
- 1如何将平板或手机作为电脑的外接显示器?
- 22022年中国数据库排行榜年终盘点-墨天轮_摩天轮数据库排行榜
- 3Python 量化交易实战_python量化交易软件
- 4人脸检测之是否佩戴口罩检测_检测是否佩戴口罩应用的什么技术
- 5windows环境下在家用笔记本电脑本地部署并微调Gemma全流程记录_gemma windows电脑
- 6蓝桥杯系列1——python组真题_蓝桥杯python真题
- 7Bert MLM_bert 的mlm
- 8计算机视觉 - Attention机制(附代码)_计算机视觉中的attention
- 9微软edge离线下载_edge-tts 离线
- 10用 WebSocket 实现一个简单的客服聊天系统
Python机器学习:Sklearn快速入门(稍微懂一些机器学习内容即可)_python sklearn
赞
踩
1.Sklearn数据集API
Sklearn中的自带数据集都在datasets子命名空间中。
# 1.使用load_*函数加载Sklearn自带的小规模数据集(其中的*表示数据集名字)
# 语法:sklearn.datasets.load_*()
B1=sklearn.datasets.load_iris() # 鸢尾花数据集
B2=sklearn.datasets.load_boston() # 波士顿房价数据集
# 2.使用fetch_*函数加载Sklearn自带的大规模数据集(其中的*表示数据集名字)
# 语法:sklearn.datasets.fetch_*(data_home=数据集路径)
# 注意事项:无论是使用load还是fetch,都返回一个继承自字典类型的Bunch类型对象
# 注意事项:大规模数据集没有存放在标准包中,需要单独从网上下载,data_home参数可以省略,表示数据集在Sklearn默认目录中。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.Bunch对象的信息获取
可以通过Bunch对象中一些键来获取对应的信息。
import sklearn
iris=sklearn.datasets.load_iris() # 此处以鸢尾花数据集为例
# 1.使用 data 键获取特征数据数组
print(iris['data'])
# 2.使用 target 键获取标签数据数组
print(iris['target'])
# 3.使用 DESCR 键获取数据描述
print(iris['DESCR'])
# 4.使用 feature_names 键获取特征名
print(iris['feature_names'])
# 5.使用 target_names 键获取标签名
print(iris['target_names'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
3.对数据集进行划分
对数据集进行划分的函数在model_selection子命名空间中。
'''
# 使用train_test_split函数对数据集进行训练集与测试集划分
# 语法:sklearn.model_selection.train_test_split(数据集中的特征数据,数据集中的标签数据)
# 可选参数:test_size表示测试集占数据集的比例(默认为0.25),random_state表示进行划分的随机数种子(用于获取相同的划分结果),shuffle是一个布尔值,表示是否对数据集进行随机打乱。
# 返回值:返回一个元组(训练集数据,测试集数据,训练集标签,测试集标签)
'''
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris=load_iris()
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.2,random_state=1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
4.特征提取(字典、文本)
特征提取是指将任意数据转化为可以用于机器学习的数字特征的方法。
# 1.使用DicVectorizer对象的fit_transform方法对字典进行特征提取 # 语法:首先以无参数方式创建一个DicVectorizer对象,然后调用该对象的fit_transform方法即可(以需要进行特征提取的字典对象作为参数) # 注意事项:如果在创建DicVectorizer对象时将sparse属性设置为True,则返回的结果是一个稀疏矩阵;如果设置为False,则是一个常规矩阵。 # 稀疏矩阵的表示:稀疏矩阵就是把矩阵中的非零元素的位置用元组表示出来。使用稀疏矩阵可以提高矩阵的加载效率。 from sklearn.feature_extraction import DictVectorizer data=[{"city:北京","temperature:100"},{"city:上海","temperature:100"},{"city:深圳","temperature:30"} transfer=DictVectorizer() transfer_result=transfer.fit_transform(data) # 之后可以使用DictVector对象的get_feature_names方法获取特征的名称 names=transfer.get_feature_names() # 2.使用CountVectorizer对象的fit_transform方法对文本进行特征提取 # 语法:首先创建一个CountVectorizer对象,然后以需要进行特征提取的文本字符串为参数调用该对象的fit_transform方法即可,同样返回一个稀疏矩阵,表示每一个单词出现的次数 # 结果分析:以字符串中所包含的每一个单词作为一个特征 # 注意事项:该方法只能得到稀疏矩阵,而不能得到常规矩阵;但是可以使用结果变量的toarray()方法获得常规矩阵 # 得到的结果也可以通过get_feature_names方法获取特征名字 # 该方式只能对英文这种单词之间用逗号隔开的语言使用,中文不能使用。如果需要对中文进行分词则需要借用jieba等类似的中文分词模块 # 另外,可以设置停用词,也就是指定不作为特征的词语 from sklearn.feature_extraction.text import CountVectorizer data=["life is short,i like python","life is long,i dislike python"] transfer=CountVectorizer() data_new=transfer.fit_transform(data) # 3.使用TfidfVectorizer对象的fit_transform方法对文本进行特征提取 # 原理:如果某些词语在一篇文章中出现概率高,而在另一些文章中出现概率低,则认为这些词语具有很好的区分能力,适合作为分类标准。因此推荐使用这种方法而不是CountVectorizer # 语法:和CountVectorizer的语法类似,只需修改一下转换器即可 from sklearn.feature_extraction.text import TfidfVectorizer data=["life is short,i like python","life is long,i dislike python"] transfer=TfidfVectorizer() data_new=transfer.fit_transform(data)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
5.数据归一化
# 使用MinMaxScaler对象的fit_transfrom方法对原始数据进行归一化
# 语法:首先创建一个MinMaxScaler对象,然后调用该对象的MinMaxScaler方法即可
# 可以在方法参数中加上feature_range参数,该参数是一个表示归一化后的上下限范围的元组
# 该方法返回一个二维的ndarray数组,其中每行表示一个样本,每列表示一个特征
# 方法的输入参数data应该是一个numpy数组:每行表示一个样本,每一列表示一个属性
from sklearn.preprocessing import MinMaxScaler
transfer=MinMaxScaler()
data_new=transfer.fit_transform(data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
6.数据标准化
# 使用StandardScaler对象的fit_transform方法对原始数据进行标准化
# 语法:首先创建一个Standard对象,然后调用该对象的fit_transform方法即可
# 方法的输入参数data应该是一个numpy数组:每行表示一个样本,每一列表示一个属性
# 与归一化的比较:归一化容易受到异常点的影响,标准化不容易受到影响
from sklearn.preprocessing import StandardScaler
transfer=StandardScaler()
data_new=transfer.StandardScaler.fit_transform(data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
7.特征降维
# 1.使用VarianceThreshold对象的fit_transform方法进行特征的低方差过滤 # 语法:首先创建一个VarianceThreshold对象,然后调用该对象的fit_transform方法即可。 # 注意事项:创建对象时可以使用threshold作为参数,该参数表示方差的阈值,默认为0 from sklearn.feature_selection import VarianceThreshold transfer=VarianceThreshold() data_new=VarianceThreshold.fit_transform(data) # 2.使用pearsonr函数计算指标之间的相关系数 # 语法:pearsons(数据列1,数据列2) from scipy.stats import pearsonr r=pearsonr(row1,row2) # 3.使用PCA对象的fit_transform方法进行主成分分析 # 构造PCA对象时可以指定n_components参数,传递一个整数或一个小数。如果参数为小数则表示保留的数据特征比例;参数是整数表示需要保留的特征个数 # 语法:构造一个PCA对象后,以需要进行主成分分析的数据作为参数,调用PCA对象的fit_transform方法即可 # 函数的返回值是经过降维后的二维数组 from sklearn.decomposition import PCA transfer=PCA() data_new=transfer.fit_transform(data) # 4.使用FactorAnalysis对象的fit_transform方法进行主成分分析 # 构造FactorAnalysis对象时可以指定n_components参数,表示降维后的特征个数 # 语法:构造一个FactorAnalysis对象后,以需要进行主成分分析的数据作为参数,调用FactorAnalysis对象的fit_transform方法即可 # 函数的返回值是经过降维后的二维数组 from sklearn.decomposition import FactorAnalysis transfer=FactorAnalysis() data_new=transfer.fit_transform(data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
8.模型预测效果的评价
# 具体步骤:
# 1.使用模型转换器的fit方法生成训练好的模型
# 2.使用模型估计器的score方法计算预测准确率
estimator.fit(x_train,y_train)
rate=estimator.score(x_test,y_test)
- 1
- 2
- 3
- 4
- 5
9.K近邻算法(KNN)
''' # 使用KNeighborsClassfier分类器运行K近邻算法 # 构造参数1:n_neighbors表示每个点的邻居数(可选参数) # 构造参数2:algorithm表示计算当前点最近邻居的算法(默认为auto) # algorithm可选参数:ball_tree(球树)、kd_tree(KD树)、brute(蛮力搜索) # 构造参数3:n_jobs表示并行计算的进程数量,越大运算速度越快,赋值为-1表示用CPU所有内核进行计算。 # 构造参数4:p表示闵可夫斯基聚类的维数。p=1表示曼哈顿距离,p=2表示欧氏距离,以此类推。 # 构造参数5:weights表示投票权重确定方法。可选的方法有uniform(等权重投票)、distance(距离反比权重投票) # 备注:K值过小容易受到异常点的影响,过大容易受到样本不均衡的影响。 # KNN算法在使用之前最好对数据进行标准化处理。 ''' from sklearn.neighbors import KNeighborsClassfier estimator=KNeighborsClassfier(n_neighbors=3,n_jobs=-1,p=2) estimator.fit(x_train,y_train) score=estimator.score(x_test,y_test) print(score)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
10.通过网格搜索调参并使用交差验证检验
# 使用GridSearchCV对象进行网格搜索调参并进行交叉验证
# 参数介绍:
# estimator:估计器对象
# param_grid:估计器参数。以字典的形式进行表示(暴力逐一尝试)
# cv:指定交叉验证的折数
# 后续的使用方法和一般的估计器相似:使用fit方法训练数据得到模型,使用score方法求预测准确率
# 常用属性介绍:best_params_表示最佳参数结果,best_score_表示最佳成功率
# best_estimator_表示最佳估计器,cv_results_表示交叉验证结果
from sklearn.model_selection import GridSearchCV
estimator=NeighborsClassfier()
param_dict={"n_neighbors":[1,3,5,7,9]}
estimator=GridSearchCV(estimator,param_grid=param_dict,cv=10)
estimator.fit(x_train,y_train)
print(estimator.best_params,estimator.best_score,estimator.best_estimator,estimator.cv_results)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
11.朴素贝叶斯分类器
# 使用MultinomialNB分类器进行多项式朴素贝叶斯分类
# 构造参数:alpha表示拉普拉斯平滑系数,默认为1.0,一般不修改
from sklearn.naive_bayes import MultinomialNB
estimator=MultinomialNB(alpha=1.0)
MultinomialNB.fit(x_train,y_train)
# 另外,还有另外两种朴素贝叶斯分类器,分别是GaussianNB和BernoulliNB,使用方法与MultinomialNB类似
- 1
- 2
- 3
- 4
- 5
- 6
12.决策树
# 1.使用DecisionTreeClaaifier分类器即可进行决策树分类 # API所在命名空间:sklearn.tree # 构造时的参数random_state用于指定初始随机数种子,max_depty用于指定最大深度 # 可以增加特征选择标准参数criterion:"gini"表示基尼指数(默认),"entropy"表示信息熵 # 参数max_features用于指定最大特征数,可选的值有:auto(自动)、sqrt(平方根)、log2(2对数)和None(所有特征都用) # 参数splitter表示特征点的划分标准,可选的值有:best(最佳划分)、random(随机划分) # random_state用于指定随机数种子 from sklearn.tree import DecisionTreeClassifier dstree_estimator=DecisionTreeClassfier(random_state=1,criterion="entropy") dstree_estimator.fit(x_train,y_train) print(dstree_estimator.score(x_test,y_test)) # 2.使用export_graphviz方法保存决策树结果 # 语法:export_graphviz(决策树估计器,out_files=导出文件路径名) # 注意事项:文件名的后缀要用dot # 导出的文件内容可以到下面的网站进行决策树可视化:webgraphviz.com expot_graphviz(detree_estimator,out_files="决策树.dot") # 3.使用plot_tree方法对决策树结果可视化 # 语法:plot_tree(决策树估计器,feature_names=特征名列表) plot_tree(dstree_estimator)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
13.随机森林
集成学习方法:通过建立若干个模型的组合来解决单一预测问题。其工作原理是生成多个模型,各自独立地学习并作出预测,这些预测结果最后结合成组合预测结果,因此优于任何一个单分类所作出的预测。
随机森林概述:包含多个决策树的分类器。组合预测结果的大小是多个决策树预测结果的大多数。
随机森林的随机性:分为特征随机和训练集随机。这是为了生成不同的决策树。
随机生成训练集:对原始训练集使用BootStrap方法(随机有放回抽样)。
随机生成特征:从所有特征中随机抽取指定个特征。
随机森林的优缺点:一般情况下的准确率较高,比较适用于高维的大数据集,能够评估每个分类特征在当前分类问题上的重要性。随机森林的缺点在于计算复杂度比较高。
''' 使用RandomForestClassifier分类器进行随机森林分类 命名空间:sklearn.ensemble 构造参数: 1.n_estimators:表示森林中树的个数。 2.criterion:表示特征选择的标准,默认为"gini“(基尼指数),也可选"entropy"(信息熵)。 3.max_depth:表示森林中每棵树的最大深度。 4.max_features:每个决策树的最大特征数量,非必选参数。可选的值有:”sqrt“(总特征数的平方根)、"log2”(总特征数的2对数)、None(总特征数)。 5.bootstrap:表示是否采用随机有放回抽样方法。默认为True。 6.random_state:表示初始随机数种子。 7.min_samples_split:表示节点划分的最小样本数。 8.min_samples_leaf:表示叶子节点的最小样本数。 使用例子: ''' from sklearn.ensemble import RandomForestClassifier rf_estimator=RandomForestClassifier(n_estimators=5,random_state=1,criterion="entropy") rf_estimator.fit(x_train,y_train) print(rf_estimator.score(x_test,y_test))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
14.正规方程优化线性回归
# 使用LinearRegression对象进行正规方程优化的线性回归
# LinearRegression对象的常用属性:coef_(权重系数) intercept_(偏置系数)
from sklearn.linear_model import LinearRegression
linear_estimator=LinearRegression()
LinearRegression.fit(x_train,y_train)
print("权重系数为:",LinearRegression.coef_)
print("偏置为:",LinearRegression.intercept_)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
15.梯度下降优化线性回归
# 使用SGDRegressor对象进行梯度下降优化的线性回归,使用方法和LinearRegression对象类似
from sklearn.linear_model import SGDRegressor
linear_estimator=SGDRegressor()
LinearRegression.fit(x_train,y_train)
print("权重系数为:",LinearRegression.coef_)
print("偏置为:",LinearRegression.intercept_)
# 对于回归器,可以通过square_error方法输出其均方误差和
print("均方误差为:",LinearRegression.square_error(x_test,y_test))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
16.逻辑回归
逻辑回归看上去是一个回归模型,但是实际上是一个分类模型。逻辑回归尤其适用于二分类问题。
# 使用LogisticRegression分类器进行逻辑回归
# 所在命名空间:sklearn.linear_model
# 参数solver:用于优化求解的算法,可选的有liblinear(适用于小数据集)、sag、saga、newton-cg、lbfgs
# 参数penalty:正则化的种类。可选l1或l2。
# 正则化强度C:一个正的浮点数,越小正则化力度越强。
from sklearn.linear_model import LogisticRegression
logit_estimator=LogisticRegression()
logit_estimator.fit(x_train,x_test)
print(logit_estimator.score(x_test,y_test))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
17.混淆矩阵和分类评估报告
- 混淆矩阵:混淆矩阵是用于直观评价分类结果好坏的一个矩阵。其每一行表示一种真实结果,每一列表示一种预测结果;矩阵中的元素表示在真实结果和预测结果分别为某一种情况的样本个数。一个二维的混淆矩阵如下图所示(当分类结果不只有两种时会产生更高维度的混淆矩阵):
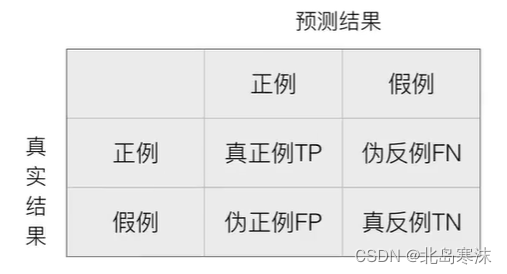
另外,混淆矩阵也是另外三种评价指标:精确率、召回率和F1分数的基础。
Sklearn中混淆矩阵的API如下所示:
'''
# API所在命名空间:sklearn.metrics
# 使用语法:confusion_matrix(y_true,y_predict,labels=分类标签列表)
# 参数解释:y_true和y_predict分别是表示样本真实分类结果和样本预测分类结果的列表或ndarray数组;labels表示混淆矩阵的行标签(和列标签是一样的)
# 返回值:返回一个用ndarray数组表示的混淆矩阵
# 测试用例:
'''
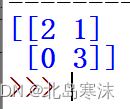
from sklearn.metrics import confusion_matrix
y_true=[0,0,0,1,1,1]
y_predict=[0,0,1,1,1,1]
test_matrix=confusion_matrix(y_true,y_predict,labels=[0,1])
print(test_matrix)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
测试用例输出结果:
- 精确率:真实情况和预测情况都为正例的样本个数/预测情况为正例的样本个数;在混淆矩阵中体现在对角线上的某个元素与其所在列的元素之和的商。
- 召回率:真实情况和预测情况都为正例的样本个数/真实情况为正例的样本个数;在混淆矩阵中体现在对角线上的某个元素与其所在行的元素之和的商。
- F1分数:精确率和召回率的调和平均值,综合了精确率和召回率两种因素。
适用情况:上述三种评价指标都适用于样本集本身较为均衡的情况,也就是各种类型的占比接近,但是对于样本集本身不均衡的情况,上述三种评价指标就不那么适用了。
Sklearn中求解精确率、召回率和F1分数的API如下所示:
'''
# API所在命名空间:sklearn.metrics
# 使用语法:classification_report(y_true,y_predict,labels=分类标签列表)
# 构造参数:y_true和y_predict分别是表示样本真实分类结果和样本预测分类结果的列表或ndarray数组;labels表示混淆矩阵的行标签(和列标签是一样的)
# 返回值:一个分类报告,报告中包含精确率、召回率和F1分数
# 测试用例
'''
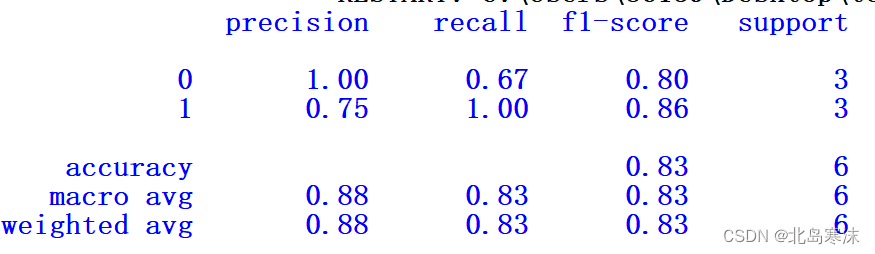
from sklearn.metrics import classification_report
y_true=[0,0,0,1,1,1]
y_predict=[0,0,1,1,1,1]
test_report=classification_report(y_true,y_predict,labels=[0,1])
print(test_report)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
测试用例输出结果:
18.ROC曲线和AUC指标
ROC曲线:ROC曲线即横坐标为FPR,纵坐标是TRP的曲线。具体曲线如下图所示:
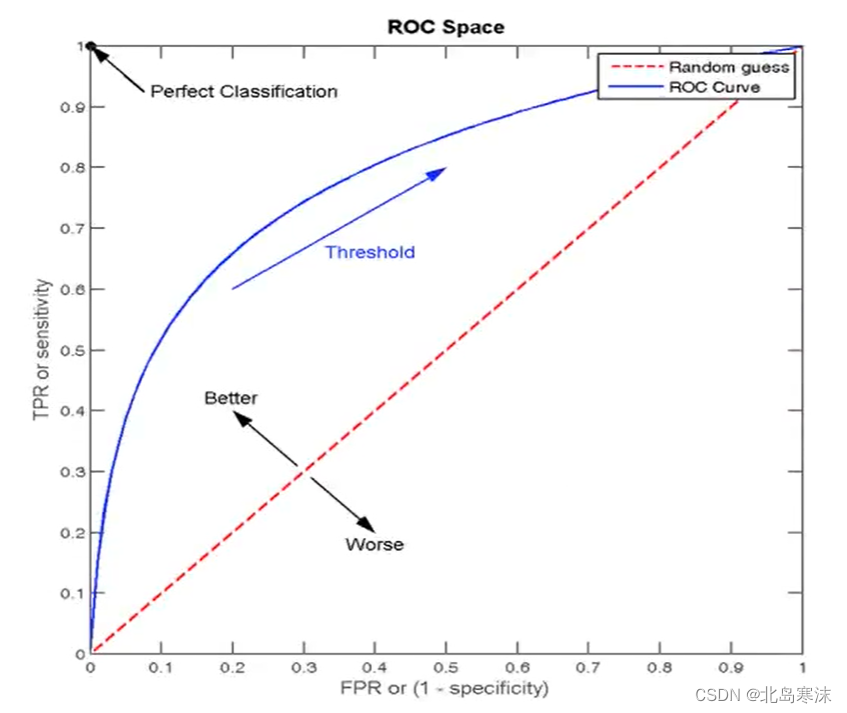
- FPR:所有真实类别为0的样本中,预测为1的样本比例;
- TPR:所有真实类别为1的样本中,预测为1的样本比例;
上图中红色虚线的FPR始终和TPR相等,也就是说无论样本情况如何都预测为1,相当于随机猜测。
Sklearn中绘制ROC曲线的API如下所示:
'''
API所在命名空间:sklearn.metrics
使用语法:roc_curve(y_true,y_score,pos_label=正样本分类标签)
参数解释:y_score表示模型预测的正类概率值(也可以是分类结果)
返回值:FPR数组,TPR数组,thresholds(选择的不同阈值按照降序排序,一般没用)
绘图方法:用得到的FPR数组和TPR数组进行ROC曲线绘制即可
测试用例(由于数字是随便给的,分类器效果不好就不展示结果了):
'''
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
y_true=[0,0,0,1,1,1]
y_predict=[0.3,0.5,1.0,0.8,0.9,0.7]
fpr,tpr,thresholds=roc_curve(y_true,y_predict,pos_label=0)
plt.plot(fpr,tpr)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
AUC:AUC即ROC曲线与两个坐标轴围成的面积。在随机猜测的情况下,AUC的值为0.5。分类器对应的AUC的值越接近于1则分类器的性能越好,一般情况下AUC的值为1的分类器不存在。
Sklearn中在获取FPR和TPR数组后,可以用如下的函数方便地计算AUC指标:
'''
所在命名空间:sklearn.metrics
使用语法:AUC值=auc(fpr,tpr)
'''
- 1
- 2
- 3
- 4
AUC只能用于二分类问题,特别适用于在样本不均衡条件下评价分类模型的好坏。
19.K均值聚类算法
# 使用KMeans对象对数据进行K均值聚类
# 构造参数:
# 1.n_clusters:指定的聚类个数
# 2.init:初始化方法,默认的方法为"K-means++”,也就是K均值++算法
# 3.max_iter:最大迭代次数
# 所在的库:sklearn.cluster
# 使用语法:
# 1.首先导入函数库
from sklearn.cluster import KMeans
# 2.构造一个KMeans对象并对其进行初始化
Kmeans_estimator=KMeans(n_clusters=3,init="k-means++",max_iter=300)
# 3.使用数据训练模型
Kmeans_estimator.fit(data)
# 4.获取模型的预测结果
Predict_result=Kmeans_estimator.predict(data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
20.轮廓系数
# 使用silhouette_score函数求聚类结果的轮廓系数
# 所在的库:sklearn.metrics
# 使用语法:silhouette(data,cluster_result)
# 参数解释:data即进行聚类的数据,cluster_result即通过聚类算法得到的聚类结果
from sklearn.metrics import silhouette_score
judge_result=silhouette_score(data,predict)
- 1
- 2
- 3
- 4
- 5
- 6
21.模型的保存和加载
每次训练好的模型可以保存到本地,下次使用时直接导入,这样就可以节约大量的训练时间。
模型保存和导入的API如下所示:
'''
所在命名空间:joblib
保存模型语法:joblib.dump(经过训练后的分类器变量,保存的文件名)
模型加载语法:joblib.load(模型文件名)
'''
- 1
- 2
- 3
- 4
- 5
22.神经网络回归
'''
所在命名空间:sklearn.neural_network
构造参数:
1.solver:MLP的求解方法:lbfgs适用于小数据集,adam鲁棒性较好;sgd表示随机梯度下降,在参数调整较优时会有最佳表现(分类效果与迭代次数)。
2.alpha:进行L2正则化的参数,是一个数字
3.hidden_layer_sizes:用一个元组来表示神经网络的隐藏层层数和每层的神经元个数。元组中的元素个数表示隐藏层层数,每个元素的值表示对应的神经元个数。
4.activation :激活函数的类型,可选‘identity’, ‘logistic’, ‘tanh’, ‘relu’}。
5.learning_rate:学习率的类型。可选‘constant’, ‘invscaling’, ‘adaptive’。
6.random_state:随机数种子
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

