendOpts(is_show=False)
- )
- .render("题三(折线图).html")
- )
这其中的legend_opts=opts.LegendOpts(is_show=False) 就是不显示每个线的标志
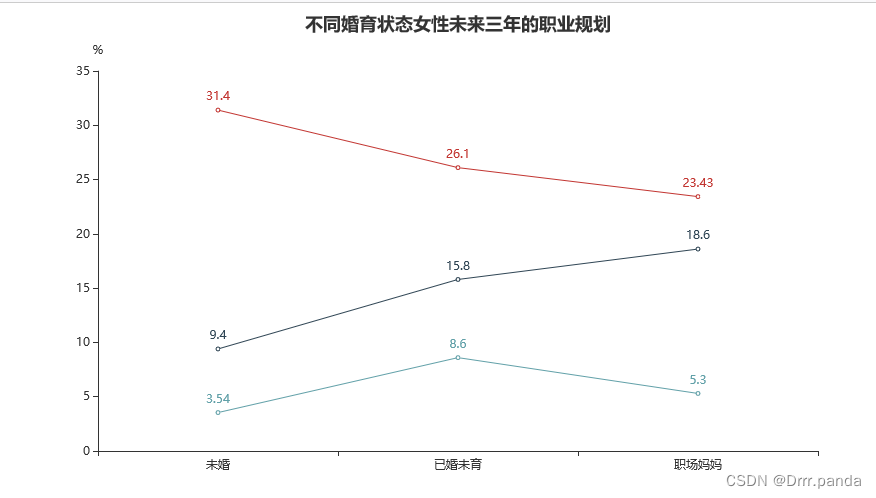
再来一个:
- from pyecharts import options as opts
- from pyecharts.charts import Line
- import pandas as pd
-
- df = pd.read_excel('1-7task3原始数据.xlsx')
- # print(df)
- shi = df['事项'].tolist()
- mother = df['职场妈妈'].tolist()
- father = df["职场爸爸"].tolist()
-
- print(shi, mother, father)
-
- line = (
- Line()
- .add_xaxis(shi)
- .add_yaxis("职场妈妈", mother)
- .add_yaxis("职场爸爸", father)
- .set_global_opts(title_opts=opts.TitleOpts(title="职场人的收入分配", pos_left="center"),
- yaxis_opts=opts.AxisOpts(name="占比(%)"), legend_opts=opts.LegendOpts(is_show=False)
- )
- .render("题三折线图(职场人的收入分配).html")
-
- )
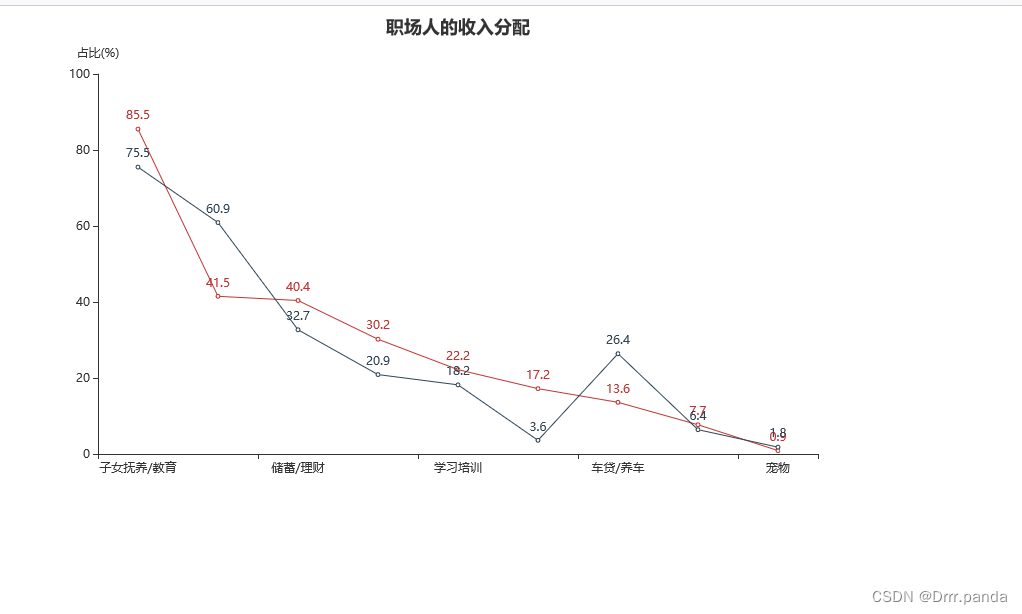

堆积图:
第一步:
老规矩,导入包
- from pyecharts import options as opts
- from pyecharts.charts import Bar
- import pandas as pd
第二步:
导入excel表格
df = pd.read_excel("1-2task2原始数据.xlsx")第三步:
- fenlei = df['商品分类']
- coutry = df['农村居民'] * 100
- city = df['城镇居民'] * 100
- print(fenlei)
第四步:
- b = (
- Bar()
- .add_xaxis(fenlei.tolist())
- .add_yaxis("农村居民", coutry.tolist(), stack="stack1")
- .add_yaxis("城镇居民", city.tolist(), stack="stack1")
- .set_series_opts(label_opts=opts.LabelOpts(position="right", formatter="{c}%"))
- .set_global_opts(
- title_opts=opts.TitleOpts(title="农村与城镇居民商品种类购买情况", pos_left="left"),
- legend_opts=opts.LegendOpts(pos_left="center")
- )
- .render("农村与城镇居民商品种类购买情况.html")
- )


再来一个:
- import pandas as pd
- from pyecharts.charts import Line, Bar
- from pyecharts import options as opts
- from pyecharts.commons.utils import JsCode
-
- df = pd.read_excel('1-6task1原始数据.xlsx')
- print(df)
- status = df["婚育状态"].tolist()
- peoper = (df["陪伴家人"] * 100).tolist()
- student = (df["充电学习"] * 100).tolist()
- game = (df["休息娱乐"] * 100).tolist()
-
- print(status, peoper, student, game)
-
- bar = (
- Bar()
- .add_xaxis(student)
- .add_yaxis("陪伴家人", peoper, stack="stack1", color="grey")
- .add_yaxis("充电学习", student, stack="stack1", color="red")
- .add_yaxis("休息娱乐", game, stack="stack1", category_gap="50%", color="green")
- .set_series_opts(
- label_opts=opts.LabelOpts(position="right", formatter="{c}%")
-
- )
- .set_global_opts(title_opts=opts.TitleOpts(title="不同婚育状态女性的业余时间分配"))
- .render("题一(堆积图).html")
- )
这里面有一个category_gap="50%",这个表示柱状图的宽度,区别不大,但是还是给一个比较好,里面只要包含一个,所有的柱子都会统一宽度
然后这个里面的stack="stack1“表达的就是堆积,如果不用这个的话就会变成下面这样


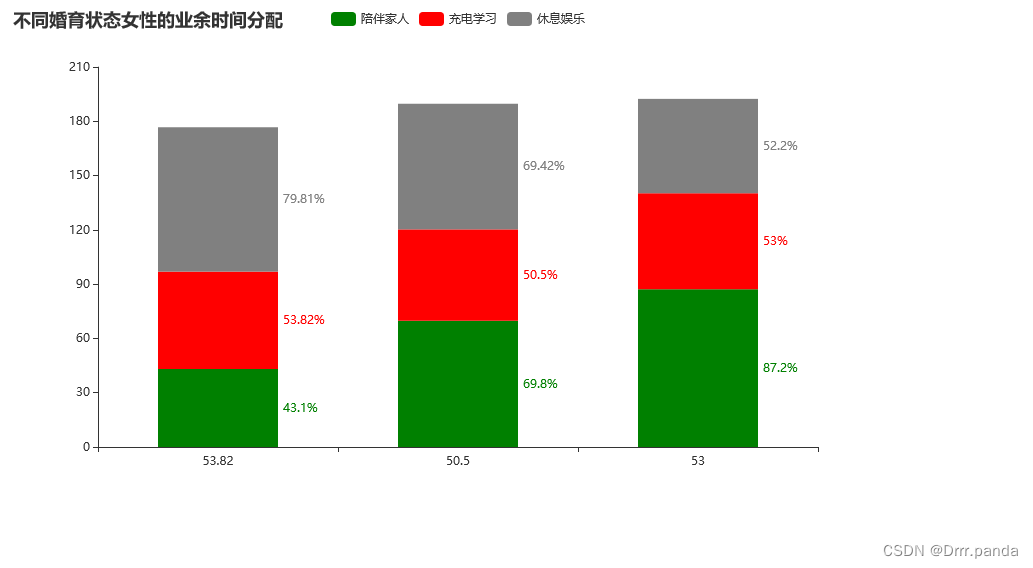
饼图:
第一步
还还还还还是老规矩
先导入包
- from pyecharts import options as opts
- from pyecharts.charts import Pie
- import pandas as pd
- import numpy as np
第二步
然后就是导入excel表格
- df = pd.read_excel('1-1task3原始数据.xlsx')
- print(df)
第三步
- yy = df['选择网购的主要原因']
- lv = (df['认同率'] * 100).tolist()
-
- print(yy, lv)
- data = [list(z) for z in zip(yy, lv)] #这一句是饼状图必备
这个z是元组类型,反正按照这么写就完事了
- p = (
- Pie()
- .add("",
- data_pair=data,
- radius="55%", # 饼状图的大小
- center=["50%", "50%"] # 前面的那个是在屏幕左右的位置,后面的是在屏幕上下的位置
- )
- .set_global_opts(title_opts=opts.TitleOpts(title="选择网购的主要原因认同率", pos_left="center"),
- legend_opts=opts.LegendOpts(pos_left="center", pos_top="90%")) # pos_top=90% 就是那个注释图表的上下位置,越小就越高
- .set_series_opts(label_opts=opts.LabelOpts(position="right", formatter="{c}%"))
-
- .render("选择网购的主要原因认同率.html")
- )


还有一个点,我们画出来的饼状图上面显示的数据相加不是百分之一百很正常,因为里面有些多选的存在,所以只要大小对的上就行,别出现%50比%10还小就行
再来一个
- import pandas as pd
-
- df = pd.read_excel("1-3task3原始数据.xlsx")
- print(df)
-
- wenti = df['问题']
- zb = df['占比']
-
- p = (
- Pie()
- .add(
- "来源",
- data_pair=[list(z) for z in zip(wenti, zb)],
- radius="55%"
-
- )
- .set_series_opts(label_opts=opts.LabelOpts(position="right", formatter="{c}%"))
- .set_global_opts(title_opts=opts.TitleOpts(title="用户对网购最不满意的方面", pos_left="center"),
- legend_opts=opts.LegendOpts(pos_left="center", pos_top="90%")
- )
- .render("用户对网购最不满意的方面.html")
- )


再来一个
- from pyecharts import options as opts
- from pyecharts.charts import Pie
- import pandas as pd
-
- df = pd.read_excel("1-5task2原始数据.xlsx")
- print(df)
-
- pt = df["平台"].tolist()
- sales = df["销售额占比"].tolist()
- print(pt)
- print(sales)
- pie = (
- Pie()
- .add(
- "来源",
- data_pair=[list(z) for z in zip(pt, sales)], # 使用zip函数将二者进行组合 将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
- radius="55%" # 设置大小
-
- )
- .set_series_opts(label_opts=opts.LabelOpts(position="right", formatter="{c}%"))
- # 配置全局配置
- .set_global_opts(
- title_opts=opts.TitleOpts(title="2018年双十一各平台销售额占比", pos_left="center"),
- legend_opts=opts.LegendOpts(pos_left="center", pos_top="85%")
- )
- .set_colors(["purple", "green", "yellow", "red", "black"])
- .render("2018年双十一各平台销售额占比.html")
-
- )

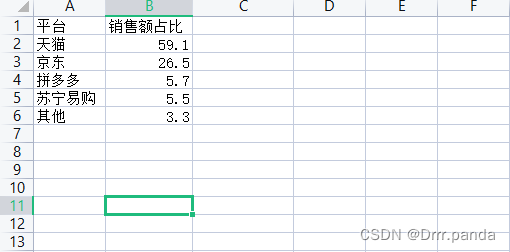
再来一个
- import pandas as pd
- from pyecharts.charts import Pie
- from pyecharts import options as opts
- from pyecharts.commons.utils import JsCode
-
- df = pd.read_excel('1-6task2原始数据.xlsx')
- print(df)
-
- status = df["婚育状态"].tolist()
- zhangbi = (df["晋升占比"] * 100).tolist()
- data_pair = [list(z) for z in zip(status, zhangbi)]
- print(status, zhangbi)
- data_pair.sort(key=lambda x: x[1])
-
- pie = (
- Pie()
- .add(
- series_name="访问来源",
- data_pair=data_pair,
- rosetype="radius",
- radius="55%",
- center=["50%", "50%"],
- label_opts=opts.LabelOpts(is_show=False, position="center")
- )
- .set_global_opts(
- title_opts=opts.TitleOpts(title="不同婚育状态女性认为未来一年有可能晋升的占比", pos_left="center"),
- legend_opts=opts.LegendOpts(is_show=False)
- )
- .set_series_opts(
- label_opts=opts.LabelOpts(position="right", formatter="{b}({c}%){d}%")
- )
- .render("题二(饼图).html")
- )


环形图
第一步
导入库
- from pyecharts import options as opts
- from pyecharts.charts import Pie
-
- import pandas as pd
第二步
- df = pd.read_excel("1-2task3原始数据.xlsx")
- print(df)
第三步
导入excel表格
- age = df['年龄']
- user = df['网购用户']
第四步
- p = (
- Pie()
- .add(
- series_name="来源",
- data_pair=[list(z) for z in zip(age, user)],
- radius=["50%", "70%"],
- )
series_name="来源",这一句看下图就有了
第五步
- .set_series_opts(label_opts=opts.LabelOpts(position="right", formatter="{c}%"))
- .set_global_opts(title_opts=opts.TitleOpts(title="不同年龄与性别网购用户分布", pos_left='center'),
- legend_opts=opts.LegendOpts(pos_left="center", pos_top="90%"))
- .render("不同年龄与性别网购用户分布.html")


