
热门标签
热门文章
- 1大数据开发学习笔记_大数据应用开发课堂笔记
- 2NLP实践——文本生成中停不下来的问题_repetition penalty
- 3【安卓】Android API 指南之数据存储(Data Storage)之存储选项(Storage Options)
- 4java项目之固定资产管理系统(源码+文档)_资产管理系统源码
- 5使用frp实现内网穿透教程_frps配置使用详解
- 6Error resolving plugin [id: ‘com.android.application‘, version: ‘7.2.2‘, apply: false] > Could not r_org.gradle.api.gradleexception: error resolving pl
- 7OpenCV的基本绘图、平滑滤波(模糊)处理【C++的OpenCV 第五课-OpenCV图像常用操作(二)】_图像模糊处理 c++
- 8部署前清单:Django Web安全性
- 9【操作系统】第九章-操作系统接口_操作系统提供的两种接口方式(库函数、联机命令)
- 10Android6.0源码分析之View(一)_android view 源代码
当前位置: article > 正文
Pandas 中的 read_excel() 读取 excel 数据详细参数用法_pd.readexcel
作者:人工智能uu | 2024-06-29 06:52:12
赞
踩
pd.readexcel
前言:read_excel() 参数说明
pandas 中读取 excel 数据的:pd.read_excel()
pandas.read_excel( io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=False, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, comment=None, skipfooter=0, convert_float=True, mangle_dupe_cols=True, **kwds )

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
以下表作为案例,表名为:学习率图形.xlsx

1. 基本用法(io)
直接使用 pd.read_excel(r"文件路径"),默认读取第一个 sheet 的全部数据
实际上就是第一个参数:io,支持 str, bytes, ExcelFile, xlrd.Book, path object, or file-like object
import pandas as pd
data = pd.read_excel(r'学习率图形.xlsx')
print(data)
- 1
- 2
- 3
- 4
- 5
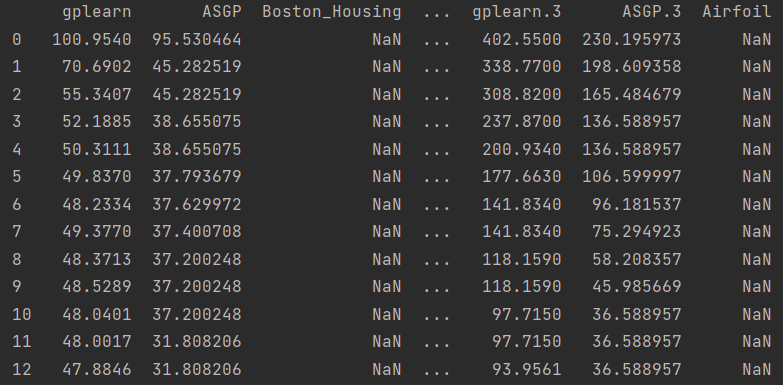
2. sheet_name(str, int, list, None, default 0)
str 字符串用于引用的 sheet 的名称

import pandas as pd
data = pd.read_excel(r'学习率图形.xlsx', sheet_name='second')
print(data)
- 1
- 2
- 3
- 4
- 5


int 整数用于引用的sheet的索引(0开始)
import pandas as pd
data = pd.read_excel(r'学习率图形.xlsx', sheet_name=1)
print(data)
- 1
- 2
- 3
- 4
- 5
字符串或整数组成的列表用于引用特定的 sheet
import pandas as pd
data = pd.read_excel(r'学习率图形.xlsx', sheet_name=[0, 'second'])
print(data)
- 1
- 2
- 3
- 4
- 5

3. header(int, list of int, default 0)
表示用第几行作为表头,默认 header=0,即默认第一行为表头
import pandas as pd
data = pd.read_excel(r'学习率图形.xlsx',header=0)
print(data.head())
- 1
- 2
- 3
- 4
- 5

hearder=[1,2,3]:选择第 2,3,4 行的数据作为表头
import pandas as pd
data = pd.read_excel(r'学习率图形.xlsx',header=[1,2,3])
print(data.head())
- 1
- 2
- 3
- 4
- 5

header=None:表示不使用数据源中的表头
import pandas as pd
data = pd.read_excel(r'学习率图形.xlsx',header=None)
print(data.head())
- 1
- 2
- 3
- 4
- 5

4.names(array-like, default None)
表示自定义表头的名称,需要传递数组参数
import pandas as pd
data = pd.read_excel(r'学习率图形.xlsx', sheet_name=1, names=['algorithm'])
print(data.head())
- 1
- 2
- 3
- 4
- 5

5. index_col(int, list of int, default None)
指定列为索引列,默认为 None,也就是索引为 0 的列用作 DataFrame 的行标签
6. usecols(int, str, list-like, or callable default None)
- 默认为
None,解析所有列 - 如果为
str,则表示Excel列字母和列范围的逗号分隔列表(例如"A:E"或"A, C, E:F"或'A:B,D:G'), 范围全闭 - 如果为
int,则表示解析到第几列。 - 如果为
int列表,则表示解析那几列。
str:usecols="A:C", 只读取从 A 列到 C 列的数据
import pandas as pd
data = pd.read_excel(r'学习率图形.xlsx', usecols="A:C")
print(data.head())
- 1
- 2
- 3
- 4
- 5

int:usecols=3, 表示解析第 0,1,2,3 列,共 4 列
import pandas as pd
data = pd.read_excel(r'学习率图形.xlsx', usecols=3)
print(data.head())
- 1
- 2
- 3
- 4
- 5
int of list:usecols=[0,1,4],表示解析第 1 列,第 2 列,第 5 列的数据
import pandas as pd
data = pd.read_excel(r'学习率图形.xlsx', usecols=[0,1,4])
print(data.head())
- 1
- 2
- 3
- 4
- 5

注: 当 header 为多行组成的表头时,使用 usecols 会爆如下错误:
ValueError: cannot specify usecols when specifying a multi-index header
- 1
7. squeeze(bool, default False)
默认为 False。如果设置 squeeze=True 则表示如果解析的数据只包含一列,则返回一个 Series。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/人工智能uu/article/detail/768561
推荐阅读
相关标签

