
1.Multi-Head Attention 结构
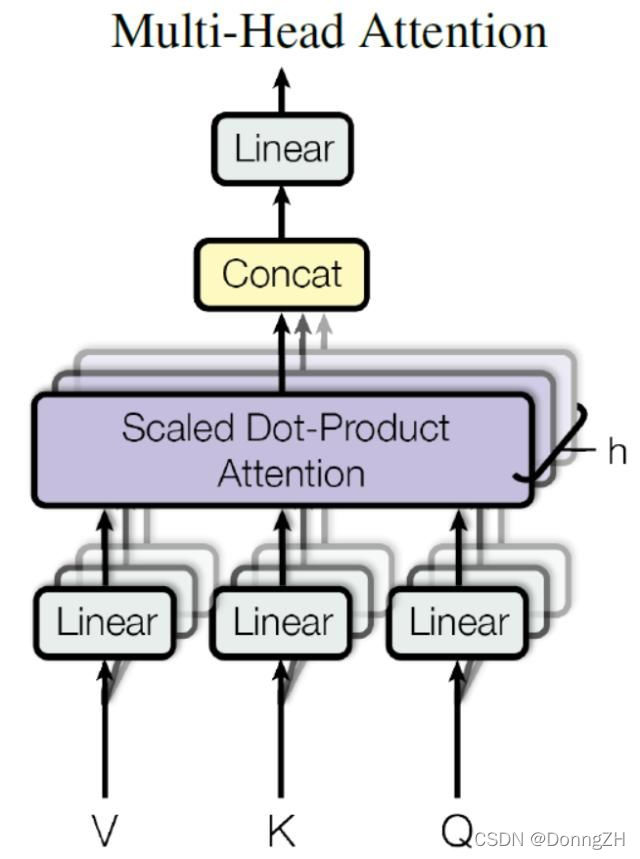
2.Multi-Head Attention 计算
Multi-Head Attention 是由多个 Self-Attention 组合形成的。对于同一个文本,一个Attention获得一个表示空间,如果多个Attention,则可以获得多个不同的表示空间。基于这种想法,就有了Multi-Head Attention。换句话说,Multi-Head Attention为Attention提供了多个“representation subspaces”。因为在每个Attention中,采用不同的Query / Key / Value权重矩阵,每个矩阵都是随机初始化生成的。然后通过训练,将词嵌入投影到不同的“representation subspaces(表示子空间)”中。
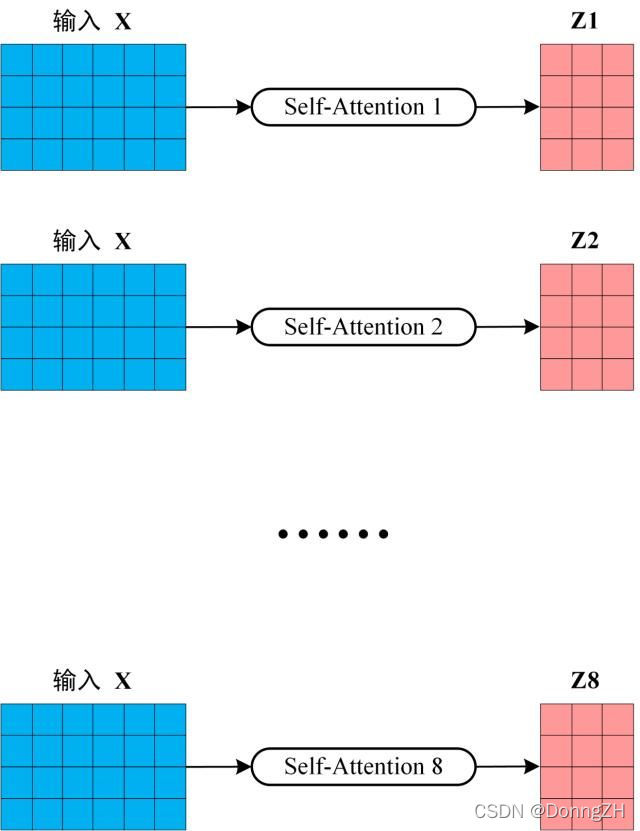
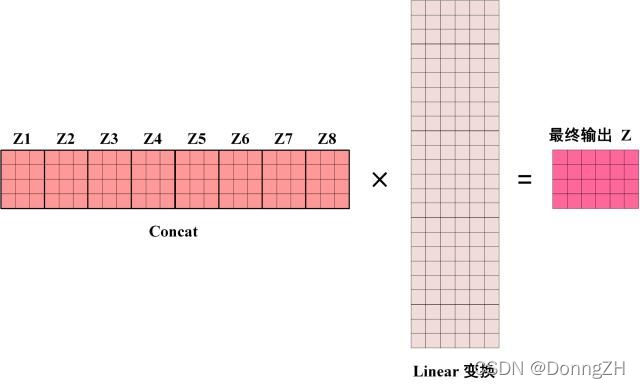
将模型分为多个头,形成多个子空间,可以让模型去关注不同方面的信息。上图中Multi-Head Attention 就是将 Scaled Dot-Product Attention 过程做了8次,再把输出合并起来。
代码实现

