
- 1传输门、D 锁存器、D触发器、建立时间与保持时间_传输门dff
- 2智能语音技术助力金融客服提效降本
- 3【AI虚拟试衣】_ai试衣
- 4多模态AnyGPT——整合图像、语音和文本多模态大规模语言模型算法原理与实践_语音文字多模态模型
- 5sql server 2008 忘记sa密码的解决方法_sqlserver2008sa密码忘记无法设置主体的凭据
- 6R11020Z-10高效智能模块:引领未来科技新潮流
- 7springboot深入实践-2.4Neo4j数据库详解_spring-data-neo4j relation
- 8covariance 公式_酒店人常用的计算公式,果断收藏了!
- 9VLAN简单配置_vlan配置
- 10Android Studio 国内镜像代理设置(如果设置之后还是远程仓库下载失败,请仔细阅读其内容就可以解决了)_mirrors.neusoft.edu.cn
海洋渔业中的YOLOv5与YOLOv8:平衡类检测和实例计数 (YOLOv5与YOLOv8对比)_yolov8和yolov5性能对
赞
踩
目录
0.摘要
本文对YOLOv5和YOLOv8对青蒿、囊肿和粪便三种 不同类别的目标检测进行了比较研究。在本对比研究中,我们从 准确率、精密度、召回率等方面分析了这些模型的性能,其中 YOLOv5在检测青蒿和囊肿方面往往表现更好,具有出色的精确 度和准确性。然而,当涉及到检测粪便时,YOLOv5面临着明显 的挑战和限制。这表明YOLOv8在检测任务中提供了更大的通用 性和适应性,而YOLOv5可能在困难的情况下挣扎,可能需要进 一步的微调或专门的培训来提高其性能。研究结果揭示了 YOLOv5和YOLOv8在具有挑战性的海洋环境中探测物体的适用 性,并对生态研究等应用产生了影响。
1.介绍
目标检测技术成为渔业管理和研究的有力工具,实现了目 标的自动识别和跟踪。本研究重点对YOLOv5和YOLOv8两种前 沿目标检测模型进行对比分析。我们分析了它们在水生环境中 检测三种重要物体的性能:活蒿草(小型浮游动物)、囊肿和粪便。 这些对象的准确检测对于各种渔业相关任务至关重要,因为它 有助于我们了解生态系统动态,评估鱼类健康,并优化水产养 殖操作。
我们设计了一个实验装置和程序来进行这项研究。这种设 置对于蒿草(盐水虾)在受控环境中的自由运动至关重要。
蒿因其高营养含量被广泛用作海洋渔业的活饲料。它们的营养 密度高,易于培养,是喂养小嘴巴海洋幼虫的宝贵资源。这种 对海洋生物发育和生长的贡献使蒿在水产养殖中必不可少。蒿 草的小尺寸,快速运动和可变方向对目标检测构成了独特的挑 战,这使它们成为评估YOLOv5和YOLOv8在动态渔业环境中的 能力的理想测试对象。我们的数据集是在各种纳米颗粒饱和盐 水样品中蒿草囊肿孵化过程中获得的。由于纳米颗粒是荧光的, 因此通过显微图像采样捕获了摄取。 由于显微镜的局限性,在具有挑战性的环境中捕获纳米颗 粒的摄取面临着一系列常见的挑战。显微镜中一个众所周知的 问题是,在这些具有挑战性的场景中捕捉到的图像往往是失焦 和模糊的。在研究微流体系统中的纳米颗粒摄取时,这些挑战 尤其常见,微流体系统中处理的是小型和动态的对象。然而, 显微镜方法对于小尺度微流体研究仍然具有优势。 在先前的研究[1]中,研究人员已经表明,微流体环境中的 不同成分,如蒿草、囊肿和排泄物,为了解这些生物的代谢过 程提供了有价值的见解。这种微流体平台提供了对微环境的高 水平控制,并使直接观察形态变化成为可能。它可以帮助研究 人员监测和区分蒿草孵化过程的各个阶段。通过将蒿草置于不同 的温度和盐度下,显著改变了其孵化的持续时间观察到的阶段、代谢率和孵化率。例如,发现较高的温度 和中等盐度显著增强休眠蒿囊的代谢恢复。这说明了环境 因素在影响代谢活动中发挥的关键作用。 目标检测模型,如YOLO (You Only Look Once),凭借 其实时能力和具有竞争力的准确性,在推进计算机视觉领 域发挥了重要作用。虽然YOLOv5是更优化的版本,但 YOLOv8进一步完善了架构,旨在提高准确性和速度。通 过使用这种实验设置进行比较研究,我们旨在为这些模型 的表现及其对渔业管理的适用性提供实用的见解。
2.该研究的方法论
在这项实验研究中,研究人员在各种饱和纳米颗粒的 盐水样品中对阿耳特米亚进行了成像。这一过程包括在显 微镜下捕捉nauplii的图像。阿耳特米亚在一些样品中自由 移动,而其他样品则被选择用于固定样品捕获。
3.数据集
一项研究[2]引入了一种新的多任务模型,该模型将 YOLOv5架构与语义分割头相结合,用于实时鱼类检测和 分割。在golden crucian carp数据集上进行的实验展示了95. 4%的目标检测精度和98.5%的语义分割精度。该模型在 PASCAL VOC 2007数据集上也表现出了具有竞争力的性能, 实现了73.8%的目标检测精度和84.3%的语义分割精度。该 模型以惊人的速度工作,在RTX3060上实现了116.6 FPS和 120 FPS的处理速率。由于增加了一个分段头,YOLOv5的 功能得到了增强。该研究遵循了精确的方法论,包括模型 验证、选择、消融实验和优化,并将其结果与其他模型进 行了比较。
本研究中使用的数据集由1000张图像组成,其中800张 用于训练,200张用于验证。为了优化计算效率和节省计算 资源,所有图像都进行了格式转换。这些原本是TIF格式的 图片,被转换成了PNG格式。这种转换起到了双重作用:在 提高计算效率的同时,显著降低了图像大小。 通过切换到PNG格式,数据集变得清晰可见,更易于 管理,而不会影响图像的质量。此外,为了方便使用 YOLO进行模型训练并优化计算效率,所有图像的大小都 从原来的2048x2044尺寸调整为a 标准化尺寸为640x640像素。这种大小调整确保了整个数 据集的均匀性,同时减少了计算开销。 当图像被调整为640x640像素的标准尺寸时,图像中 的nauplii与原始的较大尺寸的图像相比,在像素尺寸方面 变得更小,这可能会影响nauplii的测量速度(以每帧像素 计算)。这意味着,同样的物理运动的nauplius在调整尺寸 的图像中对应的像素比原始图像中对应的像素要少。因此, 以每帧像素为单位的计算速度可能会人为地显得很高。因 此,必须考虑具体的尺度因子和像素值相对于现实世界实 例和距离的潜在差异。
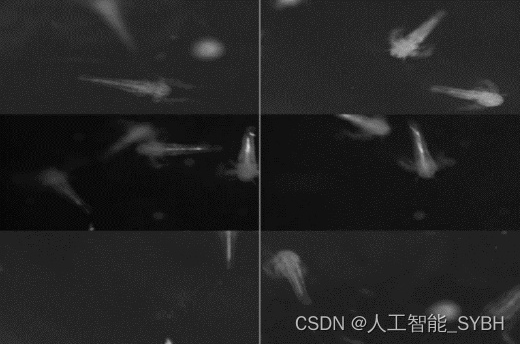
这1000张图片的选择是从一个更大的2250张图片的集 合中手动执行的。进行这种手动管理过程是为了确保图像 中物体的更好的清晰度和准确定位。通过精心挑选图像, 对数据集进行细化,以强调高质量和代表性的样本,提高 目标检测模型在捕获和识别Artemia、囊肿和排泄物方面的 可靠性。
4.类实例
训练数据集由总共1716个带注释的类实例组成,如下 所示:Artemia拥有1368个实例,占总数的79.7%。囊肿由 297个实例代表,占训练集的17.3%。最后,排泄物有51 个注释实例,约占训练数据集的3%。 在验证集上,我们总共有435个类实例。在这里,类 分布遵循类似的趋势。Artemia是最主要的类,有355个实 例,约占验证集的81.6%。囊肿由66个实例代表,对验证 数据集的贡献为15.2%。排泄物只出现了14次,仅占总验 证实例的3.2%。训练数据集和验证数据集之间相似的实 例分配,使我们能够全面评估模型在两个数据集上的性能,同时保持三个类别的比例表示。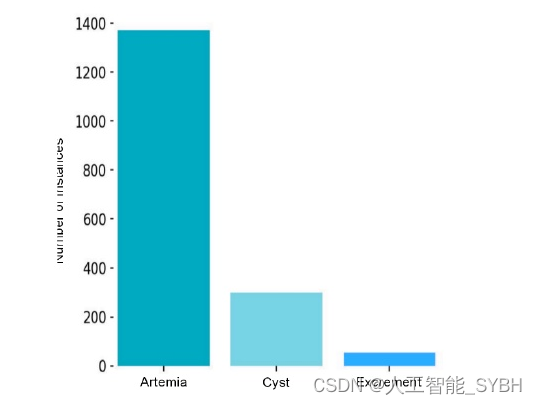
结合训练集和验证集的总数据集具有以下类别分布: Artemia以1,723个实例脱颖而出,占整个数据集的80.1%。 Artemia实例的大多数存在反映了它们在海洋环境中的生 态意义。包囊占数据集的36.3%,总共有363个实例。最 不常见的类别仅占数据集的6.5%,共有65个实例。识别 这种类分布对我们的研究至关重要,因为它为评估目标检 测模型的性能提供了基础。
5.结构相似性
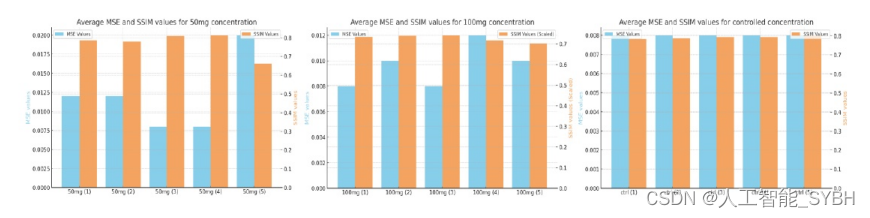
这个数据集的样本来自三个不同的浓度:50mg、 100mg和一个受控浓度。具体来说,它包括400张分别来 自50mg和100mg浓度的图像。从控制浓度中又收集了200 多张图像样本。这种分布确保了不同浓度水平的平衡表示。 在这种情况下,结构相似性指数(SSIM)的重要性不能被夸 大。SSIM是用于度量两个图像之间的相似性的度量。在 我们的研究中,它在评估数据集中图像之间的相似性方面 起着至关重要的作用。这个评估是至关重要的几个原因, 因为通过评估SSIM,我们可以确保不同浓度的图像保持 一致的质量,这对于准确的分析和比较至关重要。
SSIM还有助于确定样品在结构和外观方面是静态的 还是动态的。在研究不同浓度对受试者的影响时,这是至 关重要的。SSIM越高,表明结构相似度越高,动态变化 越少,而SSIM越低,则表明由于浓度差异而发生了显著 变化。它有助于识别由于浓度不同而发生的任何明显的结 构变化。
另一个被测量的值是均方误差(MSE)。它是一种度量 被比较的两个像素值之间的平均平方差的指标 图像。MSE值为0表示图像与自身进行比较时具有完美 的相似性。不同图像的MSE值大于0,值越大表示图像 之间的差异越大。
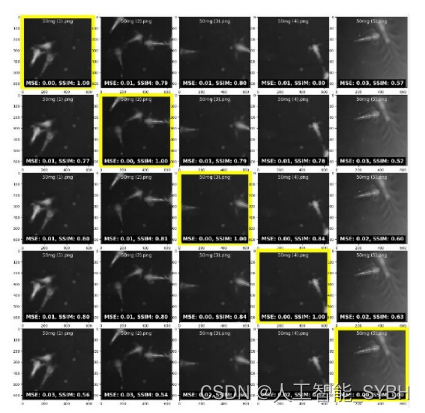
MSE值表示两幅图像像素强度差的平方的平均 值。如前所述,MSE为0表示比较图像之间没有差异(完 全相似)。例如,当“50mg (1).png”与其本身进行比较 时,MSE为0.00,表示完全匹配。同时,SSIM值衡量 两幅图像在亮度、对比度和结构方面的相似性。SSIM 值的范围从-1(不相似)到1(完全相似)。例如,与'50mg (1).png'本身相比,SSIM为1.00,这是意料之中的,因 为它是相同的图像。每个浓度有5个样本来测量和评估 这些值。有黄色边框的图像是那一行的参考图像。这 意味着该行中其他图像底部显示的所有MSE和SSIM值 都是与带有黄色边框的参考图像进行比较计算的。例 如,在第二行中,` 50mg (2).png `有一个黄色边框,表 明它是该行比较的参考图像。'50mg (1).png'与MSE值的 比较范围为0.00至0.03,SSIM值为0.52至1.00,而'50mg (2).png'与MSE值的比较范围为0.00至0.03,SSIM值为0. 54至1.00。'50mg (3).png'与MSE值的比较范围为0.00至0. 03,SSIM值为0.56至1.00,而'50mg (4).png'与MSE值的 比较范围为0.00至0.02,SSIM值为0.60至1.00。最后一张 图像'50mg (5).png'的MSE值从0.00到0.03,SSIM值从0.52到1.00。
考虑到低的MSE值和高的SSIM值,可以说在50mg浓度 下图像非常相似。这种高度的相似度表明,图像之间 在纹理、亮度和对比度上都有最小的变化。
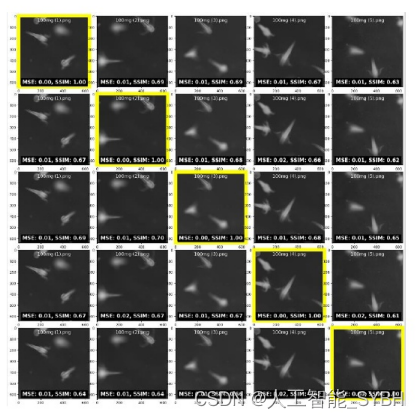
比较的MSE值也很低,测量范围在0.01到0. 02之间,这表明图像之间的像素强度差异很小,而 SSIM值大多在0.61到0.70之间,有些达到1.00(当图像 与自身进行比较时)。这些值比前一组略低,这表明结 构相似度略有下降,但总体上仍然反映了高度的相似 度。'100mg (1).png'与MSE值的比较范围为0.00至0.02, SSIM值为0.61至1.00,而'100mg (2).png'与MSE值的比 较范围为0.00至0.02,SSIM值为0.62至1.00。'100mg (3). png'的MSE值为0.00至0.01,SSIM值为0.64至1.00,而' 100mg (4).png'的MSE值为0.00至0.02,SSIM值为0.66至1. 00。'100mg (5).png'的MSE值为0.00至0.02,SSIM值为0. 61至1.00。
这些模式表明,当比较不同的图像时,与前一组(50mg) 相比,SSIM值略有下降。这表明,这些图像稍微少了 一些 与50mg组的图像相似。然而,相似度仍然很高,这表明 图像之间的差异可能仍然很细微。

“ctrl (1).png”与其他“ctrl (1).png”的MSE值 在0.00到0.01之间,SSIM值在0.72到1.00之间,而“ctrl (2).png”与其他“ctrl (1).png”的MSE值在0.00到0.01之 间,SSIM值在0.71到1.00之间。'ctrl (3).png'的MSE值从0. 00到0.01,SSIM值从0.72到1.00,而'ctrl (4).png'与其他显示 MSE值从0.00到0.01和SSIM值从0.71到1.00的比较。最后, 在比较中,“ctrl (5).png”的MSE值从0.00到0.01,SSIM值 从0.72到1.00。
控制浓度图像在比较中始终表现出较低的均方误差(MSE) 值和较高的结构相似指数(SSIM)值。这些指标表明,控 制集中的图像之间具有高度的相似性。它还表明,在像 素强度、纹理和结构方面存在最小的变化。在控制浓度 比较中观察到的高SSIM值和低MSE值加强了这些样品的 均匀性和稳定性,为实验设计和后续数据分析的完整性 提供了坚实的基础。这些关键图像质量指标的一致性有 助于更准确和清晰地了解浓度水平对研究对象的影响。
6.训练
为了训练目标检测模型,我们采用了结构化的训练 过程。数据集由1000张图像组成,其中800张用于训练, 200张用于验证,如前所述准备。在这个比较研究中,我 们使用了YOLO(你只看一次)目标检测框架的功能; YOLOv5和YOLOv8。具体使用YOLOv5s (YOLO版本5- small)和YOLOv8s (YOLO版本8-small)预训练模型架构进 行训练。
训练过程包括10个epoch。每个epoch在整个训练数据 集上迭代8次(批量大小为8)。这种精确的训练过程允许模 型学习和适应数据集内的特征和变化。在训练过程中, 模型通过随机梯度下降(SGD)优化最小化损失函数来优化 其内部参数,该优化允许模型学习和适应数据集中感兴 趣对象的鲜明特征。
通过逐步从YOLOv5升级到YOLOv8,我们探索了模 型架构的进步及其对目标检测性能的影响。10个训练 epoch和8个batch size确保了模型收敛和计算效率之间的 平衡。这也保证了模型可以有效地捕获和分类图像中的 蒿、囊肿和排泄物。
7.结果与讨论
对于目标检测,我们分别利用YOLOv5s和YOLOv8s预 训练模型,采用YOLOv5模型和YOLOv8模型。我们主要依 靠精度、召回率、f分数和平均平均精度(mAP)指标来评估 目标检测的准确性。 Precision强调的是模型做出准确的阳性预测的能力,旨 在最小化误报。另一方面,召回(Recall)侧重于模型如何有 效地检测数据集中的正例。这些指标使用以下公式计算, 其中“Pos”表示正例,“Neg”表示负例,“T”表示真, “F”表示假:
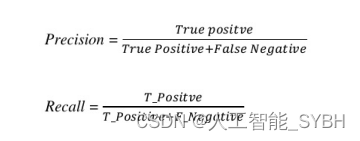
准确度作为衡量分类性能的额外指标,同时考虑真实 和错误的预测。

F1置信曲线说明了模型对用于分类阳性实例的阈值的 敏感程度。它还有助于确定在精度和召回率之间提供最佳 平衡的阈值。它还显示了该模型在同一时间跨不同置信度 水平的鲁棒性。它在假阳性和假阴性成本不同的应用中至 关重要。F1置信曲线可以提供比单个F1分数更深刻的见解, 特别是在模型具有相似的F1分数但精度-召回率平衡不同的 情况下。 此外,我们使用平均精度(mAP)来评估整体目标检测性 能。这个指标代表了被检测的所有类别计算出的平均精度 (AP)的平均值。
8.YOLOv5训练结果
YOLOv5在精选数据集上的训练提供了非常令人鼓舞的 结果,特别值得注意的是,由于渔业图像呈现的具有挑战 性的条件。显微研究方法对于在具有挑战性的水生环境中 捕捉细节图像至关重要,在水生环境中,图像经常表现出 问题,例如失焦和模糊。在处理纳米粒子和蒿(Artemia nauplii)等微观物体时,环境变得尤其具有挑战性。这种显 微成像方法至关重要,因为它允许研究人员获得高度详细的图像,这是有价值的。在一项[7] 使用吸移液管或水流来识别、分类和分离幼虫的研究中, 研究人员还使用了一种显微方法来捕捉图像。尽管显微镜 很复杂,但YOLOv5显示出其鲁棒性和适应性,可以精确地 检测和分析这些图像中的物体。
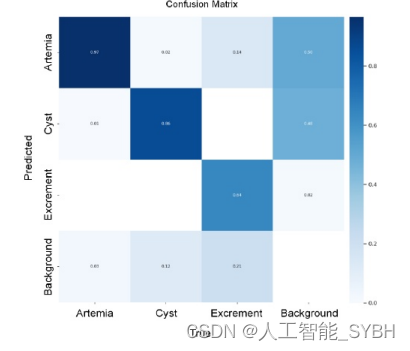
YOLOv5的混淆矩阵显示,预训练模型对蒿的成功率为0.97, 对囊肿的成功率为0.86,对排泄物的成功率为0.64。青蒿素 和囊肿的假阳性率分别为0.01和0.02,可以忽略不计。
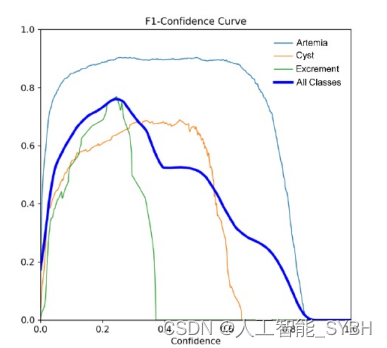
F1 -置信度作为模型对不同置信度的准确率-召回率权衡的动态表示 阈值。在0.241的阈值下,该模型持续取得了0.76的分数, 这是对准确率和召回率的平衡衡量。这一发现表明,该模 型表现出了卓越的能力,既保持了高精度,最小化假阳性, 又保持了高召回率,有效地捕获了数据集中的正例。
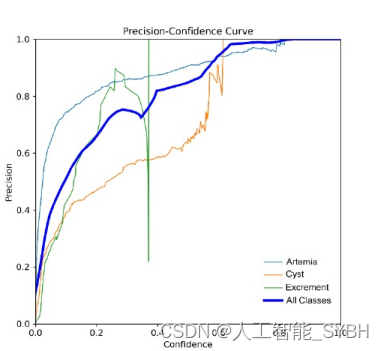
精度-置信度曲线是一个至关重要的可视化,它展示了模 型在不同置信度阈值下的精度。精度分数为1.00表示模型 在置信阈值为0.843时没有做出假阳性预测。换句话说, 当模型识别出一个置信度分数超过0.843的对象时,它的 预测就毫不含糊地准确了。
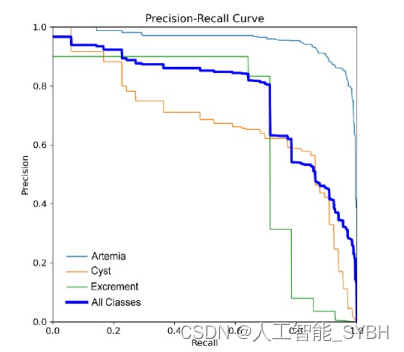
在precision - recall曲线中,平均精度(AP)为0.766,表明该 模型有效地减少了假阳性,同时捕获了数据集中的大多数 阳性实例。该模型始终在0.5的置信阈值下实现了精度-召 回率平衡,在所有类别中产生了0.766的平均精度(AP)。
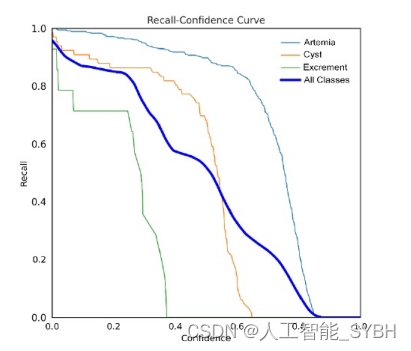
至于召回置信度,在0.000这一极低的置信度阈值下,该 模型始终取得了出色的准确率-召回率平衡,在所有类别 上的准确率得分为0.96。
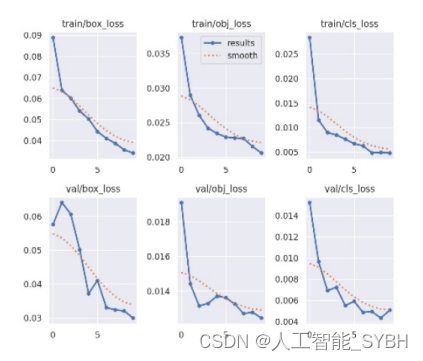
对训练和验证阶段的损失率的理解对于评估目标检测模型 的性能至关重要。在训练的初始阶段,盒子的损失大约从0. 09开始,这表明一个合理的起点。随着训练在10个epoch的 进行,有一个逐渐和持续的改善,导致盒子丢失的减少。 大约在第5个epoch,盒子损失率达到了一个稳定的水平,这 反映了模型有效预测物体边界框的能力。相比之下,与训 练曲线相比,验证损失曲线代表了一个不那么平滑的轨迹。 它从约0.06开始,然后上升到约0.07,然后逐渐下降到约0. 04。在第5个epoch之后,验证曲线表现出了稳定性,并达到 了令人称道的0.03箱损失率。
训练曲线显示了初始的对象损失率约为0.035,仅在三个 epoch后就稳定下来,最终达到了0.020的最终损失率。另一 方面,验证曲线显示了更不一致的模式,但最终在训练结 束时达到了低于0.014的优越损失率。
训练期间的类别损失最初有超过0.025的比率。然而,仅仅 经过2-3个epoch之后,损失率就下降到不到0.010,最终的 损失率极好,达到了0.005。在验证阶段,类别损失最初略 高于0.014,并伴随着曲线上的一些尖峰。最终的损失率在0. 005左右,这表明该模型在训练和验证阶段都在不准确的类 别预测方面表现出色

9.YOLOv8训练结果
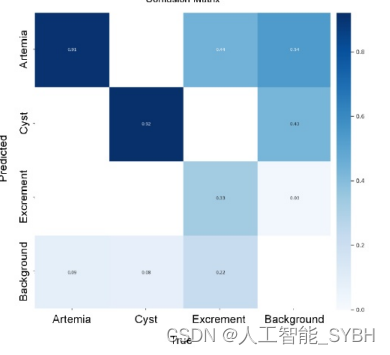
YOLOv8的混淆矩阵显示,预训练模型对Artemia的成功率 为0.91,对囊肿的成功率为0.92,假阳性为0,对排泄物的 成功率为0.33。
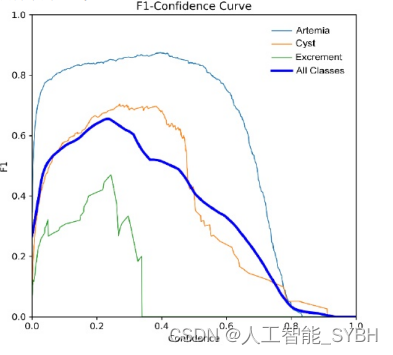
YOLOv8的F1 -置信度曲线展示了模型在各种置信度阈值下的准确 率-召回率权衡。在0.234的阈值下,该模型始终达到了0.66的F1分 数。
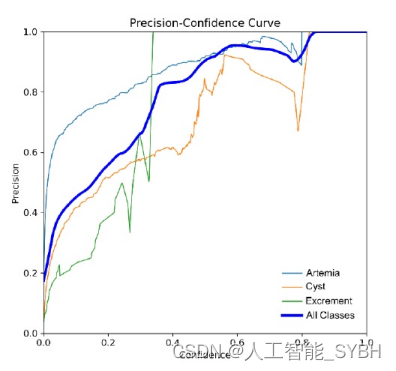
YOLOv8精度-置信曲线
对于YOLOv8,在置信阈值为0.849的情况下,YOLOv8模 型在所有类别中始终获得了1.00的完美精度分数。
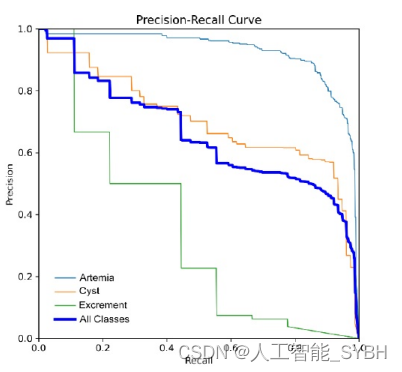
在使用mAP@0.5的中等置信度阈值下,该模型始终实现了 平衡的精度-召回性能,导致所有类别的平均精度(AP)为0. 658。准确率-召回率曲线是一个基本的可视化,评估模型 在不同的置信度阈值下平衡精度(最小化假阳性)和召回率 (捕获正例实例)的好坏。该模型通过mAP@0.5保持了精度 和召回率之间的平衡。
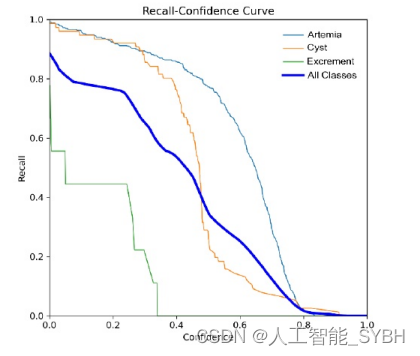
YOLOv8模型始终如一地实现了出色的精度-召回平衡,在 所有类别中精度得分为0.89。
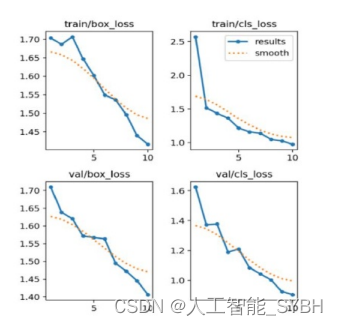
在训练中,盒子损失率最初为1.70,之后呈现出一致的下 降轨迹。经过10次训练后,最终的盒子丢失率低于1.45。 验证阶段也通过在10个epoch后达到更令人印象深刻的1.40 率,证明了盒子损失率的显著降低。训练期间的类损失遵 循类似的模式。该模型最初挣扎于大约2.5的类损失,这表 明在正确分类对象方面存在挑战。然而,该模型取得了进展 将10个epoch后的类损失率降低到1.0。另一方面,模型的 类损失在验证过程中表现出了略有不同的轨迹。它从1.6 的值开始,然后在曲线上出现一些尖峰。然而,在第5个 epoch之后,曲线逐渐平滑,最终达到大约0.05的速率。
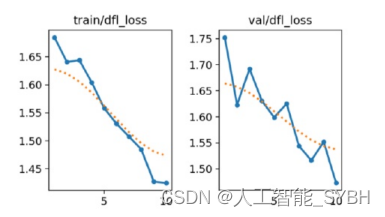
在训练过程中,分布焦损(Distributional focal loss, DFL)的 初始值超过1.65。然而,随着训练的进行,损失呈现出一 致的下降趋势,最终收敛到小于1.45的最终速率。 在验证阶段,DFL最初为1.75,这表明最初存在一些挑战。 在前两个时期之后,它显示了令人鼓舞的下降,达到了近 1.60。然而,损失再次增加,在1.70达到峰值。在验证曲 线上有一些尖峰,随着时间的推移,分布焦损失变得更加 稳定,最终损失率小于1.50。

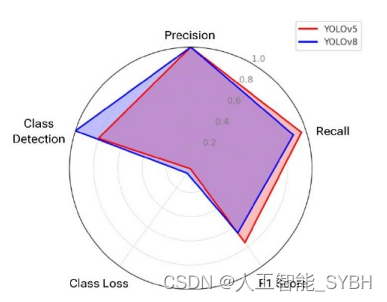
10.YOLOv5与YOLOv8结果对比
为了评估YOLOv5和YOLOv8在真实世界数据上的目标检 测能力,我们对25张图像进行了检测青蒿、囊肿和粪便的 测试。这些图像使用两个模型进行处理,每个模型都在标 记的数据集上进行训练。 图22。推断结果样本1
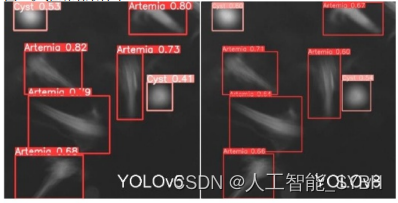
使推断结果有趣的是两个模型之间观察到的细微性能差异: YOLOv5的青蒿素和囊肿检测:在一些情况下(图22和23), YOLOv5在检测青蒿素和囊肿方面优于YOLOv8。它准确 识别和分类这些物体的能力,显示了它的熟练程度,特别 是在精度和准确性至关重要的场景中。
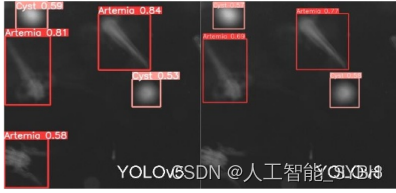

排泄物检测的挑战:然而,值得注意的是,YOLOv5在排泄 物检测方面面临着挑战。在这些情况下(图24),YOLOv5表 现出局限性,因为它难以准确地识别和检测粪便。这一观 察结果表明,YOLOv5可能需要进一步微调或专门培训,以 提高在此特定检测任务中的性能。
造成YOLOv5和YOLOv8在检测粪便方面存在差异的原因之 一可能是YOLOv8利用了DFL (Distributional 焦损)。它在解 决与对象检测相关的挑战方面起着至关重要的作用。DFL函 数用于边界盒损失,二元交叉熵用于分类损失。这些损失 被专门设计来增强更小的目标检测,在我们的例子中是排 泄物。它将焦损从离散标签扩展到连续标签,从而优化和 改进了质量估计和类别预测[8]。它使YOLOv8能够更准确地 表示实际数据中存在的灵活分布,从而降低检测结果不一 致的风险。
DFL的另一个关键优势是它能够有效地处理类不平衡[9]。 在我们的数据集中,类别之间存在着巨大的不平衡。DFL赋 予具有挑战性的例子更高的权重,在我们的例子中是粪便。 这个函数允许网络专注于学习目标边界框[10]连续位置周围 值的概率。这确保了模型可以适应任意和灵活的分布,提 高其准确检测和分类物体的能力,即使在具有挑战性的场 景中。
有了这些发现,在YOLOv5和YOLOv8之间的选择应该 由任务的特定需求和变化来驱动。进一步的研究和更广泛 的训练可能有助于确认这些最初的观察结果,并指导为给 定的应用选择最合适的模型。
结论
YOLOv5和YOLOv8在目标检测中的评估结果和结果呈 现出一幅有趣而微妙的画面。我们研究中的SSIM分析进一 步评估了YOLOv5和YOLOv8之间目标检测性能的上下文。 在各种图像浓度中观察到的高SSIM值强调了在训练数据集 中保持一致的图像质量和结构完整性的重要性。例如,使 用YOLOv5检测青蒿素和囊肿的精度表明,高质量、结构相 似的图像显著提高了其性能。另一方面,随着浓度水平的 增加,SSIM值总体上略有下降,这表明YOLOv8在保持不 同图像质量和结构相似性的检测精度方面面临着微妙的挑 战。虽然两种模型都有各自的优势和能力,但研究结果表 明,在某些情况下,YOLOv5可能优于YOLOv8。然而,同 样明显的是,这些模型的性能可能是上下文相关的和特定 于类的。
评估中值得注意的一个观察结果是,YOLOv5在检测青 蒿素和囊肿的几个实例中表现出优异的性能,显示了其在 精确驱动的检测任务中的潜力。它在这些领域的敏捷性和 准确性很有前景,特别是在精确目标识别至关重要的应用 中。
然而,同样重要的是要承认YOLOv5显示出局限性,特 别是在检测较少代表的类别时,例如粪便。在标记的数据 集中有有限的类实例的情况下,YOLOv5似乎难以准确地检 测这些类对象。
另一方面,YOLOv8在更广泛的类中检测对象方面表现 出了健壮性,即使在类实例有限的场景中也是如此。这一 观察结果表明,YOLOv8可能在某些检测任务中提供更大的 通用性和适应性,即使在特定类的训练数据稀缺时也是如 此。

